 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-HBA: Using Action Policies for Expert Advice and Agent Typification
Jul 23, 2019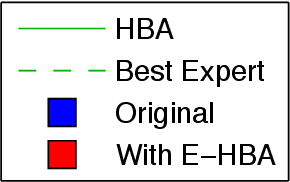
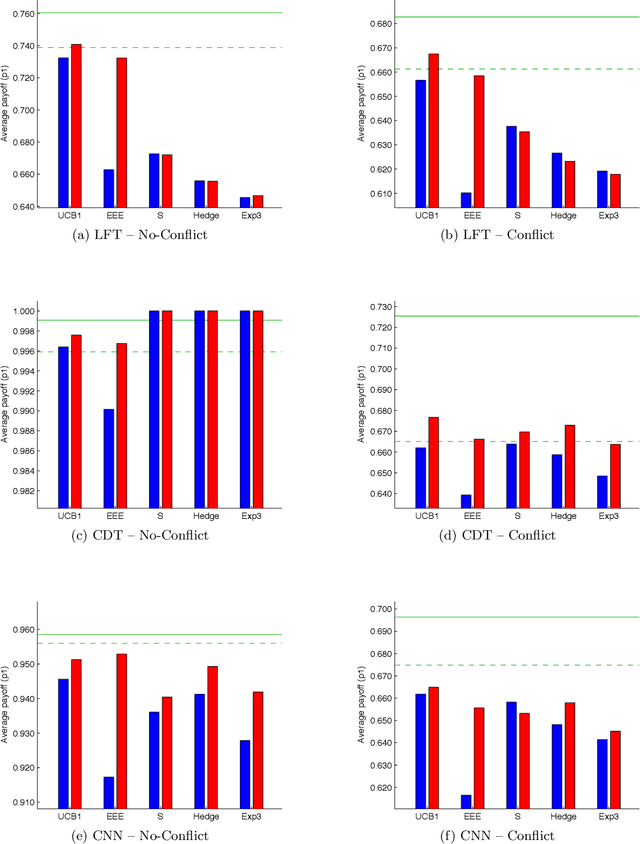
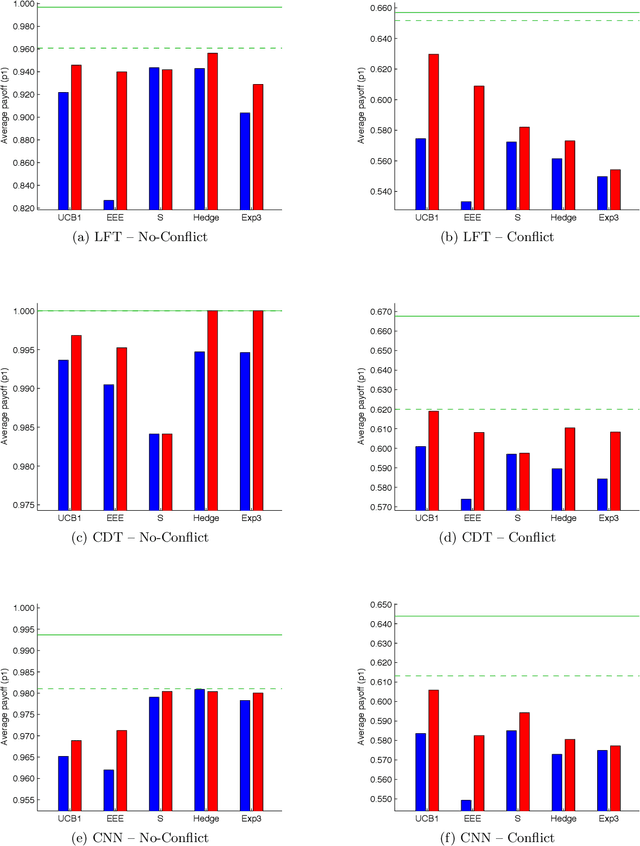
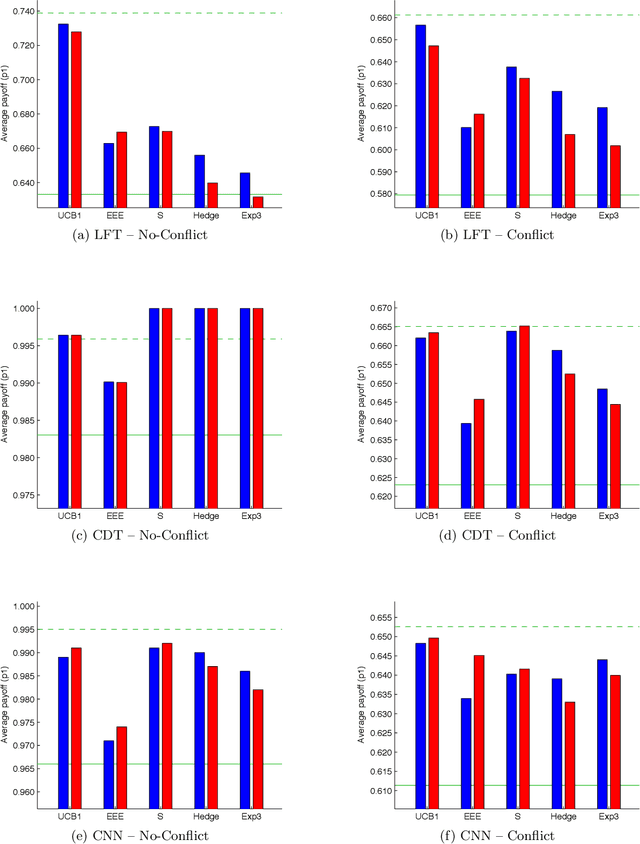
Past research has studied two approaches to utilise predefined policy sets in repeated interactions: as experts, to dictate our own actions, and as types, to characterise the behaviour of other agents. In this work, we bring these complementary views together in the form of a novel meta-algorithm, called Expert-HBA (E-HBA), which can be applied to any expert algorithm that considers the average (or total) payoff an expert has yielded in the past. E-HBA gradually mixes the past payoff with a predicted future payoff, which is computed using the type-based characterisation. We present results from a comprehensive set of repeated matrix games, comparing the performance of several well-known expert algorithms with and without the aid of E-HBA. Our results show that E-HBA has the potential to significantly improve the performance of expert algorithms.
Comparative Evaluation of Multiagent Learning Algorithms in a Diverse Set of Ad Hoc Team Problems
Jul 22, 2019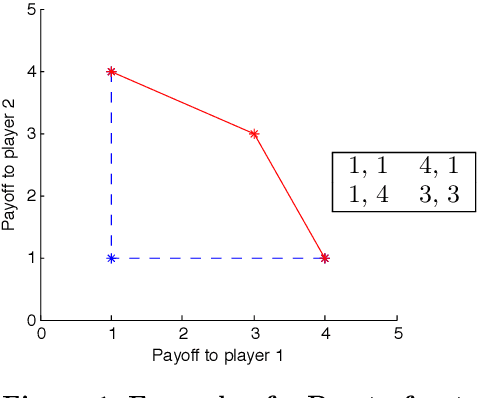
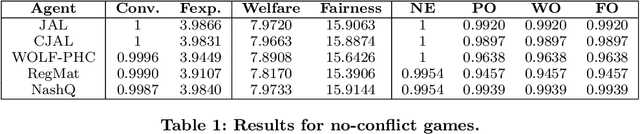
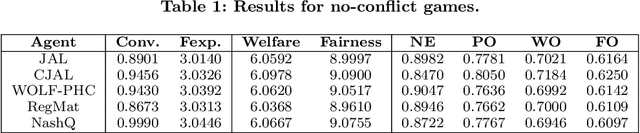
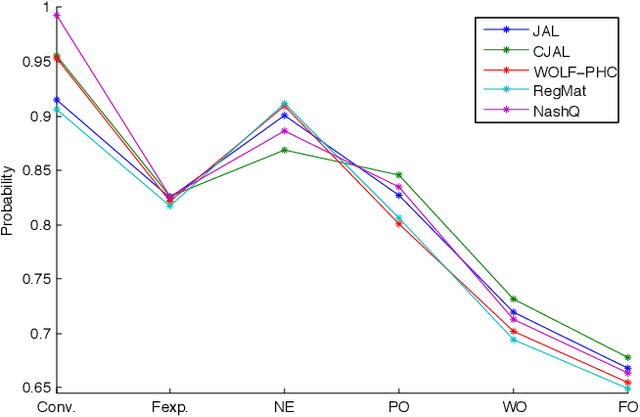
This paper is concerned with evaluating different multiagent learning (MAL) algorithms in problems where individual agents may be heterogenous, in the sense of utilizing different learning strategies, without the opportunity for prior agreements or information regarding coordination. Such a situation arises in ad hoc team problems, a model of many practical multiagent systems applications. Prior work in multiagent learning has often been focussed on homogeneous groups of agents, meaning that all agents were identical and a priori aware of this fact. Also, those algorithms that are specifically designed for ad hoc team problems are typically evaluated in teams of agents with fixed behaviours, as opposed to agents which are adapting their behaviours. In this work, we empirically evaluate five MAL algorithms, representing major approaches to multiagent learning but originally developed with the homogeneous setting in mind, to understand their behaviour in a set of ad hoc team problems. All teams consist of agents which are continuously adapting their behaviours. The algorithms are evaluated with respect to a comprehensive characterisation of repeated matrix games, using performance criteria that include considerations such as attainment of equilibrium, social welfare and fairness. Our main conclusion is that there is no clear winner. However, the comparative evaluation also highlights the relative strengths of different algorithms with respect to the type of performance criteria, e.g., social welfare vs. attainment of equilibrium.
Composing Diverse Policies for Temporally Extended Tasks
Jul 18, 2019
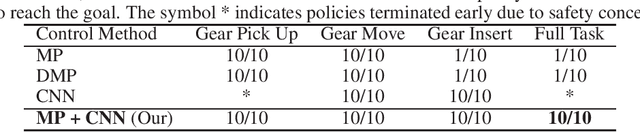
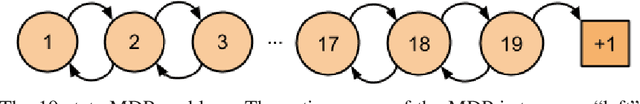
Temporally extended and sequenced robot motion tasks are often characterized by discontinuous switches between different types of local dynamics. These change-points can be exploited to build approximate models of the interleaving regions, which in turn allow the design of region-specific controllers. These can then be combined to create the initiation state-space of a final policy. However, such a pipeline can become challenging to implement for combinatorially complex, temporarily extended tasks - especially so when sub-controllers work on different information streams, time scales and action spaces. In this paper, we introduce a method that can compose diverse policies based on scripted motion planning, dynamic motion primitives and neural networks. In order to do this, we extend the options framework to introduce a per-option dynamics module and a global function that evaluates a goal metric. Additionally, we can leverage expert demonstrations to sequence these local policies, converting the learning problem in hierarchical reinforcement learning to a planning problem at inference time. We first illustrate the core concepts with an MDP benchmark, and then with a physical gear assembly task solved on a PR2 robot. We show that the proposed approach successfully discovers the optimal sequence of policies and solves both tasks efficiently.
Vid2Param: Online system identification from video for robotics applications
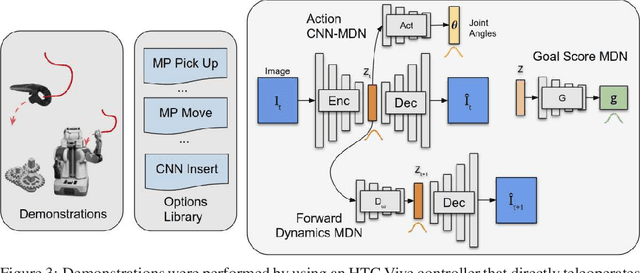
Jul 15, 2019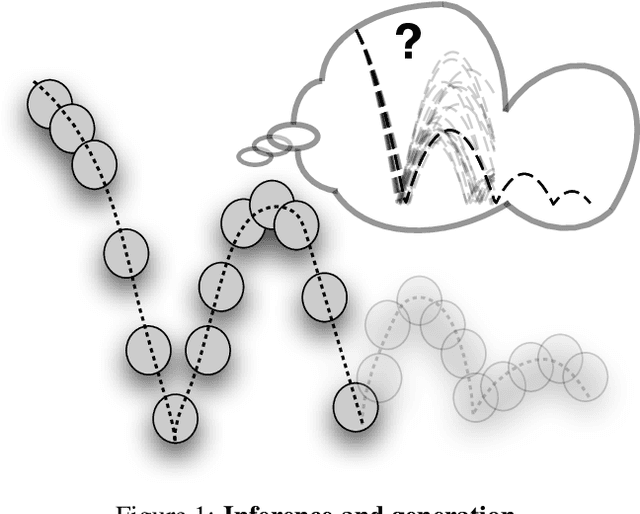

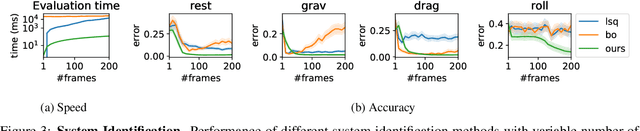
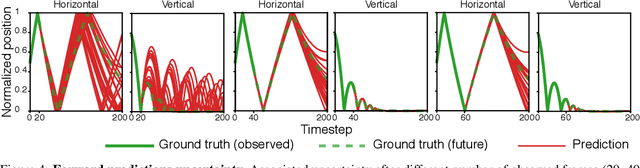
Robots performing tasks in dynamic environments would benefit greatly from understanding the underlying environment motion, in order to make future predictions and to synthesize effective control policies that use this inductive bias. Online system identification is therefore a fundamental requirement for robust autonomous agents. When the dynamics involves multiple modes (due to contacts or interactions between objects), and when system identification must proceed directly from a rich sensory stream such as video, then traditional methods for system identification may not be well suited. We propose an approach wherein fast parameter estimation with a model can be seamlessly combined with a recurrent variational autoencoder. Our Physics-based recurrent variational autoencoder model includes an additional loss that enforces conformity with the structure of a physically based dynamics model. This enables the resulting model to encode parameters such as position, velocity, restitution, air drag and other physical properties of the system. The model can be trained entirely in simulation, in an end-to-end manner with domain randomization, to perform online system identification, and probabilistic forward predictions of parameters of interest. We benchmark against existing system identification methods and demonstrate that Vid2Param outperforms the baselines in terms of speed and accuracy of identification, and also provides uncertainty quantification in the form of a distribution over future trajectories. Furthermore, we illustrate the utility of this in physical experiments wherein a PR2 robot with velocity constrained arm must intercept a bouncing ball, by estimating the physical parameters of this ball directly from the video trace after the ball is released.
On Convergence and Optimality of Best-Response Learning with Policy Types in Multiagent Systems
Jul 15, 2019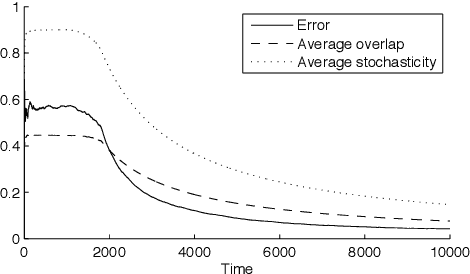
While many multiagent algorithms are designed for homogeneous systems (i.e. all agents are identical), there are important applications which require an agent to coordinate its actions without knowing a priori how the other agents behave. One method to make this problem feasible is to assume that the other agents draw their latent policy (or type) from a specific set, and that a domain expert could provide a specification of this set, albeit only a partially correct one. Algorithms have been proposed by several researchers to compute posterior beliefs over such policy libraries, which can then be used to determine optimal actions. In this paper, we provide theoretical guidance on two central design parameters of this method: Firstly, it is important that the user choose a posterior which can learn the true distribution of latent types, as otherwise suboptimal actions may be chosen. We analyse convergence properties of two existing posterior formulations and propose a new posterior which can learn correlated distributions. Secondly, since the types are provided by an expert, they may be inaccurate in the sense that they do not predict the agents' observed actions. We provide a novel characterisation of optimality which allows experts to use efficient model checking algorithms to verify optimality of types.
An Empirical Study on the Practical Impact of Prior Beliefs over Policy Types
Jul 10, 2019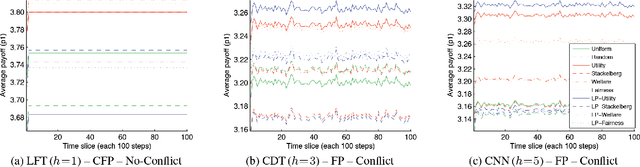
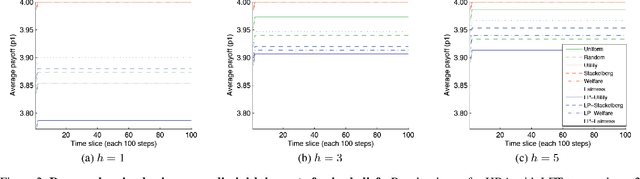
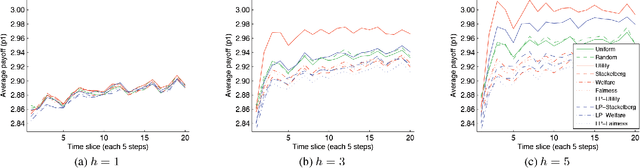
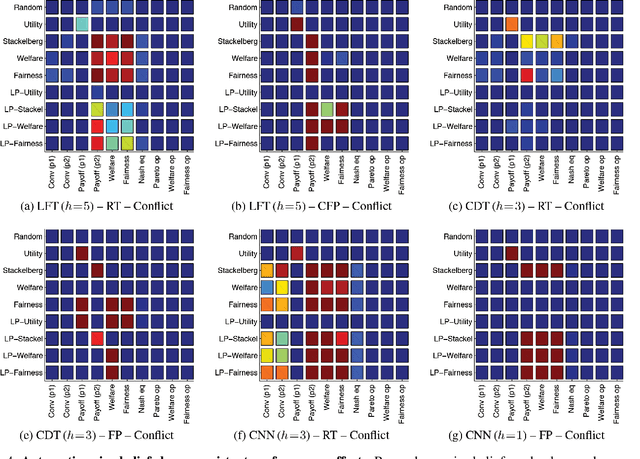
Many multiagent applications require an agent to learn quickly how to interact with previously unknown other agents. To address this problem, researchers have studied learning algorithms which compute posterior beliefs over a hypothesised set of policies, based on the observed actions of the other agents. The posterior belief is complemented by the prior belief, which specifies the subjective likelihood of policies before any actions are observed. In this paper, we present the first comprehensive empirical study on the practical impact of prior beliefs over policies in repeated interactions. We show that prior beliefs can have a significant impact on the long-term performance of such methods, and that the magnitude of the impact depends on the depth of the planning horizon. Moreover, our results demonstrate that automatic methods can be used to compute prior beliefs with consistent performance effects. This indicates that prior beliefs could be eliminated as a manual parameter and instead be computed automatically.
Exploiting Causality for Selective Belief Filtering in Dynamic Bayesian Networks (Extended Abstract)
Jul 10, 2019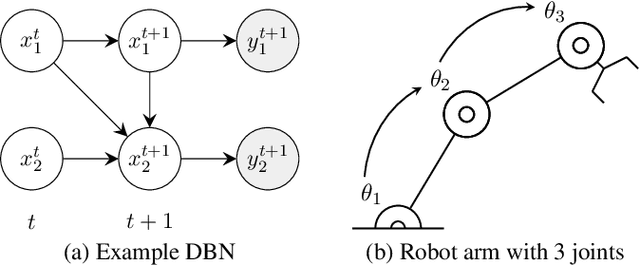
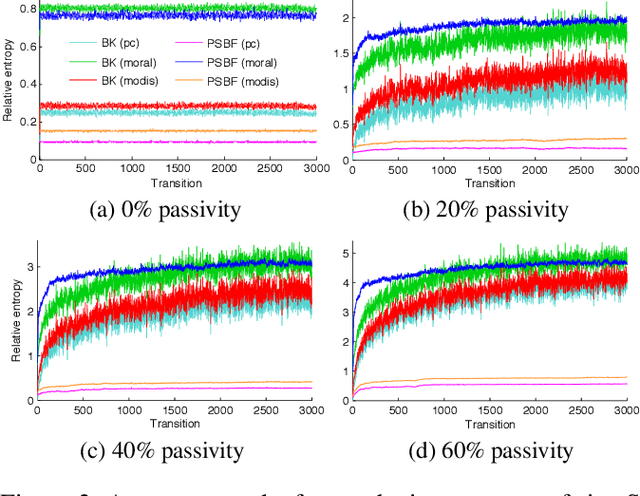
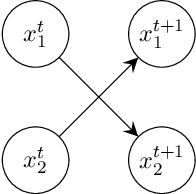
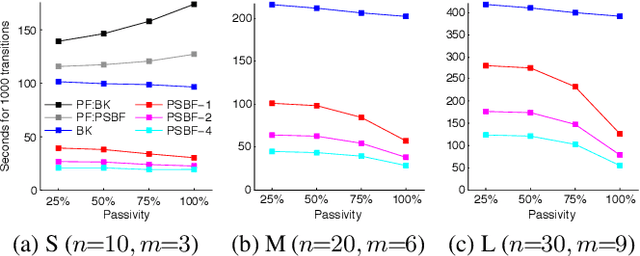
Dynamic Bayesian networks (DBNs) are a general model for stochastic processes with partially observed states. Belief filtering in DBNs is the task of inferring the belief state (i.e. the probability distribution over process states) based on incomplete and uncertain observations. In this article, we explore the idea of accelerating the filtering task by automatically exploiting causality in the process. We consider a specific type of causal relation, called passivity, which pertains to how state variables cause changes in other variables. We present the Passivity-based Selective Belief Filtering (PSBF) method, which maintains a factored belief representation and exploits passivity to perform selective updates over the belief factors. PSBF is evaluated in both synthetic processes and a simulated multi-robot warehouse, where it outperformed alternative filtering methods by exploiting passivity.
DynoPlan: Combining Motion Planning and Deep Neural Network based Controllers for Safe HRL
Jun 24, 2019
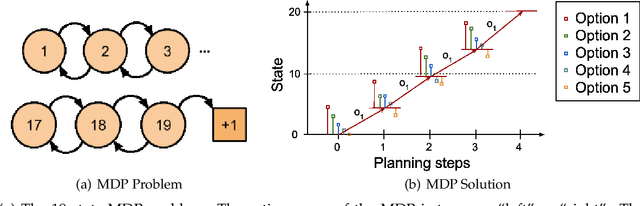
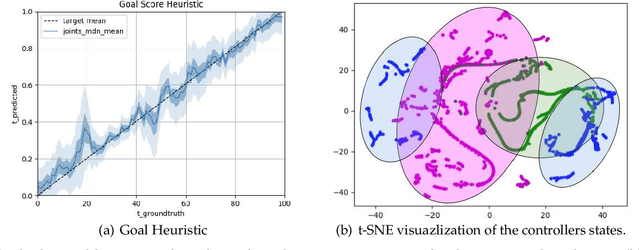
Many realistic robotics tasks are best solved compositionally, through control architectures that sequentially invoke primitives and achieve error correction through the use of loops and conditionals taking the system back to alternative earlier states. Recent end-to-end approaches to task learning attempt to directly learn a single controller that solves an entire task, but this has been difficult for complex control tasks that would have otherwise required a diversity of local primitive moves, and the resulting solutions are also not easy to inspect for plan monitoring purposes. In this work, we aim to bridge the gap between hand designed and learned controllers, by representing each as an option in a hybrid hierarchical Reinforcement Learning framework - DynoPlan. We extend the options framework by adding a dynamics model and the use of a nearness-to-goal heuristic, derived from demonstrations. This translates the optimization of a hierarchical policy controller to a problem of planning with a model predictive controller. By unrolling the dynamics of each option and assessing the expected value of each future state, we can create a simple switching controller for choosing the optimal policy within a constrained time horizon similarly to hill climbing heuristic search. The individual dynamics model allows each option to iterate and be activated independently of the specific underlying instantiation, thus allowing for a mix of motion planning and deep neural network based primitives. We can assess the safety regions of the resulting hybrid controller by investigating the initiation sets of the different options, and also by reasoning about the completeness and performance guarantees of the underpinning motion planners.
Learning Grasp Affordance Reasoning through Semantic Relations
Jun 24, 2019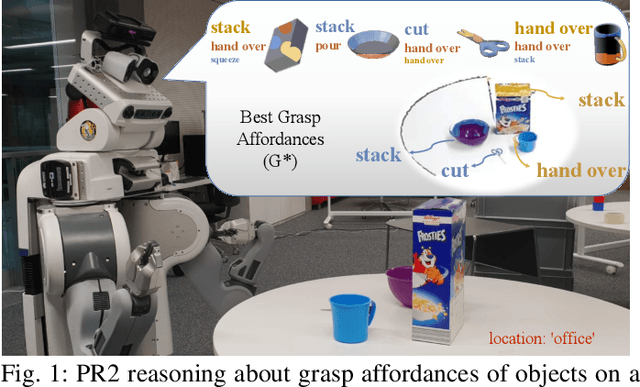
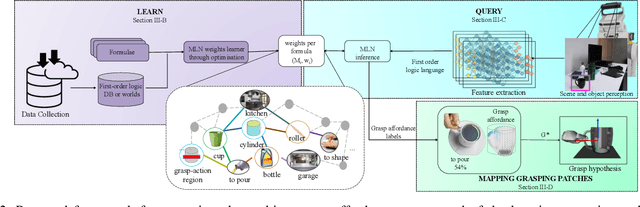
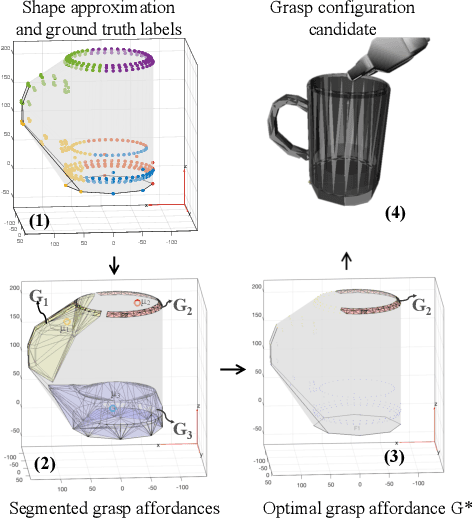
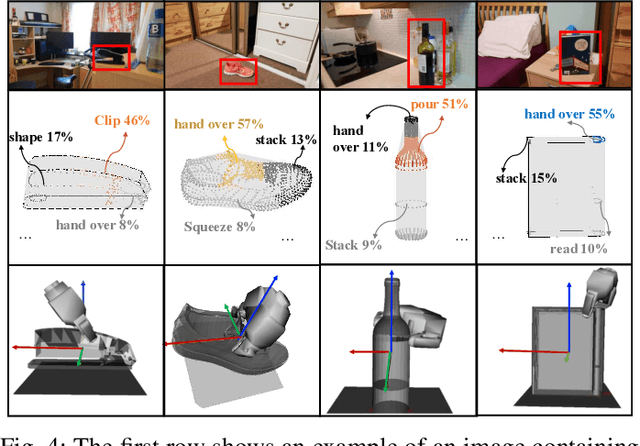
Reasoning about object affordances allows an autonomous agent to perform generalised manipulation tasks among object instances. While current approaches to grasp affordance estimation are effective, they are limited to a single hypothesis. We present an approach for detection and extraction of multiple grasp affordances on an object via visual input. We define semantics as a combination of multiple attributes, which yields benefits in terms of generalisation for grasp affordance prediction. We use Markov Logic Networks to build a knowledge base graph representation to obtain a probability distribution of grasp affordances for an object. To harvest the knowledge base, we collect and make available a novel dataset that relates different semantic attributes. We achieve reliable mappings of the predicted grasp affordances on the object by learning prototypical grasping patches from several examples. We show our method's generalisation capabilities on grasp affordance prediction for novel instances and compare with similar methods in the literature. Moreover, using a robotic platform, on simulated and real scenarios, we evaluate the success of the grasping task when conditioned on the grasp affordance prediction.
Iterative Model-Based Reinforcement Learning Using Simulations in the Differentiable Neural Computer
Jun 17, 2019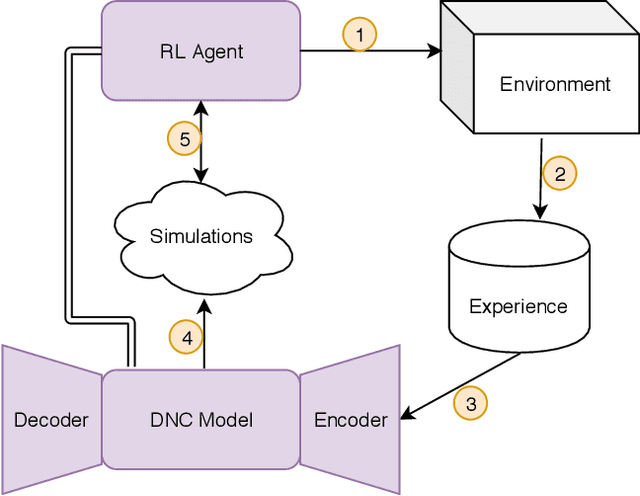
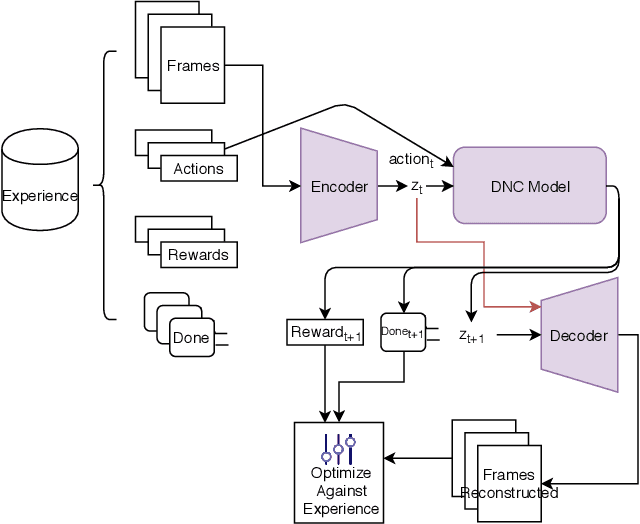
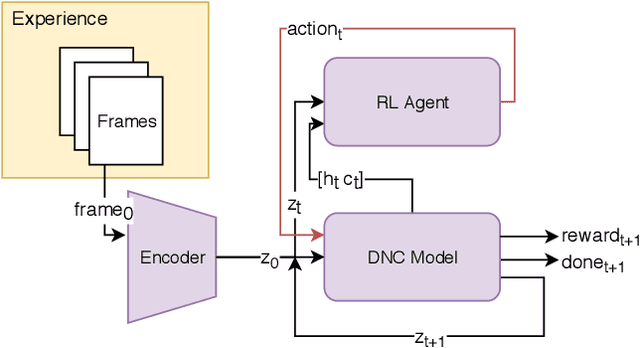
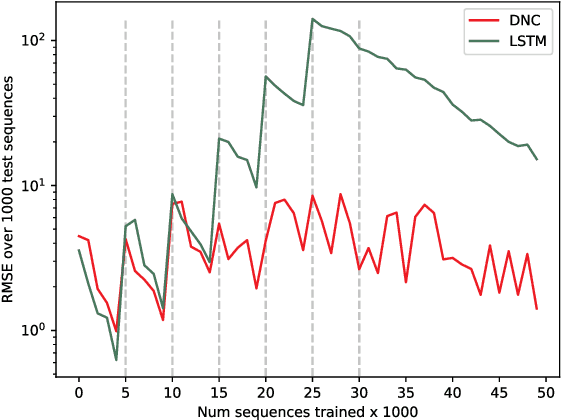
We propose a lifelong learning architecture, the Neural Computer Agent (NCA), where a Reinforcement Learning agent is paired with a predictive model of the environment learned by a Differentiable Neural Computer (DNC). The agent and DNC model are trained in conjunction iteratively. The agent improves its policy in simulations generated by the DNC model and rolls out the policy to the live environment, collecting experiences in new portions or tasks of the environment for further learning. Experiments in two synthetic environments show that DNC models can continually learn from pixels alone to simulate new tasks as they are encountered by the agent, while the agents can be successfully trained to solve the tasks using Proximal Policy Optimization entirely in simulations.