 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbRobScene: A Probabilistic Specification Language for 3D Robotic Manipulation Environments
Nov 06, 2020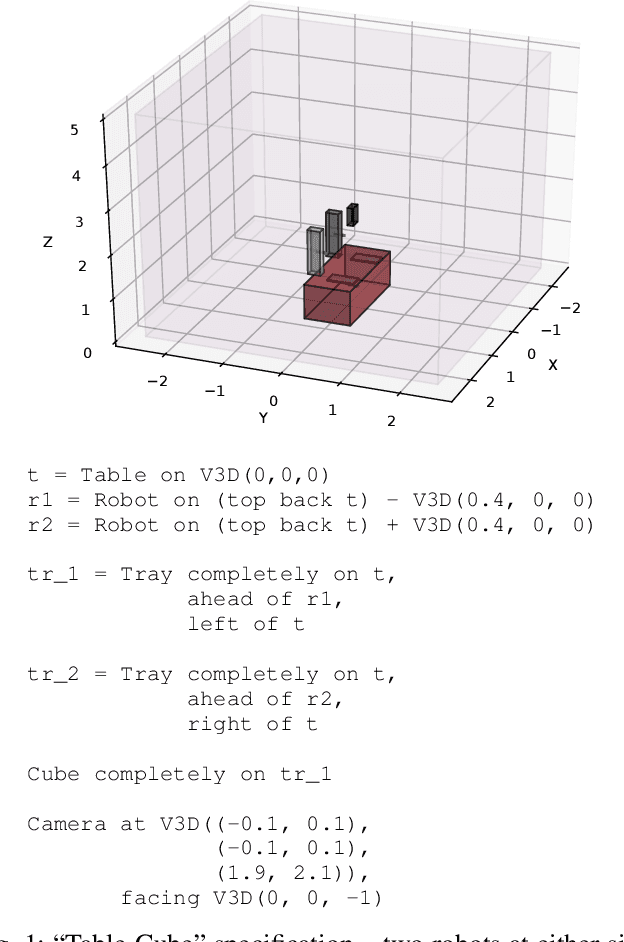

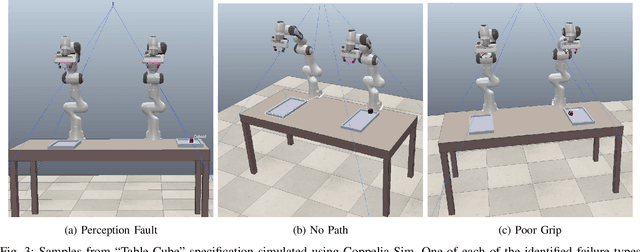

Robotic control tasks are often first run in simulation for the purposes of verification, debugging and data augmentation. Many methods exist to specify what task a robot must complete, but few exist to specify what range of environments a user expects such tasks to be achieved in. ProbRobScene is a probabilistic specification language for describing robotic manipulation environments. Using the language, a user need only specify the relational constraints that must hold between objects in a scene. ProbRobScene will then automatically generate scenes which conform to this specification. By combining aspects of probabilistic programming languages and convex geometry, we provide a method for sampling this space of possible environments efficiently. We demonstrate the usefulness of our language by using it to debug a robotic controller in a tabletop robot manipulation environment.
PILOT: Efficient Planning by Imitation Learning and Optimisation for Safe Autonomous Driving
Nov 01, 2020
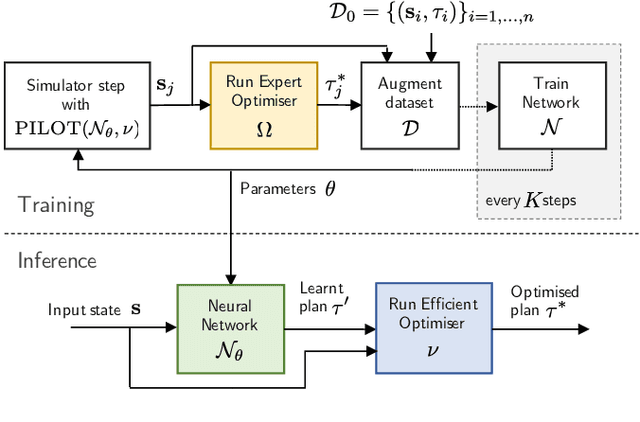
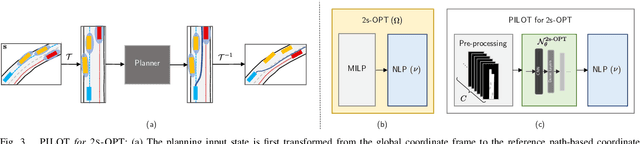
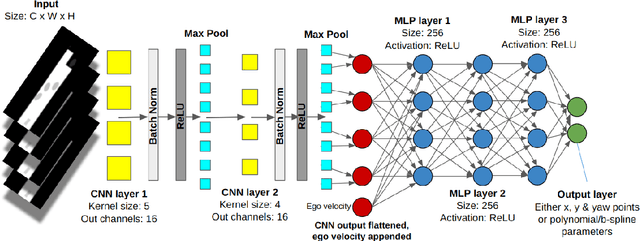
Achieving the right balance between planning quality, safety and runtime efficiency is a major challenge for autonomous driving research. Optimisation-based planners are typically capable of producing high-quality, safe plans, but at the cost of efficiency. We present PILOT, a two-stage planning framework comprising an imitation neural network and an efficient optimisation component that guarantees the satisfaction of requirements of safety and comfort. The neural network is trained to imitate an expensive-to-run optimisation-based planning system with the same objective as the efficient optimisation component of PILOT. We demonstrate in simulated autonomous driving experiments that the proposed framework achieves a significant reduction in runtime when compared to the optimisation-based expert it imitates, without sacrificing the planning quality.
Affordance-Aware Handovers with Human Arm Mobility Constraints
Oct 29, 2020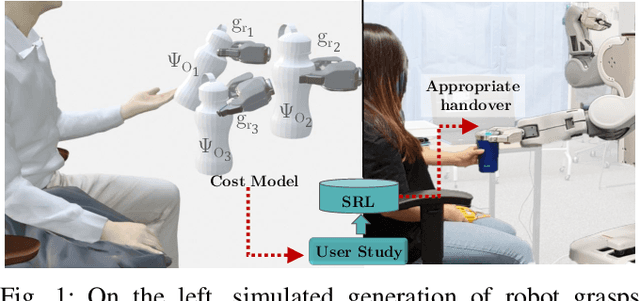
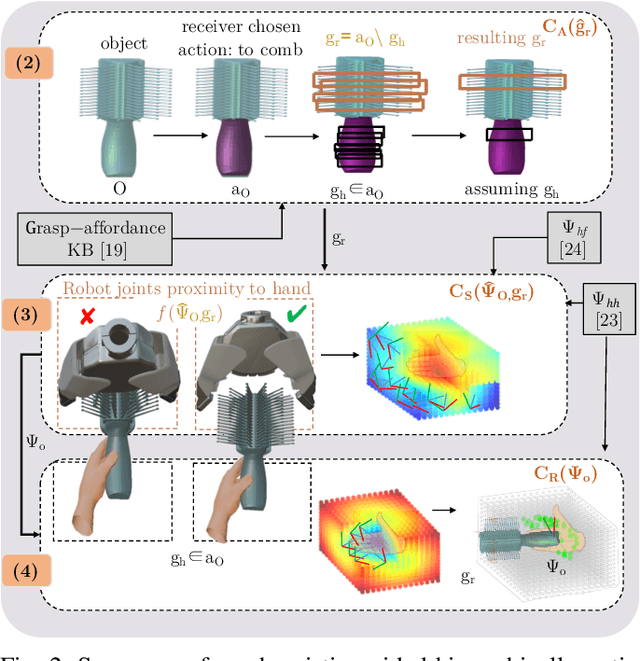
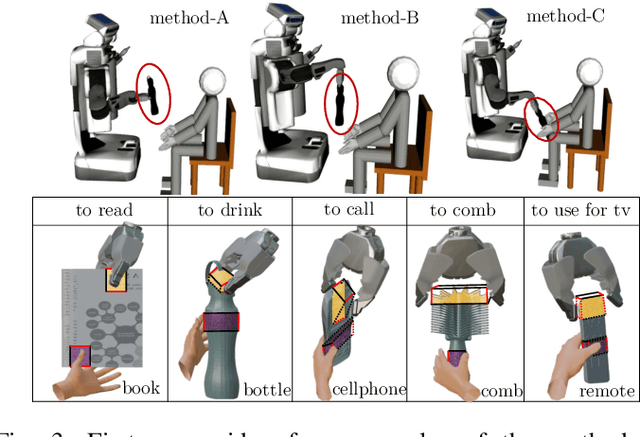
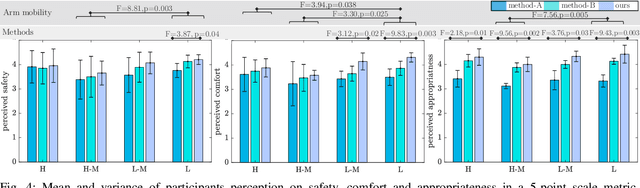
Reasoning about object handover configurations allows an assistive agent to estimate the appropriateness of handover for a receiver with different arm mobility capacities. While there are existing approaches to estimating the effectiveness of handovers, their findings are limited to users without arm mobility impairments and to specific objects. Therefore, current state-of-the-art approaches are unable to hand over novel objects to receivers with different arm mobility capacities. We propose a method that generalises handover behaviours to previously unseen objects, subject to the constraint of a user's arm mobility levels and the task context. We propose a heuristic-guided hierarchically optimised cost whose optimisation adapts object configurations for receivers with low arm mobility. This also ensures that the robot grasps consider the context of the user's upcoming task, i.e., the usage of the object. To understand preferences over handover configurations, we report on the findings of an online study, wherein we presented different handover methods, including ours, to $259$ users with different levels of arm mobility. We encapsulate these preferences in a SRL that is able to reason about the most suitable handover configuration given a receiver's arm mobility and upcoming task. We find that people's preferences over handover methods are correlated to their arm mobility capacities. In experiments with a PR2 robotic platform, we obtained an average handover accuracy of $90.8\%$ when generalising handovers to novel objects.
Counterfactual Explanation and Causal Inference in Service of Robustness in Robot Control
Sep 22, 2020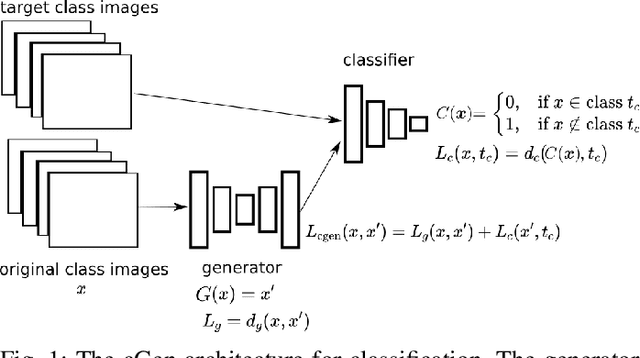


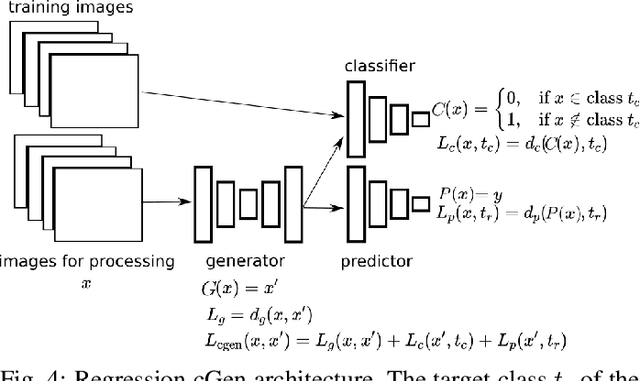
We propose an architecture for training generative models of counterfactual conditionals of the form, 'can we modify event A to cause B instead of C?', motivated by applications in robot control. Using an 'adversarial training' paradigm, an image-based deep neural network model is trained to produce small and realistic modifications to an original image in order to cause user-defined effects. These modifications can be used in the design process of image-based robust control - to determine the ability of the controller to return to a working regime by modifications in the input space, rather than by adaptation. In contrast to conventional control design approaches, where robustness is quantified in terms of the ability to reject noise, we explore the space of counterfactuals that might cause a certain requirement to be violated, thus proposing an alternative model that might be more expressive in certain robotics applications. So, we propose the generation of counterfactuals as an approach to explanation of black-box models and the envisioning of potential movement paths in autonomous robotic control. Firstly, we demonstrate this approach in a set of classification tasks, using the well known MNIST and CelebFaces Attributes datasets. Then, addressing multi-dimensional regression, we demonstrate our approach in a reaching task with a physical robot, and in a navigation task with a robot in a digital twin simulation.
Residual Learning from Demonstration
Aug 18, 2020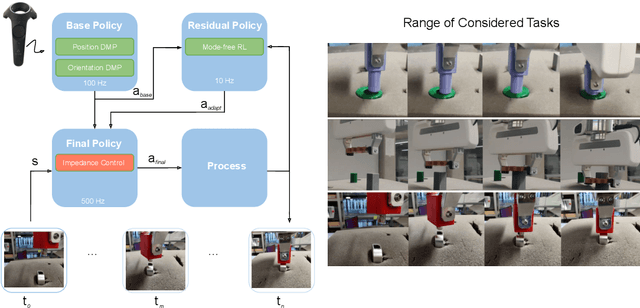
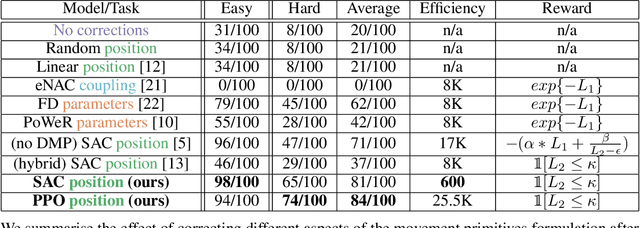
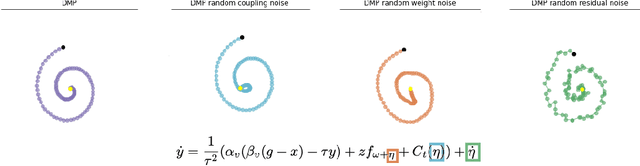
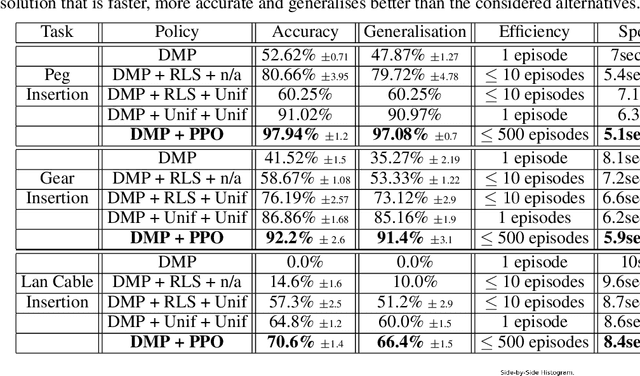
Contacts and friction are inherent to nearly all robotic manipulation tasks. Through the motor skill of insertion, we study how robots can learn to cope when these attributes play a salient role. In this work we propose residual learning from demonstration (rLfD), a framework that combines dynamic movement primitives (DMP) that rely on behavioural cloning with a reinforcement learning (RL) based residual correction policy. The proposed solution is applied directly in task space and operates on the full pose of the robot. We show that rLfD outperforms alternatives and improves the generalisation abilities of DMPs. We evaluate this approach by training an agent to successfully perform both simulated and real world insertions of pegs, gears and plugs into respective sockets.
Action sequencing using visual permutations
Aug 03, 2020
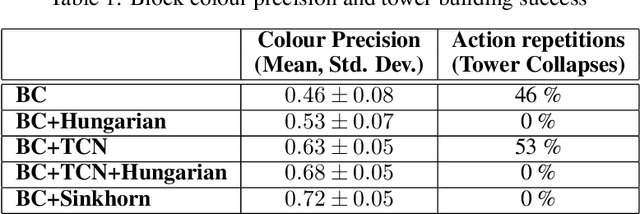
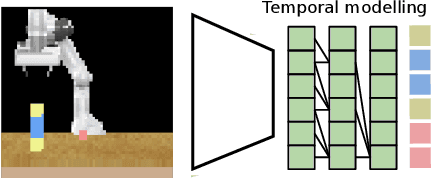
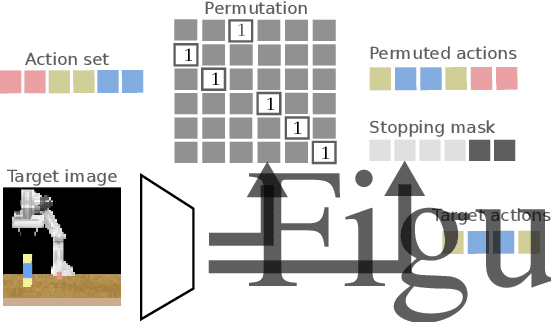
Humans can easily reason about the sequence of high level actions needed to complete tasks, but it is particularly difficult to instil this ability in robots trained from relatively few examples. This work considers the task of neural action sequencing conditioned on a single reference visual state. This task is extremely challenging as it is not only subject to the significant combinatorial complexity that arises from large action sets, but also requires a model that can perform some form of symbol grounding, mapping high dimensional input data to actions, while reasoning about action relationships. Drawing on human cognitive abilities to rearrange objects in scenes to create new configurations, we take a permutation perspective and argue that action sequencing benefits from the ability to reason about both permutations and ordering concepts. Empirical analysis shows that neural models trained with latent permutations outperform standard neural architectures in constrained action sequencing tasks. Results also show that action sequencing using visual permutations is an effective mechanism to initialise and speed up traditional planning techniques and successfully scales to far greater action set sizes than models considered previously.
Semi-supervised Learning From Demonstration Through Program Synthesis: An Inspection Robot Case Study
Jul 23, 2020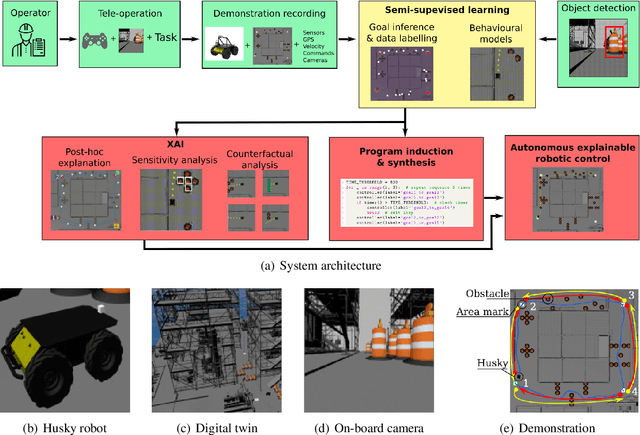
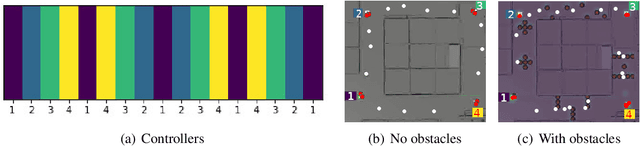
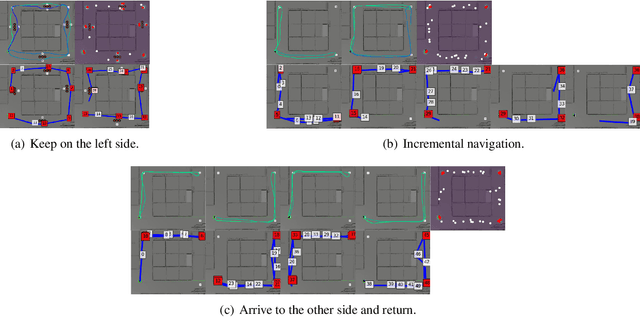
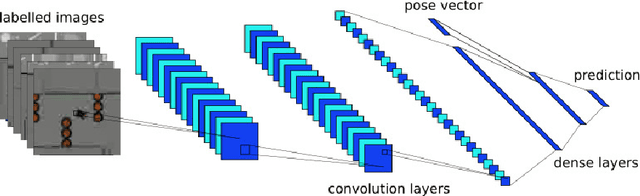
Semi-supervised learning improves the performance of supervised machine learning by leveraging methods from unsupervised learning to extract information not explicitly available in the labels. Through the design of a system that enables a robot to learn inspection strategies from a human operator, we present a hybrid semi-supervised system capable of learning interpretable and verifiable models from demonstrations. The system induces a controller program by learning from immersive demonstrations using sequential importance sampling. These visual servo controllers are parametrised by proportional gains and are visually verifiable through observation of the position of the robot in the environment. Clustering and effective particle size filtering allows the system to discover goals in the state space. These goals are used to label the original demonstration for end-to-end learning of behavioural models. The behavioural models are used for autonomous model predictive control and scrutinised for explanations. We implement causal sensitivity analysis to identify salient objects and generate counterfactual conditional explanations. These features enable decision making interpretation and post hoc discovery of the causes of a failure. The proposed system expands on previous approaches to program synthesis by incorporating repellers in the attribution prior of the sampling process. We successfully learn the hybrid system from an inspection scenario where an unmanned ground vehicle has to inspect, in a specific order, different areas of the environment. The system induces an interpretable computer program of the demonstration that can be synthesised to produce novel inspection behaviours. Importantly, the robot successfully runs the synthesised program on an unseen configuration of the environment while presenting explanations of its autonomous behaviour.
* In Proceedings AREA 2020, arXiv:2007.11260
Self-Assessment of Grasp Affordance Transfer
Jul 04, 2020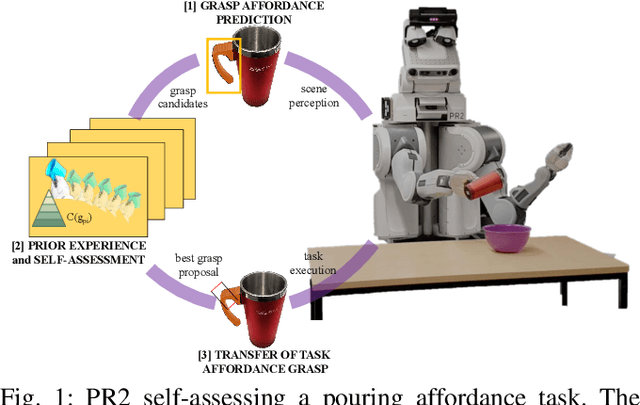
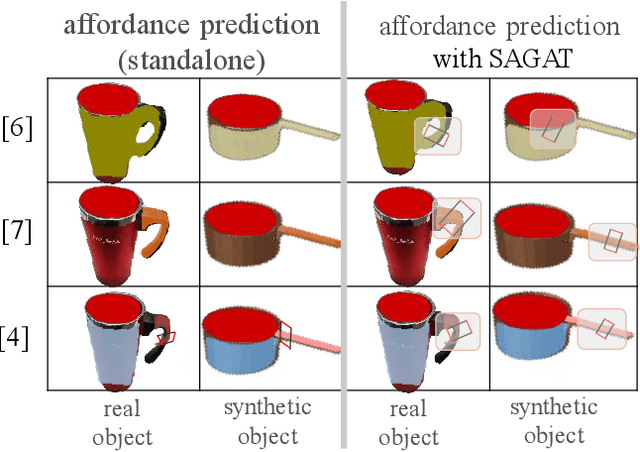
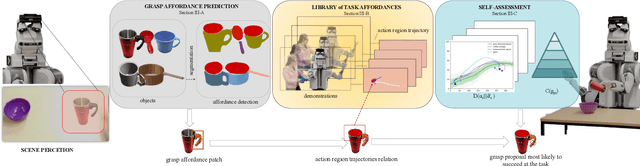
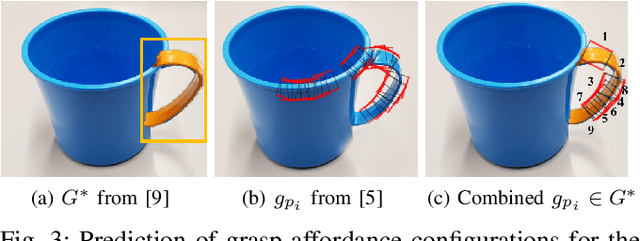
Reasoning about object grasp affordances allows an autonomous agent to estimate the most suitable grasp to execute a task. While current approaches for estimating grasp affordances are effective, their prediction is driven by hypotheses on visual features rather than an indicator of a proposal's suitability for an affordance task. Consequently, these works cannot guarantee any level of performance when executing a task and, in fact, not even ensure successful task completion. In this work, we present a pipeline for SAGAT based on prior experiences. We visually detect a grasp affordance region to extract multiple grasp affordance configuration candidates. Using these candidates, we forward simulate the outcome of executing the affordance task to analyse the relation between task outcome and grasp candidates. The relations are ranked by performance success with a heuristic confidence function and used to build a library of affordance task experiences. The library is later queried to perform one-shot transfer estimation of the best grasp configuration on new objects. Experimental evaluation shows that our method exhibits a significant performance improvement up to 11.7% against current state-of-the-art methods on grasp affordance detection. Experiments on a PR2 robotic platform demonstrate our method's highly reliable deployability to deal with real-world task affordance problems.
Learning from Demonstration with Weakly Supervised Disentanglement
Jun 16, 2020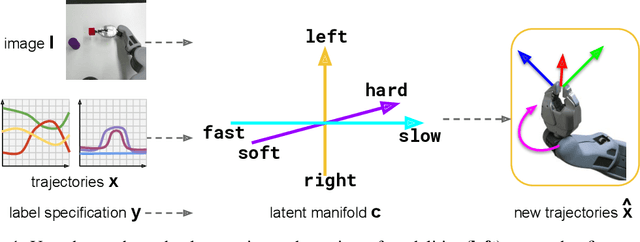
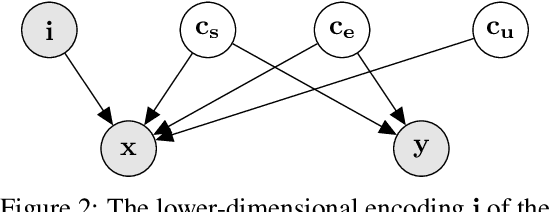
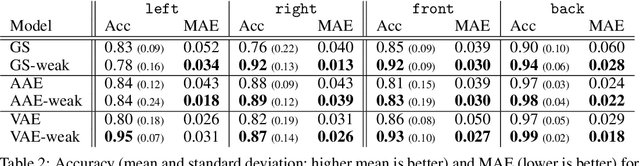
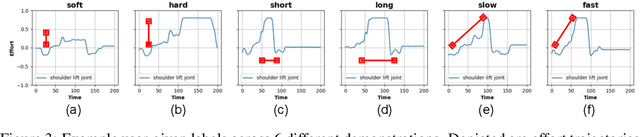
Robotic manipulation tasks, such as wiping with a soft sponge, require control from multiple rich sensory modalities. Human-robot interaction, aimed at teaching robots, is difficult in this setting as there is potential for mismatch between human and machine comprehension of the rich data streams. We treat the task of interpretable learning from demonstration as an optimisation problem over a probabilistic generative model. To account for the high-dimensionality of the data, a high-capacity neural network is chosen to represent the model. The latent variables in this model are explicitly aligned with high-level notions and concepts that are manifested in a set of demonstrations. We show that such alignment is best achieved through the use of labels from the end user, in an appropriately restricted vocabulary, in contrast to the conventional approach of the designer picking a prior over the latent variables. Our approach is evaluated in the context of a table-top robot manipulation task performed by a PR2 robot -- that of dabbing liquids with a sponge (forcefully pressing a sponge and moving it along a surface). The robot provides visual information, arm joint positions and arm joint efforts. We have made videos of the task and data available - see supplementary materials at https://sites.google.com/view/weak-label-lfd
From Demonstrations to Task-Space Specifications: Using Causal Analysis to Extract Rule Parameterization from Demonstrations
Jun 08, 2020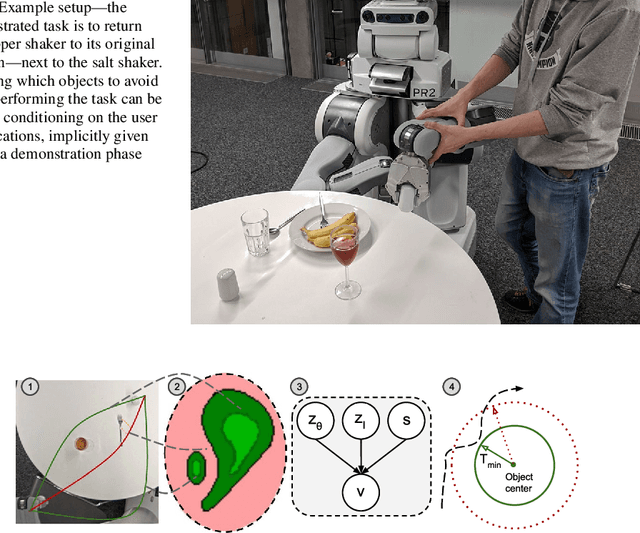

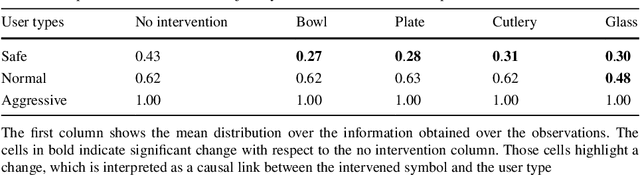
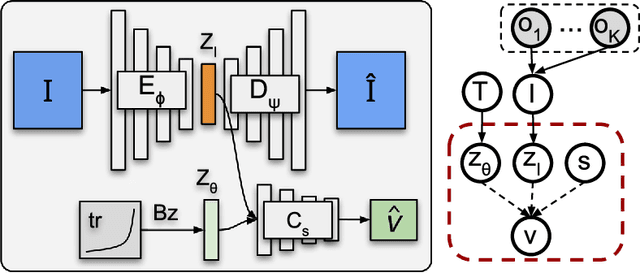
Learning models of user behaviour is an important problem that is broadly applicable across many application domains requiring human-robot interaction. In this work, we show that it is possible to learn generative models for distinct user behavioural types, extracted from human demonstrations, by enforcing clustering of preferred task solutions within the latent space. We use these models to differentiate between user types and to find cases with overlapping solutions. Moreover, we can alter an initially guessed solution to satisfy the preferences that constitute a particular user type by backpropagating through the learned differentiable models. An advantage of structuring generative models in this way is that we can extract causal relationships between symbols that might form part of the user's specification of the task, as manifested in the demonstrations. We further parameterize these specifications through constraint optimization in order to find a safety envelope under which motion planning can be performed. We show that the proposed method is capable of correctly distinguishing between three user types, who differ in degrees of cautiousness in their motion, while performing the task of moving objects with a kinesthetically driven robot in a tabletop environment. Our method successfully identifies the correct type, within the specified time, in 99% [97.8 - 99.8] of the cases, which outperforms an IRL baseline. We also show that our proposed method correctly changes a default trajectory to one satisfying a particular user specification even with unseen objects. The resulting trajectory is shown to be directly implementable on a PR2 humanoid robot completing the same task.