 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe ORCA Hub: Explainable Offshore Robotics through Intelligent Interfaces
Mar 06, 2018
We present the UK Robotics and Artificial Intelligence Hub for Offshore Robotics for Certification of Assets (ORCA Hub), a 3.5 year EPSRC funded, multi-site project. The ORCA Hub vision is to use teams of robots and autonomous intelligent systems (AIS) to work on offshore energy platforms to enable cheaper, safer and more efficient working practices. The ORCA Hub will research, integrate, validate and deploy remote AIS solutions that can operate with existing and future offshore energy assets and sensors, interacting safely in autonomous or semi-autonomous modes in complex and cluttered environments, co-operating with remote operators. The goal is that through the use of such robotic systems offshore, the need for personnel will decrease. To enable this to happen, the remote operator will need a high level of situation awareness and key to this is the transparency of what the autonomous systems are doing and why. This increased transparency will facilitate a trusting relationship, which is particularly key in high-stakes, hazardous situations.
Reasoning about Unforeseen Possibilities During Policy Learning
Jan 10, 2018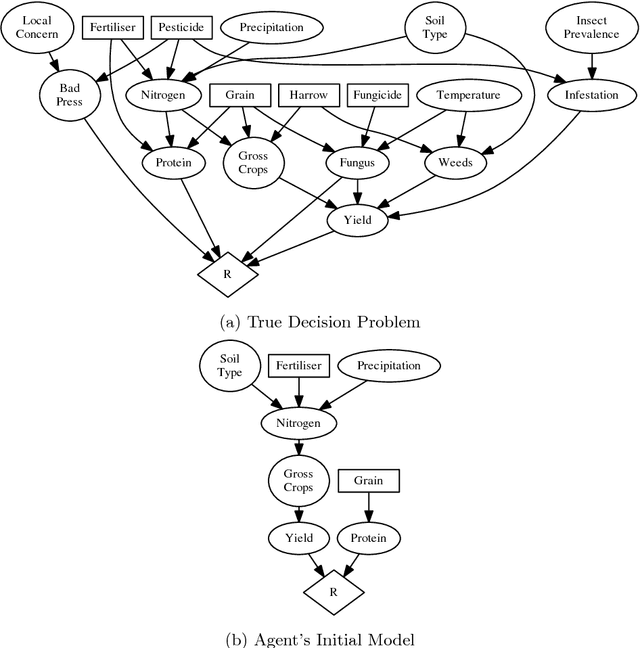
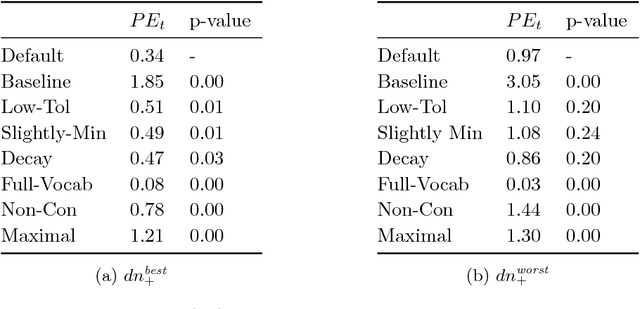
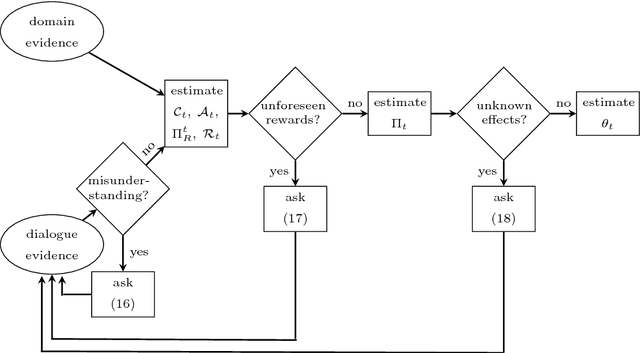
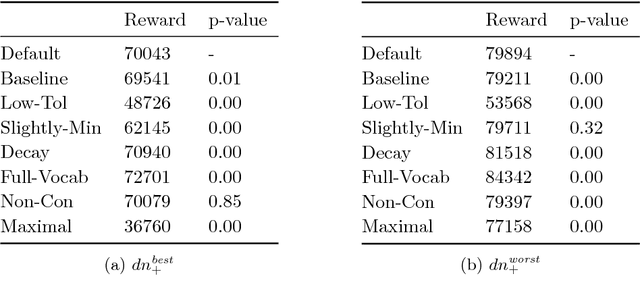
Methods for learning optimal policies in autonomous agents often assume that the way the domain is conceptualised---its possible states and actions and their causal structure---is known in advance and does not change during learning. This is an unrealistic assumption in many scenarios, because new evidence can reveal important information about what is possible, possibilities that the agent was not aware existed prior to learning. We present a model of an agent which both discovers and learns to exploit unforeseen possibilities using two sources of evidence: direct interaction with the world and communication with a domain expert. We use a combination of probabilistic and symbolic reasoning to estimate all components of the decision problem, including its set of random variables and their causal dependencies. Agent simulations show that the agent converges on optimal polices even when it starts out unaware of factors that are critical to behaving optimally.
Using Program Induction to Interpret Transition System Dynamics
Jul 26, 2017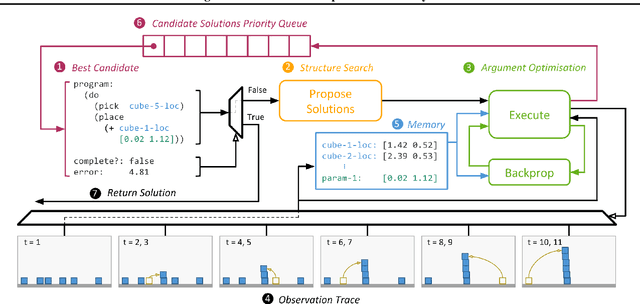
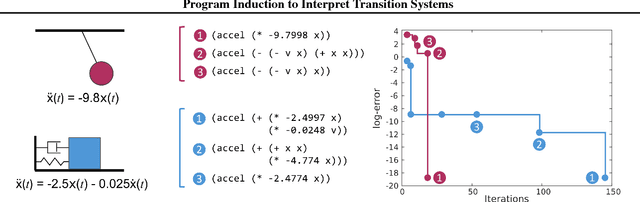
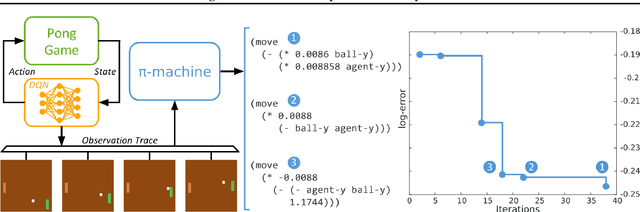
Explaining and reasoning about processes which underlie observed black-box phenomena enables the discovery of causal mechanisms, derivation of suitable abstract representations and the formulation of more robust predictions. We propose to learn high level functional programs in order to represent abstract models which capture the invariant structure in the observed data. We introduce the $\pi$-machine (program-induction machine) -- an architecture able to induce interpretable LISP-like programs from observed data traces. We propose an optimisation procedure for program learning based on backpropagation, gradient descent and A* search. We apply the proposed method to two problems: system identification of dynamical systems and explaining the behaviour of a DQN agent. Our results show that the $\pi$-machine can efficiently induce interpretable programs from individual data traces.
Grounding Symbols in Multi-Modal Instructions
Jun 01, 2017
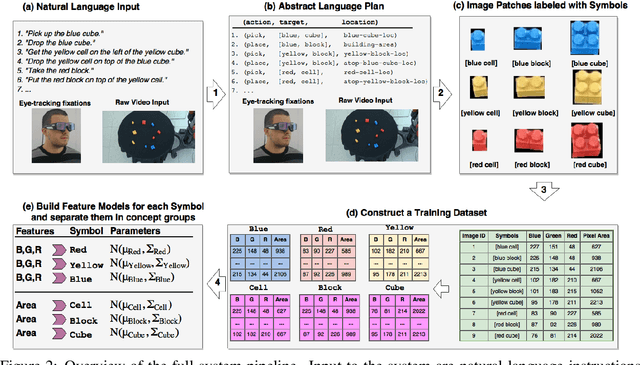
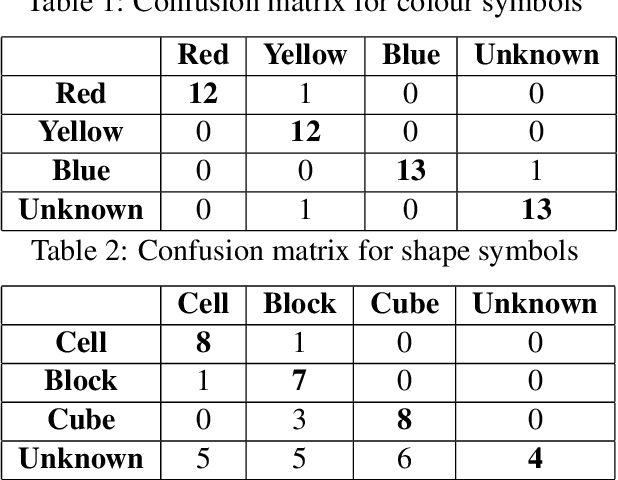
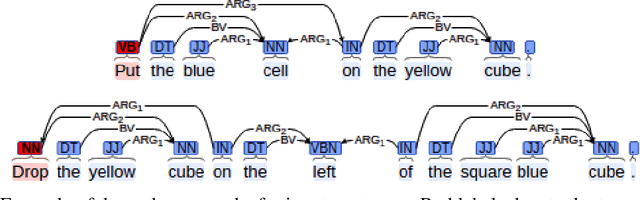
As robots begin to cohabit with humans in semi-structured environments, the need arises to understand instructions involving rich variability---for instance, learning to ground symbols in the physical world. Realistically, this task must cope with small datasets consisting of a particular users' contextual assignment of meaning to terms. We present a method for processing a raw stream of cross-modal input---i.e., linguistic instructions, visual perception of a scene and a concurrent trace of 3D eye tracking fixations---to produce the segmentation of objects with a correspondent association to high-level concepts. To test our framework we present experiments in a table-top object manipulation scenario. Our results show our model learns the user's notion of colour and shape from a small number of physical demonstrations, generalising to identifying physical referents for novel combinations of the words.
Explaining Transition Systems through Program Induction
May 23, 2017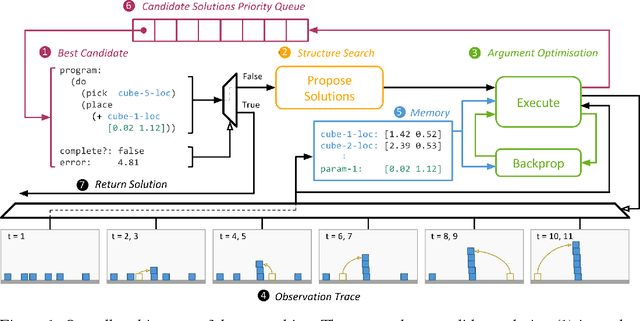

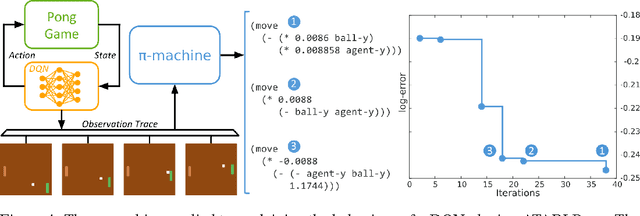

Explaining and reasoning about processes which underlie observed black-box phenomena enables the discovery of causal mechanisms, derivation of suitable abstract representations and the formulation of more robust predictions. We propose to learn high level functional programs in order to represent abstract models which capture the invariant structure in the observed data. We introduce the $\pi$-machine (program-induction machine) -- an architecture able to induce interpretable LISP-like programs from observed data traces. We propose an optimisation procedure for program learning based on backpropagation, gradient descent and A* search. We apply the proposed method to three problems: system identification of dynamical systems, explaining the behaviour of a DQN agent and learning by demonstration in a human-robot interaction scenario. Our experimental results show that the $\pi$-machine can efficiently induce interpretable programs from individual data traces.
Estimating Activity at Multiple Scales using Spatial Abstractions
Jul 25, 2016
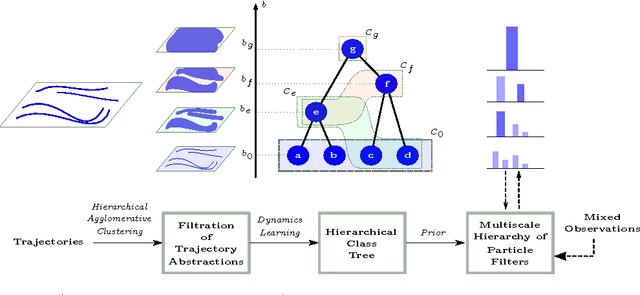
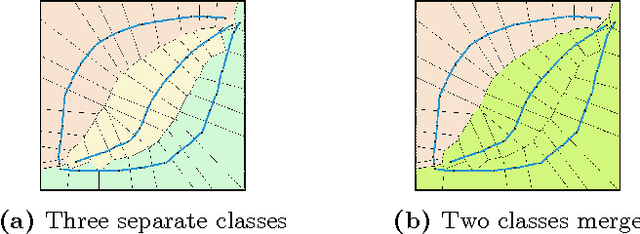

Autonomous robots operating in dynamic environments must maintain beliefs over a hypothesis space that is rich enough to represent the activities of interest at different scales. This is important both in order to accommodate the availability of evidence at varying degrees of coarseness, such as when interpreting and assimilating natural instructions, but also in order to make subsequent reactive planning more efficient. We present an algorithm that combines a topology-based trajectory clustering procedure that generates hierarchically-structured spatial abstractions with a bank of particle filters at each of these abstraction levels so as to produce probability estimates over an agent's navigation activity that is kept consistent across the hierarchy. We study the performance of the proposed method using a synthetic trajectory dataset in 2D, as well as a dataset taken from AIS-based tracking of ships in an extended harbour area. We show that, in comparison to a baseline which is a particle filter that estimates activity without exploiting such structure, our method achieves a better normalised error in predicting the trajectory as well as better time to convergence to a true class when compared against ground truth.
Clustering Markov Decision Processes For Continual Transfer
May 01, 2016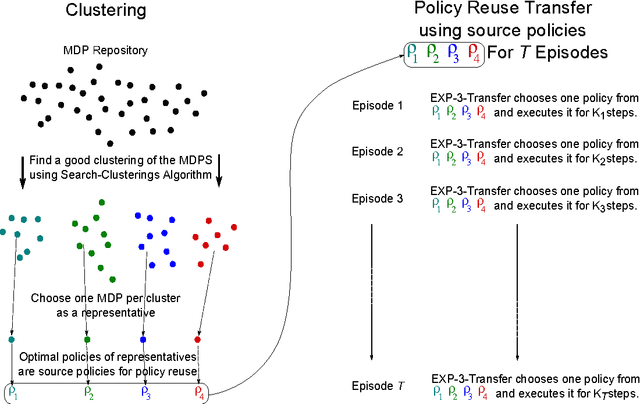

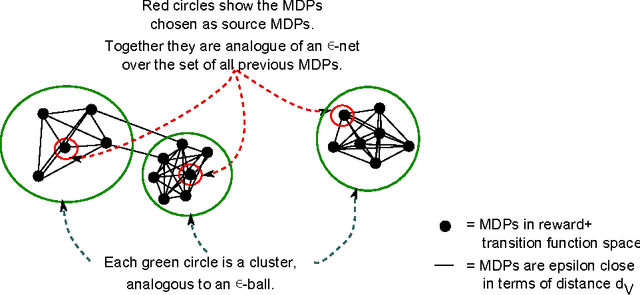

We present algorithms to effectively represent a set of Markov decision processes (MDPs), whose optimal policies have already been learned, by a smaller source subset for lifelong, policy-reuse-based transfer learning in reinforcement learning. This is necessary when the number of previous tasks is large and the cost of measuring similarity counteracts the benefit of transfer. The source subset forms an `$\epsilon$-net' over the original set of MDPs, in the sense that for each previous MDP $M_p$, there is a source $M^s$ whose optimal policy has $<\epsilon$ regret in $M_p$. Our contributions are as follows. We present EXP-3-Transfer, a principled policy-reuse algorithm that optimally reuses a given source policy set when learning for a new MDP. We present a framework to cluster the previous MDPs to extract a source subset. The framework consists of (i) a distance $d_V$ over MDPs to measure policy-based similarity between MDPs; (ii) a cost function $g(\cdot)$ that uses $d_V$ to measure how good a particular clustering is for generating useful source tasks for EXP-3-Transfer and (iii) a provably convergent algorithm, MHAV, for finding the optimal clustering. We validate our algorithms through experiments in a surveillance domain.
Exploiting Causality for Selective Belief Filtering in Dynamic Bayesian Networks
Apr 25, 2016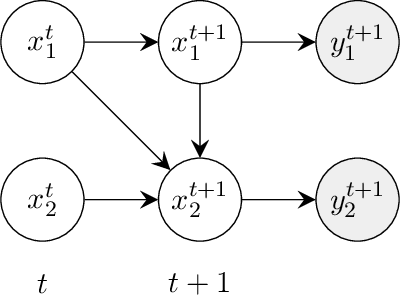

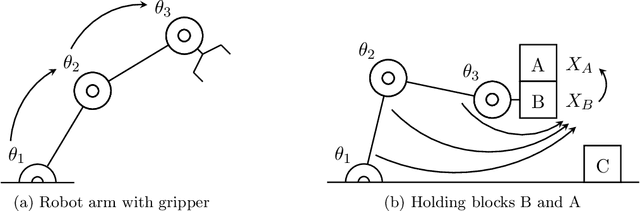
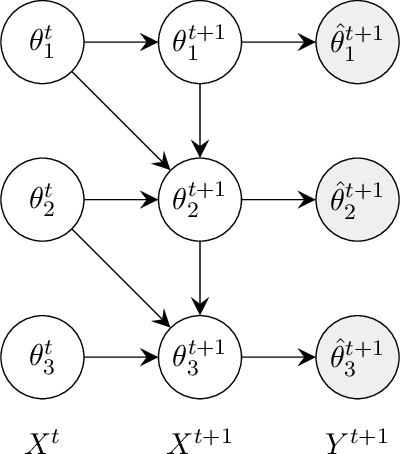
Dynamic Bayesian networks (DBNs) are a general model for stochastic processes with partially observed states. Belief filtering in DBNs is the task of inferring the belief state (i.e. the probability distribution over process states) based on incomplete and noisy observations. This can be a hard problem in complex processes with large state spaces. In this article, we explore the idea of accelerating the filtering task by automatically exploiting causality in the process. We consider a specific type of causal relation, called passivity, which pertains to how state variables cause changes in other variables. We present the Passivity-based Selective Belief Filtering (PSBF) method, which maintains a factored belief representation and exploits passivity to perform selective updates over the belief factors. PSBF produces exact belief states under certain assumptions and approximate belief states otherwise, where the approximation error is bounded by the degree of uncertainty in the process. We show empirically, in synthetic processes with varying sizes and degrees of passivity, that PSBF is faster than several alternative methods while achieving competitive accuracy. Furthermore, we demonstrate how passivity occurs naturally in a complex system such as a multi-robot warehouse, and how PSBF can exploit this to accelerate the filtering task.
Belief and Truth in Hypothesised Behaviours
Mar 02, 2016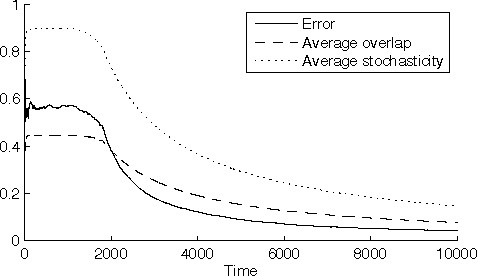
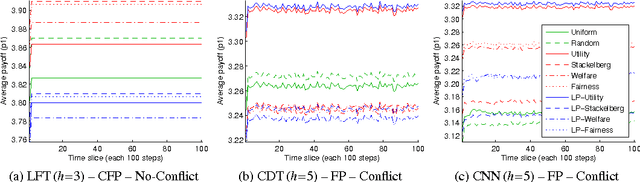
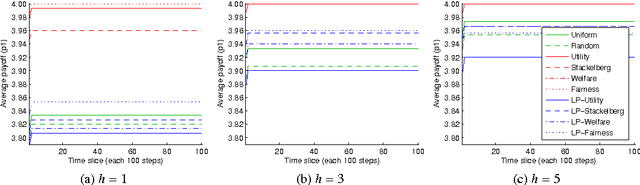
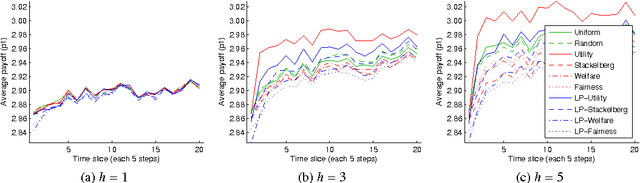
There is a long history in game theory on the topic of Bayesian or "rational" learning, in which each player maintains beliefs over a set of alternative behaviours, or types, for the other players. This idea has gained increasing interest in the artificial intelligence (AI) community, where it is used as a method to control a single agent in a system composed of multiple agents with unknown behaviours. The idea is to hypothesise a set of types, each specifying a possible behaviour for the other agents, and to plan our own actions with respect to those types which we believe are most likely, given the observed actions of the agents. The game theory literature studies this idea primarily in the context of equilibrium attainment. In contrast, many AI applications have a focus on task completion and payoff maximisation. With this perspective in mind, we identify and address a spectrum of questions pertaining to belief and truth in hypothesised types. We formulate three basic ways to incorporate evidence into posterior beliefs and show when the resulting beliefs are correct, and when they may fail to be correct. Moreover, we demonstrate that prior beliefs can have a significant impact on our ability to maximise payoffs in the long-term, and that they can be computed automatically with consistent performance effects. Furthermore, we analyse the conditions under which we are able complete our task optimally, despite inaccuracies in the hypothesised types. Finally, we show how the correctness of hypothesised types can be ascertained during the interaction via an automated statistical analysis.
Bayesian Policy Reuse
Dec 14, 2015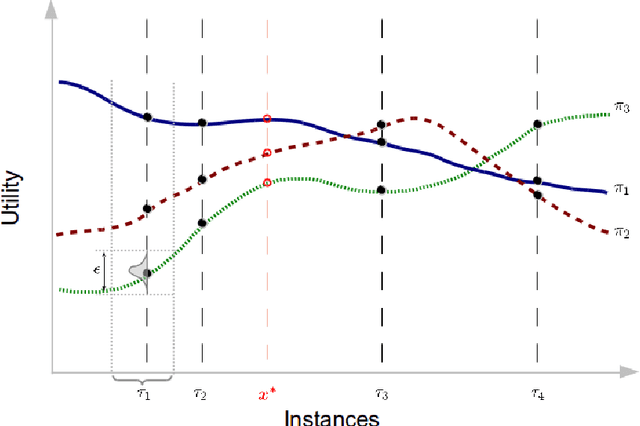
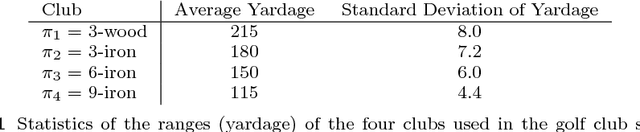
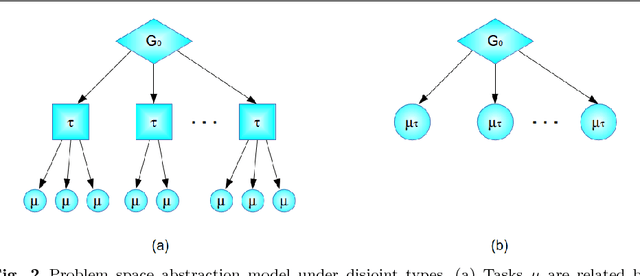
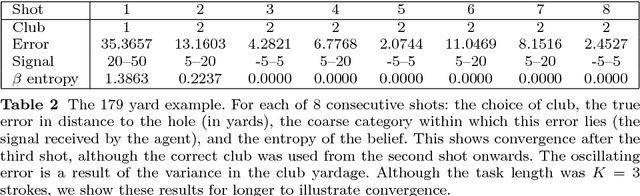
A long-lived autonomous agent should be able to respond online to novel instances of tasks from a familiar domain. Acting online requires 'fast' responses, in terms of rapid convergence, especially when the task instance has a short duration, such as in applications involving interactions with humans. These requirements can be problematic for many established methods for learning to act. In domains where the agent knows that the task instance is drawn from a family of related tasks, albeit without access to the label of any given instance, it can choose to act through a process of policy reuse from a library, rather than policy learning from scratch. In policy reuse, the agent has prior knowledge of the class of tasks in the form of a library of policies that were learnt from sample task instances during an offline training phase. We formalise the problem of policy reuse, and present an algorithm for efficiently responding to a novel task instance by reusing a policy from the library of existing policies, where the choice is based on observed 'signals' which correlate to policy performance. We achieve this by posing the problem as a Bayesian choice problem with a corresponding notion of an optimal response, but the computation of that response is in many cases intractable. Therefore, to reduce the computation cost of the posterior, we follow a Bayesian optimisation approach and define a set of policy selection functions, which balance exploration in the policy library against exploitation of previously tried policies, together with a model of expected performance of the policy library on their corresponding task instances. We validate our method in several simulated domains of interactive, short-duration episodic tasks, showing rapid convergence in unknown task variations.