 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Language Models' Success at Zero-Shot Probabilistic Prediction
Sep 18, 2025Recent work has investigated the capabilities of large language models (LLMs) as zero-shot models for generating individual-level characteristics (e.g., to serve as risk models or augment survey datasets). However, when should a user have confidence that an LLM will provide high-quality predictions for their particular task? To address this question, we conduct a large-scale empirical study of LLMs' zero-shot predictive capabilities across a wide range of tabular prediction tasks. We find that LLMs' performance is highly variable, both on tasks within the same dataset and across different datasets. However, when the LLM performs well on the base prediction task, its predicted probabilities become a stronger signal for individual-level accuracy. Then, we construct metrics to predict LLMs' performance at the task level, aiming to distinguish between tasks where LLMs may perform well and where they are likely unsuitable. We find that some of these metrics, each of which are assessed without labeled data, yield strong signals of LLMs' predictive performance on new tasks.
AttentionInfluence: Adopting Attention Head Influence for Weak-to-Strong Pretraining Data Selection
May 12, 2025Recently, there has been growing interest in collecting reasoning-intensive pretraining data to improve LLMs' complex reasoning ability. Prior approaches typically rely on supervised classifiers to identify such data, which requires labeling by humans or LLMs, often introducing domain-specific biases. Due to the attention heads being crucial to in-context reasoning, we propose AttentionInfluence, a simple yet effective, training-free method without supervision signal. Our approach enables a small pretrained language model to act as a strong data selector through a simple attention head masking operation. Specifically, we identify retrieval heads and compute the loss difference when masking these heads. We apply AttentionInfluence to a 1.3B-parameter dense model to conduct data selection on the SmolLM corpus of 241B tokens, and mix the SmolLM corpus with the selected subset comprising 73B tokens to pretrain a 7B-parameter dense model using 1T training tokens and WSD learning rate scheduling. Our experimental results demonstrate substantial improvements, ranging from 1.4pp to 3.5pp, across several knowledge-intensive and reasoning-heavy benchmarks (i.e., MMLU, MMLU-Pro, AGIEval-en, GSM8K, and HumanEval). This demonstrates an effective weak-to-strong scaling property, with small models improving the final performance of larger models-offering a promising and scalable path for reasoning-centric data selection.
Winning the MIDST Challenge: New Membership Inference Attacks on Diffusion Models for Tabular Data Synthesis
Mar 15, 2025



Tabular data synthesis using diffusion models has gained significant attention for its potential to balance data utility and privacy. However, existing privacy evaluations often rely on heuristic metrics or weak membership inference attacks (MIA), leaving privacy risks inadequately assessed. In this work, we conduct a rigorous MIA study on diffusion-based tabular synthesis, revealing that state-of-the-art attacks designed for image models fail in this setting. We identify noise initialization as a key factor influencing attack efficacy and propose a machine-learning-driven approach that leverages loss features across different noises and time steps. Our method, implemented with a lightweight MLP, effectively learns membership signals, eliminating the need for manual optimization. Experimental results from the MIDST Challenge @ SaTML 2025 demonstrate the effectiveness of our approach, securing first place across all tracks. Code is available at https://github.com/Nicholas0228/Tartan_Federer_MIDST.
Revealing the Unseen: Guiding Personalized Diffusion Models to Expose Training Data
Oct 03, 2024



Diffusion Models (DMs) have evolved into advanced image generation tools, especially for few-shot fine-tuning where a pretrained DM is fine-tuned on a small set of images to capture specific styles or objects. Many people upload these personalized checkpoints online, fostering communities such as Civitai and HuggingFace. However, model owners may overlook the potential risks of data leakage by releasing their fine-tuned checkpoints. Moreover, concerns regarding copyright violations arise when unauthorized data is used during fine-tuning. In this paper, we ask: "Can training data be extracted from these fine-tuned DMs shared online?" A successful extraction would present not only data leakage threats but also offer tangible evidence of copyright infringement. To answer this, we propose FineXtract, a framework for extracting fine-tuning data. Our method approximates fine-tuning as a gradual shift in the model's learned distribution -- from the original pretrained DM toward the fine-tuning data. By extrapolating the models before and after fine-tuning, we guide the generation toward high-probability regions within the fine-tuned data distribution. We then apply a clustering algorithm to extract the most probable images from those generated using this extrapolated guidance. Experiments on DMs fine-tuned with datasets such as WikiArt, DreamBooth, and real-world checkpoints posted online validate the effectiveness of our method, extracting approximately 20% of fine-tuning data in most cases, significantly surpassing baseline performance.
Decision-Focused Uncertainty Quantification
Oct 02, 2024There is increasing interest in ''decision-focused'' machine learning methods which train models to account for how their predictions are used in downstream optimization problems. Doing so can often improve performance on subsequent decision problems. However, current methods for uncertainty quantification do not incorporate any information at all about downstream decisions. We develop a framework based on conformal prediction to produce prediction sets that account for a downstream decision loss function, making them more appropriate to inform high-stakes decision-making. Our approach harnesses the strengths of conformal methods--modularity, model-agnosticism, and statistical coverage guarantees--while incorporating downstream decisions and user-specified utility functions. We prove that our methods retain standard coverage guarantees. Empirical evaluation across a range of datasets and utility metrics demonstrates that our methods achieve significantly lower decision loss compared to standard conformal methods. Additionally, we present a real-world use case in healthcare diagnosis, where our method effectively incorporates the hierarchical structure of dermatological diseases. It successfully generates sets with coherent diagnostic meaning, aiding the triage process during dermatology diagnosis and illustrating how our method can ground high-stakes decision-making on external domain knowledge.
Oracle-Efficient Differentially Private Learning with Public Data
Feb 13, 2024Due to statistical lower bounds on the learnability of many function classes under privacy constraints, there has been recent interest in leveraging public data to improve the performance of private learning algorithms. In this model, algorithms must always guarantee differential privacy with respect to the private samples while also ensuring learning guarantees when the private data distribution is sufficiently close to that of the public data. Previous work has demonstrated that when sufficient public, unlabelled data is available, private learning can be made statistically tractable, but the resulting algorithms have all been computationally inefficient. In this work, we present the first computationally efficient, algorithms to provably leverage public data to learn privately whenever a function class is learnable non-privately, where our notion of computational efficiency is with respect to the number of calls to an optimization oracle for the function class. In addition to this general result, we provide specialized algorithms with improved sample complexities in the special cases when the function class is convex or when the task is binary classification.
A Sandbox Tool to Bias-Test Fairness Algorithms
Apr 21, 2022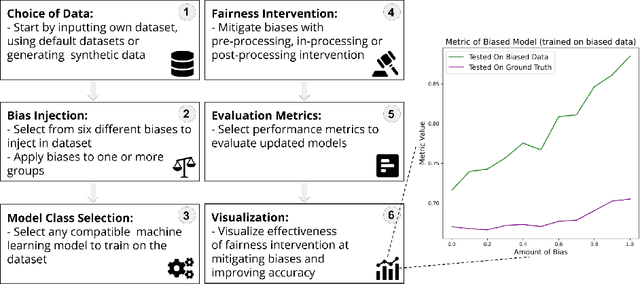
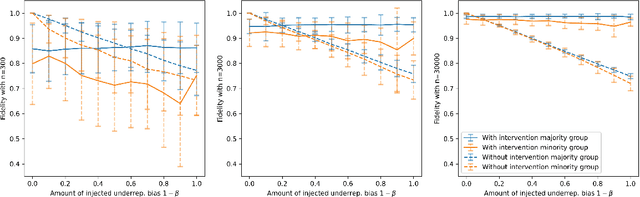
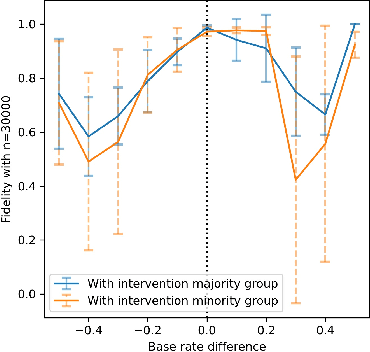
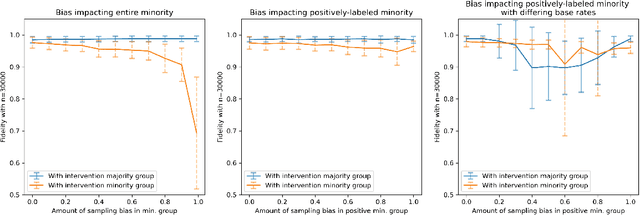
Motivated by the growing importance of reducing unfairness in ML predictions, Fair-ML researchers have presented an extensive suite of algorithmic "fairness-enhancing" remedies. Most existing algorithms, however, are agnostic to the sources of the observed unfairness. As a result, the literature currently lacks guiding frameworks to specify conditions under which each algorithmic intervention can potentially alleviate the underpinning cause of unfairness. To close this gap, we scrutinize the underlying biases (e.g., in the training data or design choices) that cause observational unfairness. We present a bias-injection sandbox tool to investigate fairness consequences of various biases and assess the effectiveness of algorithmic remedies in the presence of specific types of bias. We call this process the bias(stress)-testing of algorithmic interventions. Unlike existing toolkits, ours provides a controlled environment to counterfactually inject biases in the ML pipeline. This stylized setup offers the distinct capability of testing fairness interventions beyond observational data and against an unbiased benchmark. In particular, we can test whether a given remedy can alleviate the injected bias by comparing the predictions resulting after the intervention in the biased setting with true labels in the unbiased regime -- that is, before any bias injection. We illustrate the utility of our toolkit via a proof-of-concept case study on synthetic data. Our empirical analysis showcases the type of insights that can be obtained through our simulations.
The Disagreement Problem in Explainable Machine Learning: A Practitioner's Perspective
Feb 08, 2022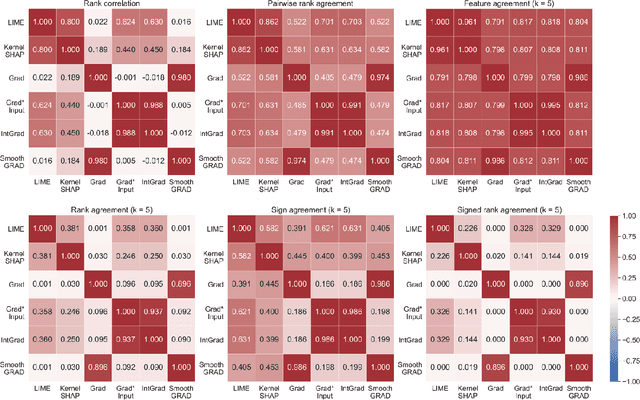

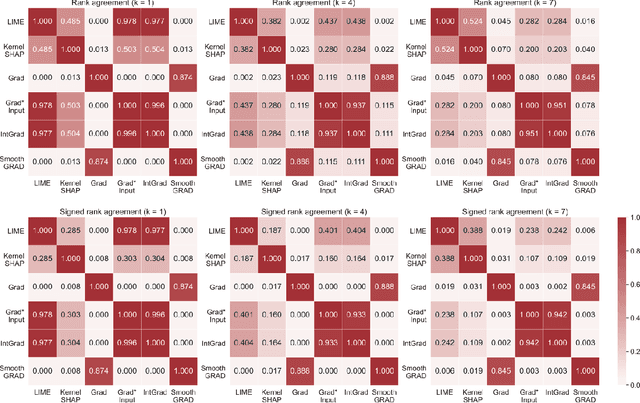
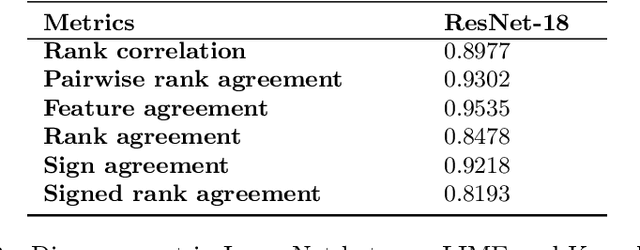
As various post hoc explanation methods are increasingly being leveraged to explain complex models in high-stakes settings, it becomes critical to develop a deeper understanding of if and when the explanations output by these methods disagree with each other, and how such disagreements are resolved in practice. However, there is little to no research that provides answers to these critical questions. In this work, we introduce and study the disagreement problem in explainable machine learning. More specifically, we formalize the notion of disagreement between explanations, analyze how often such disagreements occur in practice, and how do practitioners resolve these disagreements. To this end, we first conduct interviews with data scientists to understand what constitutes disagreement between explanations generated by different methods for the same model prediction, and introduce a novel quantitative framework to formalize this understanding. We then leverage this framework to carry out a rigorous empirical analysis with four real-world datasets, six state-of-the-art post hoc explanation methods, and eight different predictive models, to measure the extent of disagreement between the explanations generated by various popular explanation methods. In addition, we carry out an online user study with data scientists to understand how they resolve the aforementioned disagreements. Our results indicate that state-of-the-art explanation methods often disagree in terms of the explanations they output. Our findings also underscore the importance of developing principled evaluation metrics that enable practitioners to effectively compare explanations.
Value Cards: An Educational Toolkit for Teaching Social Impacts of Machine Learning through Deliberation
Oct 22, 2020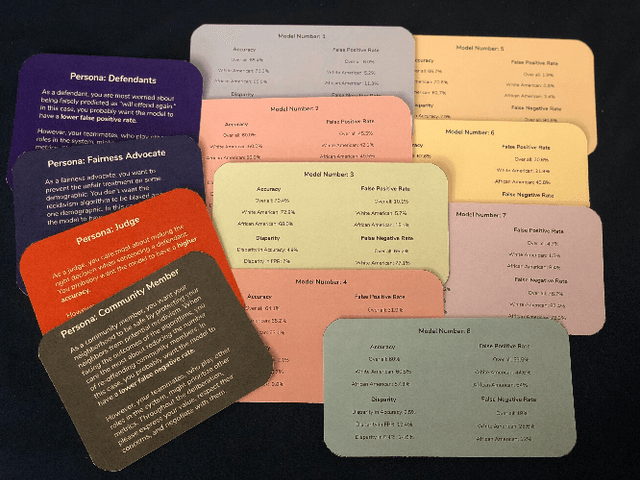
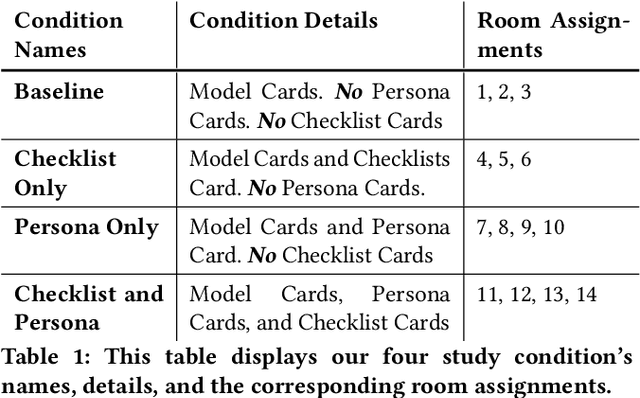
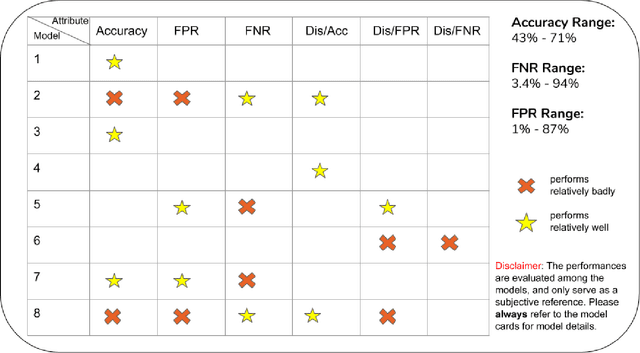

Recently, there have been increasing calls for computer science curricula to complement existing technical training with topics related to Fairness, Accountability, Transparency, and Ethics. In this paper, we present Value Card, an educational toolkit to inform students and practitioners of the social impacts of different machine learning models via deliberation. This paper presents an early use of our approach in a college-level computer science course. Through an in-class activity, we report empirical data for the initial effectiveness of our approach. Our results suggest that the use of the Value Cards toolkit can improve students' understanding of both the technical definitions and trade-offs of performance metrics and apply them in real-world contexts, help them recognize the significance of considering diverse social values in the development of deployment of algorithmic systems, and enable them to communicate, negotiate and synthesize the perspectives of diverse stakeholders. Our study also demonstrates a number of caveats we need to consider when using the different variants of the Value Cards toolkit. Finally, we discuss the challenges as well as future applications of our approach.