 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Electronic Design Automation: A Handoff Perspective
Jun 18, 2026Electronic design automation (EDA) is inherently multi-stage and handoff-heavy. Design artifacts, flow scripts, and engineering decisions cross tool, session, and organizational boundaries before final implementation, signoff, or release. Each transfer carries explicit and implicit requirements that may not be fully captured by stage-local checks. LLM-based agents now invoke EDA tools directly, embed retrieved knowledge in executable scripts, and hand off state across sessions and stages. Once their outputs condition downstream engineering decisions, the transferred object must satisfy a handoff contract and meet the assumptions of its next consumer. This survey introduces handoff validity as its organizing principle. A handoff is valid when the transferred object satisfies the consumer's acceptance conditions and carries sufficient context, evidence, and provenance for downstream use. We review 82 systems and classify them into three boundary classes. Stage-Bound systems establish validity within a single EDA stage or bounded verification task. Flow-Bound systems preserve coherent workflow state across tools, invocations, and sessions. Organization-Bound systems maintain source grounding, provenance, scope, and admissibility across knowledge and authority boundaries. For each class, we analyze handoff contracts, handoff objects, coordination mechanisms, and open questions. These analyses motivate a five-layer EDA agent communication protocol (EACP), covering the agent discovery, agent message, tool invocation, workflow orchestration, and security and IP protocols. We aim to provide a common vocabulary and research agenda for trustworthy agentic EDA.
LLM-DSE: Searching Accelerator Parameters with LLM Agents
May 18, 2025



Even though high-level synthesis (HLS) tools mitigate the challenges of programming domain-specific accelerators (DSAs) by raising the abstraction level, optimizing hardware directive parameters remains a significant hurdle. Existing heuristic and learning-based methods struggle with adaptability and sample efficiency.We present LLM-DSE, a multi-agent framework designed specifically for optimizing HLS directives. Combining LLM with design space exploration (DSE), our explorer coordinates four agents: Router, Specialists, Arbitrator, and Critic. These multi-agent components interact with various tools to accelerate the optimization process. LLM-DSE leverages essential domain knowledge to identify efficient parameter combinations while maintaining adaptability through verbal learning from online interactions. Evaluations on the HLSyn dataset demonstrate that LLM-DSE achieves substantial $2.55\times$ performance gains over state-of-the-art methods, uncovering novel designs while reducing runtime. Ablation studies validate the effectiveness and necessity of the proposed agent interactions. Our code is open-sourced here: https://github.com/Nozidoali/LLM-DSE.
ChatEDA: A Large Language Model Powered Autonomous Agent for EDA
Aug 20, 2023The integration of a complex set of Electronic Design Automation (EDA) tools to enhance interoperability is a critical concern for circuit designers. Recent advancements in large language models (LLMs) have showcased their exceptional capabilities in natural language processing and comprehension, offering a novel approach to interfacing with EDA tools. This research paper introduces ChatEDA, an autonomous agent for EDA empowered by a large language model, AutoMage, complemented by EDA tools serving as executors. ChatEDA streamlines the design flow from the Register-Transfer Level (RTL) to the Graphic Data System Version II (GDSII) by effectively managing task planning, script generation, and task execution. Through comprehensive experimental evaluations, ChatEDA has demonstrated its proficiency in handling diverse requirements, and our fine-tuned AutoMage model has exhibited superior performance compared to GPT-4 and other similar LLMs.
Low Error-Rate Approximate Multiplier Design for DNNs with Hardware-Driven Co-Optimization
Oct 08, 2022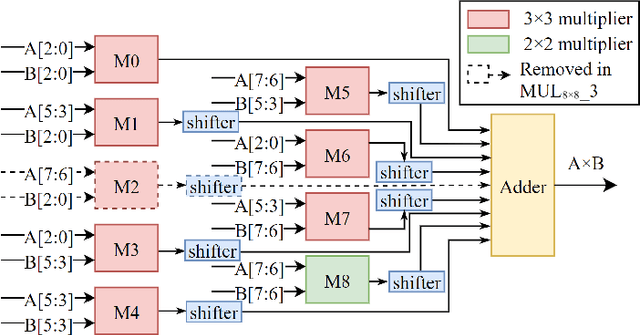
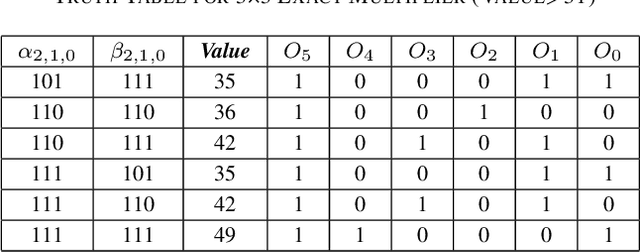
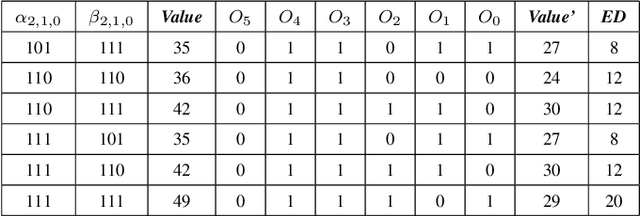
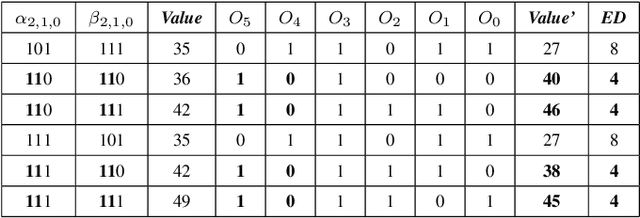
In this paper, two approximate 3*3 multipliers are proposed and the synthesis results of the ASAP-7nm process library justify that they can reduce the area by 31.38% and 36.17%, and the power consumption by 36.73% and 35.66% compared with the exact multiplier, respectively. They can be aggregated with a 2*2 multiplier to produce an 8*8 multiplier with low error rate based on the distribution of DNN weights. We propose a hardware-driven software co-optimization method to improve the DNN accuracy by retraining. Based on the proposed two approximate 3-bit multipliers, three approximate 8-bit multipliers with low error-rate are designed for DNNs. Compared with the exact 8-bit unsigned multiplier, our design can achieve a significant advantage over other approximate multipliers on the public dataset.
HEAM: High-Efficiency Approximate Multiplier Optimization for Deep Neural Networks
Jan 25, 2022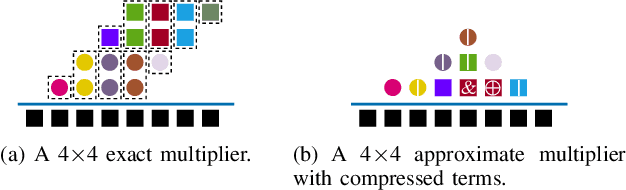

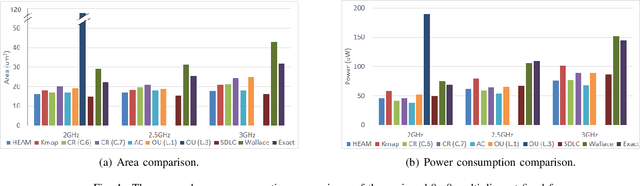

We propose an optimization method for the automatic design of approximate multipliers, which minimizes the average error according to the operand distributions. Our multiplier achieves up to 50.24% higher accuracy than the best reproduced approximate multiplier in DNNs, with 15.76% smaller area, 25.05% less power consumption, and 3.50% shorter delay. Compared with an exact multiplier, our multiplier reduces the area, power consumption, and delay by 44.94%, 47.63%, and 16.78%, respectively, with negligible accuracy losses. The tested DNN accelerator modules with our multiplier obtain up to 18.70% smaller area and 9.99% less power consumption than the original modules.