 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffordances in Robotic Tasks -- A Survey
Apr 15, 2020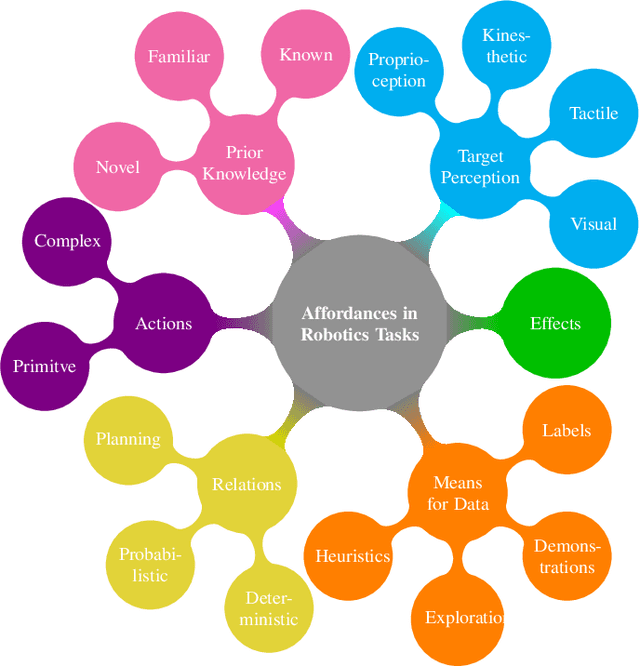

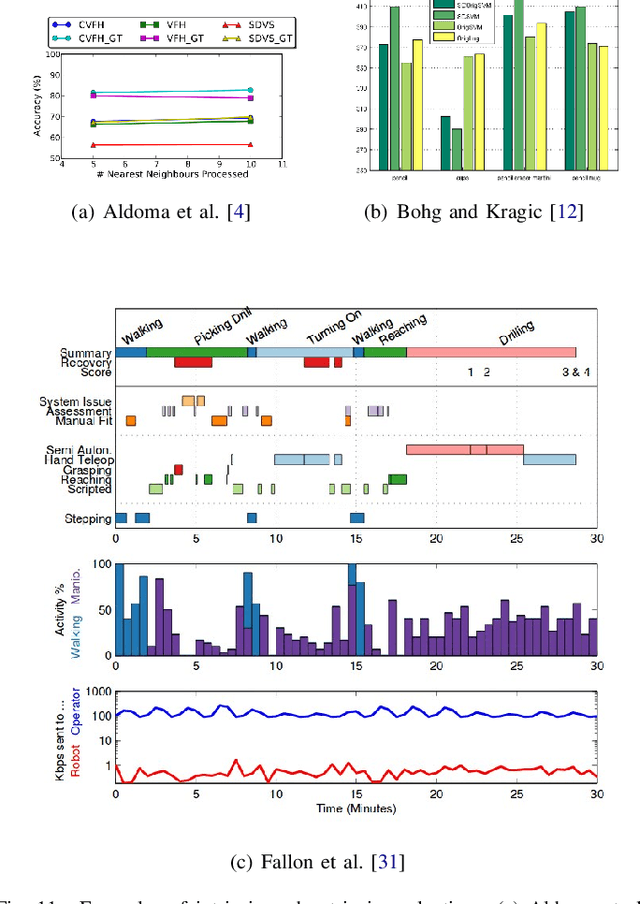

Affordances are key attributes of what must be perceived by an autonomous robotic agent in order to effectively interact with novel objects. Historically, the concept derives from the literature in psychology and cognitive science, where affordances are discussed in a way that makes it hard for the definition to be directly transferred to computational specifications useful for robots. This review article is focused specifically on robotics, so we discuss the related literature from this perspective. In this survey, we classify the literature and try to find common ground amongst different approaches with a view to application in robotics. We propose a categorisation based on the level of prior knowledge that is assumed to build the relationship among different affordance components that matter for a particular robotic task. We also identify areas for future improvement and discuss possible directions that are likely to be fruitful in terms of impact on robotics practice.
Integrating Planning and Interpretable Goal Recognition for Autonomous Driving
Feb 06, 2020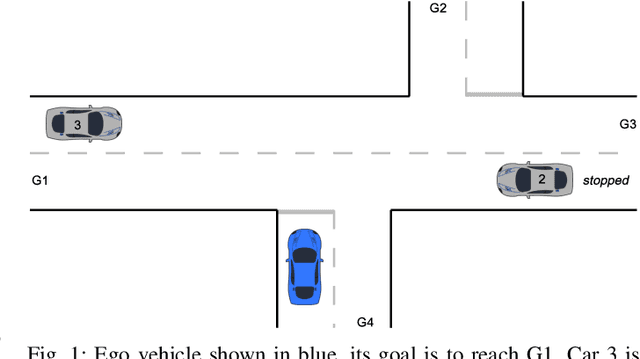
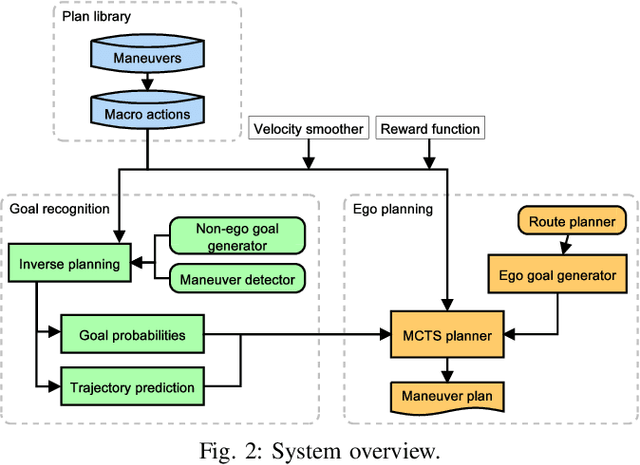

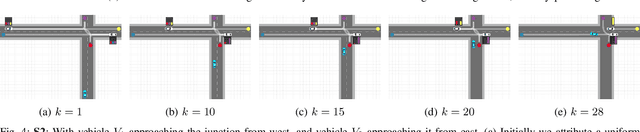
The ability to predict the intentions and driving trajectories of other vehicles is a key problem for autonomous driving. We propose an integrated planning and prediction system which leverages the computational benefit of using a finite space of maneuvers, and extend the approach to planning and prediction of sequences (plans) of maneuvers via rational inverse planning to recognise the goals of other vehicles. Goal recognition informs a Monte Carlo Tree Search (MCTS) algorithm to plan optimal maneuvers for the ego vehicle. Inverse planning and MCTS utilise a shared set of defined maneuvers to construct plans which are explainable by means of rationality, i.e. plans are optimal in given metrics. Evaluation in simulations of four urban driving scenarios demonstrate the system's ability to robustly recognise the goals of other vehicles while generating near-optimal plans. In each scenario we extract intuitive explanations for the recognised goals and maneuver predictions which justify the system's decisions.
A Two-Stage Optimization Approach to Safe-by-Design Planning for Autonomous Driving
Feb 06, 2020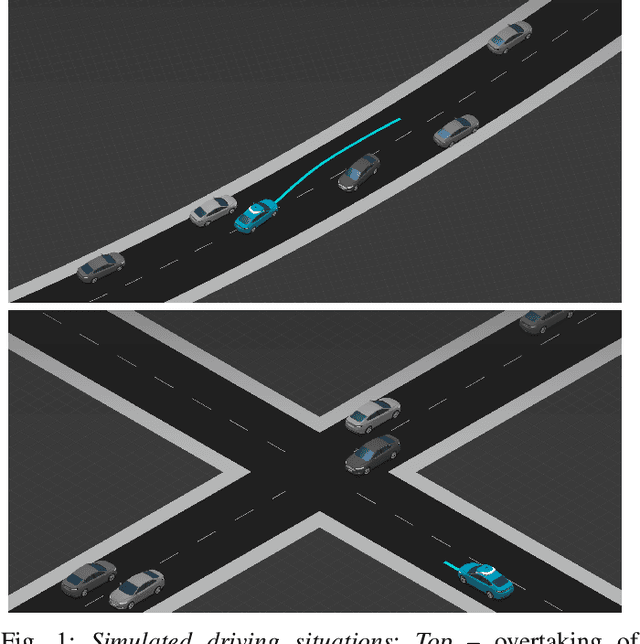

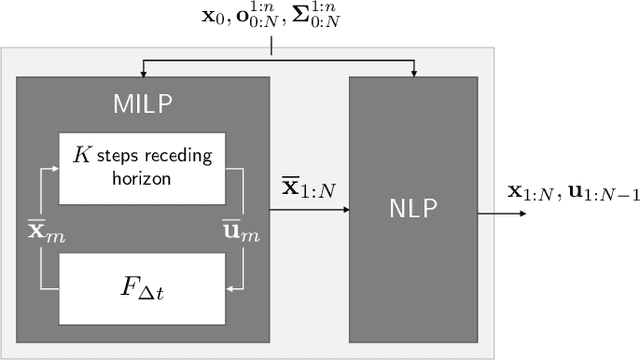
Lessons learned from the increasing diversity of road trial deployments of autonomous vehicles have made clear that guaranteeing safety of driving decisions is a crucial bottleneck on the path towards wider adoption. A promising direction is to pose safety requirements as planning constraints in nonlinear optimization problems for motion synthesis. However, many implementations of this approach are limited by uncertain convergence and local optimality of the solutions achieved, affecting overall robustness. In this paper, we propose a novel two-stage optimization framework: in the first stage, we find a global but approximate solution to a Mixed-Integer Linear Programming (MILP) formulation of the motion synthesis problem, the output of which initializes a second Nonlinear Programming (NLP) stage. The MILP stage enforces hard constraints including safety and road rules, while the NLP stage refines that solution within safety bounds to make it feasible with respect to vehicle dynamics and smoothness. We demonstrate the usefulness of our framework through experiments in complex driving situations, showing it outperforms a state of the art baseline in terms of convergence, comfort and progress metrics.
Learning robotic ultrasound scanning using probabilistic temporal ranking
Feb 04, 2020This paper addresses a common class of problems where a robot learns to perform a discovery task based on example solutions, or human demonstrations. For example consider the problem of ultrasound scanning, where the demonstration requires that an expert adaptively searches for a satisfactory view of internal organs, vessels or tissue and potential anomalies while maintaining optimal contact between the probe and surface tissue. Such problems are currently solved by inferring notional rewards that, when optimised for, result in a plan that mimics demonstrations. A pivotal assumption, that plans with higher reward should be exponentially more likely, leads to the de facto approach for reward inference in robotics. While this approach of maximum entropy inverse reinforcement learning leads to a general and elegant formulation, it struggles to cope with frequently encountered sub-optimal demonstrations. In this paper, we propose an alternative approach to cope with the class of problems where sub-optimal demonstrations occur frequently. We hypothesise that, in tasks which require discovery, successive states of any demonstration are progressively more likely to be associated with a higher reward. We formalise this temporal ranking approach and show that it improves upon maximum-entropy approaches to perform reward inference for autonomous ultrasound scanning, a novel application of learning from demonstration in medical imaging.
Elaborating on Learned Demonstrations with Temporal Logic Specifications
Feb 03, 2020
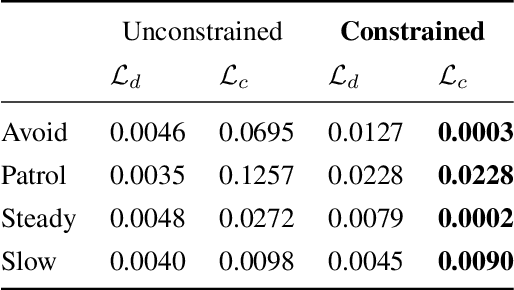
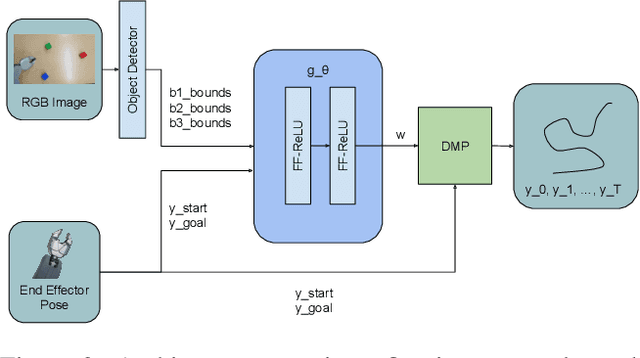
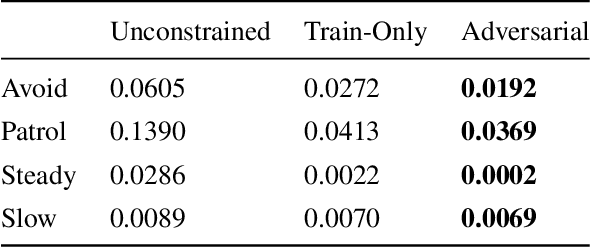
Most current methods for learning from demonstrations assume that those demonstrations alone are sufficient to learn the underlying task. This is often untrue, especially if extra safety specifications exist which were not present in the original demonstrations. In this paper, we allow an expert to elaborate on their original demonstration with additional specification information using linear temporal logic (LTL). Our system converts LTL specifications into a differentiable loss. This loss is then used to learn a dynamic movement primitive that satisfies the underlying specification, while remaining close to the original demonstration. Further, by leveraging adversarial training, our system learns to robustly satisfy the given LTL specification on unseen inputs, not just those seen in training. We show that our method is expressive enough to work across a variety of common movement specification patterns such as obstacle avoidance, patrolling, keeping steady, and speed limitation. In addition, we show that our system can modify a base demonstration with complex specifications by incrementally composing multiple simpler specifications. We also implement our system on a PR-2 robot to show how a demonstrator can start with an initial (sub-optimal) demonstration, then interactively improve task success by including additional specifications enforced with our differentiable LTL loss.
Learning with Modular Representations for Long-Term Multi-Agent Motion Predictions
Jan 17, 2020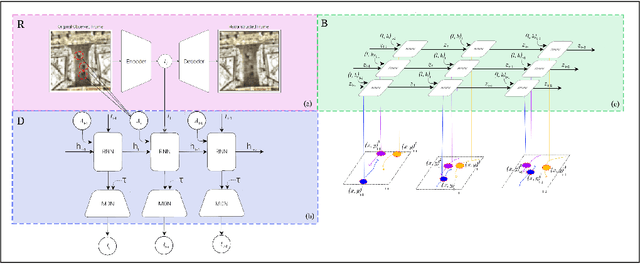
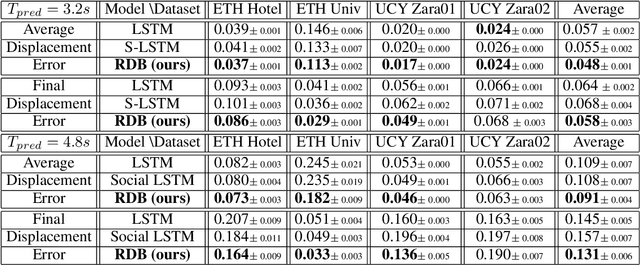
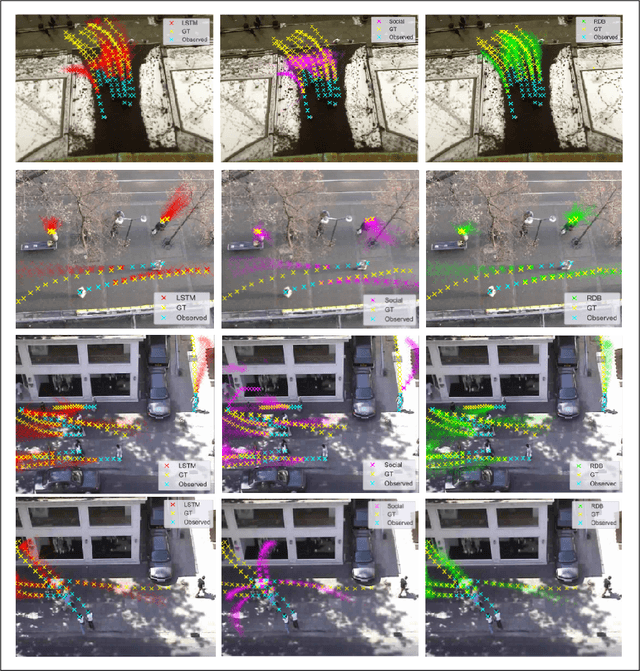
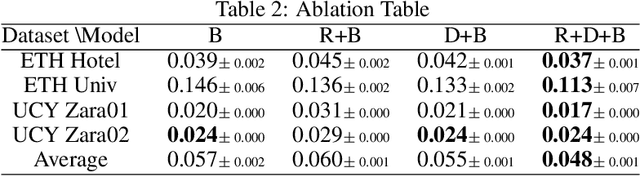
Context plays a significant role in the generation of motion for dynamic agents in interactive environments. This work proposes a modular method that utilises a model of the environment to aid motion prediction of tracked agents. This paper shows that modelling the spatial and dynamic aspects of a given environment alongside the local per agent behaviour results in more accurate and informed long-term motion prediction. Further, we observe that this decoupling of dynamics and environment models allows for better adaptation to unseen environments, requiring that only a spatial representation of a new environment be learned. We highlight the model's prediction capability using a benchmark pedestrian tracking problem and by tracking a robot arm performing a tabletop manipulation task. The proposed approach allows for robust and data efficient forward modelling, and relaxes the need for full model re-training in new environments. We evaluate this through an ablation study which shows better performance gain when utilising both representation modules in addition to improved generalisation on tasks with dynamics unseen at training time.
Lower Dimensional Kernels for Video Discriminators
Dec 18, 2019

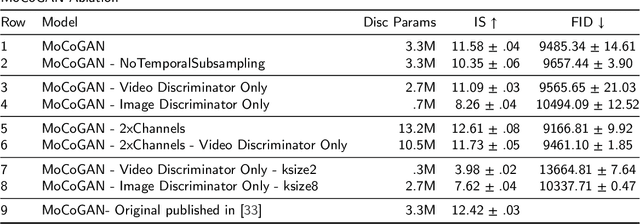
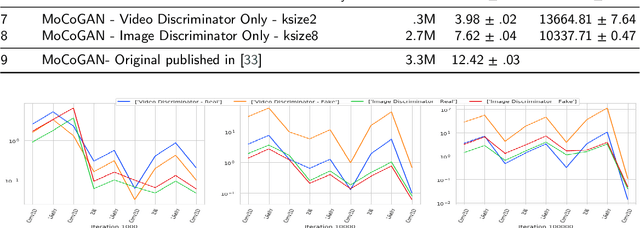
This work presents an analysis of the discriminators used in Generative Adversarial Networks (GANs) for Video. We show that unconstrained video discriminator architectures induce a loss surface with high curvature which make optimisation difficult. We also show that this curvature becomes more extreme as the maximal kernel dimension of video discriminators increases. With these observations in hand, we propose a family of efficient Lower-Dimensional Video Discriminators for GANs (LDVD GANs). The proposed family of discriminators improve the performance of video GAN models they are applied to and demonstrate good performance on complex and diverse datasets such as UCF-101. In particular, we show that they can double the performance of Temporal-GANs and provide for state-of-the-art performance on a single GPU.
Surfing on an uncertain edge: Precision cutting of soft tissue using torque-based medium classification
Sep 16, 2019
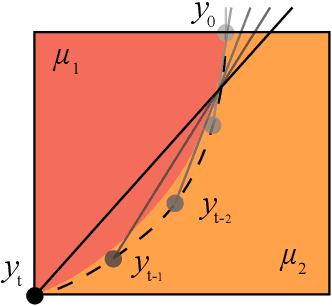
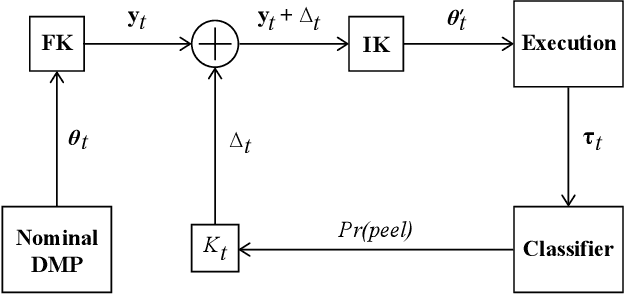

Precision cutting of soft-tissue remains a challenging problem in robotics, due to the complex and unpredictable mechanical behaviour of tissue under manipulation. Here, we consider the challenge of cutting along the boundary between two soft mediums, a problem that is made extremely difficult due to visibility constraints, which means that the precise location of the cutting trajectory is typically unknown. This paper introduces a novel strategy to address this task, using a binary medium classifier trained using joint torque measurements, and a closed loop control law that relies on an error signal compactly encoded in the decision boundary of the classifier. We illustrate this on a grapefruit cutting task, successfully modulating a nominal trajectory fit using dynamic movement primitives to follow the boundary between grapefruit pulp and peel using torque based medium classification. Results show that this control strategy is successful in 72 % of attempts in contrast to control using a nominal trajectory, which only succeeds in 50 % of attempts.
Hybrid system identification using switching density networks
Aug 06, 2019Behaviour cloning is a commonly used strategy for imitation learning and can be extremely effective in constrained domains. However, in cases where the dynamics of an environment may be state dependent and varying, behaviour cloning places a burden on model capacity and the number of demonstrations required. This paper introduces switching density networks, which rely on a categorical reparametrisation for hybrid system identification. This results in a network comprising a classification layer that is followed by a regression layer. We use switching density networks to predict the parameters of hybrid control laws, which are toggled by a switching layer to produce different controller outputs, when conditioned on an input state. This work shows how switching density networks can be used for hybrid system identification in a variety of tasks, successfully identifying the key joint angle goals that make up manipulation tasks, while simultaneously learning image-based goal classifiers and regression networks that predict joint angles from images. We also show that they can cluster the phase space of an inverted pendulum, identifying the balance, spin and pump controllers required to solve this task. Switching density networks can be difficult to train, but we introduce a cross entropy regularisation loss that stabilises training.
Disentangled Relational Representations for Explaining and Learning from Demonstration
Jul 31, 2019
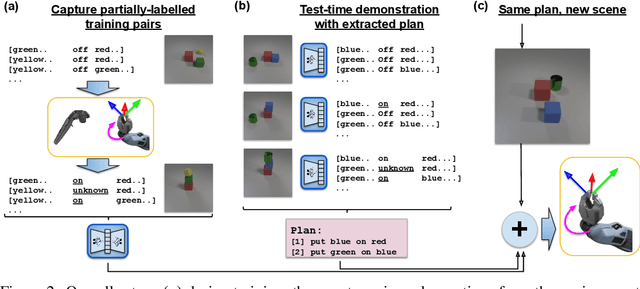

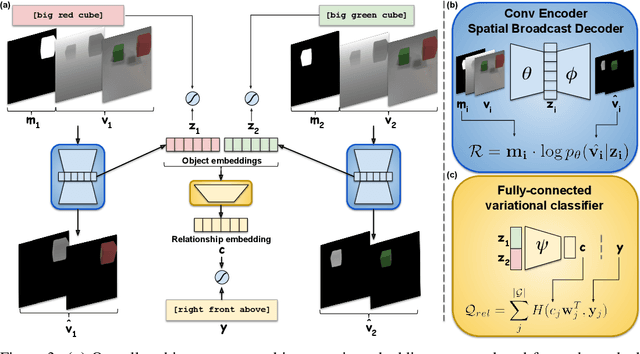
Learning from demonstration is an effective method for human users to instruct desired robot behaviour. However, for most non-trivial tasks of practical interest, efficient learning from demonstration depends crucially on inductive bias in the chosen structure for rewards/costs and policies. We address the case where this inductive bias comes from an exchange with a human user. We propose a method in which a learning agent utilizes the information bottleneck layer of a high-parameter variational neural model, with auxiliary loss terms, in order to ground abstract concepts such as spatial relations. The concepts are referred to in natural language instructions and are manifested in the high-dimensional sensory input stream the agent receives from the world. We evaluate the properties of the latent space of the learned model in a photorealistic synthetic environment and particularly focus on examining its usability for downstream tasks. Additionally, through a series of controlled table-top manipulation experiments, we demonstrate that the learned manifold can be used to ground demonstrations as symbolic plans, which can then be executed on a PR2 robot.