 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Compound Domain Adaptation for Face Anti-Spoofing
May 18, 2021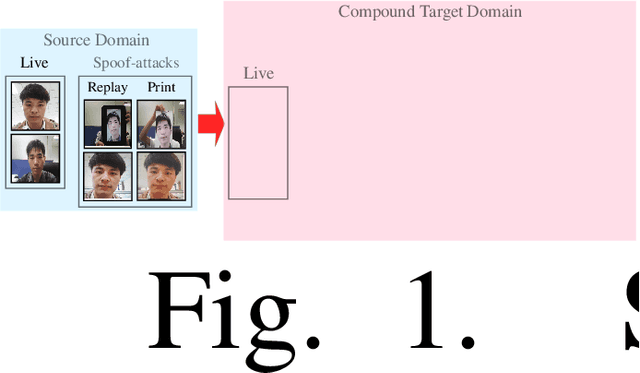
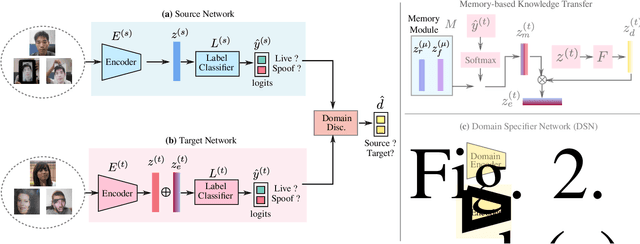
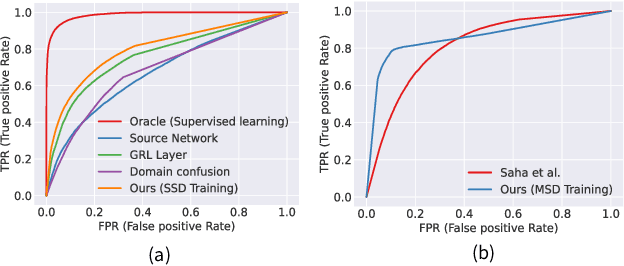
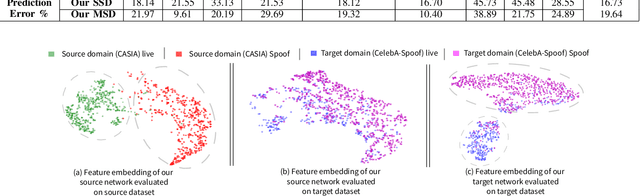
We address the problem of face anti-spoofing which aims to make the face verification systems robust in the real world settings. The context of detecting live vs. spoofed face images may differ significantly in the target domain, when compared to that of labeled source domain where the model is trained. Such difference may be caused due to new and unknown spoof types, illumination conditions, scene backgrounds, among many others. These varieties of differences make the target a compound domain, thus calling for the problem of the unsupervised compound domain adaptation. We demonstrate the effectiveness of the compound domain assumption for the task of face anti-spoofing, for the first time in this work. To this end, we propose a memory augmentation method for adapting the source model to the target domain in a domain aware manner. The adaptation process is further improved by using the curriculum learning and the domain agnostic source network training approaches. The proposed method successfully adapts to the compound target domain consisting multiple new spoof types. Our experiments on multiple benchmark datasets demonstrate the superiority of the proposed method over the state-of-the-art.
Learning to Relate Depth and Semantics for Unsupervised Domain Adaptation
May 17, 2021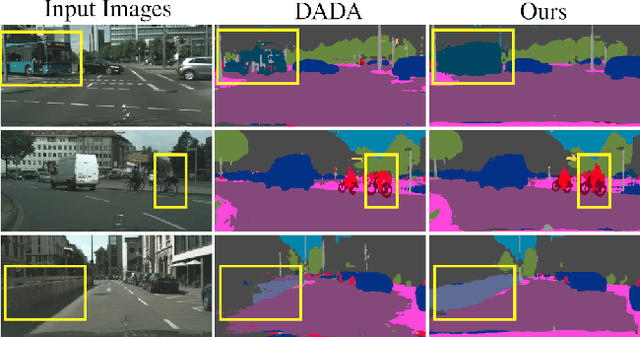
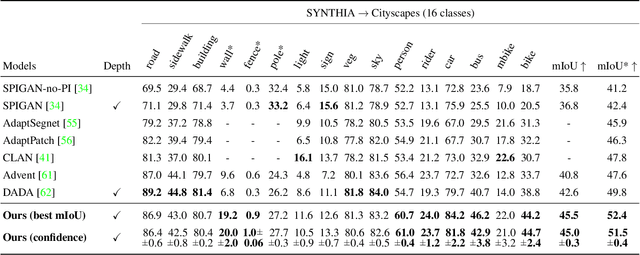

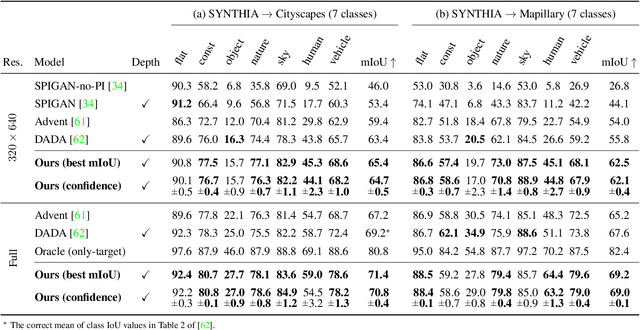
We present an approach for encoding visual task relationships to improve model performance in an Unsupervised Domain Adaptation (UDA) setting. Semantic segmentation and monocular depth estimation are shown to be complementary tasks; in a multi-task learning setting, a proper encoding of their relationships can further improve performance on both tasks. Motivated by this observation, we propose a novel Cross-Task Relation Layer (CTRL), which encodes task dependencies between the semantic and depth predictions. To capture the cross-task relationships, we propose a neural network architecture that contains task-specific and cross-task refinement heads. Furthermore, we propose an Iterative Self-Learning (ISL) training scheme, which exploits semantic pseudo-labels to provide extra supervision on the target domain. We experimentally observe improvements in both tasks' performance because the complementary information present in these tasks is better captured. Specifically, we show that: (1) our approach improves performance on all tasks when they are complementary and mutually dependent; (2) the CTRL helps to improve both semantic segmentation and depth estimation tasks performance in the challenging UDA setting; (3) the proposed ISL training scheme further improves the semantic segmentation performance. The implementation is available at https://github.com/susaha/ctrl-uda.
ROAD: The ROad event Awareness Dataset for Autonomous Driving
Feb 25, 2021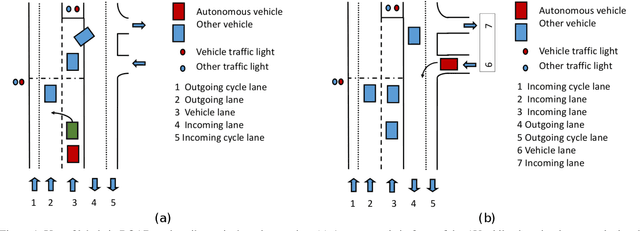

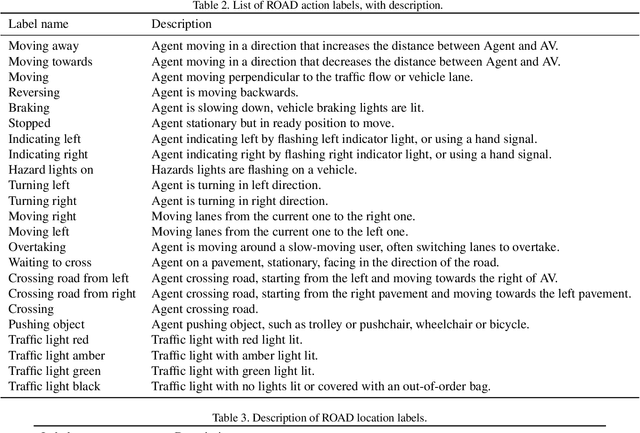

Humans approach driving in a holistic fashion which entails, in particular, understanding road events and their evolution. Injecting these capabilities in an autonomous vehicle has thus the potential to take situational awareness and decision making closer to human-level performance. To this purpose, we introduce the ROad event Awareness Dataset (ROAD) for Autonomous Driving, to our knowledge the first of its kind. ROAD is designed to test an autonomous vehicle's ability to detect road events, defined as triplets composed by a moving agent, the action(s) it performs and the corresponding scene locations. ROAD comprises 22 videos, originally from the Oxford RobotCar Dataset, annotated with bounding boxes showing the location in the image plane of each road event. We also provide as baseline a new incremental algorithm for online road event awareness, based on inflating RetinaNet along time, which achieves a mean average precision of 16.8% and 6.1% for frame-level and video-level event detection, respectively, at 50% overlap. Though promising, these figures highlight the challenges faced by situation awareness in autonomous driving. Finally, ROAD allows scholars to investigate exciting tasks such as complex (road) activity detection, future road event anticipation and the modelling of sentient road agents in terms of mental states. Dataset can be obtained from https://github.com/gurkirt/road-dataset and baseline code from https://github.com/gurkirt/3D-RetinaNet.
Three Ways to Improve Semantic Segmentation with Self-Supervised Depth Estimation
Dec 19, 2020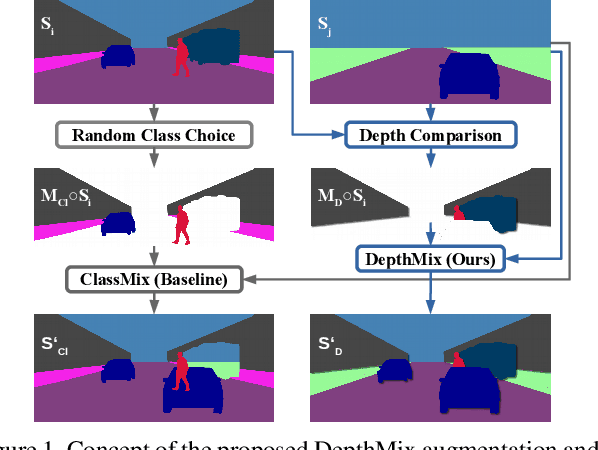
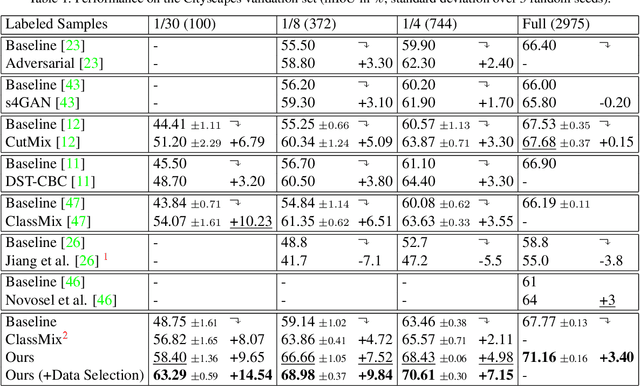
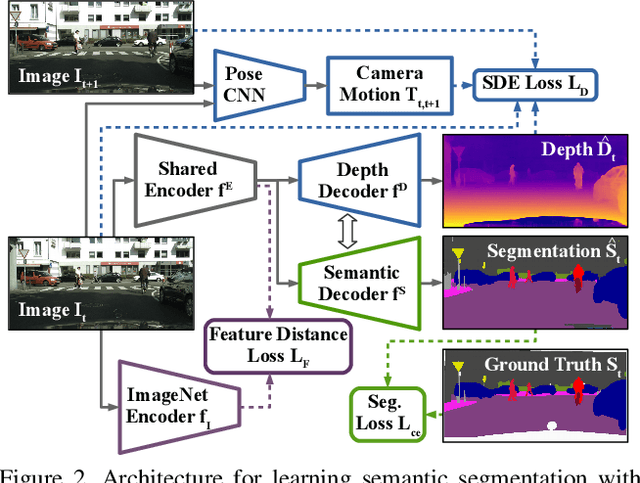
Training deep networks for semantic segmentation requires large amounts of labeled training data, which presents a major challenge in practice, as labeling segmentation masks is a highly labor-intensive process. To address this issue, we present a framework for semi-supervised semantic segmentation, which is enhanced by self-supervised monocular depth estimation from unlabeled images. In particular, we propose three key contributions: (1) We transfer knowledge from features learned during self-supervised depth estimation to semantic segmentation, (2) we implement a strong data augmentation by blending images and labels using the structure of the scene, and (3) we utilize the depth feature diversity as well as the level of difficulty of learning depth in a student-teacher framework to select the most useful samples to be annotated for semantic segmentation. We validate the proposed model on the Cityscapes dataset, where all three modules demonstrate significant performance gains, and we achieve state-of-the-art results for semi-supervised semantic segmentation. The implementation is available at https://github.com/lhoyer/improving_segmentation_with_selfsupervised_depth.
Reparameterizing Convolutions for Incremental Multi-Task Learning without Task Interference
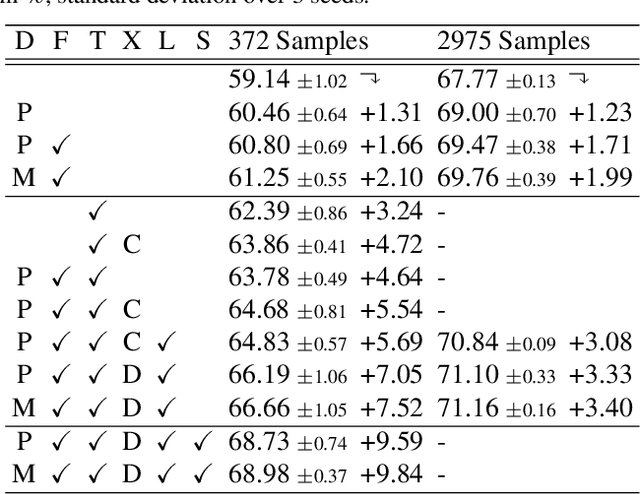
Jul 24, 2020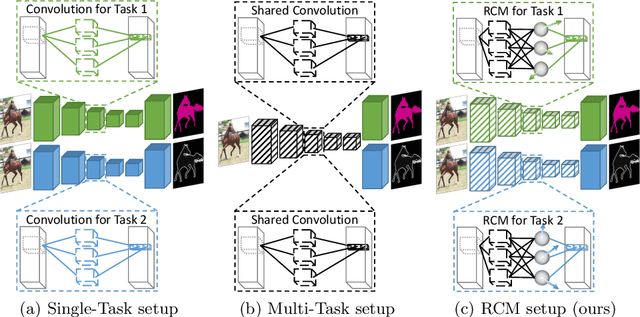

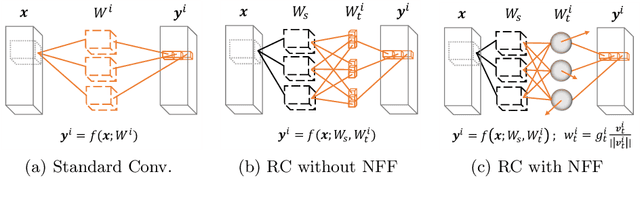
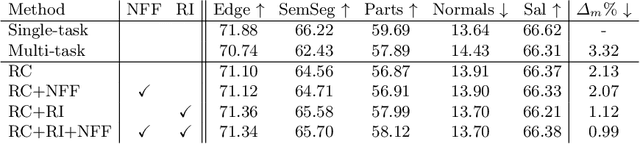
Multi-task networks are commonly utilized to alleviate the need for a large number of highly specialized single-task networks. However, two common challenges in developing multi-task models are often overlooked in literature. First, enabling the model to be inherently incremental, continuously incorporating information from new tasks without forgetting the previously learned ones (incremental learning). Second, eliminating adverse interactions amongst tasks, which has been shown to significantly degrade the single-task performance in a multi-task setup (task interference). In this paper, we show that both can be achieved simply by reparameterizing the convolutions of standard neural network architectures into a non-trainable shared part (filter bank) and task-specific parts (modulators), where each modulator has a fraction of the filter bank parameters. Thus, our reparameterization enables the model to learn new tasks without adversely affecting the performance of existing ones. The results of our ablation study attest the efficacy of the proposed reparameterization. Moreover, our method achieves state-of-the-art on two challenging multi-task learning benchmarks, PASCAL-Context and NYUD, and also demonstrates superior incremental learning capability as compared to its close competitors.
Two-Stream AMTnet for Action Detection
Apr 03, 2020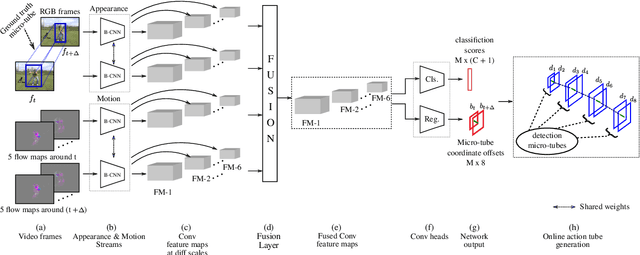
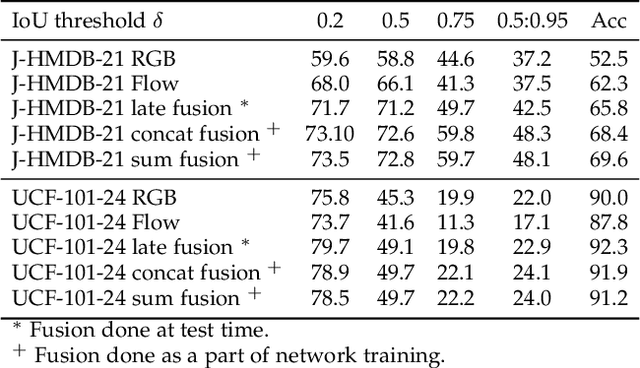
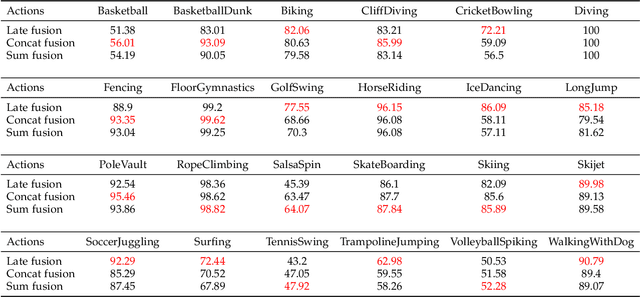
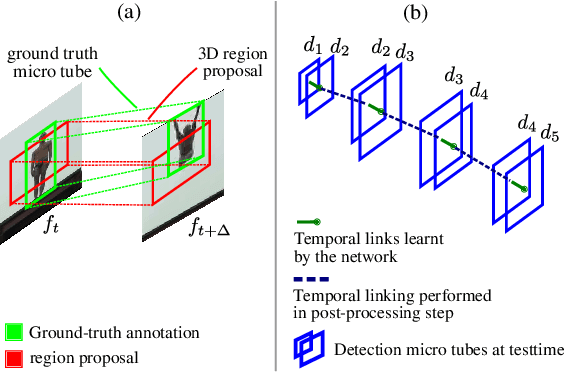
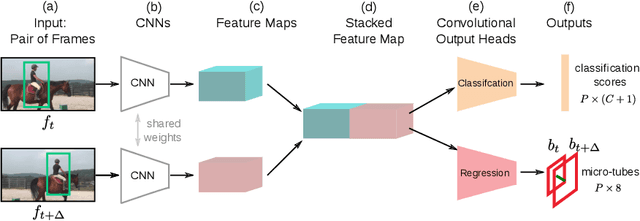
In this paper, we propose Two-Stream AMTnet, which leverages recent advances in video-based action representation[1] and incremental action tube generation[2]. Majority of the present action detectors follow a frame-based representation, a late-fusion followed by an offline action tube building steps. These are sub-optimal as: frame-based features barely encode the temporal relations; late-fusion restricts the network to learn robust spatiotemporal features; and finally, an offline action tube generation is not suitable for many real-world problems such as autonomous driving, human-robot interaction to name a few. The key contributions of this work are: (1) combining AMTnet's 3D proposal architecture with an online action tube generation technique which allows the model to learn stronger temporal features needed for accurate action detection and facilitates running inference online; (2) an efficient fusion technique allowing the deep network to learn strong spatiotemporal action representations. This is achieved by augmenting the previous Action Micro-Tube (AMTnet) action detection framework in three distinct ways: by adding a parallel motion stIn this paper, we propose a new deep neural network architecture for online action detection, termed ream to the original appearance one in AMTnet; (2) in opposition to state-of-the-art action detectors which train appearance and motion streams separately, and use a test time late fusion scheme to fuse RGB and flow cues, by jointly training both streams in an end-to-end fashion and merging RGB and optical flow features at training time; (3) by introducing an online action tube generation algorithm which works at video-level, and in real-time (when exploiting only appearance features). Two-Stream AMTnet exhibits superior action detection performance over state-of-the-art approaches on the standard action detection benchmarks.
Domain Agnostic Feature Learning for Image and Video Based Face Anti-spoofing
Dec 15, 2019
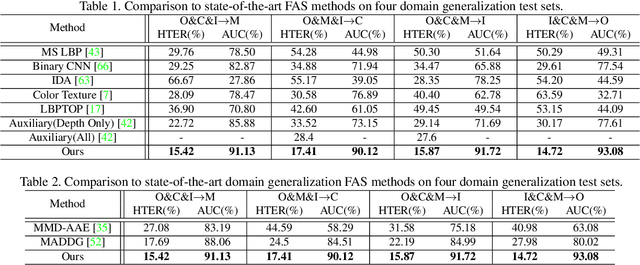
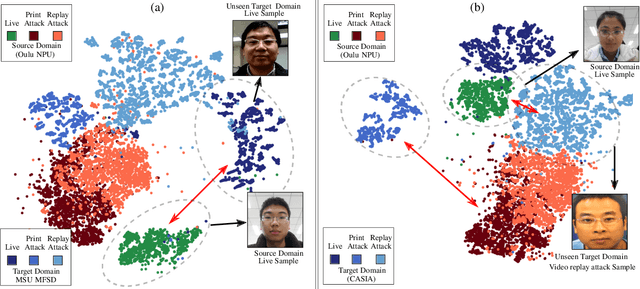
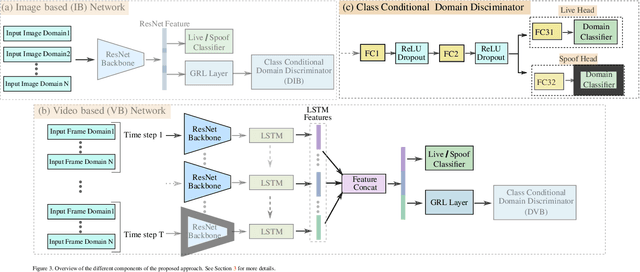
Nowadays, the increasingly growing number of mobile and computing devices has led to a demand for safer user authentication systems. Face anti-spoofing is a measure towards this direction for bio-metric user authentication, and in particular face recognition, that tries to prevent spoof attacks. The state-of-the-art anti-spoofing techniques leverage the ability of deep neural networks to learn discriminative features, based on cues from the training set images or video samples, in an effort to detect spoof attacks. However, due to the particular nature of the problem, i.e. large variability due to factors like different backgrounds, lighting conditions, camera resolutions, spoof materials, etc., these techniques typically fail to generalize to new samples. In this paper, we explicitly tackle this problem and propose a class-conditional domain discriminator module, that, coupled with a gradient reversal layer, tries to generate live and spoof features that are discriminative, but at the same time robust against the aforementioned variability factors. Extensive experimental analysis shows the effectiveness of the proposed method over existing image- and video-based anti-spoofing techniques, both in terms of numerical improvement as well as when visualizing the learned features.
Predicting Action Tubes
Aug 23, 2018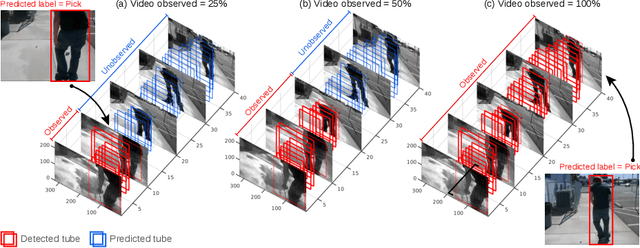
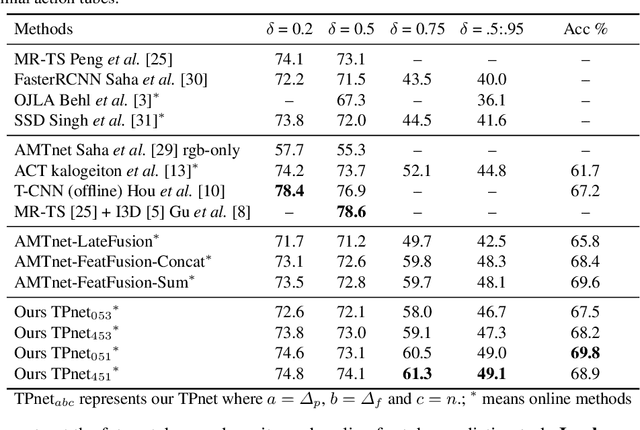
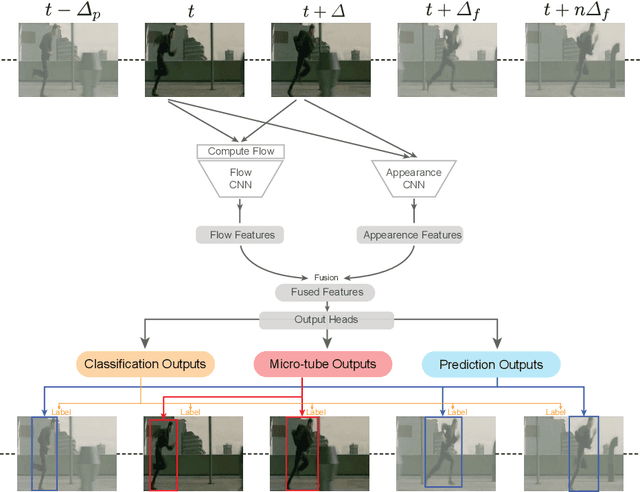
In this work, we present a method to predict an entire `action tube' (a set of temporally linked bounding boxes) in a trimmed video just by observing a smaller subset of it. Predicting where an action is going to take place in the near future is essential to many computer vision based applications such as autonomous driving or surgical robotics. Importantly, it has to be done in real-time and in an online fashion. We propose a Tube Prediction network (TPnet) which jointly predicts the past, present and future bounding boxes along with their action classification scores. At test time TPnet is used in a (temporal) sliding window setting, and its predictions are put into a tube estimation framework to construct/predict the video long action tubes not only for the observed part of the video but also for the unobserved part. Additionally, the proposed action tube predictor helps in completing action tubes for unobserved segments of the video. We quantitatively demonstrate the latter ability, and the fact that TPnet improves state-of-the-art detection performance, on one of the standard action detection benchmarks - J-HMDB-21 dataset.
TraMNet - Transition Matrix Network for Efficient Action Tube Proposals
Aug 01, 2018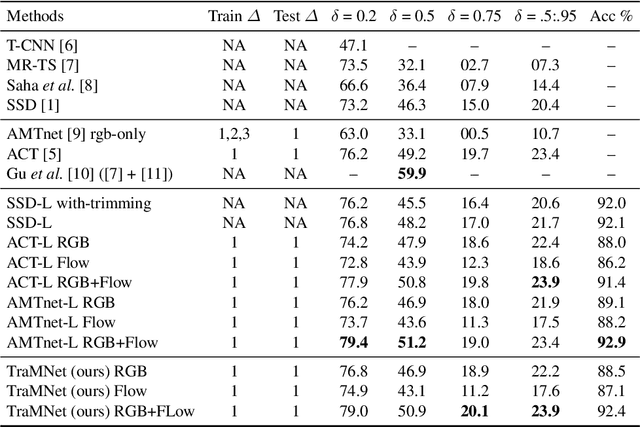
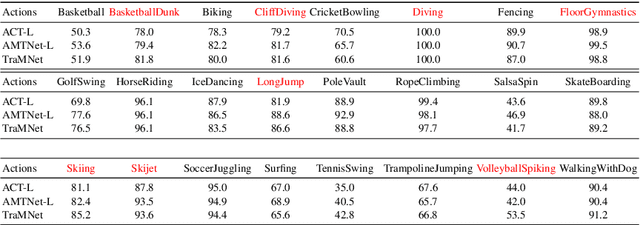
Current state-of-the-art methods solve spatiotemporal action localisation by extending 2D anchors to 3D-cuboid proposals on stacks of frames, to generate sets of temporally connected bounding boxes called \textit{action micro-tubes}. However, they fail to consider that the underlying anchor proposal hypotheses should also move (transition) from frame to frame, as the actor or the camera does. Assuming we evaluate $n$ 2D anchors in each frame, then the number of possible transitions from each 2D anchor to the next, for a sequence of $f$ consecutive frames, is in the order of $O(n^f)$, expensive even for small values of $f$. To avoid this problem, we introduce a Transition-Matrix-based Network (TraMNet) which relies on computing transition probabilities between anchor proposals while maximising their overlap with ground truth bounding boxes across frames, and enforcing sparsity via a transition threshold. As the resulting transition matrix is sparse and stochastic, this reduces the proposal hypothesis search space from $O(n^f)$ to the cardinality of the thresholded matrix. At training time, transitions are specific to cell locations of the feature maps, so that a sparse (efficient) transition matrix is used to train the network. At test time, a denser transition matrix can be obtained either by decreasing the threshold or by adding to it all the relative transitions originating from any cell location, allowing the network to handle transitions in the test data that might not have been present in the training data, and making detection translation-invariant. Finally, we show that our network can handle sparse annotations such as those available in the DALY dataset. We report extensive experiments on the DALY, UCF101-24 and Transformed-UCF101-24 datasets to support our claims.
Action Detection from a Robot-Car Perspective
Jul 30, 2018
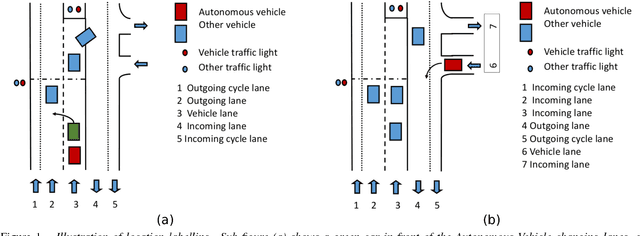

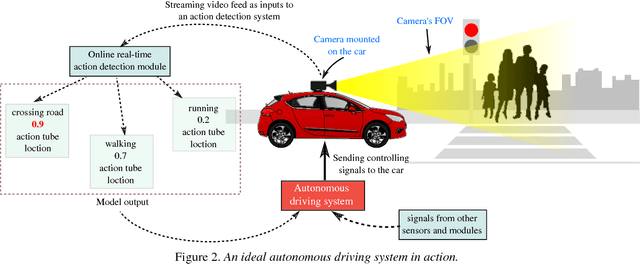
We present the new Road Event and Activity Detection (READ) dataset, designed and created from an autonomous vehicle perspective to take action detection challenges to autonomous driving. READ will give scholars in computer vision, smart cars and machine learning at large the opportunity to conduct research into exciting new problems such as understanding complex (road) activities, discerning the behaviour of sentient agents, and predicting both the label and the location of future actions and events, with the final goal of supporting autonomous decision making.