 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplications and Techniques for Fast Machine Learning in Science
Oct 25, 2021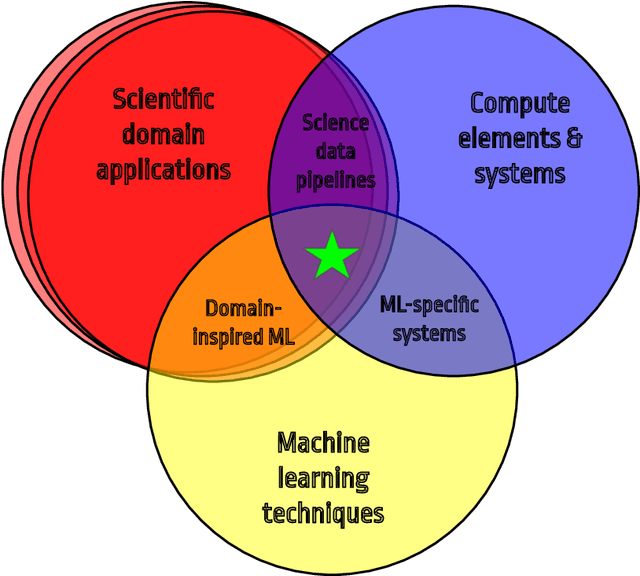
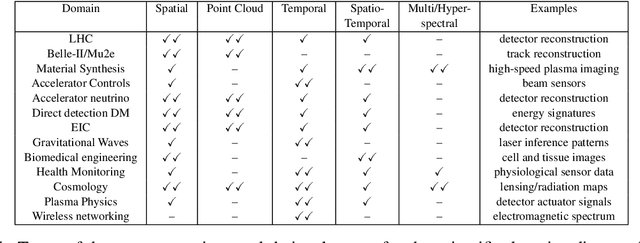
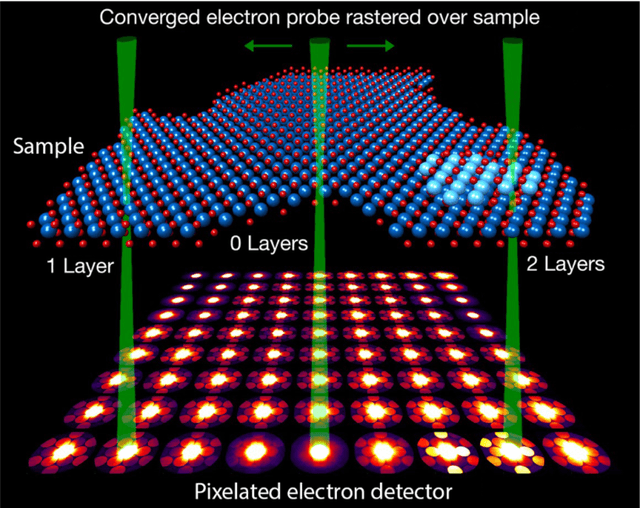
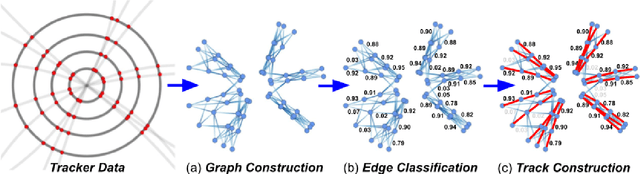
In this community review report, we discuss applications and techniques for fast machine learning (ML) in science -- the concept of integrating power ML methods into the real-time experimental data processing loop to accelerate scientific discovery. The material for the report builds on two workshops held by the Fast ML for Science community and covers three main areas: applications for fast ML across a number of scientific domains; techniques for training and implementing performant and resource-efficient ML algorithms; and computing architectures, platforms, and technologies for deploying these algorithms. We also present overlapping challenges across the multiple scientific domains where common solutions can be found. This community report is intended to give plenty of examples and inspiration for scientific discovery through integrated and accelerated ML solutions. This is followed by a high-level overview and organization of technical advances, including an abundance of pointers to source material, which can enable these breakthroughs.
Active Altruism Learning and Information Sufficiency for Autonomous Driving
Oct 09, 2021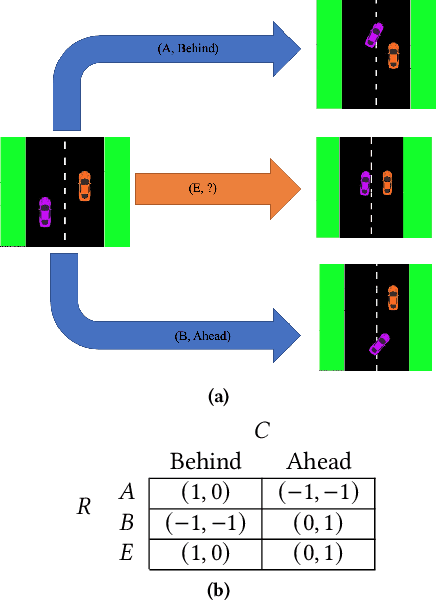
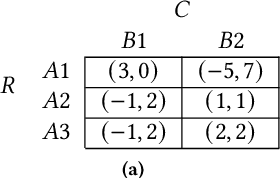
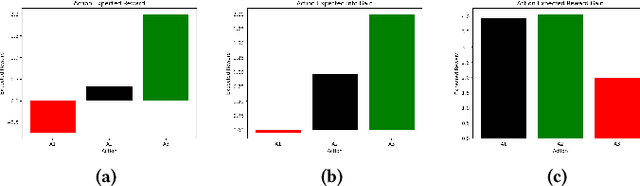
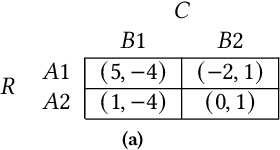
Safe interaction between vehicles requires the ability to choose actions that reveal the preferences of the other vehicles. Since exploratory actions often do not directly contribute to their objective, an interactive vehicle must also able to identify when it is appropriate to perform them. In this work we demonstrate how Active Learning methods can be used to incentivise an autonomous vehicle (AV) to choose actions that reveal information about the altruistic inclinations of another vehicle. We identify a property, Information Sufficiency, that a reward function should have in order to keep exploration from unnecessarily interfering with the pursuit of an objective. We empirically demonstrate that reward functions that do not have Information Sufficiency are prone to inadequate exploration, which can result in sub-optimal behaviour. We propose a reward definition that has Information Sufficiency, and show that it facilitates an AV choosing exploratory actions to estimate altruistic tendency, whilst also compensating for the possibility of conflicting beliefs between vehicles.
Beyond Discriminant Patterns: On the Robustness of Decision Rule Ensembles
Sep 21, 2021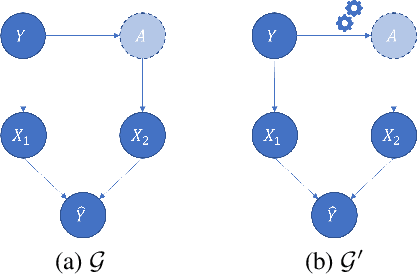
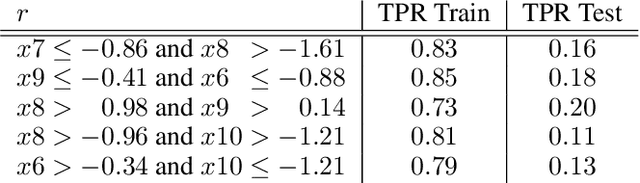

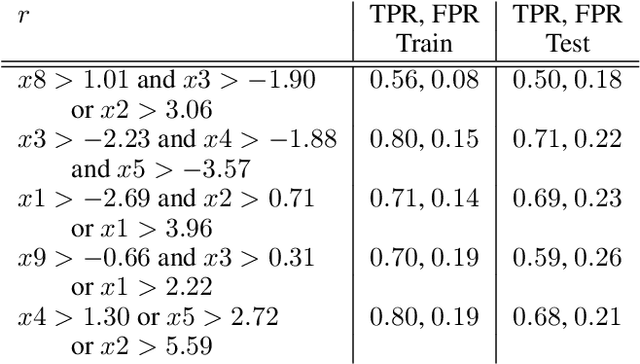
Local decision rules are commonly understood to be more explainable, due to the local nature of the patterns involved. With numerical optimization methods such as gradient boosting, ensembles of local decision rules can gain good predictive performance on data involving global structure. Meanwhile, machine learning models are being increasingly used to solve problems in high-stake domains including healthcare and finance. Here, there is an emerging consensus regarding the need for practitioners to understand whether and how those models could perform robustly in the deployment environments, in the presence of distributional shifts. Past research on local decision rules has focused mainly on maximizing discriminant patterns, without due consideration of robustness against distributional shifts. In order to fill this gap, we propose a new method to learn and ensemble local decision rules, that are robust both in the training and deployment environments. Specifically, we propose to leverage causal knowledge by regarding the distributional shifts in subpopulations and deployment environments as the results of interventions on the underlying system. We propose two regularization terms based on causal knowledge to search for optimal and stable rules. Experiments on both synthetic and benchmark datasets show that our method is effective and robust against distributional shifts in multiple environments.
Automated Testing with Temporal Logic Specifications for Robotic Controllers using Adaptive Experiment Design
Sep 16, 2021
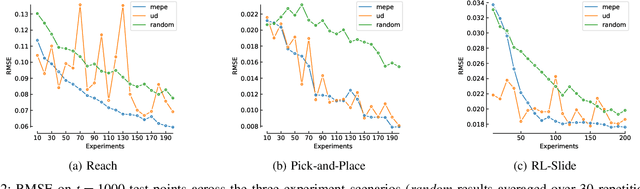
Many robot control scenarios involve assessing system robustness against a task specification. If either the controller or environment are composed of "black-box" components with unknown dynamics, we cannot rely on formal verification to assess our system. Assessing robustness via exhaustive testing is also often infeasible if the space of environments is large compared to experiment cost. Given limited budget, we provide a method to choose experiment inputs which give greatest insight into system performance against a given specification across the domain. By combining smooth robustness metrics for signal temporal logic with techniques from adaptive experiment design, our method chooses the most informative experimental inputs by incrementally constructing a surrogate model of the specification robustness. This model then chooses the next experiment to be in an area where there is either high prediction error or uncertainty. Our experiments show how this adaptive experimental design technique results in sample-efficient descriptions of system robustness. Further, we show how to use the model built via the experiment design process to assess the behaviour of a data-driven control system under domain shift.
Attainment Regions in Feature-Parameter Space for High-Level Debugging in Autonomous Robots
Aug 06, 2021

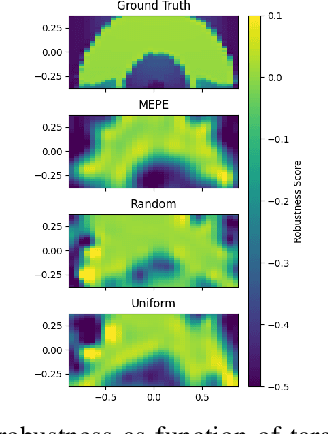
Understanding a controller's performance in different scenarios is crucial for robots that are going to be deployed in safety-critical tasks. If we do not have a model of the dynamics of the world, which is often the case in complex domains, we may need to approximate a performance function of the robot based on its interaction with the environment. Such a performance function gives us insights into the behaviour of the robot, allowing us to fine-tune the controller with manual interventions. In high-dimensionality systems, where the actionstate space is large, fine-tuning a controller is non-trivial. To overcome this problem, we propose a performance function whose domain is defined by external features and parameters of the controller. Attainment regions are defined over such a domain defined by feature-parameter pairs, and serve the purpose of enabling prediction of successful execution of the task. The use of the feature-parameter space -in contrast to the action-state space- allows us to adapt, explain and finetune the controller over a simpler (i.e., lower dimensional space). When the robot successfully executes the task, we use the attainment regions to gain insights into the limits of the controller, and its robustness. When the robot fails to execute the task, we use the regions to debug the controller and find adaptive and counterfactual changes to the solutions. Another advantage of this approach is that we can generalise through the use of Gaussian processes regression of the performance function in the high-dimensional space. To test our approach, we demonstrate learning an approximation to the performance function in simulation, with a mobile robot traversing different terrain conditions. Then, with a sample-efficient method, we propagate the attainment regions to a physical robot in a similar environment.
Interpretable Goal Recognition in the Presence of Occluded Factors for Autonomous Vehicles
Aug 05, 2021
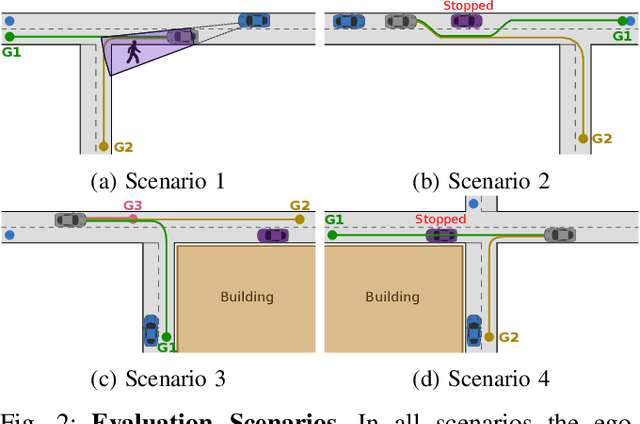
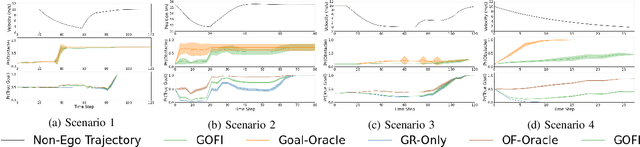
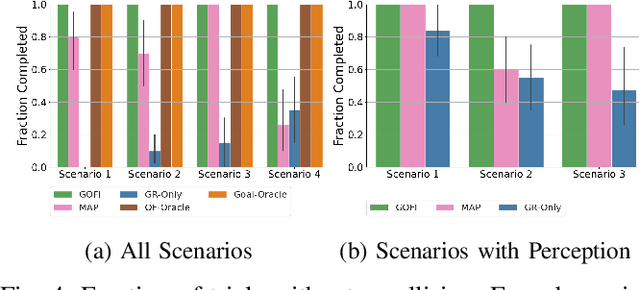
Recognising the goals or intentions of observed vehicles is a key step towards predicting the long-term future behaviour of other agents in an autonomous driving scenario. When there are unseen obstacles or occluded vehicles in a scenario, goal recognition may be confounded by the effects of these unseen entities on the behaviour of observed vehicles. Existing prediction algorithms that assume rational behaviour with respect to inferred goals may fail to make accurate long-horizon predictions because they ignore the possibility that the behaviour is influenced by such unseen entities. We introduce the Goal and Occluded Factor Inference (GOFI) algorithm which bases inference on inverse-planning to jointly infer a probabilistic belief over goals and potential occluded factors. We then show how these beliefs can be integrated into Monte Carlo Tree Search (MCTS). We demonstrate that jointly inferring goals and occluded factors leads to more accurate beliefs with respect to the true world state and allows an agent to safely navigate several scenarios where other baselines take unsafe actions leading to collisions.
Learning Time-Invariant Reward Functions through Model-Based Inverse Reinforcement Learning
Jul 07, 2021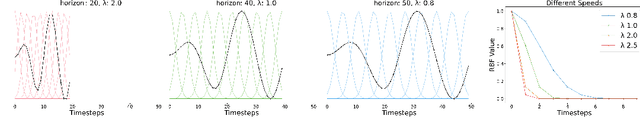
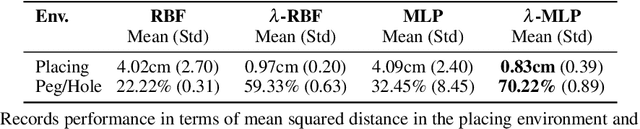

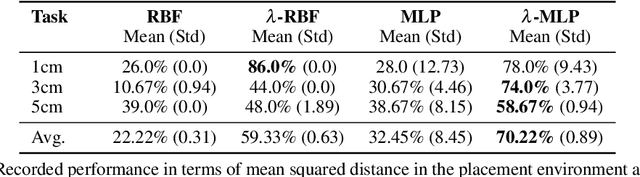
Inverse reinforcement learning is a paradigm motivated by the goal of learning general reward functions from demonstrated behaviours. Yet the notion of generality for learnt costs is often evaluated in terms of robustness to various spatial perturbations only, assuming deployment at fixed speeds of execution. However, this is impractical in the context of robotics and building time-invariant solutions is of crucial importance. In this work, we propose a formulation that allows us to 1) vary the length of execution by learning time-invariant costs, and 2) relax the temporal alignment requirements for learning from demonstration. We apply our method to two different types of cost formulations and evaluate their performance in the context of learning reward functions for simulated placement and peg in hole tasks. Our results show that our approach enables learning temporally invariant rewards from misaligned demonstration that can also generalise spatially to out of distribution tasks.
Building Affordance Relations for Robotic Agents - A Review
May 14, 2021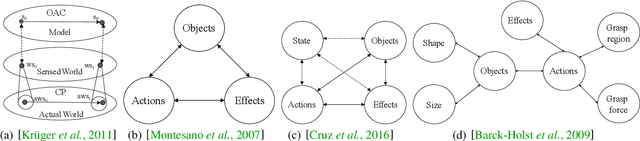

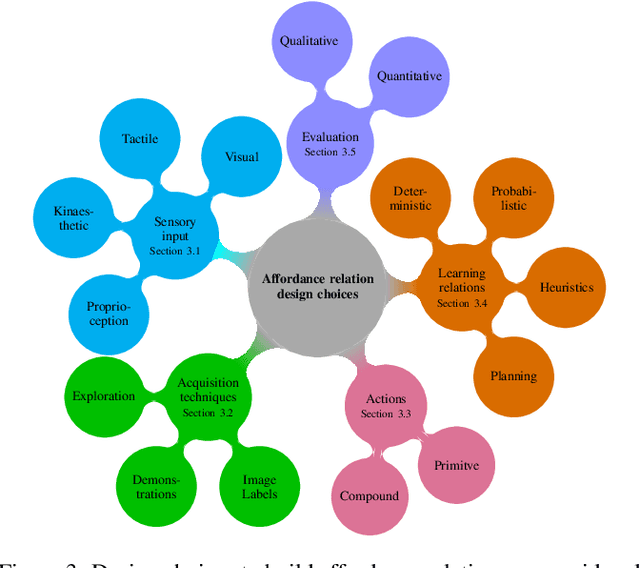
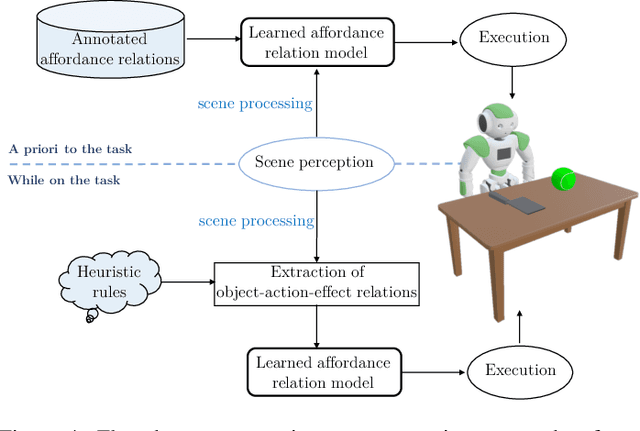
Affordances describe the possibilities for an agent to perform actions with an object. While the significance of the affordance concept has been previously studied from varied perspectives, such as psychology and cognitive science, these approaches are not always sufficient to enable direct transfer, in the sense of implementations, to artificial intelligence (AI)-based systems and robotics. However, many efforts have been made to pragmatically employ the concept of affordances, as it represents great potential for AI agents to effectively bridge perception to action. In this survey, we review and find common ground amongst different strategies that use the concept of affordances within robotic tasks, and build on these methods to provide guidance for including affordances as a mechanism to improve autonomy. To this end, we outline common design choices for building representations of affordance relations, and their implications on the generalisation capabilities of an agent when facing previously unseen scenarios. Finally, we identify and discuss a range of interesting research directions involving affordances that have the potential to improve the capabilities of an AI agent.
Learning data association without data association: An EM approach to neural assignment prediction
May 02, 2021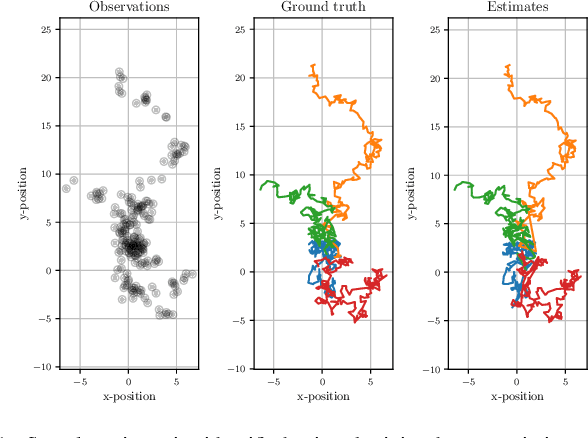
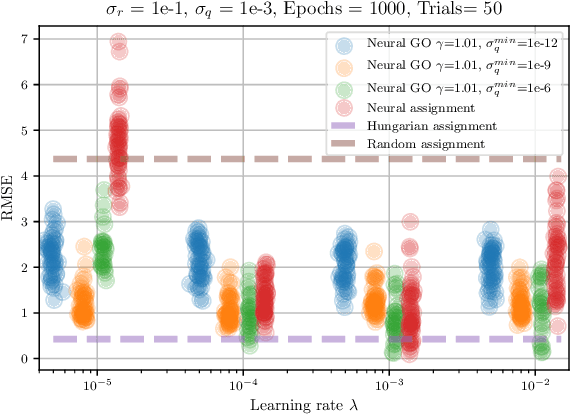
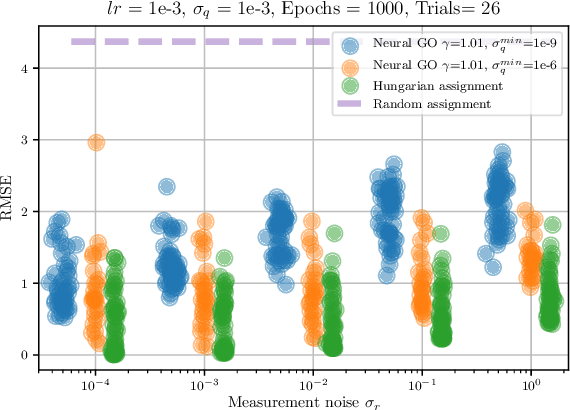
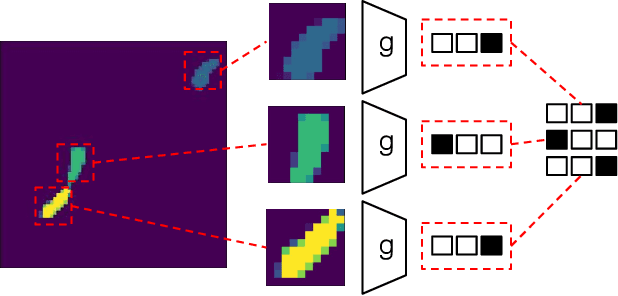
Data association is a fundamental component of effective multi-object tracking. Current approaches to data-association tend to frame this as an assignment problem relying on gating and distance-based cost matrices, or offset the challenge of data association to a problem of tracking by detection. The latter is typically formulated as a supervised learning problem, and requires labelling information about tracked object identities to train a model for object recognition. This paper introduces an expectation maximisation approach to train neural models for data association, which does not require labelling information. Here, a Sinkhorn network is trained to predict assignment matrices that maximise the marginal likelihood of trajectory observations. Importantly, networks trained using the proposed approach can be re-used in downstream tracking applications.
Formation Control for UAVs Using a Flux Guided Approach
Mar 16, 2021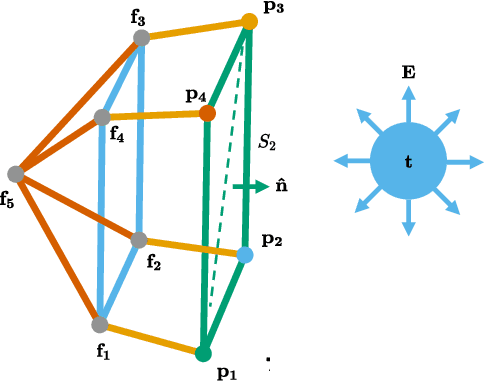
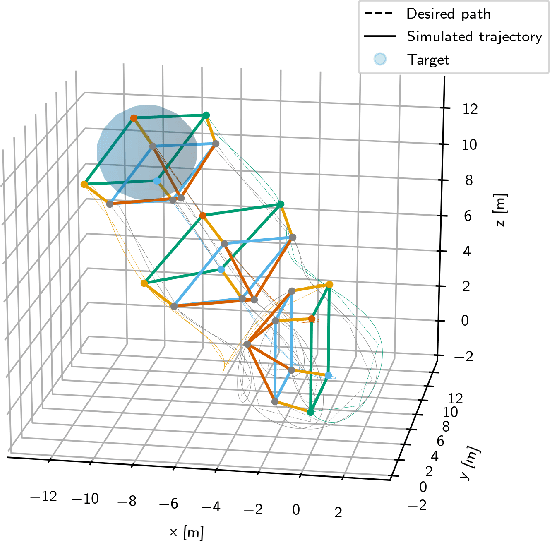
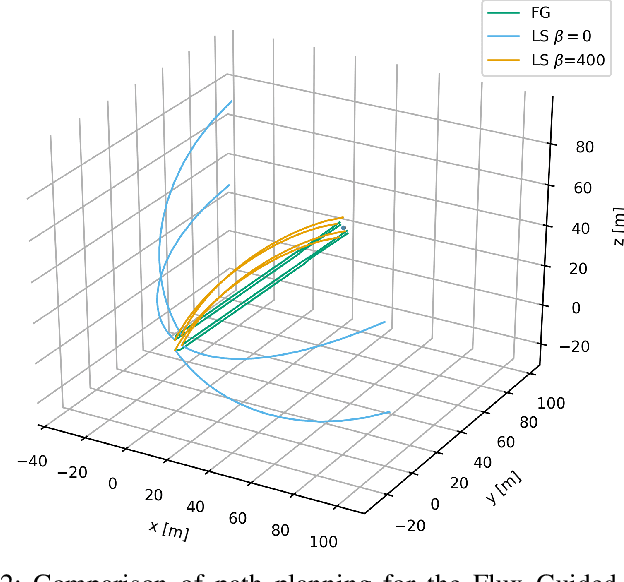
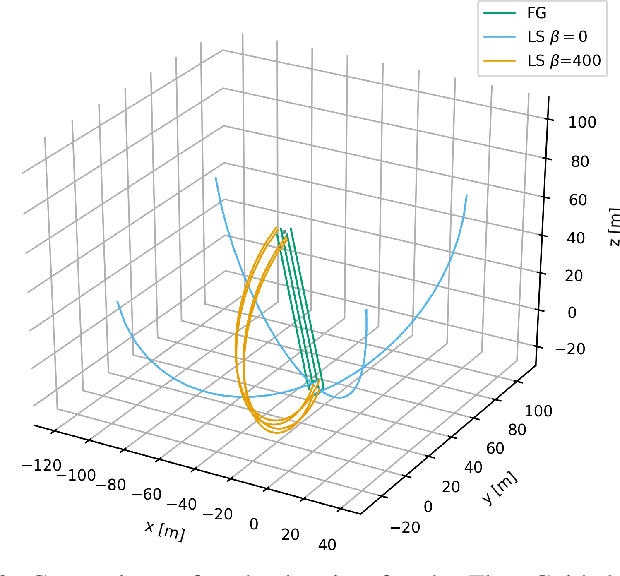
While multiple studies have proposed methods for the formation control of unmanned aerial vehicles (UAV), the trajectories generated are generally unsuitable for tracking targets where the optimum coverage of the target by the formation is required at all times. We propose a path planning approach called the Flux Guided (FG) method, which generates collision-free trajectories while maximising the coverage of one or more targets. We show that by reformulating an existing least-squares flux minimisation problem as a constrained optimisation problem, the paths obtained are $1.5 \times$ shorter and track directly toward the target. Also, we demonstrate that the scale of the formation can be controlled during flight, and that this feature can be used to track multiple scattered targets. The method is highly scalable since the planning algorithm is only required for a sub-set of UAVs on the open boundary of the formation's surface. Finally, through simulating a 3d dynamic particle system that tracks the desired trajectories using a PID controller, we show that the resulting trajectories after time-optimal parameterisation are suitable for robotic controls.