 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge6D Robotic OCT Scanning of Curved Tissue Surfaces
Mar 23, 2026Optical coherence tomography (OCT) is a non-invasive volumetric imaging modality with high spatial and temporal resolution. For imaging larger tissue structures, OCT probes need to be moved to scan the respective area. For handheld scanning, stitching of the acquired OCT volumes requires overlap to register the images. For robotic scanning and stitching, a typical approach is to restrict the motion to translations, as this avoids a full hand-eye calibration, which is complicated by the small field of view of most OCT probes. However, stitching by registration or by translational scanning are limited when curved tissue surfaces need to be scanned. We propose a marker for full six-dimensional hand-eye calibration of a robot mounted OCT probe. We show that the calibration results in highly repeatable estimates of the transformation. Moreover, we evaluate robotic scanning of two phantom surfaces to demonstrate that the proposed calibration allows for consistent scanning of large, curved tissue surfaces. As the proposed approach is not relying on image registration, it does not suffer from a potential accumulation of errors along a scan path. We also illustrate the improvement compared to conventional 3D-translational robotic scanning.
Tracking Any Point Methods for Markerless 3D Tissue Tracking in Endoscopic Stereo Images
Aug 11, 2025Minimally invasive surgery presents challenges such as dynamic tissue motion and a limited field of view. Accurate tissue tracking has the potential to support surgical guidance, improve safety by helping avoid damage to sensitive structures, and enable context-aware robotic assistance during complex procedures. In this work, we propose a novel method for markerless 3D tissue tracking by leveraging 2D Tracking Any Point (TAP) networks. Our method combines two CoTracker models, one for temporal tracking and one for stereo matching, to estimate 3D motion from stereo endoscopic images. We evaluate the system using a clinical laparoscopic setup and a robotic arm simulating tissue motion, with experiments conducted on a synthetic 3D-printed phantom and a chicken tissue phantom. Tracking on the chicken tissue phantom yielded more reliable results, with Euclidean distance errors as low as 1.1 mm at a velocity of 10 mm/s. These findings highlight the potential of TAP-based models for accurate, markerless 3D tracking in challenging surgical scenarios.
Robust Tracking with Particle Filtering for Fluorescent Cardiac Imaging
Aug 07, 2025



Intraoperative fluorescent cardiac imaging enables quality control following coronary bypass grafting surgery. We can estimate local quantitative indicators, such as cardiac perfusion, by tracking local feature points. However, heart motion and significant fluctuations in image characteristics caused by vessel structural enrichment limit traditional tracking methods. We propose a particle filtering tracker based on cyclicconsistency checks to robustly track particles sampled to follow target landmarks. Our method tracks 117 targets simultaneously at 25.4 fps, allowing real-time estimates during interventions. It achieves a tracking error of (5.00 +/- 0.22 px) and outperforms other deep learning trackers (22.3 +/- 1.1 px) and conventional trackers (58.1 +/- 27.1 px).
Learning a Terrain- and Robot-Aware Dynamics Model for Autonomous Mobile Robot Navigation
Sep 17, 2024



Mobile robots should be capable of planning cost-efficient paths for autonomous navigation. Typically, the terrain and robot properties are subject to variations. For instance, properties of the terrain such as friction may vary across different locations. Also, properties of the robot may change such as payloads or wear and tear, e.g., causing changing actuator gains or joint friction. Autonomous navigation approaches should thus be able to adapt to such variations. In this article, we propose a novel approach for learning a probabilistic, terrain- and robot-aware forward dynamics model (TRADYN) which can adapt to such variations and demonstrate its use for navigation. Our learning approach extends recent advances in meta-learning forward dynamics models based on Neural Processes for mobile robot navigation. We evaluate our method in simulation for 2D navigation of a robot with uni-cycle dynamics with varying properties on terrain with spatially varying friction coefficients. In our experiments, we demonstrate that TRADYN has lower prediction error over long time horizons than model ablations which do not adapt to robot or terrain variations. We also evaluate our model for navigation planning in a model-predictive control framework and under various sources of noise. We demonstrate that our approach yields improved performance in planning control-efficient paths by taking robot and terrain properties into account.
Single Frame Semantic Segmentation Using Multi-Modal Spherical Images
Aug 18, 2023In recent years, the research community has shown a lot of interest to panoramic images that offer a 360-degree directional perspective. Multiple data modalities can be fed, and complimentary characteristics can be utilized for more robust and rich scene interpretation based on semantic segmentation, to fully realize the potential. Existing research, however, mostly concentrated on pinhole RGB-X semantic segmentation. In this study, we propose a transformer-based cross-modal fusion architecture to bridge the gap between multi-modal fusion and omnidirectional scene perception. We employ distortion-aware modules to address extreme object deformations and panorama distortions that result from equirectangular representation. Additionally, we conduct cross-modal interactions for feature rectification and information exchange before merging the features in order to communicate long-range contexts for bi-modal and tri-modal feature streams. In thorough tests using combinations of four different modality types in three indoor panoramic-view datasets, our technique achieved state-of-the-art mIoU performance: 60.60% on Stanford2D3DS (RGB-HHA), 71.97% Structured3D (RGB-D-N), and 35.92% Matterport3D (RGB-D). We plan to release all codes and trained models soon.
Context-Conditional Navigation with a Learning-Based Terrain- and Robot-Aware Dynamics Model
Jul 20, 2023



In autonomous navigation settings, several quantities can be subject to variations. Terrain properties such as friction coefficients may vary over time depending on the location of the robot. Also, the dynamics of the robot may change due to, e.g., different payloads, changing the system's mass, or wear and tear, changing actuator gains or joint friction. An autonomous agent should thus be able to adapt to such variations. In this paper, we develop a novel probabilistic, terrain- and robot-aware forward dynamics model, termed TRADYN, which is able to adapt to the above-mentioned variations. It builds on recent advances in meta-learning forward dynamics models based on Neural Processes. We evaluate our method in a simulated 2D navigation setting with a unicycle-like robot and different terrain layouts with spatially varying friction coefficients. In our experiments, the proposed model exhibits lower prediction error for the task of long-horizon trajectory prediction, compared to non-adaptive ablation models. We also evaluate our model on the downstream task of navigation planning, which demonstrates improved performance in planning control-efficient paths by taking robot and terrain properties into account.
Active Particle Filter Networks: Efficient Active Localization in Continuous Action Spaces and Large Maps
Sep 20, 2022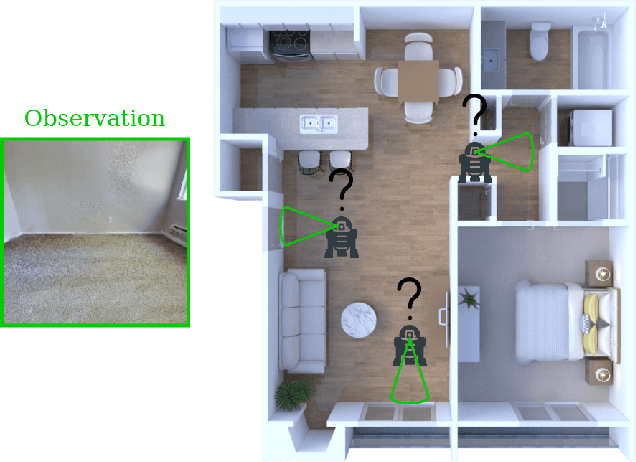
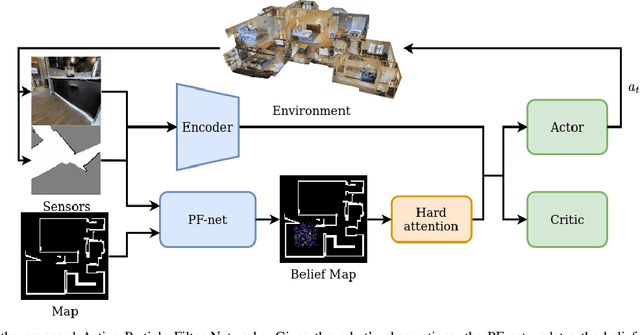
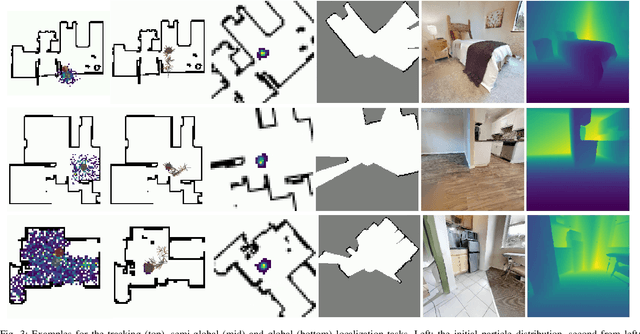
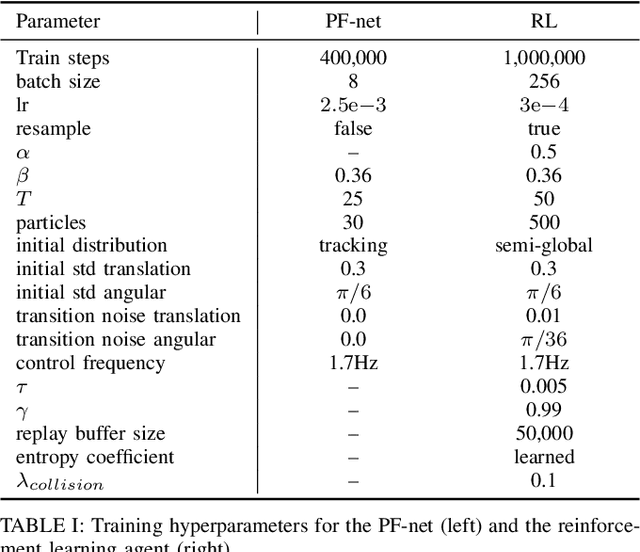
Accurate localization is a critical requirement for most robotic tasks. The main body of existing work is focused on passive localization in which the motions of the robot are assumed given, abstracting from their influence on sampling informative observations. While recent work has shown the benefits of learning motions to disambiguate the robot's poses, these methods are restricted to granular discrete actions and directly depend on the size of the global map. We propose Active Particle Filter Networks (APFN), an approach that only relies on local information for both the likelihood evaluation as well as the decision making. To do so, we couple differentiable particle filters with a reinforcement learning agent that attends to the most relevant parts of the map. The resulting approach inherits the computational benefits of particle filters and can directly act in continuous action spaces while remaining fully differentiable and thereby end-to-end optimizable as well as agnostic to the input modality. We demonstrate the benefits of our approach with extensive experiments in photorealistic indoor environments built from real-world 3D scanned apartments. Videos and code are available at http://apfn.cs.uni-freiburg.de.