 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Optimization for Multi-Camera 3D Detection and Tracking
Feb 03, 2026Outside-in multi-camera perception is increasingly important in indoor environments, where networks of static cameras must support multi-target tracking under occlusion and heterogeneous viewpoints. We evaluate Sparse4D, a query-based spatiotemporal 3D detection and tracking framework that fuses multi-view features in a shared world frame and propagates sparse object queries via instance memory. We study reduced input frame rates, post-training quantization (INT8 and FP8), transfer to the WILDTRACK benchmark, and Transformer Engine mixed-precision fine-tuning. To better capture identity stability, we report Average Track Duration (AvgTrackDur), which measures identity persistence in seconds. Sparse4D remains stable under moderate FPS reductions, but below 2 FPS, identity association collapses even when detections are stable. Selective quantization of the backbone and neck offers the best speed-accuracy trade-off, while attention-related modules are consistently sensitive to low precision. On WILDTRACK, low-FPS pretraining yields large zero-shot gains over the base checkpoint, while small-scale fine-tuning provides limited additional benefit. Transformer Engine mixed precision reduces latency and improves camera scalability, but can destabilize identity propagation, motivating stability-aware validation.
A Unified 3D Object Perception Framework for Real-Time Outside-In Multi-Camera Systems
Jan 15, 2026Accurate 3D object perception and multi-target multi-camera (MTMC) tracking are fundamental for the digital transformation of industrial infrastructure. However, transitioning "inside-out" autonomous driving models to "outside-in" static camera networks presents significant challenges due to heterogeneous camera placements and extreme occlusion. In this paper, we present an adapted Sparse4D framework specifically optimized for large-scale infrastructure environments. Our system leverages absolute world-coordinate geometric priors and introduces an occlusion-aware ReID embedding module to maintain identity stability across distributed sensor networks. To bridge the Sim2Real domain gap without manual labeling, we employ a generative data augmentation strategy using the NVIDIA COSMOS framework, creating diverse environmental styles that enhance the model's appearance-invariance. Evaluated on the AI City Challenge 2025 benchmark, our camera-only framework achieves a state-of-the-art HOTA of $45.22$. Furthermore, we address real-time deployment constraints by developing an optimized TensorRT plugin for Multi-Scale Deformable Aggregation (MSDA). Our hardware-accelerated implementation achieves a $2.15\times$ speedup on modern GPU architectures, enabling a single Blackwell-class GPU to support over 64 concurrent camera streams.
BEV-SUSHI: Multi-Target Multi-Camera 3D Detection and Tracking in Bird's-Eye View
Dec 01, 2024



Object perception from multi-view cameras is crucial for intelligent systems, particularly in indoor environments, e.g., warehouses, retail stores, and hospitals. Most traditional multi-target multi-camera (MTMC) detection and tracking methods rely on 2D object detection, single-view multi-object tracking (MOT), and cross-view re-identification (ReID) techniques, without properly handling important 3D information by multi-view image aggregation. In this paper, we propose a 3D object detection and tracking framework, named BEV-SUSHI, which first aggregates multi-view images with necessary camera calibration parameters to obtain 3D object detections in bird's-eye view (BEV). Then, we introduce hierarchical graph neural networks (GNNs) to track these 3D detections in BEV for MTMC tracking results. Unlike existing methods, BEV-SUSHI has impressive generalizability across different scenes and diverse camera settings, with exceptional capability for long-term association handling. As a result, our proposed BEV-SUSHI establishes the new state-of-the-art on the AICity'24 dataset with 81.22 HOTA, and 95.6 IDF1 on the WildTrack dataset.
MpoxSLDNet: A Novel CNN Model for Detecting Monkeypox Lesions and Performance Comparison with Pre-trained Models
May 31, 2024



Monkeypox virus (MPXV) is a zoonotic virus that poses a significant threat to public health, particularly in remote parts of Central and West Africa. Early detection of monkeypox lesions is crucial for effective treatment. However, due to its similarity with other skin diseases, monkeypox lesion detection is a challenging task. To detect monkeypox, many researchers used various deep-learning models such as MobileNetv2, VGG16, ResNet50, InceptionV3, DenseNet121, EfficientNetB3, MobileNetV2, and Xception. However, these models often require high storage space due to their large size. This study aims to improve the existing challenges by introducing a CNN model named MpoxSLDNet (Monkeypox Skin Lesion Detector Network) to facilitate early detection and categorization of Monkeypox lesions and Non-Monkeypox lesions in digital images. Our model represents a significant advancement in the field of monkeypox lesion detection by offering superior performance metrics, including precision, recall, F1-score, accuracy, and AUC, compared to traditional pre-trained models such as VGG16, ResNet50, and DenseNet121. The key novelty of our approach lies in MpoxSLDNet's ability to achieve high detection accuracy while requiring significantly less storage space than existing models. By addressing the challenge of high storage requirements, MpoxSLDNet presents a practical solution for early detection and categorization of monkeypox lesions in resource-constrained healthcare settings. In this study, we have used "Monkeypox Skin Lesion Dataset" comprising 1428 skin images of monkeypox lesions and 1764 skin images of Non-Monkeypox lesions. Dataset's limitations could potentially impact the model's ability to generalize to unseen cases. However, the MpoxSLDNet model achieved a validation accuracy of 94.56%, compared to 86.25%, 84.38%, and 67.19% for VGG16, DenseNet121, and ResNet50, respectively.
The 8th AI City Challenge
Apr 15, 2024



The eighth AI City Challenge highlighted the convergence of computer vision and artificial intelligence in areas like retail, warehouse settings, and Intelligent Traffic Systems (ITS), presenting significant research opportunities. The 2024 edition featured five tracks, attracting unprecedented interest from 726 teams in 47 countries and regions. Track 1 dealt with multi-target multi-camera (MTMC) people tracking, highlighting significant enhancements in camera count, character number, 3D annotation, and camera matrices, alongside new rules for 3D tracking and online tracking algorithm encouragement. Track 2 introduced dense video captioning for traffic safety, focusing on pedestrian accidents using multi-camera feeds to improve insights for insurance and prevention. Track 3 required teams to classify driver actions in a naturalistic driving analysis. Track 4 explored fish-eye camera analytics using the FishEye8K dataset. Track 5 focused on motorcycle helmet rule violation detection. The challenge utilized two leaderboards to showcase methods, with participants setting new benchmarks, some surpassing existing state-of-the-art achievements.
Training with Product Digital Twins for AutoRetail Checkout
Aug 18, 2023



Automating the checkout process is important in smart retail, where users effortlessly pass products by hand through a camera, triggering automatic product detection, tracking, and counting. In this emerging area, due to the lack of annotated training data, we introduce a dataset comprised of product 3D models, which allows for fast, flexible, and large-scale training data generation through graphic engine rendering. Within this context, we discern an intriguing facet, because of the user "hands-on" approach, bias in user behavior leads to distinct patterns in the real checkout process. The existence of such patterns would compromise training effectiveness if training data fail to reflect the same. To address this user bias problem, we propose a training data optimization framework, i.e., training with digital twins (DtTrain). Specifically, we leverage the product 3D models and optimize their rendering viewpoint and illumination to generate "digital twins" that visually resemble representative user images. These digital twins, inherit product labels and, when augmented, form the Digital Twin training set (DT set). Because the digital twins individually mimic user bias, the resulting DT training set better reflects the characteristics of the target scenario and allows us to train more effective product detection and tracking models. In our experiment, we show that DT set outperforms training sets created by existing dataset synthesis methods in terms of counting accuracy. Moreover, by combining DT set with pseudo-labeled real checkout data, further improvement is observed. The code is available at https://github.com/yorkeyao/Automated-Retail-Checkout.
Impact Learning: A Learning Method from Features Impact and Competition
Nov 04, 2022
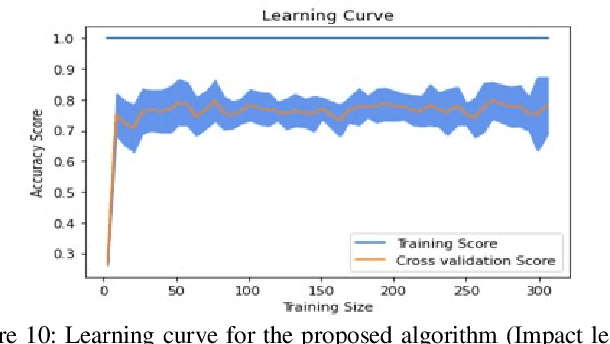
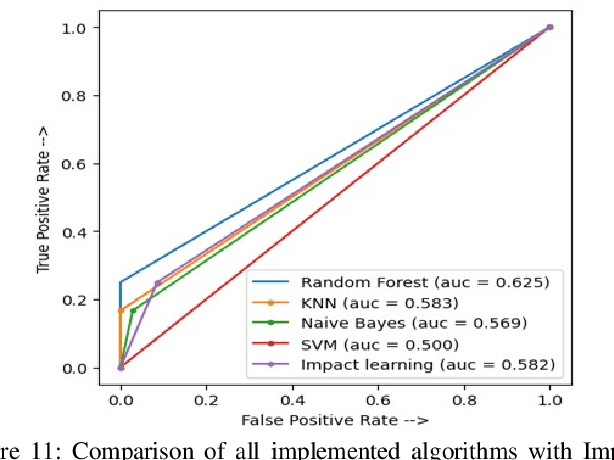
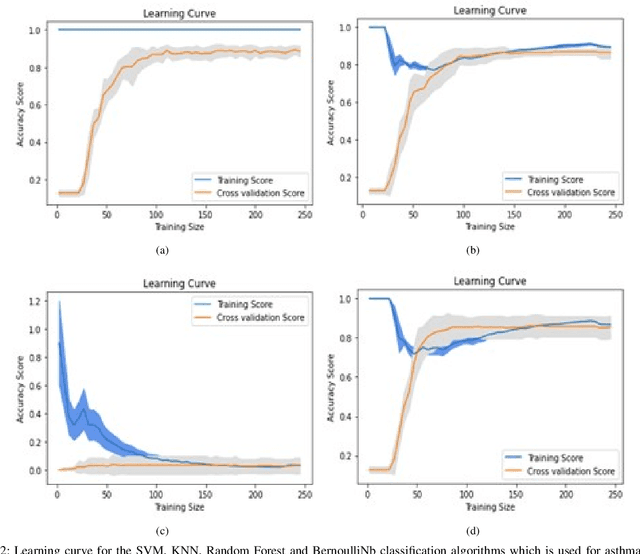
Machine learning is the study of computer algorithms that can automatically improve based on data and experience. Machine learning algorithms build a model from sample data, called training data, to make predictions or judgments without being explicitly programmed to do so. A variety of wellknown machine learning algorithms have been developed for use in the field of computer science to analyze data. This paper introduced a new machine learning algorithm called impact learning. Impact learning is a supervised learning algorithm that can be consolidated in both classification and regression problems. It can furthermore manifest its superiority in analyzing competitive data. This algorithm is remarkable for learning from the competitive situation and the competition comes from the effects of autonomous features. It is prepared by the impacts of the highlights from the intrinsic rate of natural increase (RNI). We, moreover, manifest the prevalence of the impact learning over the conventional machine learning algorithm.