 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAblation Study of Block Size, Weight Precision, and Scale Precision in NVFP4 Inference for Low-Power Edge-Efficient Neural Networks
Jun 03, 2026Energy-efficient edge inference requires reducing arithmetic cost, memory traffic, and hardware overhead. This paper presents an ablation-focused study of NVFP4 LUT-based inference for edge-efficient neural networks. The proposed NVLUT framework combines 4-bit NVFP4 activations, two-level scaling, LUT-based mantissa computation, voltage-scaled storage, and selective ECC protection. Multiplication is decomposed into sign, exponent, and mantissa paths, where sign uses XOR logic, exponent uses integer addition, and mantissa multiplication is replaced by compact LUT access. NVFP4 activations use FP4 data with an FP8 block scale and an FP32 tensor scale. Across six edge-efficient models, block-size ablation shows that B = 16 offers a practical accuracy/storage trade-off, requiring only 4.5078 bits per input for N = 4096. Weight-precision ablation shows that FP8 and FP16 weights provide only modest gains over FP4 weights under the same NVFP4 activation path. Compared with pure unscaled FP4, NVFP4 without retraining recovers substantial accuracy by restoring activation dynamic range, while NVFP4 with retraining achieves the best accuracy across models. Hardware analysis shows that NVLUT achieves up to 26.85x energy reduction over traditional LUTs with ECC plus voltage scaling and up to 22.85x under mixed-voltage operation. Area is reduced by up to 2.21x and 1.52x, respectively. These results demonstrate that NVFP4 two-level scaling with selective reliability protection enables robust, low-energy edge inference.
Grammar-Forced Translation of Natural Language to Temporal Logic using LLMs
Dec 18, 2025
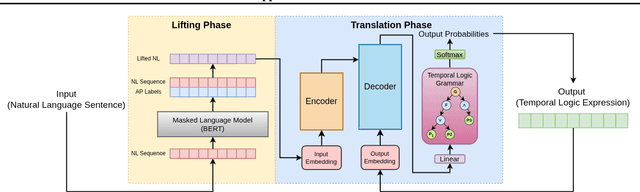

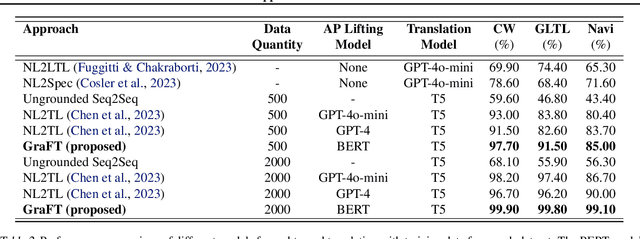
Translating natural language (NL) into a formal language such as temporal logic (TL) is integral for human communication with robots and autonomous systems. State-of-the-art approaches decompose the task into a lifting of atomic propositions (APs) phase and a translation phase. However, existing methods struggle with accurate lifting, the existence of co-references, and learning from limited data. In this paper, we propose a framework for NL to TL translation called Grammar Forced Translation (GraFT). The framework is based on the observation that previous work solves both the lifting and translation steps by letting a language model iteratively predict tokens from its full vocabulary. In contrast, GraFT reduces the complexity of both tasks by restricting the set of valid output tokens from the full vocabulary to only a handful in each step. The solution space reduction is obtained by exploiting the unique properties of each problem. We also provide a theoretical justification for why the solution space reduction leads to more efficient learning. We evaluate the effectiveness of GraFT using the CW, GLTL, and Navi benchmarks. Compared with state-of-the-art translation approaches, it can be observed that GraFT the end-to-end translation accuracy by 5.49% and out-of-domain translation accuracy by 14.06% on average.
GinSign: Grounding Natural Language Into System Signatures for Temporal Logic Translation
Dec 18, 2025Natural language (NL) to temporal logic (TL) translation enables engineers to specify, verify, and enforce system behaviors without manually crafting formal specifications-an essential capability for building trustworthy autonomous systems. While existing NL-to-TL translation frameworks have demonstrated encouraging initial results, these systems either explicitly assume access to accurate atom grounding or suffer from low grounded translation accuracy. In this paper, we propose a framework for Grounding Natural Language Into System Signatures for Temporal Logic translation called GinSign. The framework introduces a grounding model that learns the abstract task of mapping NL spans onto a given system signature: given a lifted NL specification and a system signature $\mathcal{S}$, the classifier must assign each lifted atomic proposition to an element of the set of signature-defined atoms $\mathcal{P}$. We decompose the grounding task hierarchically -- first predicting predicate labels, then selecting the appropriately typed constant arguments. Decomposing this task from a free-form generation problem into a structured classification problem permits the use of smaller masked language models and eliminates the reliance on expensive LLMs. Experiments across multiple domains show that frameworks which omit grounding tend to produce syntactically correct lifted LTL that is semantically nonequivalent to grounded target expressions, whereas our framework supports downstream model checking and achieves grounded logical-equivalence scores of $95.5\%$, a $1.4\times$ improvement over SOTA.
Explaining the Reasoning of Large Language Models Using Attribution Graphs
Dec 17, 2025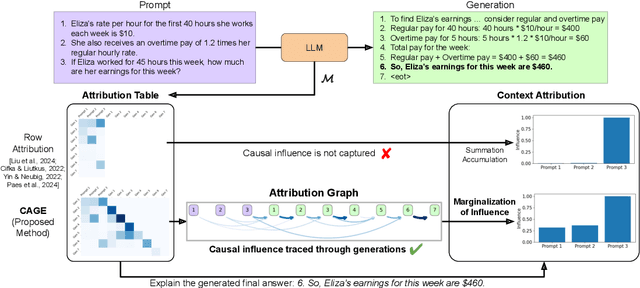
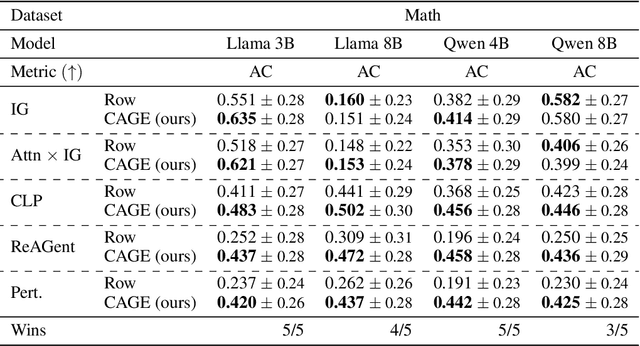
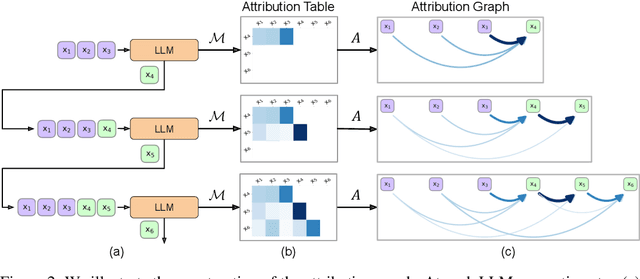
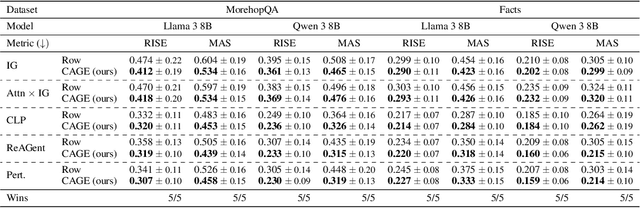
Large language models (LLMs) exhibit remarkable capabilities, yet their reasoning remains opaque, raising safety and trust concerns. Attribution methods, which assign credit to input features, have proven effective for explaining the decision making of computer vision models. From these, context attributions have emerged as a promising approach for explaining the behavior of autoregressive LLMs. However, current context attributions produce incomplete explanations by directly relating generated tokens to the prompt, discarding inter-generational influence in the process. To overcome these shortcomings, we introduce the Context Attribution via Graph Explanations (CAGE) framework. CAGE introduces an attribution graph: a directed graph that quantifies how each generation is influenced by both the prompt and all prior generations. The graph is constructed to preserve two properties-causality and row stochasticity. The attribution graph allows context attributions to be computed by marginalizing intermediate contributions along paths in the graph. Across multiple models, datasets, metrics, and methods, CAGE improves context attribution faithfulness, achieving average gains of up to 40%.
Verifiable Natural Language to Linear Temporal Logic Translation: A Benchmark Dataset and Evaluation Suite
Jul 01, 2025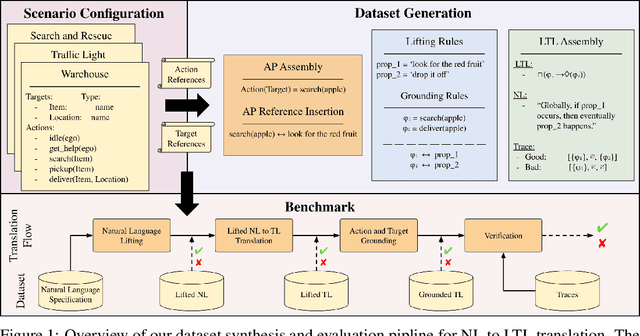
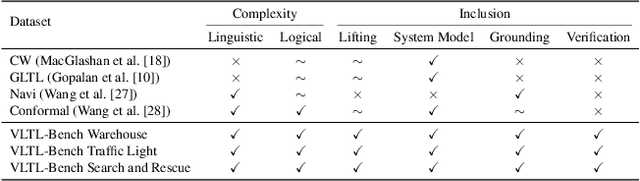


Empirical evaluation of state-of-the-art natural-language (NL) to temporal-logic (TL) translation systems reveals near-perfect performance on existing benchmarks. However, current studies measure only the accuracy of the translation of NL logic into formal TL, ignoring a system's capacity to ground atomic propositions into new scenarios or environments. This is a critical feature, necessary for the verification of resulting formulas in a concrete state space. Consequently, most NL-to-TL translation frameworks propose their own bespoke dataset in which the correct grounding is known a-priori, inflating performance metrics and neglecting the need for extensible, domain-general systems. In this paper, we introduce the Verifiable Linear Temporal Logic Benchmark ( VLTL-Bench), a unifying benchmark that measures verification and verifiability of automated NL-to-LTL translation. The dataset consists of three unique state spaces and thousands of diverse natural language specifications and corresponding formal specifications in temporal logic. Moreover, the benchmark contains sample traces to validate the temporal logic expressions. While the benchmark directly supports end-to-end evaluation, we observe that many frameworks decompose the process into i) lifting, ii) grounding, iii) translation, and iv) verification. The benchmark provides ground truths after each of these steps to enable researches to improve and evaluate different substeps of the overall problem. To encourage methodologically sound advances in verifiable NL-to-LTL translation approaches, we release VLTL-Bench here: https://www.kaggle.com/datasets/dubascudes/vltl bench.
NSP: A Neuro-Symbolic Natural Language Navigational Planner
Sep 10, 2024



Path planners that can interpret free-form natural language instructions hold promise to automate a wide range of robotics applications. These planners simplify user interactions and enable intuitive control over complex semi-autonomous systems. While existing symbolic approaches offer guarantees on the correctness and efficiency, they struggle to parse free-form natural language inputs. Conversely, neural approaches based on pre-trained Large Language Models (LLMs) can manage natural language inputs but lack performance guarantees. In this paper, we propose a neuro-symbolic framework for path planning from natural language inputs called NSP. The framework leverages the neural reasoning abilities of LLMs to i) craft symbolic representations of the environment and ii) a symbolic path planning algorithm. Next, a solution to the path planning problem is obtained by executing the algorithm on the environment representation. The framework uses a feedback loop from the symbolic execution environment to the neural generation process to self-correct syntax errors and satisfy execution time constraints. We evaluate our neuro-symbolic approach using a benchmark suite with 1500 path-planning problems. The experimental evaluation shows that our neuro-symbolic approach produces 90.1% valid paths that are on average 19-77% shorter than state-of-the-art neural approaches.
Data Augmentation for Image Classification using Generative AI
Aug 31, 2024Scaling laws dictate that the performance of AI models is proportional to the amount of available data. Data augmentation is a promising solution to expanding the dataset size. Traditional approaches focused on augmentation using rotation, translation, and resizing. Recent approaches use generative AI models to improve dataset diversity. However, the generative methods struggle with issues such as subject corruption and the introduction of irrelevant artifacts. In this paper, we propose the Automated Generative Data Augmentation (AGA). The framework combines the utility of large language models (LLMs), diffusion models, and segmentation models to augment data. AGA preserves foreground authenticity while ensuring background diversity. Specific contributions include: i) segment and superclass based object extraction, ii) prompt diversity with combinatorial complexity using prompt decomposition, and iii) affine subject manipulation. We evaluate AGA against state-of-the-art (SOTA) techniques on three representative datasets, ImageNet, CUB, and iWildCam. The experimental evaluation demonstrates an accuracy improvement of 15.6% and 23.5% for in and out-of-distribution data compared to baseline models, respectively. There is also a 64.3% improvement in SIC score compared to the baselines.
Neuro Symbolic Reasoning for Planning: Counterexample Guided Inductive Synthesis using Large Language Models and Satisfiability Solving
Sep 28, 2023



Generative large language models (LLMs) with instruct training such as GPT-4 can follow human-provided instruction prompts and generate human-like responses to these prompts. Apart from natural language responses, they have also been found to be effective at generating formal artifacts such as code, plans, and logical specifications from natural language prompts. Despite their remarkably improved accuracy, these models are still known to produce factually incorrect or contextually inappropriate results despite their syntactic coherence - a phenomenon often referred to as hallucination. This limitation makes it difficult to use these models to synthesize formal artifacts that are used in safety-critical applications. Unlike tasks such as text summarization and question-answering, bugs in code, plan, and other formal artifacts produced by LLMs can be catastrophic. We posit that we can use the satisfiability modulo theory (SMT) solvers as deductive reasoning engines to analyze the generated solutions from the LLMs, produce counterexamples when the solutions are incorrect, and provide that feedback to the LLMs exploiting the dialog capability of instruct-trained LLMs. This interaction between inductive LLMs and deductive SMT solvers can iteratively steer the LLM to generate the correct response. In our experiments, we use planning over the domain of blocks as our synthesis task for evaluating our approach. We use GPT-4, GPT3.5 Turbo, Davinci, Curie, Babbage, and Ada as the LLMs and Z3 as the SMT solver. Our method allows the user to communicate the planning problem in natural language; even the formulation of queries to SMT solvers is automatically generated from natural language. Thus, the proposed technique can enable non-expert users to describe their problems in natural language, and the combination of LLMs and SMT solvers can produce provably correct solutions.
Neural Stochastic Differential Equations for Robust and Explainable Analysis of Electromagnetic Unintended Radiated Emissions
Sep 27, 2023We present a comprehensive evaluation of the robustness and explainability of ResNet-like models in the context of Unintended Radiated Emission (URE) classification and suggest a new approach leveraging Neural Stochastic Differential Equations (SDEs) to address identified limitations. We provide an empirical demonstration of the fragility of ResNet-like models to Gaussian noise perturbations, where the model performance deteriorates sharply and its F1-score drops to near insignificance at 0.008 with a Gaussian noise of only 0.5 standard deviation. We also highlight a concerning discrepancy where the explanations provided by ResNet-like models do not reflect the inherent periodicity in the input data, a crucial attribute in URE detection from stable devices. In response to these findings, we propose a novel application of Neural SDEs to build models for URE classification that are not only robust to noise but also provide more meaningful and intuitive explanations. Neural SDE models maintain a high F1-score of 0.93 even when exposed to Gaussian noise with a standard deviation of 0.5, demonstrating superior resilience to ResNet models. Neural SDE models successfully recover the time-invariant or periodic horizontal bands from the input data, a feature that was conspicuously missing in the explanations generated by ResNet-like models. This advancement presents a small but significant step in the development of robust and interpretable models for real-world URE applications where data is inherently noisy and assurance arguments demand interpretable machine learning predictions.
Integrated Decision Gradients: Compute Your Attributions Where the Model Makes Its Decision
May 31, 2023



Attribution algorithms are frequently employed to explain the decisions of neural network models. Integrated Gradients (IG) is an influential attribution method due to its strong axiomatic foundation. The algorithm is based on integrating the gradients along a path from a reference image to the input image. Unfortunately, it can be observed that gradients computed from regions where the output logit changes minimally along the path provide poor explanations for the model decision, which is called the saturation effect problem. In this paper, we propose an attribution algorithm called integrated decision gradients (IDG). The algorithm focuses on integrating gradients from the region of the path where the model makes its decision, i.e., the portion of the path where the output logit rapidly transitions from zero to its final value. This is practically realized by scaling each gradient by the derivative of the output logit with respect to the path. The algorithm thereby provides a principled solution to the saturation problem. Additionally, we minimize the errors within the Riemann sum approximation of the path integral by utilizing non-uniform subdivisions determined by adaptive sampling. In the evaluation on ImageNet, it is demonstrated that IDG outperforms IG, left-IG, guided IG, and adversarial gradient integration both qualitatively and quantitatively using standard insertion and deletion metrics across three common models.