 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Stochastic Differential Equations for Robust and Explainable Analysis of Electromagnetic Unintended Radiated Emissions
Sep 27, 2023We present a comprehensive evaluation of the robustness and explainability of ResNet-like models in the context of Unintended Radiated Emission (URE) classification and suggest a new approach leveraging Neural Stochastic Differential Equations (SDEs) to address identified limitations. We provide an empirical demonstration of the fragility of ResNet-like models to Gaussian noise perturbations, where the model performance deteriorates sharply and its F1-score drops to near insignificance at 0.008 with a Gaussian noise of only 0.5 standard deviation. We also highlight a concerning discrepancy where the explanations provided by ResNet-like models do not reflect the inherent periodicity in the input data, a crucial attribute in URE detection from stable devices. In response to these findings, we propose a novel application of Neural SDEs to build models for URE classification that are not only robust to noise but also provide more meaningful and intuitive explanations. Neural SDE models maintain a high F1-score of 0.93 even when exposed to Gaussian noise with a standard deviation of 0.5, demonstrating superior resilience to ResNet models. Neural SDE models successfully recover the time-invariant or periodic horizontal bands from the input data, a feature that was conspicuously missing in the explanations generated by ResNet-like models. This advancement presents a small but significant step in the development of robust and interpretable models for real-world URE applications where data is inherently noisy and assurance arguments demand interpretable machine learning predictions.
TIJO: Trigger Inversion with Joint Optimization for Defending Multimodal Backdoored Models
Aug 07, 2023We present a Multimodal Backdoor Defense technique TIJO (Trigger Inversion using Joint Optimization). Recent work arXiv:2112.07668 has demonstrated successful backdoor attacks on multimodal models for the Visual Question Answering task. Their dual-key backdoor trigger is split across two modalities (image and text), such that the backdoor is activated if and only if the trigger is present in both modalities. We propose TIJO that defends against dual-key attacks through a joint optimization that reverse-engineers the trigger in both the image and text modalities. This joint optimization is challenging in multimodal models due to the disconnected nature of the visual pipeline which consists of an offline feature extractor, whose output is then fused with the text using a fusion module. The key insight enabling the joint optimization in TIJO is that the trigger inversion needs to be carried out in the object detection box feature space as opposed to the pixel space. We demonstrate the effectiveness of our method on the TrojVQA benchmark, where TIJO improves upon the state-of-the-art unimodal methods from an AUC of 0.6 to 0.92 on multimodal dual-key backdoors. Furthermore, our method also improves upon the unimodal baselines on unimodal backdoors. We present ablation studies and qualitative results to provide insights into our algorithm such as the critical importance of overlaying the inverted feature triggers on all visual features during trigger inversion. The prototype implementation of TIJO is available at https://github.com/SRI-CSL/TIJO.
AircraftVerse: A Large-Scale Multimodal Dataset of Aerial Vehicle Designs
Jun 08, 2023



We present AircraftVerse, a publicly available aerial vehicle design dataset. Aircraft design encompasses different physics domains and, hence, multiple modalities of representation. The evaluation of these cyber-physical system (CPS) designs requires the use of scientific analytical and simulation models ranging from computer-aided design tools for structural and manufacturing analysis, computational fluid dynamics tools for drag and lift computation, battery models for energy estimation, and simulation models for flight control and dynamics. AircraftVerse contains 27,714 diverse air vehicle designs - the largest corpus of engineering designs with this level of complexity. Each design comprises the following artifacts: a symbolic design tree describing topology, propulsion subsystem, battery subsystem, and other design details; a STandard for the Exchange of Product (STEP) model data; a 3D CAD design using a stereolithography (STL) file format; a 3D point cloud for the shape of the design; and evaluation results from high fidelity state-of-the-art physics models that characterize performance metrics such as maximum flight distance and hover-time. We also present baseline surrogate models that use different modalities of design representation to predict design performance metrics, which we provide as part of our dataset release. Finally, we discuss the potential impact of this dataset on the use of learning in aircraft design and, more generally, in CPS. AircraftVerse is accompanied by a data card, and it is released under Creative Commons Attribution-ShareAlike (CC BY-SA) license. The dataset is hosted at https://zenodo.org/record/6525446, baseline models and code at https://github.com/SRI-CSL/AircraftVerse, and the dataset description at https://aircraftverse.onrender.com/.
Measuring Classification Decision Certainty and Doubt
Mar 28, 2023Quantitative characterizations and estimations of uncertainty are of fundamental importance in optimization and decision-making processes. Herein, we propose intuitive scores, which we call certainty and doubt, that can be used in both a Bayesian and frequentist framework to assess and compare the quality and uncertainty of predictions in (multi-)classification decision machine learning problems.
On the Robustness of AlphaFold: A COVID-19 Case Study
Jan 12, 2023



Protein folding neural networks (PFNNs) such as AlphaFold predict remarkably accurate structures of proteins compared to other approaches. However, the robustness of such networks has heretofore not been explored. This is particularly relevant given the broad social implications of such technologies and the fact that biologically small perturbations in the protein sequence do not generally lead to drastic changes in the protein structure. In this paper, we demonstrate that AlphaFold does not exhibit such robustness despite its high accuracy. This raises the challenge of detecting and quantifying the extent to which these predicted protein structures can be trusted. To measure the robustness of the predicted structures, we utilize (i) the root-mean-square deviation (RMSD) and (ii) the Global Distance Test (GDT) similarity measure between the predicted structure of the original sequence and the structure of its adversarially perturbed version. We prove that the problem of minimally perturbing protein sequences to fool protein folding neural networks is NP-complete. Based on the well-established BLOSUM62 sequence alignment scoring matrix, we generate adversarial protein sequences and show that the RMSD between the predicted protein structure and the structure of the original sequence are very large when the adversarial changes are bounded by (i) 20 units in the BLOSUM62 distance, and (ii) five residues (out of hundreds or thousands of residues) in the given protein sequence. In our experimental evaluation, we consider 111 COVID-19 proteins in the Universal Protein resource (UniProt), a central resource for protein data managed by the European Bioinformatics Institute, Swiss Institute of Bioinformatics, and the US Protein Information Resource. These result in an overall GDT similarity test score average of around 34%, demonstrating a substantial drop in the performance of AlphaFold.
Design of Unmanned Air Vehicles Using Transformer Surrogate Models
Nov 11, 2022



Computer-aided design (CAD) is a promising new area for the application of artificial intelligence (AI) and machine learning (ML). The current practice of design of cyber-physical systems uses the digital twin methodology, wherein the actual physical design is preceded by building detailed models that can be evaluated by physics simulation models. These physics models are often slow and the manual design process often relies on exploring near-by variations of existing designs. AI holds the promise of breaking these design silos and increasing the diversity and performance of designs by accelerating the exploration of the design space. In this paper, we focus on the design of electrical unmanned aerial vehicles (UAVs). The high-density batteries and purely electrical propulsion systems have disrupted the space of UAV design, making this domain an ideal target for AI-based design. In this paper, we develop an AI Designer that synthesizes novel UAV designs. Our approach uses a deep transformer model with a novel domain-specific encoding such that we can evaluate the performance of new proposed designs without running expensive flight dynamics models and CAD tools. We demonstrate that our approach significantly reduces the overall compute requirements for the design process and accelerates the design space exploration. Finally, we identify future research directions to achieve full-scale deployment of AI-assisted CAD for UAVs.
CODiT: Conformal Out-of-Distribution Detection in Time-Series Data
Jul 24, 2022

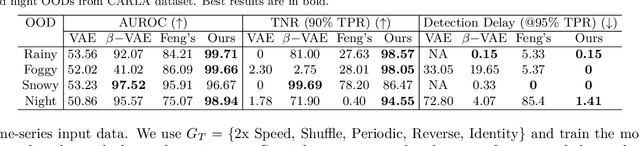
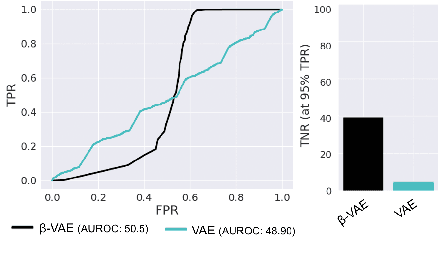
Machine learning models are prone to making incorrect predictions on inputs that are far from the training distribution. This hinders their deployment in safety-critical applications such as autonomous vehicles and healthcare. The detection of a shift from the training distribution of individual datapoints has gained attention. A number of techniques have been proposed for such out-of-distribution (OOD) detection. But in many applications, the inputs to a machine learning model form a temporal sequence. Existing techniques for OOD detection in time-series data either do not exploit temporal relationships in the sequence or do not provide any guarantees on detection. We propose using deviation from the in-distribution temporal equivariance as the non-conformity measure in conformal anomaly detection framework for OOD detection in time-series data.Computing independent predictions from multiple conformal detectors based on the proposed measure and combining these predictions by Fisher's method leads to the proposed detector CODiT with guarantees on false detection in time-series data. We illustrate the efficacy of CODiT by achieving state-of-the-art results on computer vision datasets in autonomous driving. We also show that CODiT can be used for OOD detection in non-vision datasets by performing experiments on the physiological GAIT sensory dataset. Code, data, and trained models are available at https://github.com/kaustubhsridhar/time-series-OOD.
Inferring and Conveying Intentionality: Beyond Numerical Rewards to Logical Intentions
Jul 13, 2022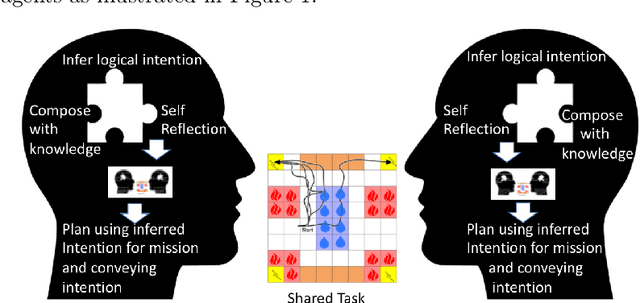
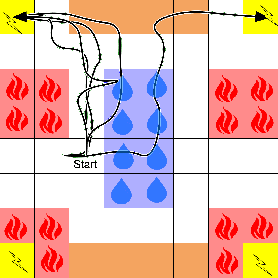
Shared intentionality is a critical component in developing conscious AI agents capable of collaboration, self-reflection, deliberation, and reasoning. We formulate inference of shared intentionality as an inverse reinforcement learning problem with logical reward specifications. We show how the approach can infer task descriptions from demonstrations. We also extend our approach to actively convey intentionality. We demonstrate the approach on a simple grid-world example.
Multiple Testing Framework for Out-of-Distribution Detection
Jun 22, 2022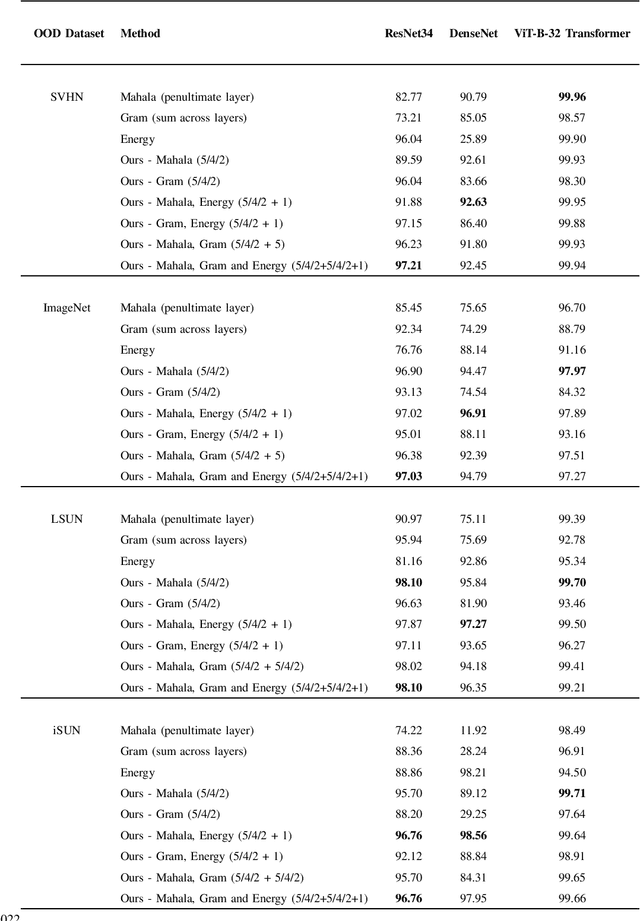
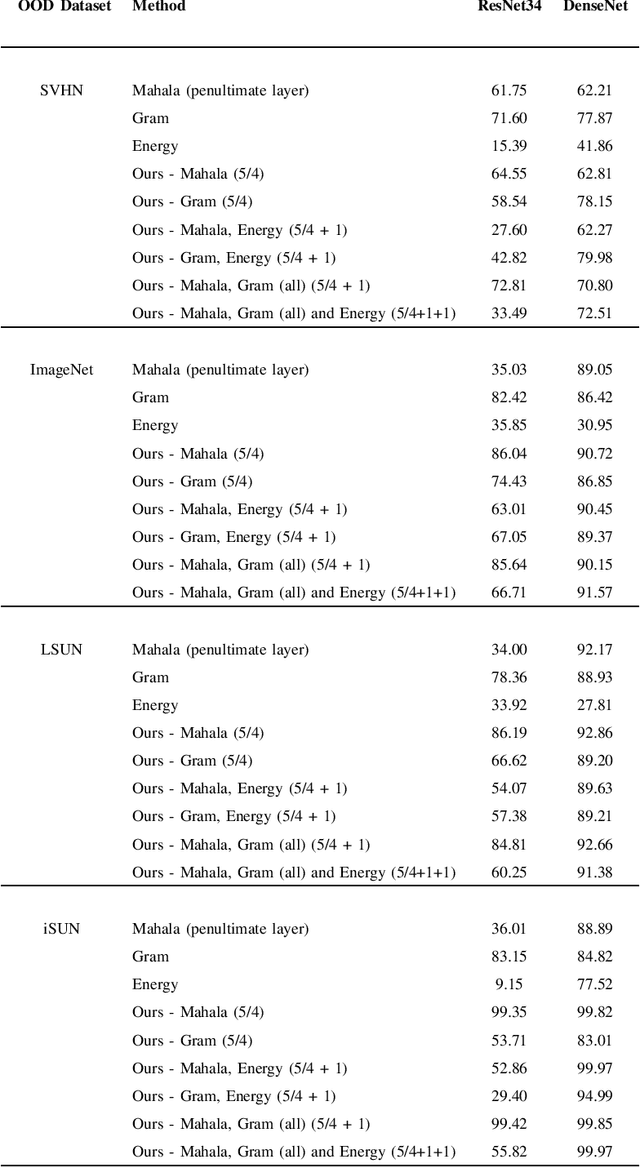
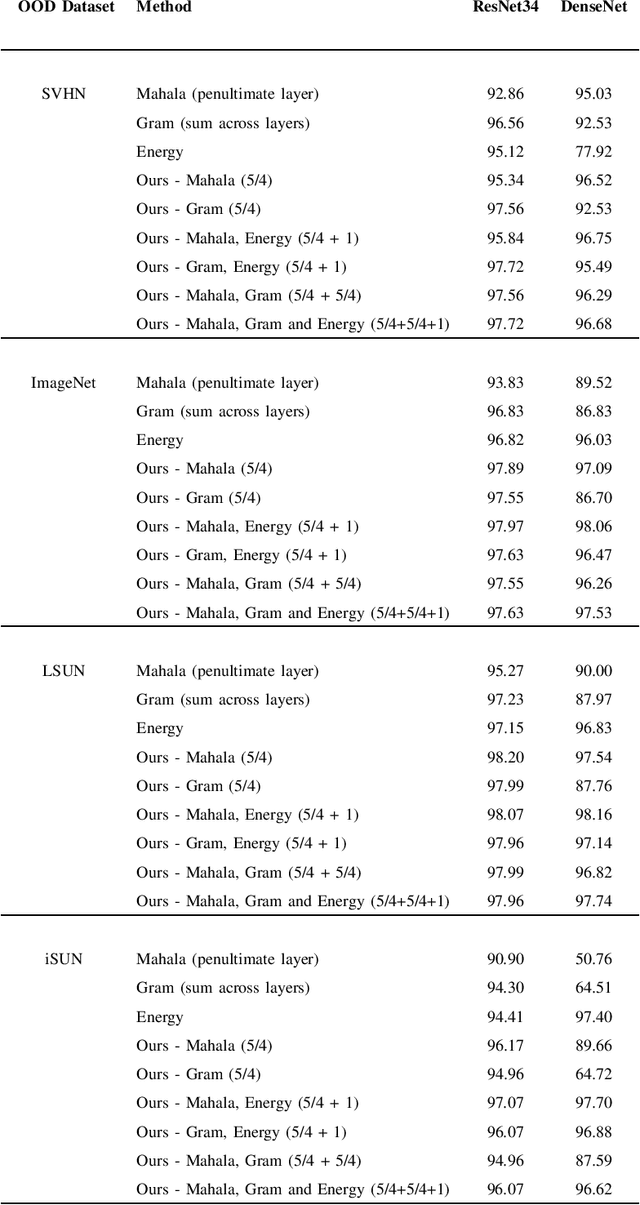
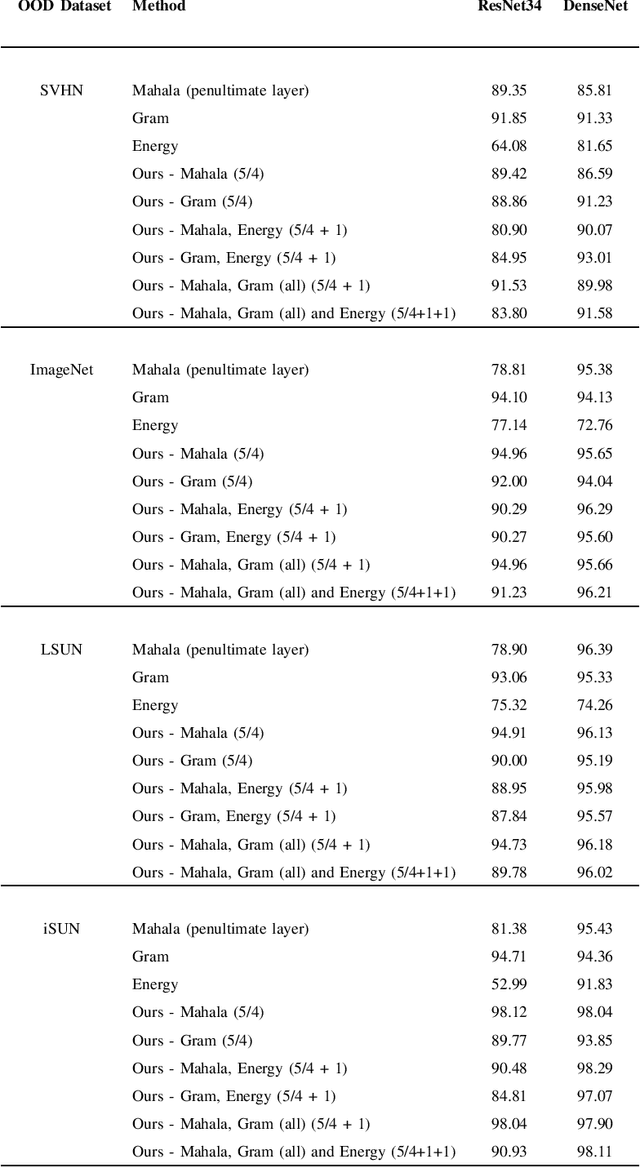
We study the problem of Out-of-Distribution (OOD) detection, that is, detecting whether a learning algorithm's output can be trusted at inference time. While a number of tests for OOD detection have been proposed in prior work, a formal framework for studying this problem is lacking. We propose a definition for the notion of OOD that includes both the input distribution and the learning algorithm, which provides insights for the construction of powerful tests for OOD detection. We propose a multiple hypothesis testing inspired procedure to systematically combine any number of different statistics from the learning algorithm using conformal p-values. We further provide strong guarantees on the probability of incorrectly classifying an in-distribution sample as OOD. In our experiments, we find that threshold-based tests proposed in prior work perform well in specific settings, but not uniformly well across different types of OOD instances. In contrast, our proposed method that combines multiple statistics performs uniformly well across different datasets and neural networks.
Principal Manifold Flows
Feb 14, 2022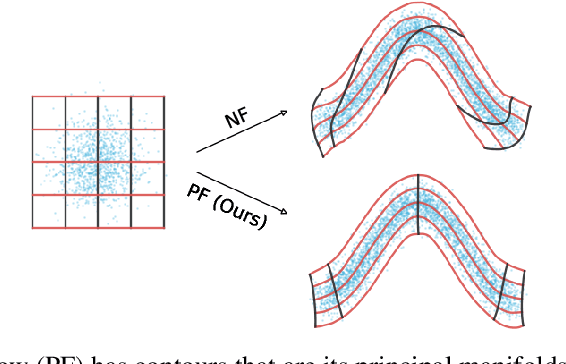

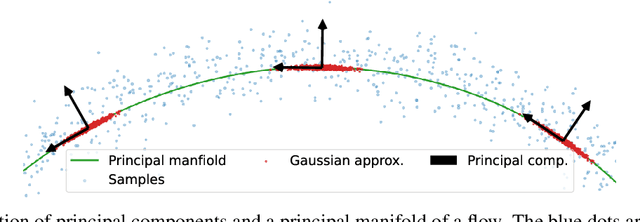

Normalizing flows map an independent set of latent variables to their samples using a bijective transformation. Despite the exact correspondence between samples and latent variables, their high level relationship is not well understood. In this paper we characterize the geometric structure of flows using principal manifolds and understand the relationship between latent variables and samples using contours. We introduce a novel class of normalizing flows, called principal manifold flows (PF), whose contours are its principal manifolds, and a variant for injective flows (iPF) that is more efficient to train than regular injective flows. PFs can be constructed using any flow architecture, are trained with a regularized maximum likelihood objective and can perform density estimation on all of their principal manifolds. In our experiments we show that PFs and iPFs are able to learn the principal manifolds over a variety of datasets. Additionally, we show that PFs can perform density estimation on data that lie on a manifold with variable dimensionality, which is not possible with existing normalizing flows.