 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnti-Adversarially Manipulated Attributions for Weakly Supervised Semantic Segmentation and Object Localization
Apr 11, 2022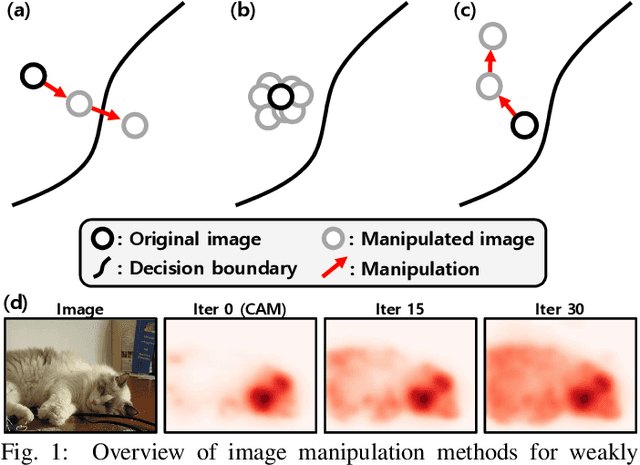
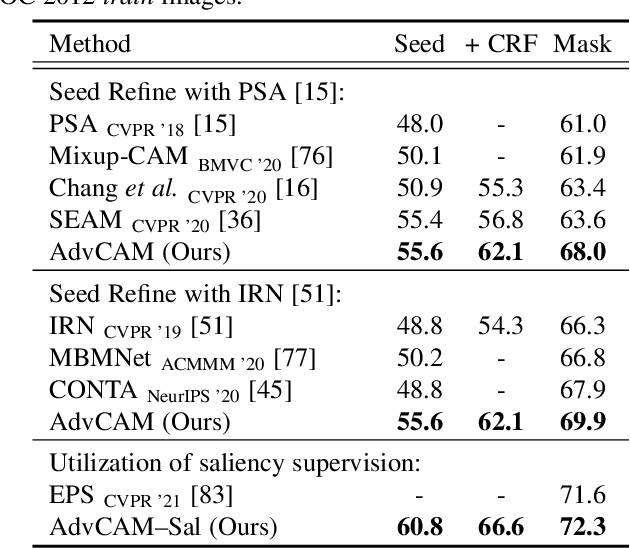
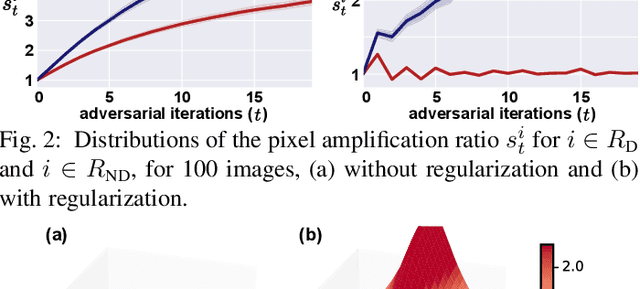

Obtaining accurate pixel-level localization from class labels is a crucial process in weakly supervised semantic segmentation and object localization. Attribution maps from a trained classifier are widely used to provide pixel-level localization, but their focus tends to be restricted to a small discriminative region of the target object. An AdvCAM is an attribution map of an image that is manipulated to increase the classification score produced by a classifier before the final softmax or sigmoid layer. This manipulation is realized in an anti-adversarial manner, so that the original image is perturbed along pixel gradients in directions opposite to those used in an adversarial attack. This process enhances non-discriminative yet class-relevant features, which make an insufficient contribution to previous attribution maps, so that the resulting AdvCAM identifies more regions of the target object. In addition, we introduce a new regularization procedure that inhibits the incorrect attribution of regions unrelated to the target object and the excessive concentration of attributions on a small region of the target object. Our method achieves a new state-of-the-art performance in weakly and semi-supervised semantic segmentation, on both the PASCAL VOC 2012 and MS COCO 2014 datasets. In weakly supervised object localization, it achieves a new state-of-the-art performance on the CUB-200-2011 and ImageNet-1K datasets.
Perception Prioritized Training of Diffusion Models
Apr 01, 2022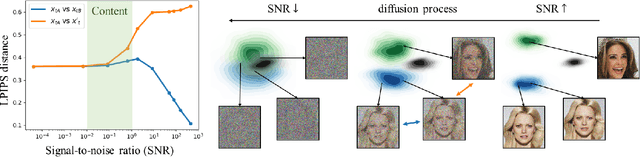
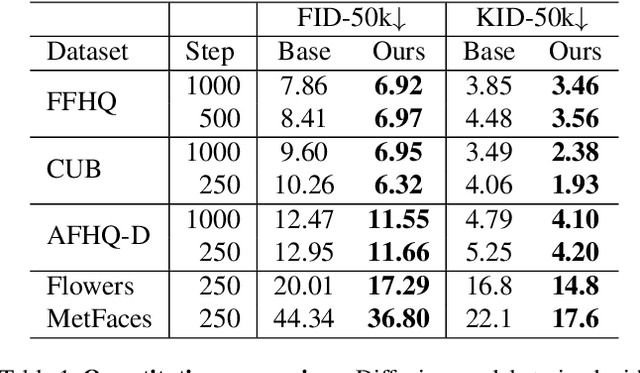

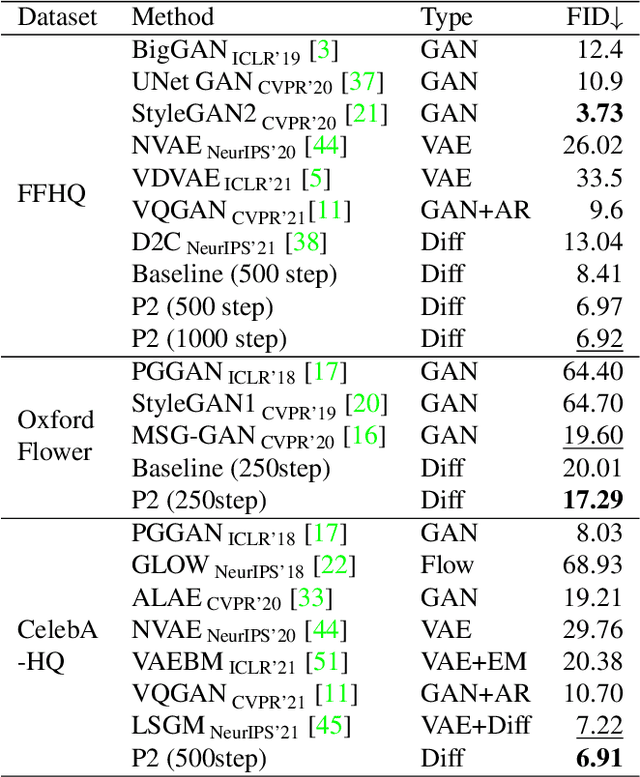
Diffusion models learn to restore noisy data, which is corrupted with different levels of noise, by optimizing the weighted sum of the corresponding loss terms, i.e., denoising score matching loss. In this paper, we show that restoring data corrupted with certain noise levels offers a proper pretext task for the model to learn rich visual concepts. We propose to prioritize such noise levels over other levels during training, by redesigning the weighting scheme of the objective function. We show that our simple redesign of the weighting scheme significantly improves the performance of diffusion models regardless of the datasets, architectures, and sampling strategies.
Bridging the Gap between Classification and Localization for Weakly Supervised Object Localization
Apr 01, 2022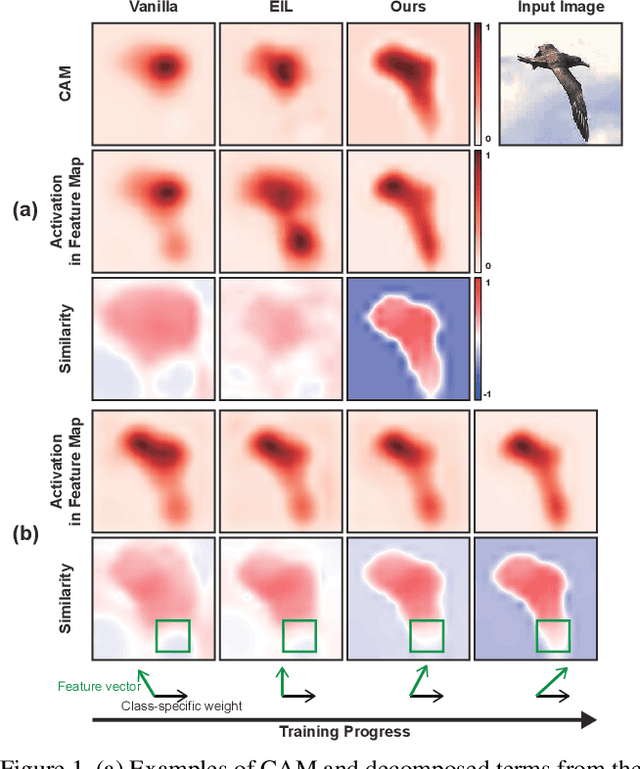
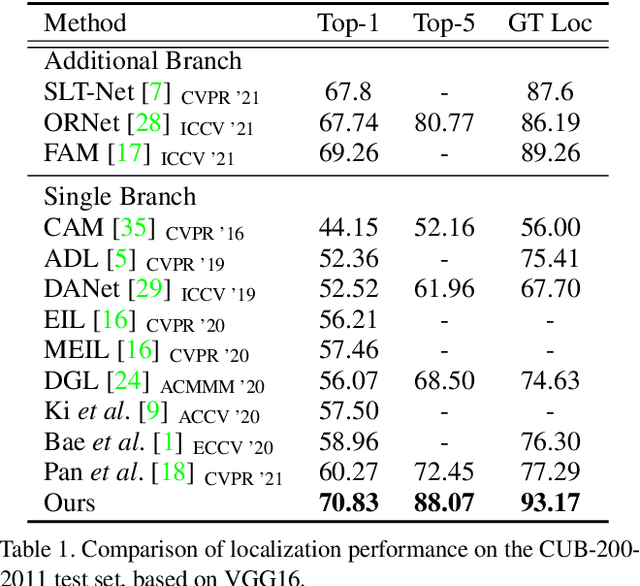
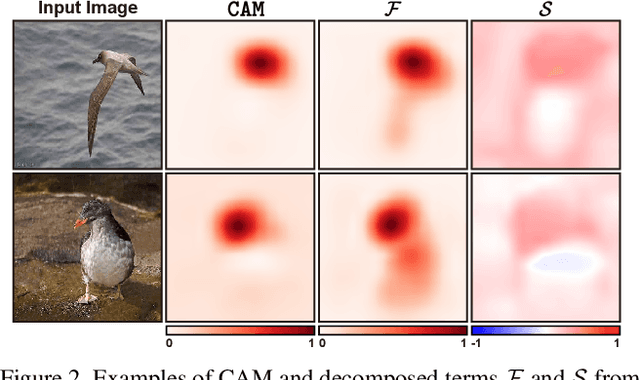
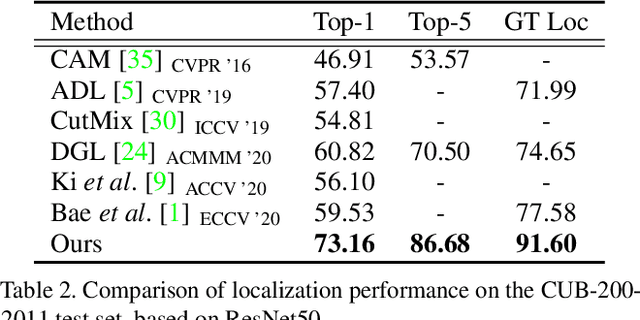
Weakly supervised object localization aims to find a target object region in a given image with only weak supervision, such as image-level labels. Most existing methods use a class activation map (CAM) to generate a localization map; however, a CAM identifies only the most discriminative parts of a target object rather than the entire object region. In this work, we find the gap between classification and localization in terms of the misalignment of the directions between an input feature and a class-specific weight. We demonstrate that the misalignment suppresses the activation of CAM in areas that are less discriminative but belong to the target object. To bridge the gap, we propose a method to align feature directions with a class-specific weight. The proposed method achieves a state-of-the-art localization performance on the CUB-200-2011 and ImageNet-1K benchmarks.
Demystifying the Neural Tangent Kernel from a Practical Perspective: Can it be trusted for Neural Architecture Search without training?
Mar 28, 2022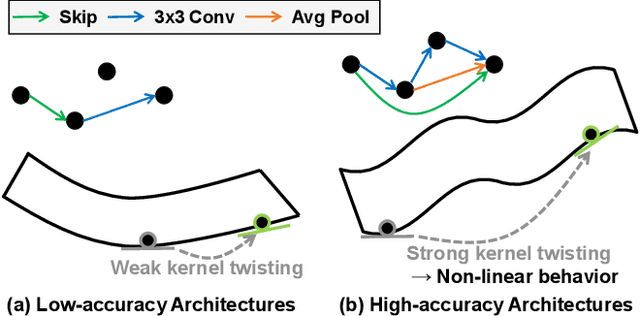
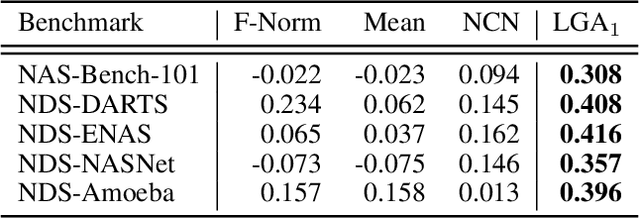
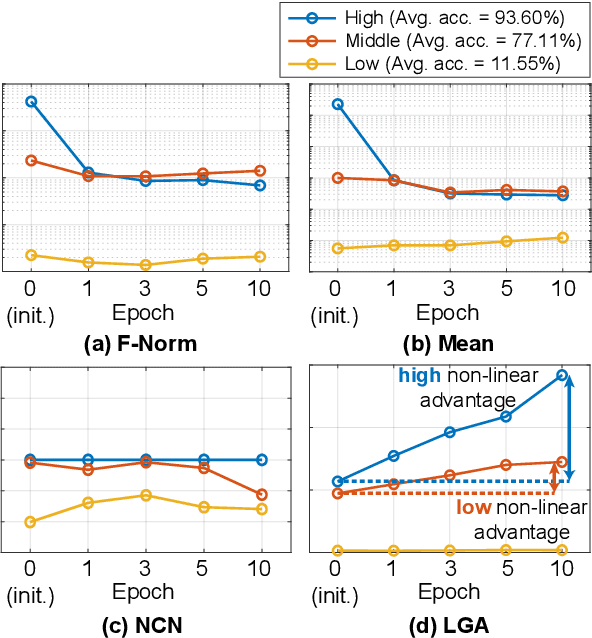
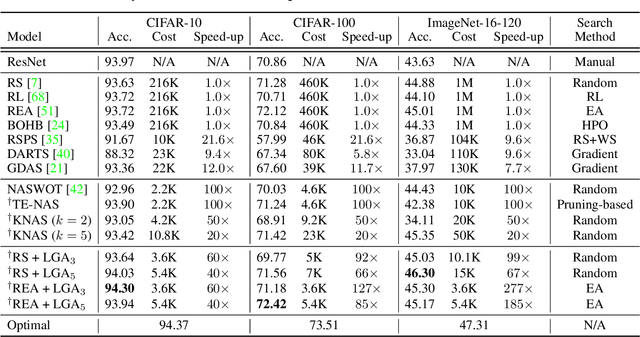
In Neural Architecture Search (NAS), reducing the cost of architecture evaluation remains one of the most crucial challenges. Among a plethora of efforts to bypass training of each candidate architecture to convergence for evaluation, the Neural Tangent Kernel (NTK) is emerging as a promising theoretical framework that can be utilized to estimate the performance of a neural architecture at initialization. In this work, we revisit several at-initialization metrics that can be derived from the NTK and reveal their key shortcomings. Then, through the empirical analysis of the time evolution of NTK, we deduce that modern neural architectures exhibit highly non-linear characteristics, making the NTK-based metrics incapable of reliably estimating the performance of an architecture without some amount of training. To take such non-linear characteristics into account, we introduce Label-Gradient Alignment (LGA), a novel NTK-based metric whose inherent formulation allows it to capture the large amount of non-linear advantage present in modern neural architectures. With minimal amount of training, LGA obtains a meaningful level of rank correlation with the post-training test accuracy of an architecture. Lastly, we demonstrate that LGA, complemented with few epochs of training, successfully guides existing search algorithms to achieve competitive search performances with significantly less search cost. The code is available at: https://github.com/nutellamok/DemystifyingNTK.
Weakly Supervised Semantic Segmentation using Out-of-Distribution Data
Mar 08, 2022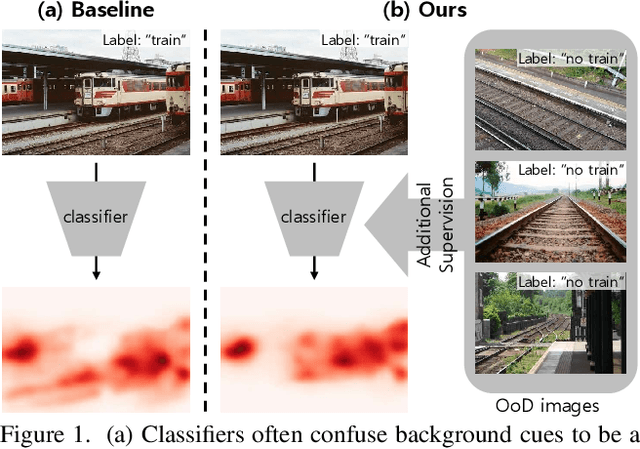
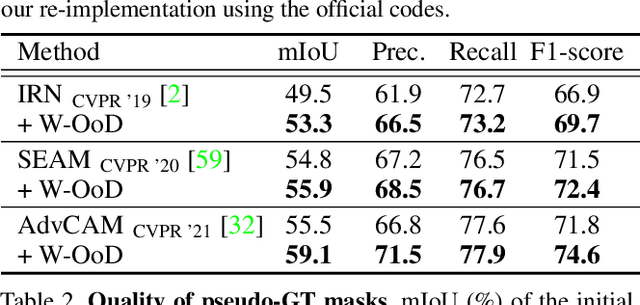

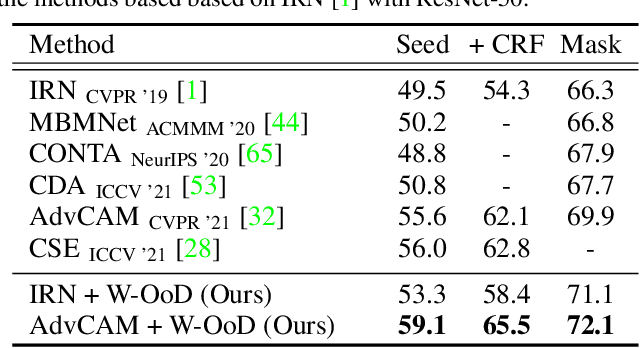
Weakly supervised semantic segmentation (WSSS) methods are often built on pixel-level localization maps obtained from a classifier. However, training on class labels only, classifiers suffer from the spurious correlation between foreground and background cues (e.g. train and rail), fundamentally bounding the performance of WSSS. There have been previous endeavors to address this issue with additional supervision. We propose a novel source of information to distinguish foreground from the background: Out-of-Distribution (OoD) data, or images devoid of foreground object classes. In particular, we utilize the hard OoDs that the classifier is likely to make false-positive predictions. These samples typically carry key visual features on the background (e.g. rail) that the classifiers often confuse as foreground (e.g. train), so these cues let classifiers correctly suppress spurious background cues. Acquiring such hard OoDs does not require an extensive amount of annotation efforts; it only incurs a few additional image-level labeling costs on top of the original efforts to collect class labels. We propose a method, W-OoD, for utilizing the hard OoDs. W-OoD achieves state-of-the-art performance on Pascal VOC 2012.
AutoSNN: Towards Energy-Efficient Spiking Neural Networks
Feb 16, 2022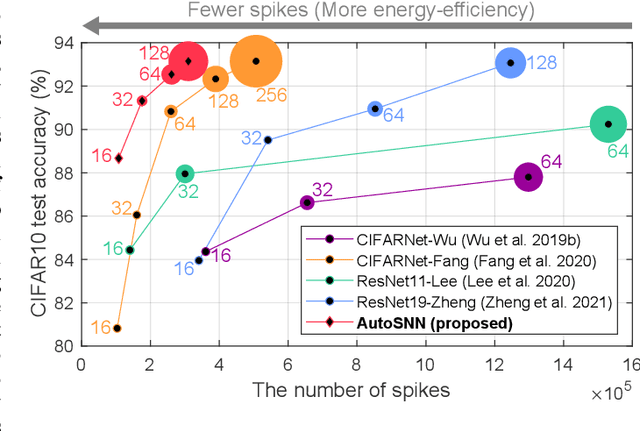
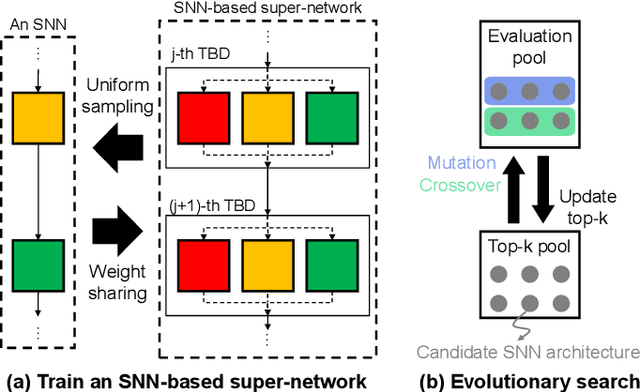
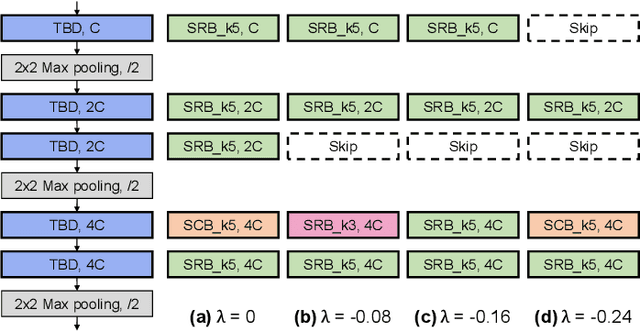
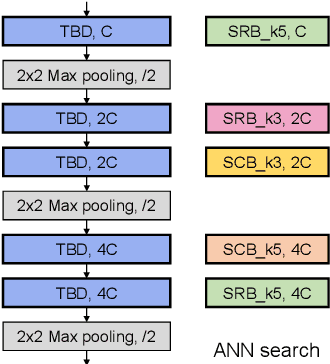
Spiking neural networks (SNNs) that mimic information transmission in the brain can energy-efficiently process spatio-temporal information through discrete and sparse spikes, thereby receiving considerable attention. To improve accuracy and energy efficiency of SNNs, most previous studies have focused solely on training methods, and the effect of architecture has rarely been studied. We investigate the design choices used in the previous studies in terms of the accuracy and number of spikes and figure out that they are not best-suited for SNNs. To further improve the accuracy and reduce the spikes generated by SNNs, we propose a spike-aware neural architecture search framework called AutoSNN. We define a search space consisting of architectures without undesirable design choices. To enable the spike-aware architecture search, we introduce a fitness that considers both the accuracy and number of spikes. AutoSNN successfully searches for SNN architectures that outperform hand-crafted SNNs in accuracy and energy efficiency. We thoroughly demonstrate the effectiveness of AutoSNN on various datasets including neuromorphic datasets.
Dataset Condensation with Contrastive Signals
Feb 07, 2022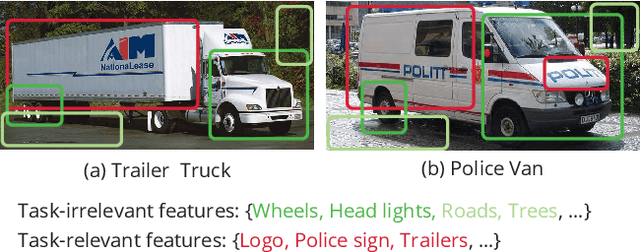
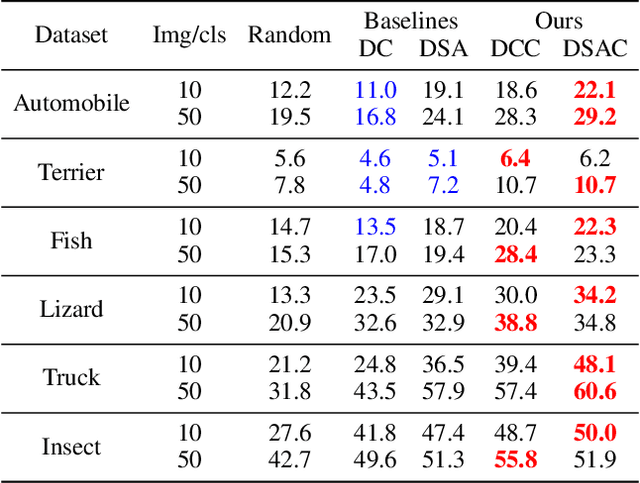
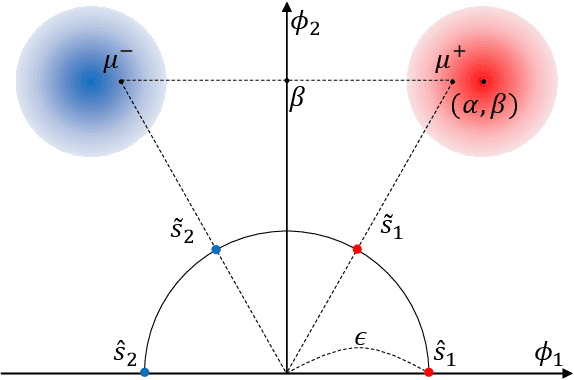
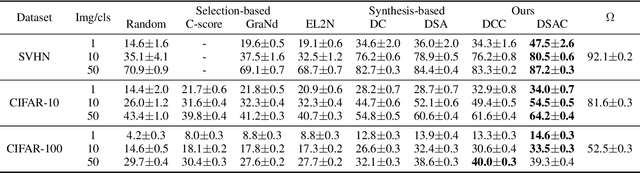
Recent studies have demonstrated that gradient matching-based dataset synthesis, or dataset condensation (DC), methods can achieve state-of-the-art performance when applied to data-efficient learning tasks. However, in this study, we prove that the existing DC methods can perform worse than the random selection method when task-irrelevant information forms a significant part of the training dataset. We attribute this to the lack of participation of the contrastive signals between the classes resulting from the class-wise gradient matching strategy. To address this problem, we propose Dataset Condensation with Contrastive signals (DCC) by modifying the loss function to enable the DC methods to effectively capture the differences between classes. In addition, we analyze the new loss function in terms of training dynamics by tracking the kernel velocity. Furthermore, we introduce a bi-level warm-up strategy to stabilize the optimization. Our experimental results indicate that while the existing methods are ineffective for fine-grained image classification tasks, the proposed method can successfully generate informative synthetic datasets for the same tasks. Moreover, we demonstrate that the proposed method outperforms the baselines even on benchmark datasets such as SVHN, CIFAR-10, and CIFAR-100. Finally, we demonstrate the high applicability of the proposed method by applying it to continual learning tasks.
Robust End-to-End Focal Liver Lesion Detection using Unregistered Multiphase Computed Tomography Images
Dec 17, 2021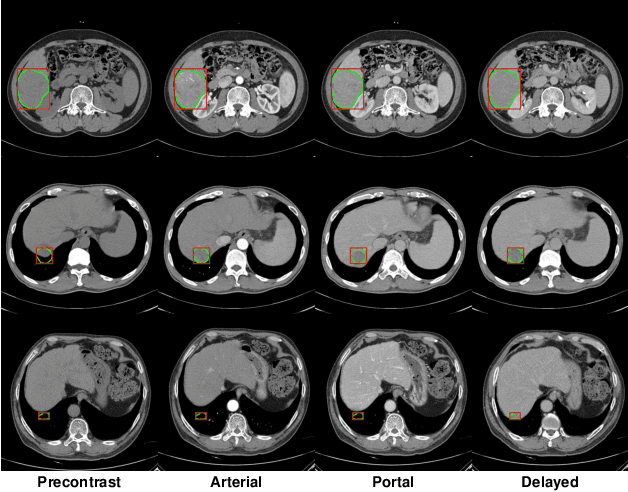
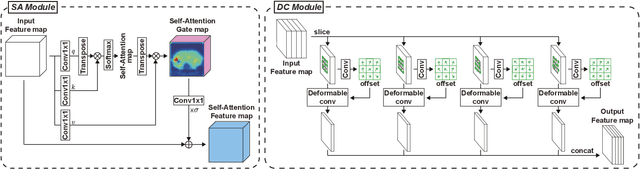
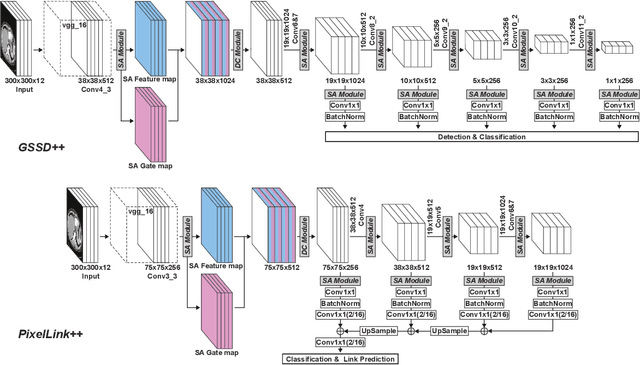
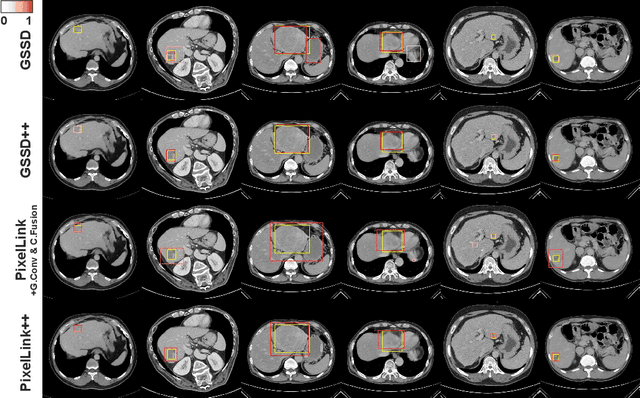
The computer-aided diagnosis of focal liver lesions (FLLs) can help improve workflow and enable correct diagnoses; FLL detection is the first step in such a computer-aided diagnosis. Despite the recent success of deep-learning-based approaches in detecting FLLs, current methods are not sufficiently robust for assessing misaligned multiphase data. By introducing an attention-guided multiphase alignment in feature space, this study presents a fully automated, end-to-end learning framework for detecting FLLs from multiphase computed tomography (CT) images. Our method is robust to misaligned multiphase images owing to its complete learning-based approach, which reduces the sensitivity of the model's performance to the quality of registration and enables a standalone deployment of the model in clinical practice. Evaluation on a large-scale dataset with 280 patients confirmed that our method outperformed previous state-of-the-art methods and significantly reduced the performance degradation for detecting FLLs using misaligned multiphase CT images. The robustness of the proposed method can enhance the clinical adoption of the deep-learning-based computer-aided detection system.
Guided-TTS:Text-to-Speech with Untranscribed Speech
Dec 07, 2021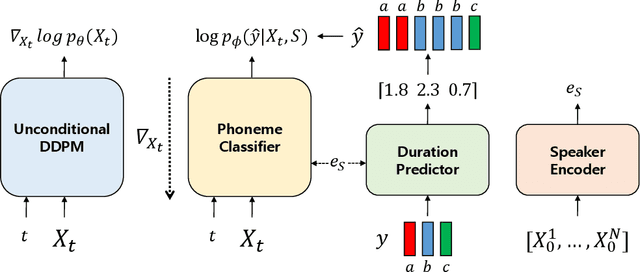

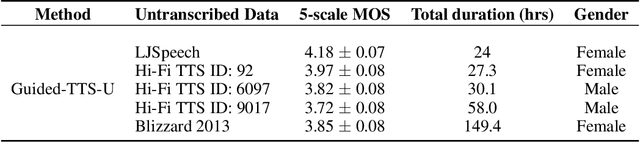
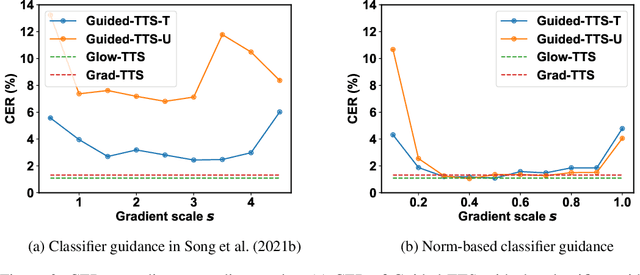
Most neural text-to-speech (TTS) models require <speech, transcript> paired data from the desired speaker for high-quality speech synthesis, which limits the usage of large amounts of untranscribed data for training. In this work, we present Guided-TTS, a high-quality TTS model that learns to generate speech from untranscribed speech data. Guided-TTS combines an unconditional diffusion probabilistic model with a separately trained phoneme classifier for text-to-speech. By modeling the unconditional distribution for speech, our model can utilize the untranscribed data for training. For text-to-speech synthesis, we guide the generative process of the unconditional DDPM via phoneme classification to produce mel-spectrograms from the conditional distribution given transcript. We show that Guided-TTS achieves comparable performance with the existing methods without any transcript for LJSpeech. Our results further show that a single speaker-dependent phoneme classifier trained on multispeaker large-scale data can guide unconditional DDPMs for various speakers to perform TTS.
Supervised Neural Discrete Universal Denoiser for Adaptive Denoising
Nov 24, 2021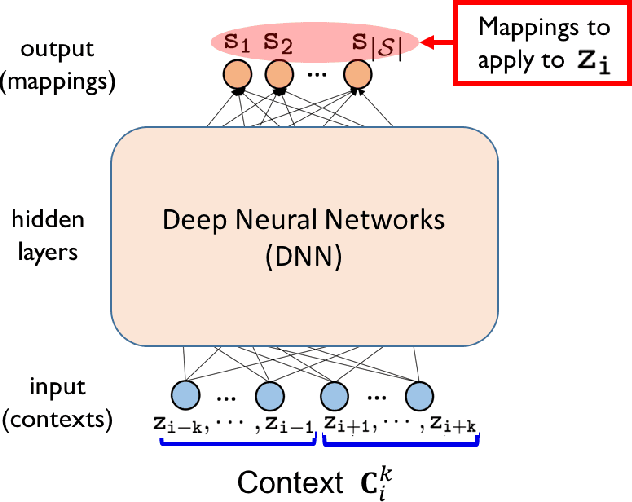
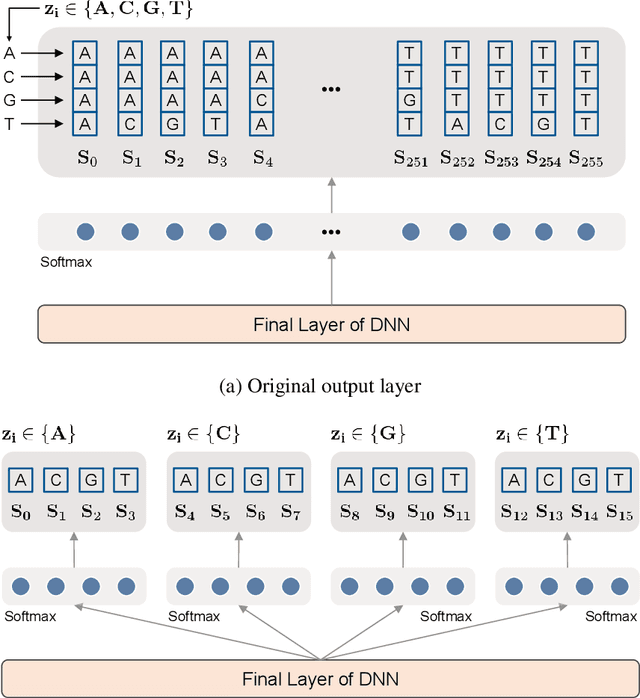
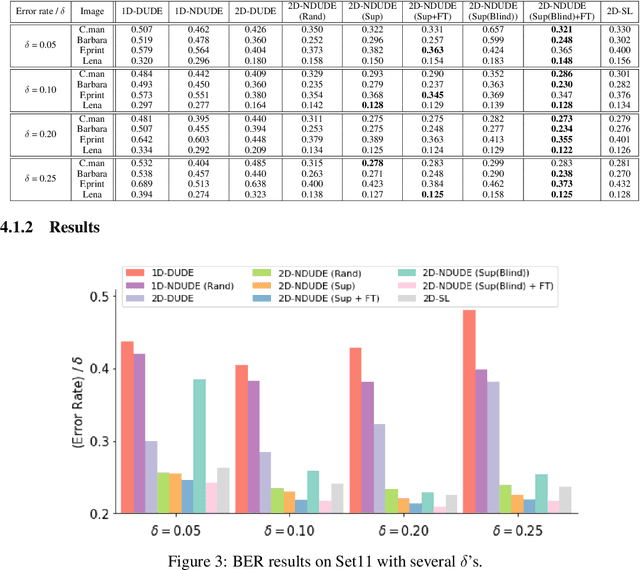
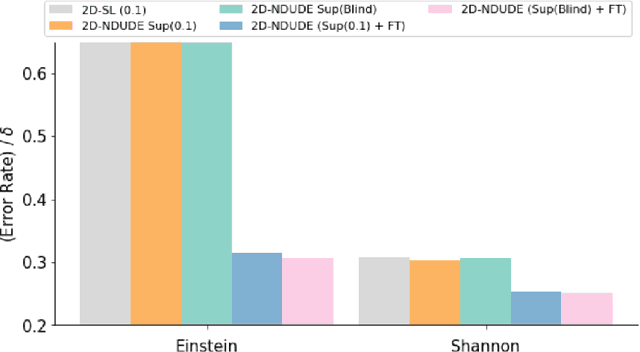
We improve the recently developed Neural DUDE, a neural network-based adaptive discrete denoiser, by combining it with the supervised learning framework. Namely, we make the supervised pre-training of Neural DUDE compatible with the adaptive fine-tuning of the parameters based on the given noisy data subject to denoising. As a result, we achieve a significant denoising performance boost compared to the vanilla Neural DUDE, which only carries out the adaptive fine-tuning step with randomly initialized parameters. Moreover, we show the adaptive fine-tuning makes the algorithm robust such that a noise-mismatched or blindly trained supervised model can still achieve the performance of that of the matched model. Furthermore, we make a few algorithmic advancements to make Neural DUDE more scalable and deal with multi-dimensional data or data with larger alphabet size. We systematically show our improvements on two very diverse datasets, binary images and DNA sequences.