 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSy-CON: Symmetric Contrastive Loss for Continual Self-Supervised Representation Learning
Jun 08, 2023We introduce a novel and general loss function, called Symmetric Contrastive (Sy-CON) loss, for effective continual self-supervised learning (CSSL). We first argue that the conventional loss form of continual learning which consists of single task-specific loss (for plasticity) and a regularizer (for stability) may not be ideal for contrastive loss based CSSL that focus on representation learning. Our reasoning is that, in contrastive learning based methods, the task-specific loss would suffer from decreasing diversity of negative samples and the regularizer may hinder learning new distinctive representations. To that end, we propose Sy-CON that consists of two losses (one for plasticity and the other for stability) with symmetric dependence on current and past models' negative sample embeddings. We argue our model can naturally find good trade-off between the plasticity and stability without any explicit hyperparameter tuning. We validate the effectiveness of our approach through extensive experiments, demonstrating that MoCo-based implementation of Sy-CON loss achieves superior performance compared to other state-of-the-art CSSL methods.
Learning to Unlearn: Instance-wise Unlearning for Pre-trained Classifiers
Jan 27, 2023



Since the recent advent of regulations for data protection (e.g., the General Data Protection Regulation), there has been increasing demand in deleting information learned from sensitive data in pre-trained models without retraining from scratch. The inherent vulnerability of neural networks towards adversarial attacks and unfairness also calls for a robust method to remove or correct information in an instance-wise fashion, while retaining the predictive performance across remaining data. To this end, we define instance-wise unlearning, of which the goal is to delete information on a set of instances from a pre-trained model, by either misclassifying each instance away from its original prediction or relabeling the instance to a different label. We also propose two methods that reduce forgetting on the remaining data: 1) utilizing adversarial examples to overcome forgetting at the representation-level and 2) leveraging weight importance metrics to pinpoint network parameters guilty of propagating unwanted information. Both methods only require the pre-trained model and data instances to forget, allowing painless application to real-life settings where the entire training set is unavailable. Through extensive experimentation on various image classification benchmarks, we show that our approach effectively preserves knowledge of remaining data while unlearning given instances in both single-task and continual unlearning scenarios.
Knowledge Unlearning for Mitigating Privacy Risks in Language Models
Oct 04, 2022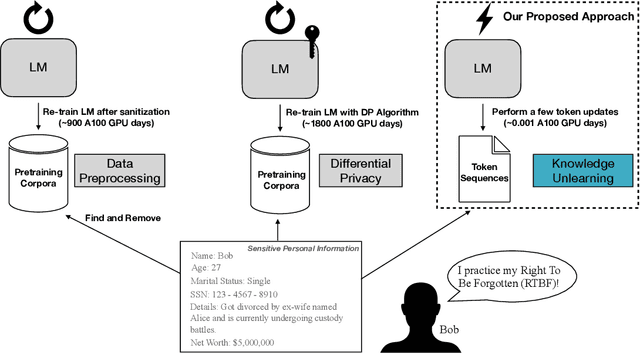
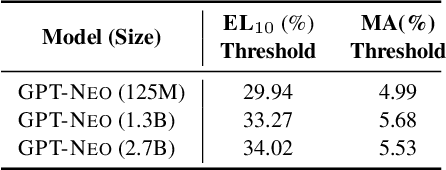
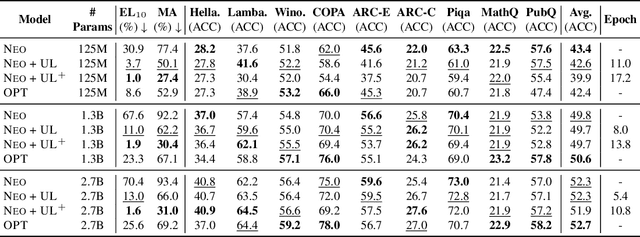
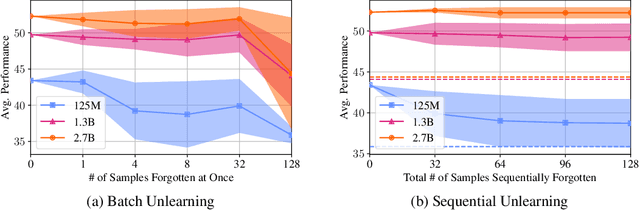
Pretrained Language Models (LMs) memorize a vast amount of knowledge during initial pretraining, including information that may violate the privacy of personal lives and identities. Previous work addressing privacy issues for language models has mostly focused on data preprocessing and differential privacy methods, both requiring re-training the underlying LM. We propose knowledge unlearning as an alternative method to reduce privacy risks for LMs post hoc. We show that simply applying the unlikelihood training objective to target token sequences is effective at forgetting them with little to no degradation of general language modeling performances; it sometimes even substantially improves the underlying LM with just a few iterations. We also find that sequential unlearning is better than trying to unlearn all the data at once and that unlearning is highly dependent on which kind of data (domain) is forgotten. By showing comparisons with a previous data preprocessing method known to mitigate privacy risks for LMs, we show that unlearning can give a stronger empirical privacy guarantee in scenarios where the data vulnerable to extraction attacks are known a priori while being orders of magnitude more computationally efficient. We release the code and dataset needed to replicate our results at https://github.com/joeljang/knowledge-unlearning .
Is Continual Learning Truly Learning Representations Continually?
Jun 16, 2022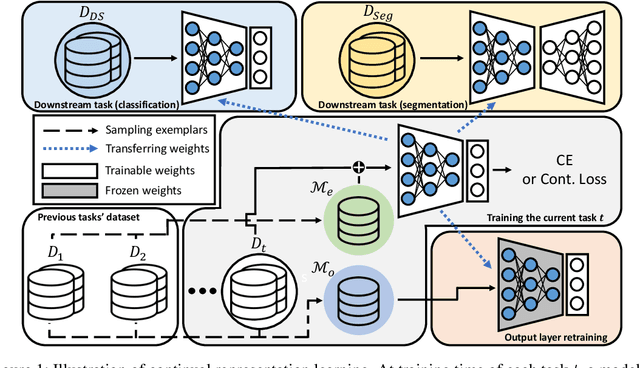
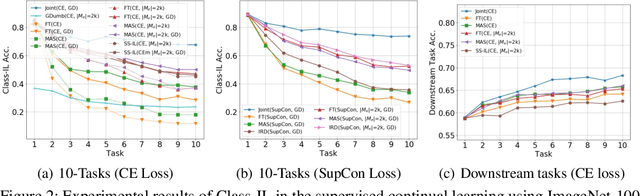
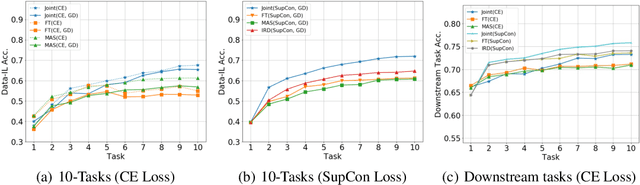
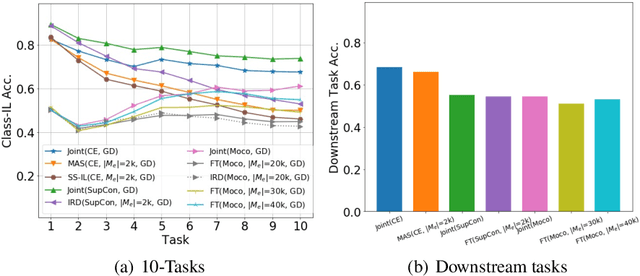
Continual learning (CL) aims to learn from sequentially arriving tasks without forgetting previous tasks. Whereas CL algorithms have tried to achieve higher average test accuracy across all the tasks learned so far, learning continuously useful representations is critical for successful generalization and downstream transfer. To measure representational quality, we re-train only the output layers using a small balanced dataset for all the tasks, evaluating the average accuracy without any biased predictions toward the current task. We also test on several downstream tasks, measuring transfer learning accuracy of the learned representations. By testing our new formalism on ImageNet-100 and ImageNet-1000, we find that using more exemplar memory is the only option to make a meaningful difference in learned representations, and most of the regularization- or distillation-based CL algorithms that use the exemplar memory fail to learn continuously useful representations in class-incremental learning. Surprisingly, unsupervised (or self-supervised) CL with sufficient memory size can achieve comparable performance to the supervised counterparts. Considering non-trivial labeling costs, we claim that finding more efficient unsupervised CL algorithms that minimally use exemplary memory would be the next promising direction for CL research.
Task-Balanced Batch Normalization for Exemplar-based Class-Incremental Learning
Jan 29, 2022Batch Normalization (BN) is an essential layer for training neural network models in various computer vision tasks. It has been widely used in continual learning scenarios with little discussion, but we find that BN should be carefully applied, particularly for the exemplar memory based class incremental learning (CIL). We first analyze that the empirical mean and variance obtained for normalization in a BN layer become highly biased toward the current task. To tackle its significant problems in training and test phases, we propose Task-Balanced Batch Normalization (TBBN). Given each mini-batch imbalanced between the current and previous tasks, TBBN first reshapes and repeats the batch, calculating near task-balanced mean and variance. Second, we show that when the affine transformation parameters of BN are learned from a reshaped feature map, they become less-biased toward the current task. Based on our extensive CIL experiments with CIFAR-100 and ImageNet-100 datasets, we demonstrate that our TBBN is easily applicable to most of existing exemplar-based CIL algorithms, improving their performance by decreasing the forgetting on the previous tasks.
Supervised Neural Discrete Universal Denoiser for Adaptive Denoising
Nov 24, 2021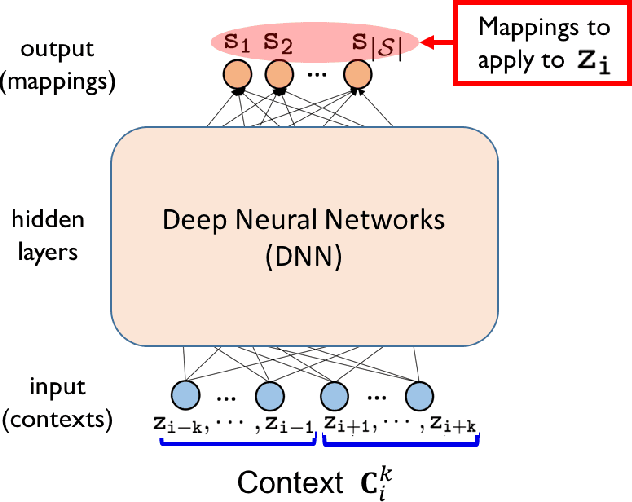
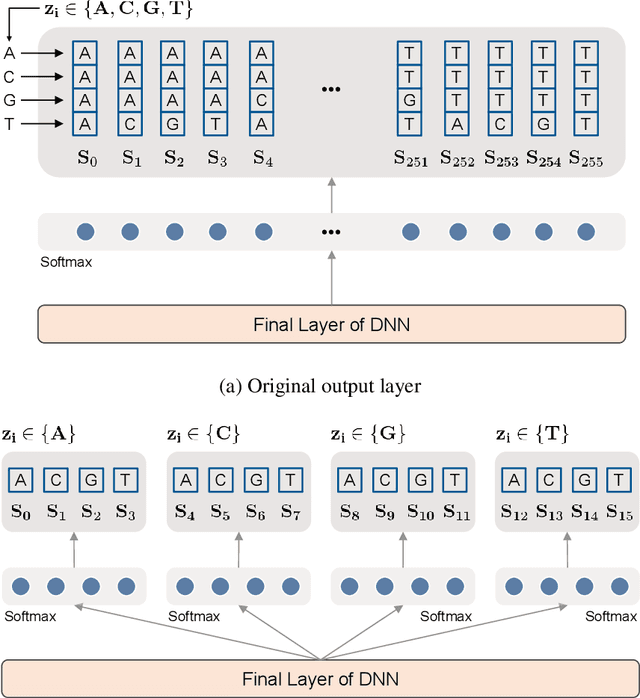
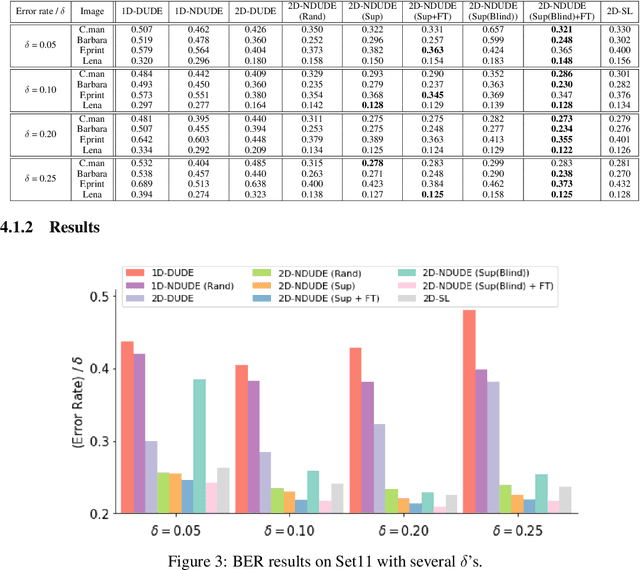
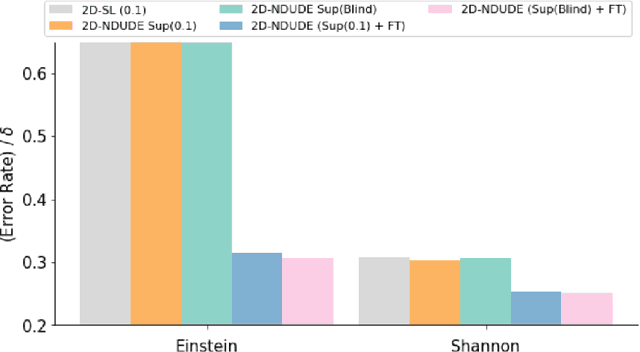
We improve the recently developed Neural DUDE, a neural network-based adaptive discrete denoiser, by combining it with the supervised learning framework. Namely, we make the supervised pre-training of Neural DUDE compatible with the adaptive fine-tuning of the parameters based on the given noisy data subject to denoising. As a result, we achieve a significant denoising performance boost compared to the vanilla Neural DUDE, which only carries out the adaptive fine-tuning step with randomly initialized parameters. Moreover, we show the adaptive fine-tuning makes the algorithm robust such that a noise-mismatched or blindly trained supervised model can still achieve the performance of that of the matched model. Furthermore, we make a few algorithmic advancements to make Neural DUDE more scalable and deal with multi-dimensional data or data with larger alphabet size. We systematically show our improvements on two very diverse datasets, binary images and DNA sequences.
Observations on K-image Expansion of Image-Mixing Augmentation for Classification
Oct 08, 2021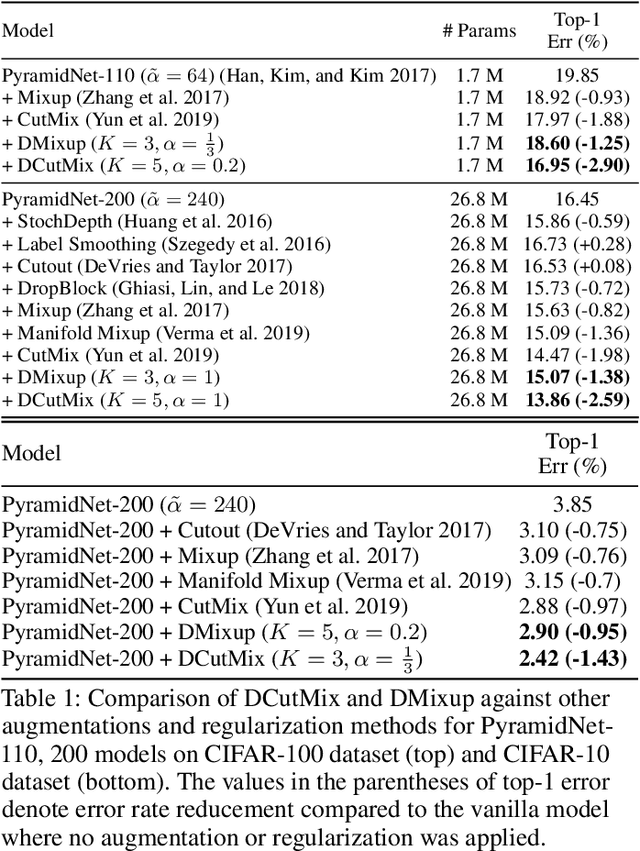
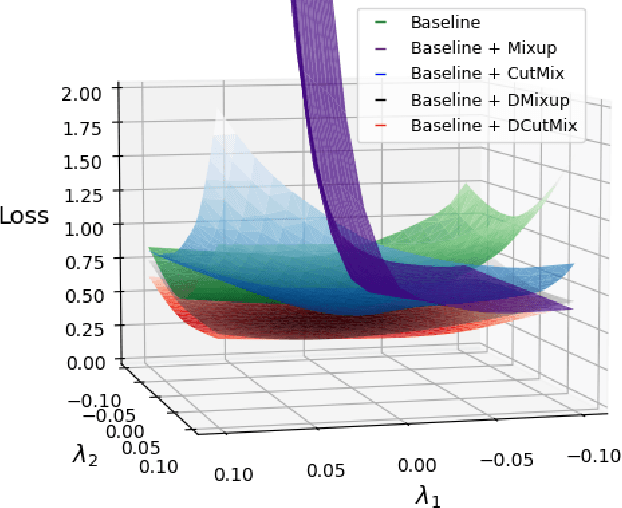

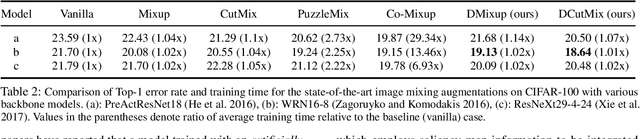
Image-mixing augmentations (e.g., Mixup or CutMix), which typically mix two images, have become de-facto training tricks for image classification. Despite their huge success on image classification, the number of images to mix has not been profoundly investigated by the previous works, only showing the naive K-image expansion leads to poor performance degradation. This paper derives a new K-image mixing augmentation based on the stick-breaking process under Dirichlet prior. We show that our method can train more robust and generalized classifiers through extensive experiments and analysis on classification accuracy, a shape of a loss landscape and adversarial robustness, than the usual two-image methods. Furthermore, we show that our probabilistic model can measure the sample-wise uncertainty and can boost the efficiency for Network Architecture Search (NAS) with 7x reduced search time.
SSUL: Semantic Segmentation with Unknown Label for Exemplar-based Class-Incremental Learning
Jul 01, 2021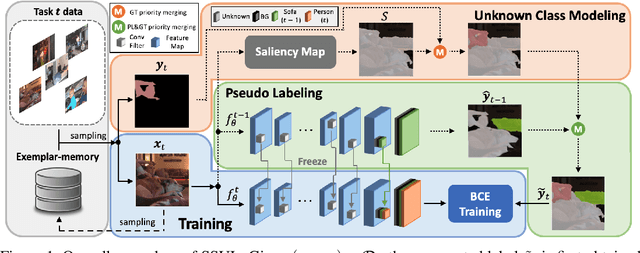


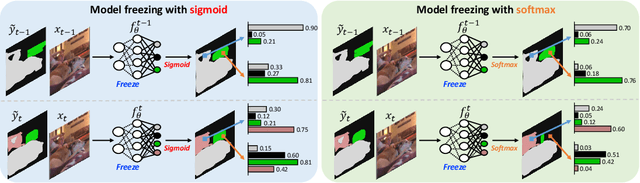
We consider a class-incremental semantic segmentation (CISS) problem. While some recently proposed algorithms utilized variants of knowledge distillation (KD) technique to tackle the problem, they only partially addressed the key additional challenges in CISS that causes the catastrophic forgetting; i.e., the semantic drift of the background class and multi-label prediction issue. To better address these challenges, we propose a new method, dubbed as SSUL-M (Semantic Segmentation with Unknown Label with Memory), by carefully combining several techniques tailored for semantic segmentation. More specifically, we make three main contributions; (1) modeling unknown class within the background class to help learning future classes (help plasticity), (2) freezing backbone network and past classifiers with binary cross-entropy loss and pseudo-labeling to overcome catastrophic forgetting (help stability), and (3) utilizing tiny exemplar memory for the first time in CISS to improve both plasticity and stability. As a result, we show our method achieves significantly better performance than the recent state-of-the-art baselines on the standard benchmark datasets. Furthermore, we justify our contributions with thorough and extensive ablation analyses and discuss different natures of the CISS problem compared to the standard class-incremental learning for classification.
Self-Supervised Iterative Contextual Smoothing for Efficient Adversarial Defense against Gray- and Black-Box Attack
Jun 22, 2021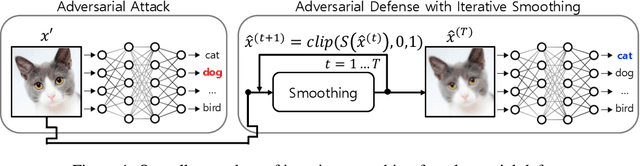
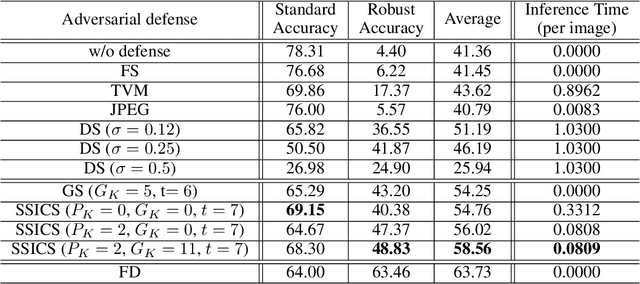
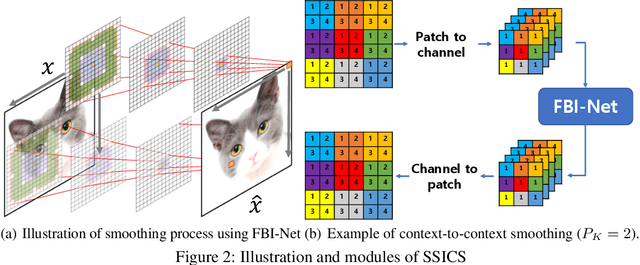
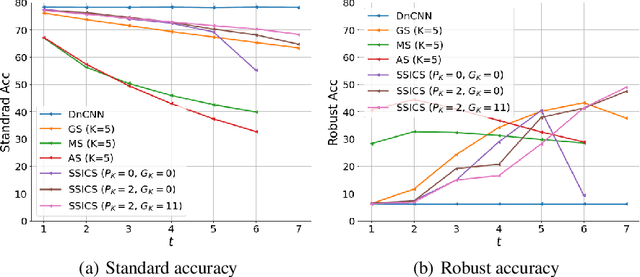
We propose a novel and effective input transformation based adversarial defense method against gray- and black-box attack, which is computationally efficient and does not require any adversarial training or retraining of a classification model. We first show that a very simple iterative Gaussian smoothing can effectively wash out adversarial noise and achieve substantially high robust accuracy. Based on the observation, we propose Self-Supervised Iterative Contextual Smoothing (SSICS), which aims to reconstruct the original discriminative features from the Gaussian-smoothed image in context-adaptive manner, while still smoothing out the adversarial noise. From the experiments on ImageNet, we show that our SSICS achieves both high standard accuracy and very competitive robust accuracy for the gray- and black-box attacks; e.g., transfer-based PGD-attack and score-based attack. A note-worthy point to stress is that our defense is free of computationally expensive adversarial training, yet, can approach its robust accuracy via input transformation.
FBI-Denoiser: Fast Blind Image Denoiser for Poisson-Gaussian Noise
May 23, 2021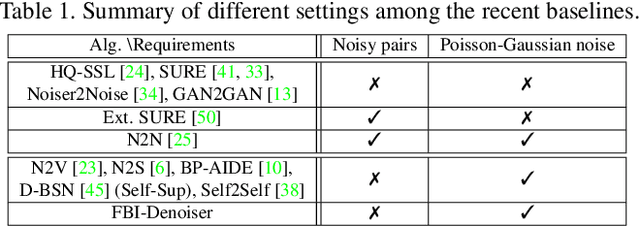
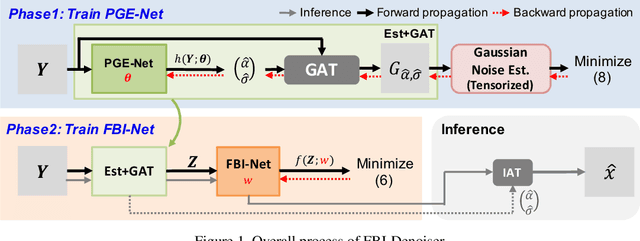
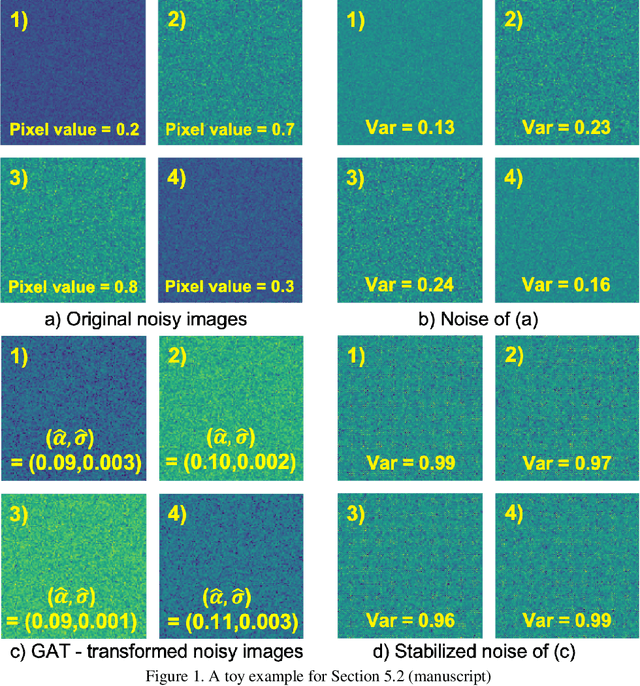
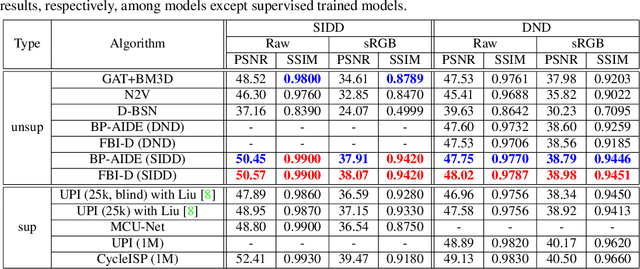
We consider the challenging blind denoising problem for Poisson-Gaussian noise, in which no additional information about clean images or noise level parameters is available. Particularly, when only "single" noisy images are available for training a denoiser, the denoising performance of existing methods was not satisfactory. Recently, the blind pixelwise affine image denoiser (BP-AIDE) was proposed and significantly improved the performance in the above setting, to the extent that it is competitive with denoisers which utilized additional information. However, BP-AIDE seriously suffered from slow inference time due to the inefficiency of noise level estimation procedure and that of the blind-spot network (BSN) architecture it used. To that end, we propose Fast Blind Image Denoiser (FBI-Denoiser) for Poisson-Gaussian noise, which consists of two neural network models; 1) PGE-Net that estimates Poisson-Gaussian noise parameters 2000 times faster than the conventional methods and 2) FBI-Net that realizes a much more efficient BSN for pixelwise affine denoiser in terms of the number of parameters and inference speed. Consequently, we show that our FBI-Denoiser blindly trained solely based on single noisy images can achieve the state-of-the-art performance on several real-world noisy image benchmark datasets with much faster inference time (x 10), compared to BP-AIDE. The official code of our method is available at https://github.com/csm9493/FBI-Denoiser.