 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Name Classes for Vision and Language Models
Apr 04, 2023Large scale vision and language models can achieve impressive zero-shot recognition performance by mapping class specific text queries to image content. Two distinct challenges that remain however, are high sensitivity to the choice of handcrafted class names that define queries, and the difficulty of adaptation to new, smaller datasets. Towards addressing these problems, we propose to leverage available data to learn, for each class, an optimal word embedding as a function of the visual content. By learning new word embeddings on an otherwise frozen model, we are able to retain zero-shot capabilities for new classes, easily adapt models to new datasets, and adjust potentially erroneous, non-descriptive or ambiguous class names. We show that our solution can easily be integrated in image classification and object detection pipelines, yields significant performance gains in multiple scenarios and provides insights into model biases and labelling errors.
Tunable Convolutions with Parametric Multi-Loss Optimization
Apr 03, 2023Behavior of neural networks is irremediably determined by the specific loss and data used during training. However it is often desirable to tune the model at inference time based on external factors such as preferences of the user or dynamic characteristics of the data. This is especially important to balance the perception-distortion trade-off of ill-posed image-to-image translation tasks. In this work, we propose to optimize a parametric tunable convolutional layer, which includes a number of different kernels, using a parametric multi-loss, which includes an equal number of objectives. Our key insight is to use a shared set of parameters to dynamically interpolate both the objectives and the kernels. During training, these parameters are sampled at random to explicitly optimize all possible combinations of objectives and consequently disentangle their effect into the corresponding kernels. During inference, these parameters become interactive inputs of the model hence enabling reliable and consistent control over the model behavior. Extensive experimental results demonstrate that our tunable convolutions effectively work as a drop-in replacement for traditional convolutions in existing neural networks at virtually no extra computational cost, outperforming state-of-the-art control strategies in a wide range of applications; including image denoising, deblurring, super-resolution, and style transfer.
Region Proposal Network Pre-Training Helps Label-Efficient Object Detection
Nov 16, 2022Self-supervised pre-training, based on the pretext task of instance discrimination, has fueled the recent advance in label-efficient object detection. However, existing studies focus on pre-training only a feature extractor network to learn transferable representations for downstream detection tasks. This leads to the necessity of training multiple detection-specific modules from scratch in the fine-tuning phase. We argue that the region proposal network (RPN), a common detection-specific module, can additionally be pre-trained towards reducing the localization error of multi-stage detectors. In this work, we propose a simple pretext task that provides an effective pre-training for the RPN, towards efficiently improving downstream object detection performance. We evaluate the efficacy of our approach on benchmark object detection tasks and additional downstream tasks, including instance segmentation and few-shot detection. In comparison with multi-stage detectors without RPN pre-training, our approach is able to consistently improve downstream task performance, with largest gains found in label-scarce settings.
Content-Diverse Comparisons improve IQA
Nov 09, 2022



Image quality assessment (IQA) forms a natural and often straightforward undertaking for humans, yet effective automation of the task remains highly challenging. Recent metrics from the deep learning community commonly compare image pairs during training to improve upon traditional metrics such as PSNR or SSIM. However, current comparisons ignore the fact that image content affects quality assessment as comparisons only occur between images of similar content. This restricts the diversity and number of image pairs that the model is exposed to during training. In this paper, we strive to enrich these comparisons with content diversity. Firstly, we relax comparison constraints, and compare pairs of images with differing content. This increases the variety of available comparisons. Secondly, we introduce listwise comparisons to provide a holistic view to the model. By including differentiable regularizers, derived from correlation coefficients, models can better adjust predicted scores relative to one another. Evaluation on multiple benchmarks, covering a wide range of distortions and image content, shows the effectiveness of our learning scheme for training image quality assessment models.
CLAD: A realistic Continual Learning benchmark for Autonomous Driving
Oct 07, 2022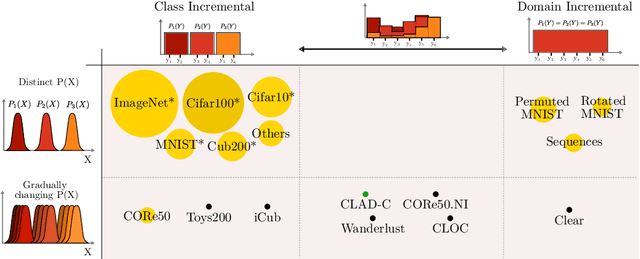

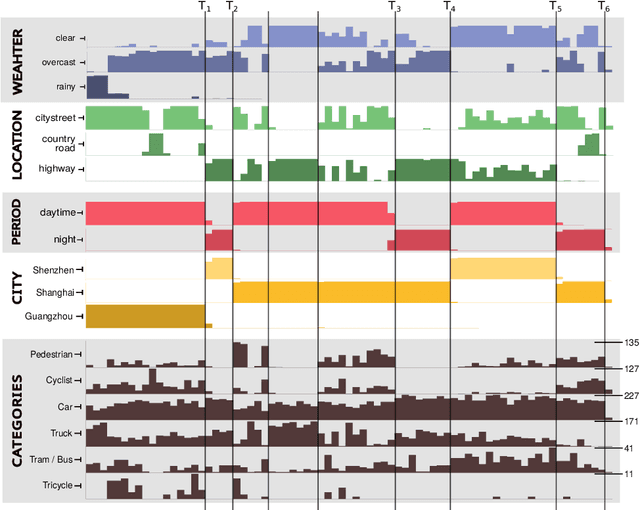
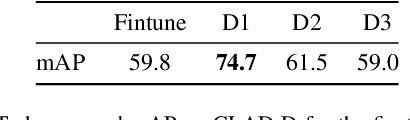
In this paper we describe the design and the ideas motivating a new Continual Learning benchmark for Autonomous Driving (CLAD), that focuses on the problems of object classification and object detection. The benchmark utilises SODA10M, a recently released large-scale dataset that concerns autonomous driving related problems. First, we review and discuss existing continual learning benchmarks, how they are related, and show that most are extreme cases of continual learning. To this end, we survey the benchmarks used in continual learning papers at three highly ranked computer vision conferences. Next, we introduce CLAD-C, an online classification benchmark realised through a chronological data stream that poses both class and domain incremental challenges; and CLAD-D, a domain incremental continual object detection benchmark. We examine the inherent difficulties and challenges posed by the benchmark, through a survey of the techniques and methods used by the top-3 participants in a CLAD-challenge workshop at ICCV 2021. We conclude with possible pathways to improve the current continual learning state of the art, and which directions we deem promising for future research.
Out-of-Distribution Detection with Class Ratio Estimation
Jun 08, 2022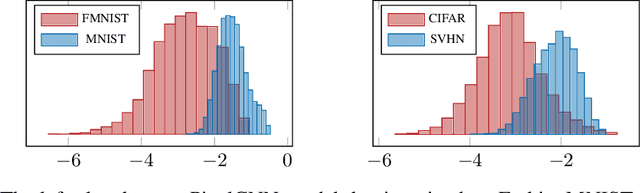
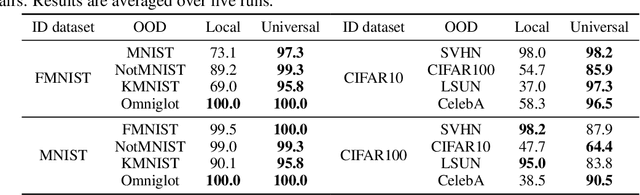
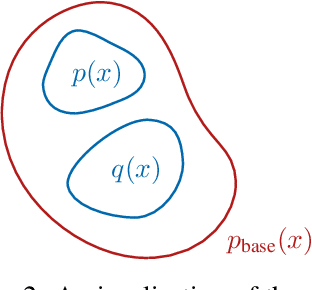
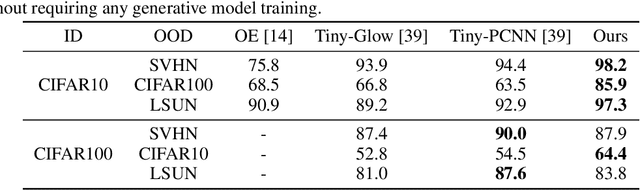
Density-based Out-of-distribution (OOD) detection has recently been shown unreliable for the task of detecting OOD images. Various density ratio based approaches achieve good empirical performance, however methods typically lack a principled probabilistic modelling explanation. In this work, we propose to unify density ratio based methods under a novel framework that builds energy-based models and employs differing base distributions. Under our framework, the density ratio can be viewed as the unnormalized density of an implicit semantic distribution. Further, we propose to directly estimate the density ratio of a data sample through class ratio estimation. We report competitive results on OOD image problems in comparison with recent work that alternatively requires training of deep generative models for the task. Our approach enables a simple and yet effective path towards solving the OOD detection problem.
Re-examining Distillation For Continual Object Detection
Apr 04, 2022
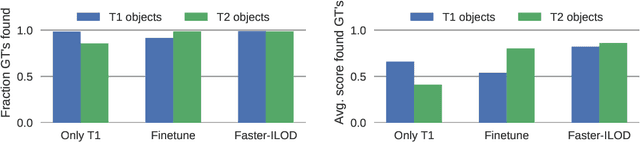


Training models continually to detect and classify objects, from new classes and new domains, remains an open problem. In this work, we conduct a thorough analysis of why and how object detection models forget catastrophically. We focus on distillation-based approaches in two-stage networks; the most-common strategy employed in contemporary continual object detection work.Distillation aims to transfer the knowledge of a model trained on previous tasks -- the teacher -- to a new model -- the student -- while it learns the new task. We show that this works well for the region proposal network, but that wrong, yet overly confident teacher predictions prevent student models from effective learning of the classification head. Our analysis provides a foundation that allows us to propose improvements for existing techniques by detecting incorrect teacher predictions, based on current ground-truth labels, and by employing an adaptive Huber loss as opposed to the mean squared error for the distillation loss in the classification heads. We evidence that our strategy works not only in a class incremental setting, but also in domain incremental settings, which constitute a realistic context, likely to be the setting of representative real-world problems.
CroMo: Cross-Modal Learning for Monocular Depth Estimation
Mar 28, 2022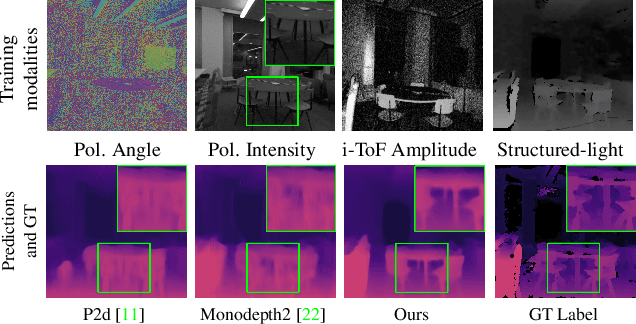
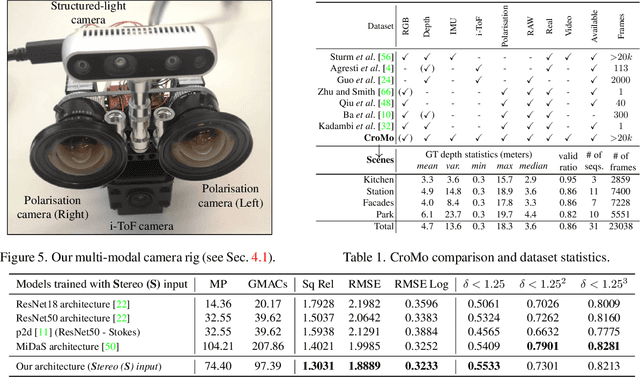

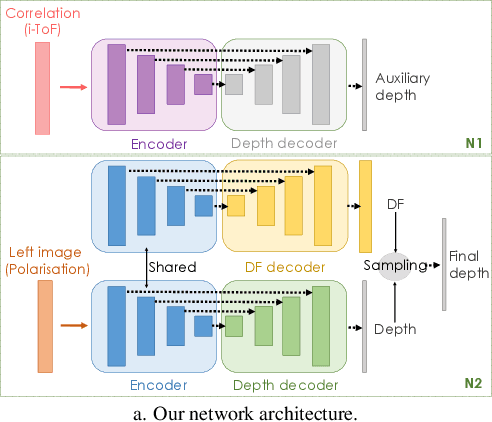
Learning-based depth estimation has witnessed recent progress in multiple directions; from self-supervision using monocular video to supervised methods offering highest accuracy. Complementary to supervision, further boosts to performance and robustness are gained by combining information from multiple signals. In this paper we systematically investigate key trade-offs associated with sensor and modality design choices as well as related model training strategies. Our study leads us to a new method, capable of connecting modality-specific advantages from polarisation, Time-of-Flight and structured-light inputs. We propose a novel pipeline capable of estimating depth from monocular polarisation for which we evaluate various training signals. The inversion of differentiable analytic models thereby connects scene geometry with polarisation and ToF signals and enables self-supervised and cross-modal learning. In the absence of existing multimodal datasets, we examine our approach with a custom-made multi-modal camera rig and collect CroMo; the first dataset to consist of synchronized stereo polarisation, indirect ToF and structured-light depth, captured at video rates. Extensive experiments on challenging video scenes confirm both qualitative and quantitative pipeline advantages where we are able to outperform competitive monocular depth estimation method.
Model-Based Image Signal Processors via Learnable Dictionaries
Jan 10, 2022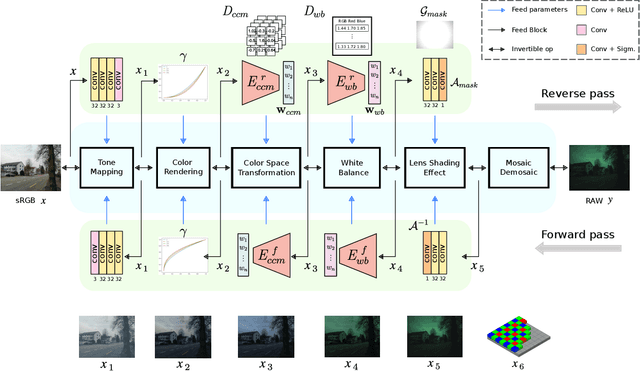
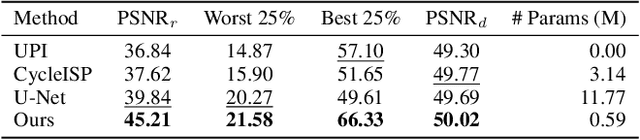
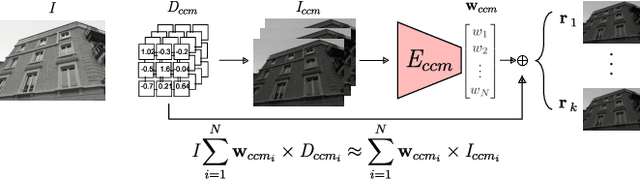
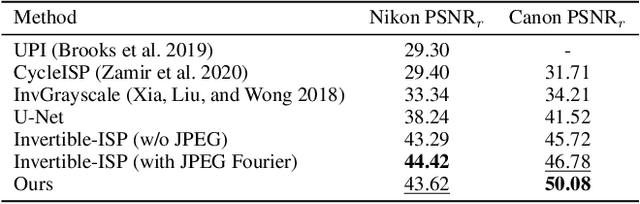
Digital cameras transform sensor RAW readings into RGB images by means of their Image Signal Processor (ISP). Computational photography tasks such as image denoising and colour constancy are commonly performed in the RAW domain, in part due to the inherent hardware design, but also due to the appealing simplicity of noise statistics that result from the direct sensor readings. Despite this, the availability of RAW images is limited in comparison with the abundance and diversity of available RGB data. Recent approaches have attempted to bridge this gap by estimating the RGB to RAW mapping: handcrafted model-based methods that are interpretable and controllable usually require manual parameter fine-tuning, while end-to-end learnable neural networks require large amounts of training data, at times with complex training procedures, and generally lack interpretability and parametric control. Towards addressing these existing limitations, we present a novel hybrid model-based and data-driven ISP that builds on canonical ISP operations and is both learnable and interpretable. Our proposed invertible model, capable of bidirectional mapping between RAW and RGB domains, employs end-to-end learning of rich parameter representations, i.e. dictionaries, that are free from direct parametric supervision and additionally enable simple and plausible data augmentation. We evidence the value of our data generation process by extensive experiments under both RAW image reconstruction and RAW image denoising tasks, obtaining state-of-the-art performance in both. Additionally, we show that our ISP can learn meaningful mappings from few data samples, and that denoising models trained with our dictionary-based data augmentation are competitive despite having only few or zero ground-truth labels.
Long-tail Recognition via Compositional Knowledge Transfer
Dec 13, 2021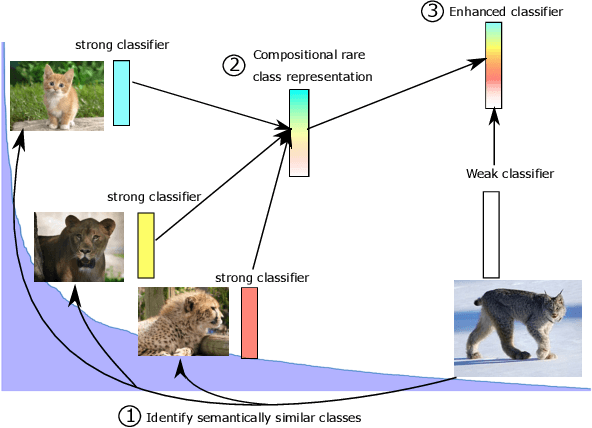
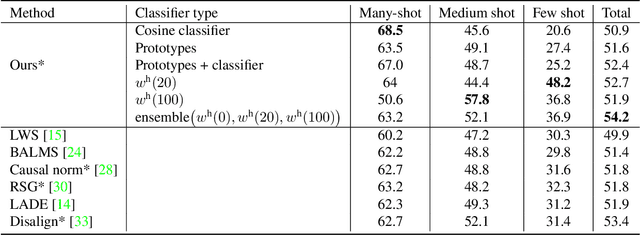
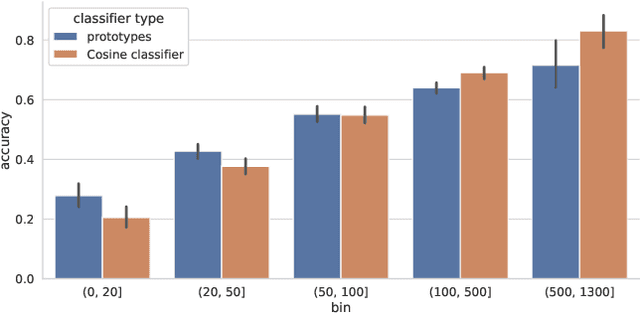
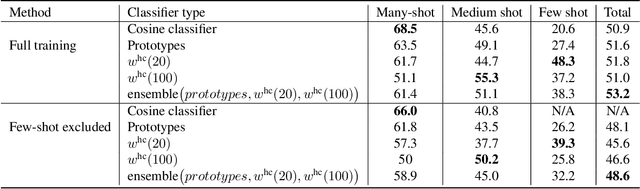
In this work, we introduce a novel strategy for long-tail recognition that addresses the tail classes' few-shot problem via training-free knowledge transfer. Our objective is to transfer knowledge acquired from information-rich common classes to semantically similar, and yet data-hungry, rare classes in order to obtain stronger tail class representations. We leverage the fact that class prototypes and learned cosine classifiers provide two different, complementary representations of class cluster centres in feature space, and use an attention mechanism to select and recompose learned classifier features from common classes to obtain higher quality rare class representations. Our knowledge transfer process is training free, reducing overfitting risks, and can afford continual extension of classifiers to new classes. Experiments show that our approach can achieve significant performance boosts on rare classes while maintaining robust common class performance, outperforming directly comparable state-of-the-art models.