 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Trustworthiness of AI Disease Severity Rating in Medical Imaging with Ordinal Conformal Prediction Sets
Jul 05, 2022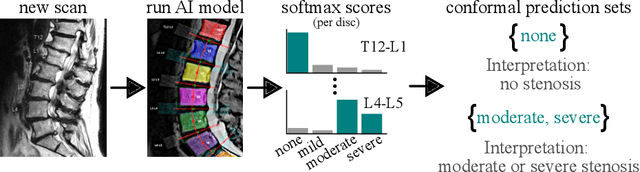
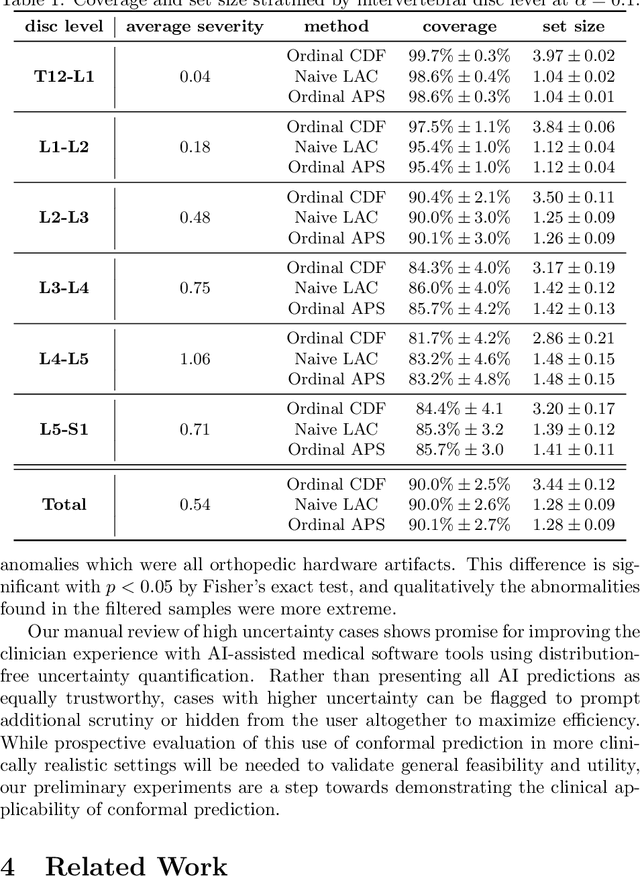
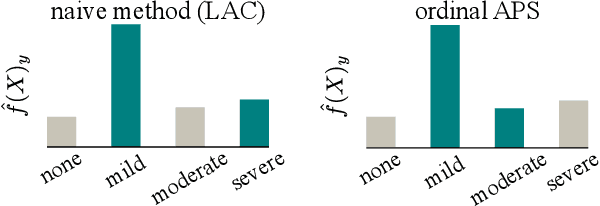
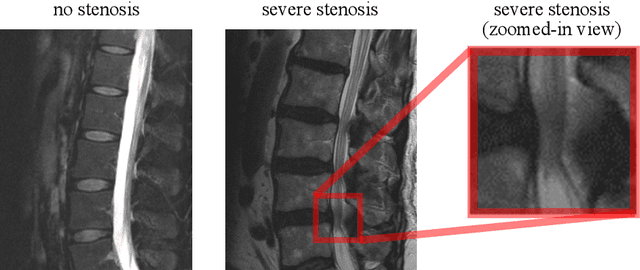
The regulatory approval and broad clinical deployment of medical AI have been hampered by the perception that deep learning models fail in unpredictable and possibly catastrophic ways. A lack of statistically rigorous uncertainty quantification is a significant factor undermining trust in AI results. Recent developments in distribution-free uncertainty quantification present practical solutions for these issues by providing reliability guarantees for black-box models on arbitrary data distributions as formally valid finite-sample prediction intervals. Our work applies these new uncertainty quantification methods -- specifically conformal prediction -- to a deep-learning model for grading the severity of spinal stenosis in lumbar spine MRI. We demonstrate a technique for forming ordinal prediction sets that are guaranteed to contain the correct stenosis severity within a user-defined probability (confidence interval). On a dataset of 409 MRI exams processed by the deep-learning model, the conformal method provides tight coverage with small prediction set sizes. Furthermore, we explore the potential clinical applicability of flagging cases with high uncertainty predictions (large prediction sets) by quantifying an increase in the prevalence of significant imaging abnormalities (e.g. motion artifacts, metallic artifacts, and tumors) that could degrade confidence in predictive performance when compared to a random sample of cases.
Deploying clinical machine learning? Consider the following...
Sep 14, 2021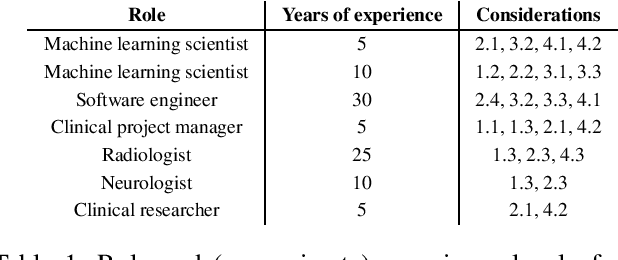
Despite the intense attention and investment into clinical machine learning (CML) research, relatively few applications convert to clinical practice. While research is important in advancing the state-of-the-art, translation is equally important in bringing these technologies into a position to ultimately impact patient care and live up to extensive expectations surrounding AI in healthcare. To better characterize a holistic perspective among researchers and practitioners, we survey several participants with experience in developing CML for clinical deployment about their learned experiences. We collate these insights and identify several main categories of barriers and pitfalls in order to better design and develop clinical machine learning applications.