 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-DSE: Searching Accelerator Parameters with LLM Agents
May 18, 2025



Even though high-level synthesis (HLS) tools mitigate the challenges of programming domain-specific accelerators (DSAs) by raising the abstraction level, optimizing hardware directive parameters remains a significant hurdle. Existing heuristic and learning-based methods struggle with adaptability and sample efficiency.We present LLM-DSE, a multi-agent framework designed specifically for optimizing HLS directives. Combining LLM with design space exploration (DSE), our explorer coordinates four agents: Router, Specialists, Arbitrator, and Critic. These multi-agent components interact with various tools to accelerate the optimization process. LLM-DSE leverages essential domain knowledge to identify efficient parameter combinations while maintaining adaptability through verbal learning from online interactions. Evaluations on the HLSyn dataset demonstrate that LLM-DSE achieves substantial $2.55\times$ performance gains over state-of-the-art methods, uncovering novel designs while reducing runtime. Ablation studies validate the effectiveness and necessity of the proposed agent interactions. Our code is open-sourced here: https://github.com/Nozidoali/LLM-DSE.
UNIT: Unifying Tensorized Instruction Compilation
Jan 21, 2021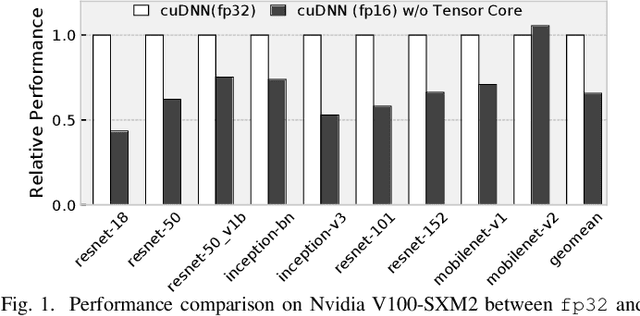
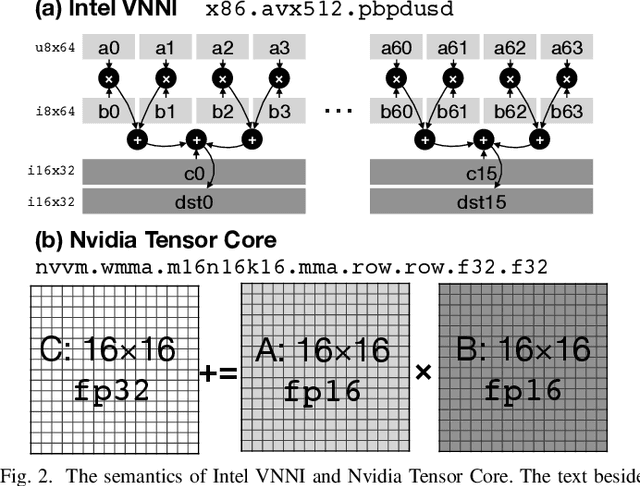
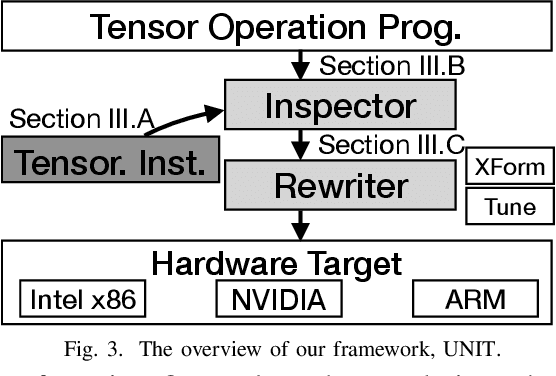

Because of the increasing demand for computation in DNN, researchers develope both hardware and software mechanisms to reduce the compute and memory burden. A widely adopted approach is to use mixed precision data types. However, it is hard to leverage mixed precision without hardware support because of the overhead of data casting. Hardware vendors offer tensorized instructions for mixed-precision tensor operations, like Intel VNNI, Tensor Core, and ARM-DOT. These instructions involve a computing idiom that reduces multiple low precision elements into one high precision element. The lack of compilation techniques for this makes it hard to utilize these instructions: Using vendor-provided libraries for computationally-intensive kernels is inflexible and prevents further optimizations, and manually writing hardware intrinsics is error-prone and difficult for programmers. Some prior works address this problem by creating compilers for each instruction. This requires excessive effort when it comes to many tensorized instructions. In this work, we develop a compiler framework to unify the compilation for these instructions -- a unified semantics abstraction eases the integration of new instructions, and reuses the analysis and transformations. Tensorized instructions from different platforms can be compiled via UNIT with moderate effort for favorable performance. Given a tensorized instruction and a tensor operation, UNIT automatically detects the applicability, transforms the loop organization of the operation,and rewrites the loop body to leverage the tensorized instruction. According to our evaluation, UNIT can target various mainstream hardware platforms. The generated end-to-end inference model achieves 1.3x speedup over Intel oneDNN on an x86 CPU, 1.75x speedup over Nvidia cuDNN on an NvidiaGPU, and 1.13x speedup over a carefully tuned TVM solution for ARM DOT on an ARM CPU.
Hardware Acceleration of Sparse and Irregular Tensor Computations of ML Models: A Survey and Insights
Jul 02, 2020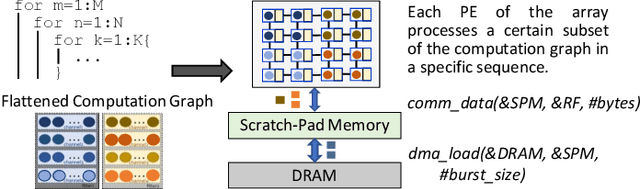


Machine learning (ML) models are widely used in many domains including media processing and generation, computer vision, medical diagnosis, embedded systems, high-performance and scientific computing, and recommendation systems. For efficiently processing these computational- and memory-intensive applications, tensors of these over-parameterized models are compressed by leveraging sparsity, size reduction, and quantization of tensors. Unstructured sparsity and tensors with varying dimensions yield irregular-shaped computation, communication, and memory access patterns; processing them on hardware accelerators in a conventional manner does not inherently leverage acceleration opportunities. This paper provides a comprehensive survey on how to efficiently execute sparse and irregular tensor computations of ML models on hardware accelerators. In particular, it discusses additional enhancement modules in architecture design and software support; categorizes different hardware designs and acceleration techniques and analyzes them in terms of hardware and execution costs; highlights further opportunities in terms of hardware/software/algorithm co-design optimizations and joint optimizations among described hardware and software enhancement modules. The takeaways from this paper include: understanding the key challenges in accelerating sparse, irregular-shaped, and quantized tensors; understanding enhancements in acceleration systems for supporting their efficient computations; analyzing trade-offs in opting for a specific type of design enhancement; understanding how to map and compile models with sparse tensors on the accelerators; understanding recent design trends for efficient accelerations and further opportunities.