 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogAI: A Library for Log Analytics and Intelligence
Jan 31, 2023



Software and System logs record runtime information about processes executing within a system. These logs have become the most critical and ubiquitous forms of observability data that help developers understand system behavior, monitor system health and resolve issues. However, the volume of logs generated can be humongous (of the order of petabytes per day) especially for complex distributed systems, such as cloud, search engine, social media, etc. This has propelled a lot of research on developing AI-based log based analytics and intelligence solutions that can process huge volume of raw logs and generate insights. In order to enable users to perform multiple types of AI-based log analysis tasks in a uniform manner, we introduce LogAI (https://github.com/salesforce/logai), a one-stop open source library for log analytics and intelligence. LogAI supports tasks such as log summarization, log clustering and log anomaly detection. It adopts the OpenTelemetry data model, to enable compatibility with different log management platforms. LogAI provides a unified model interface and provides popular time-series, statistical learning and deep learning models. Alongside this, LogAI also provides an out-of-the-box GUI for users to conduct interactive analysis. With LogAI, we can also easily benchmark popular deep learning algorithms for log anomaly detection without putting in redundant effort to process the logs. We have opensourced LogAI to cater to a wide range of applications benefiting both academic research and industrial prototyping.
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
Jan 30, 2023



The cost of vision-and-language pre-training has become increasingly prohibitive due to end-to-end training of large-scale models. This paper proposes BLIP-2, a generic and efficient pre-training strategy that bootstraps vision-language pre-training from off-the-shelf frozen pre-trained image encoders and frozen large language models. BLIP-2 bridges the modality gap with a lightweight Querying Transformer, which is pre-trained in two stages. The first stage bootstraps vision-language representation learning from a frozen image encoder. The second stage bootstraps vision-to-language generative learning from a frozen language model. BLIP-2 achieves state-of-the-art performance on various vision-language tasks, despite having significantly fewer trainable parameters than existing methods. For example, our model outperforms Flamingo80B by 8.7% on zero-shot VQAv2 with 54x fewer trainable parameters. We also demonstrate the model's emerging capabilities of zero-shot image-to-text generation that can follow natural language instructions.
Detect-Localize-Repair: A Unified Framework for Learning to Debug with CodeT5
Dec 22, 2022



Automated software debugging is a crucial task for improving the productivity of software developers. Many neural-based techniques have been proven effective for debugging-related tasks such as bug localization and program repair (or bug fixing). However, these techniques often focus only on either one of them or approach them in a stage-wise manner, ignoring the mutual benefits between them. In this work, we propose a novel unified \emph{Detect-Localize-Repair} framework based on a pretrained programming language model CodeT5 to seamlessly address these tasks, named CodeT5-DLR. Specifically, we propose three objectives to adapt the generic CodeT5 for debugging: a bug detection objective to determine whether a given code snippet is buggy or not, a bug localization objective to identify the buggy lines, and a program repair objective to translate the buggy code to its fixed version. We evaluate it on each of these tasks and their combined setting on two newly collected line-level debugging datasets in Java and Python. Extensive results show that our model significantly outperforms existing baselines from both NLP and software engineering domains.
BotSIM: An End-to-End Bot Simulation Framework for Commercial Task-Oriented Dialog Systems
Nov 30, 2022



We present BotSIM, a data-efficient end-to-end Bot SIMulation toolkit for commercial text-based task-oriented dialog (TOD) systems. BotSIM consists of three major components: 1) a Generator that can infer semantic-level dialog acts and entities from bot definitions and generate user queries via model-based paraphrasing; 2) an agenda-based dialog user Simulator (ABUS) to simulate conversations with the dialog agents; 3) a Remediator to analyze the simulated conversations, visualize the bot health reports and provide actionable remediation suggestions for bot troubleshooting and improvement. We demonstrate BotSIM's effectiveness in end-to-end evaluation, remediation and multi-intent dialog generation via case studies on two commercial bot platforms. BotSIM's "generation-simulation-remediation" paradigm accelerates the end-to-end bot evaluation and iteration process by: 1) reducing manual test cases creation efforts; 2) enabling a holistic gauge of the bot in terms of NLU and end-to-end performance via extensive dialog simulation; 3) improving the bot troubleshooting process with actionable suggestions. A demo of our system can be found at https://tinyurl.com/mryu74cd and a demo video at https://youtu.be/qLi5iSoly30. We have open-sourced the toolkit at https://github.com/salesforce/botsim
BotSIM: An End-to-End Bot Simulation Toolkit for Commercial Task-Oriented Dialog Systems
Nov 30, 2022



We introduce BotSIM, a modular, open-source Bot SIMulation environment with dialog generation, user simulation and conversation analytics capabilities. BotSIM aims to serve as a one-stop solution for large-scale data-efficient end-to-end evaluation, diagnosis and remediation of commercial task-oriented dialog (TOD) systems to significantly accelerate commercial bot development and evaluation, reduce cost and time-to-market. BotSIM adopts a layered design comprising the infrastructure layer, the adaptor layer and the application layer. The infrastructure layer hosts key models and components to support BotSIM's major functionalities via a streamlined "generation-simulation-remediation" pipeline. The adaptor layer is used to extend BotSIM to accommodate new bot platforms. The application layer provides a suite of command line tools and a Web App to significantly lower the entry barrier for BotSIM users such as bot admins or practitioners. In this report, we focus on the technical designs of various system components. A detailed case study using Einstein BotBuilder is also presented to show how to apply BotSIM pipeline for bot evaluation and remediation. The detailed system descriptions can be found in our system demo paper. The toolkit is available at: https://github.com/salesforce/BotSIM .
DeepTIMe: Deep Time-Index Meta-Learning for Non-Stationary Time-Series Forecasting
Jul 14, 2022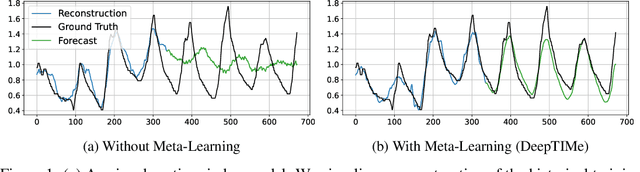
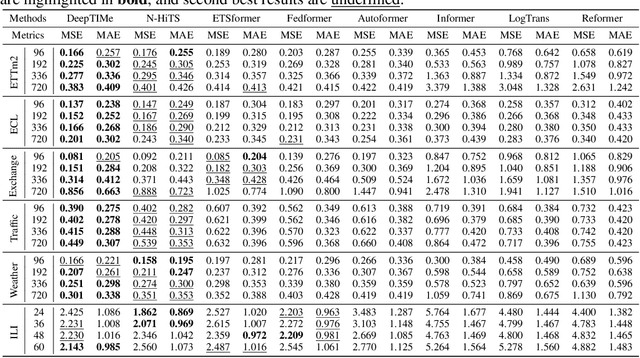
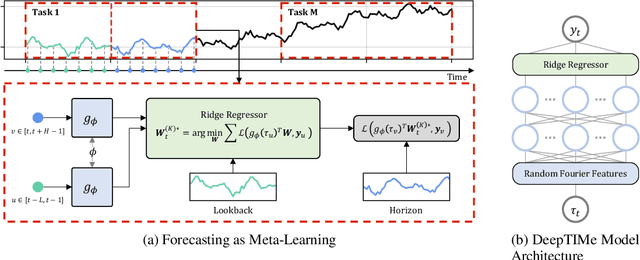
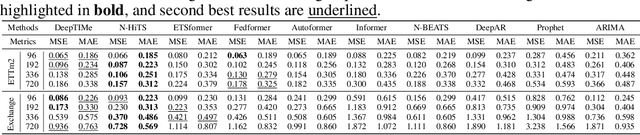
Deep learning has been actively applied to time-series forecasting, leading to a deluge of new autoregressive model architectures. Yet, despite the attractive properties of time-index based models, such as being a continuous signal function over time leading to smooth representations, little attention has been given to them. Indeed, while naive deep time-index based models are far more expressive than the manually predefined function representations of classical time-index based models, they are inadequate for forecasting due to the lack of inductive biases, and the non-stationarity of time-series. In this paper, we propose DeepTIMe, a deep time-index based model trained via a meta-learning formulation which overcomes these limitations, yielding an efficient and accurate forecasting model. Extensive experiments on real world datasets demonstrate that our approach achieves competitive results with state-of-the-art methods, and is highly efficient. Code is available at https://github.com/salesforce/DeepTIMe.
Continual Normalization: Rethinking Batch Normalization for Online Continual Learning
Mar 30, 2022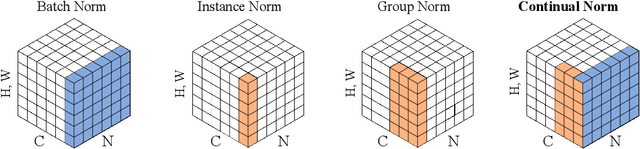
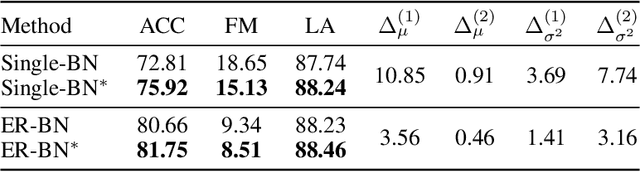
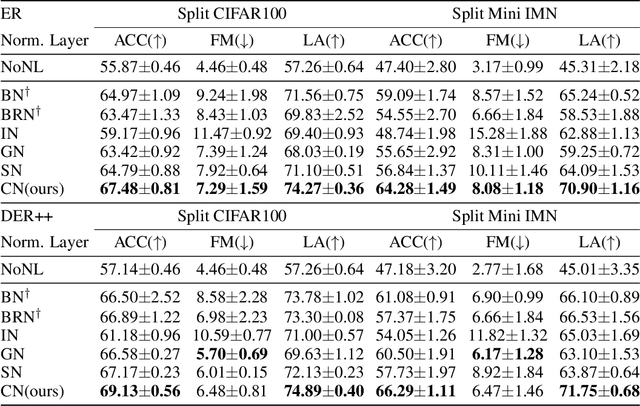

Existing continual learning methods use Batch Normalization (BN) to facilitate training and improve generalization across tasks. However, the non-i.i.d and non-stationary nature of continual learning data, especially in the online setting, amplify the discrepancy between training and testing in BN and hinder the performance of older tasks. In this work, we study the cross-task normalization effect of BN in online continual learning where BN normalizes the testing data using moments biased towards the current task, resulting in higher catastrophic forgetting. This limitation motivates us to propose a simple yet effective method that we call Continual Normalization (CN) to facilitate training similar to BN while mitigating its negative effect. Extensive experiments on different continual learning algorithms and online scenarios show that CN is a direct replacement for BN and can provide substantial performance improvements. Our implementation is available at \url{https://github.com/phquang/Continual-Normalization}.
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
Feb 15, 2022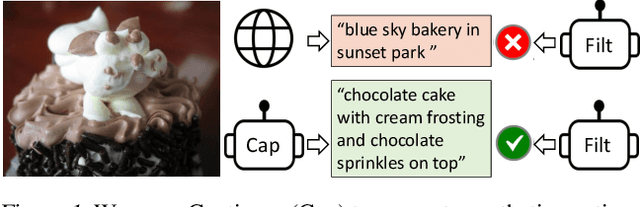
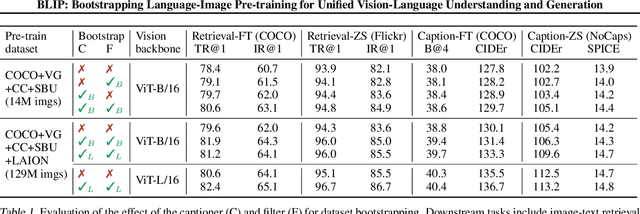
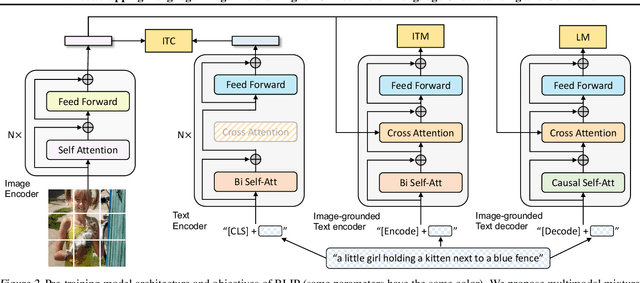

Vision-Language Pre-training (VLP) has advanced the performance for many vision-language tasks. However, most existing pre-trained models only excel in either understanding-based tasks or generation-based tasks. Furthermore, performance improvement has been largely achieved by scaling up the dataset with noisy image-text pairs collected from the web, which is a suboptimal source of supervision. In this paper, we propose BLIP, a new VLP framework which transfers flexibly to both vision-language understanding and generation tasks. BLIP effectively utilizes the noisy web data by bootstrapping the captions, where a captioner generates synthetic captions and a filter removes the noisy ones. We achieve state-of-the-art results on a wide range of vision-language tasks, such as image-text retrieval (+2.7% in average recall@1), image captioning (+2.8% in CIDEr), and VQA (+1.6% in VQA score). BLIP also demonstrates strong generalization ability when directly transferred to video-language tasks in a zero-shot manner. Code, models, and datasets are released at https://github.com/salesforce/BLIP.
CoST: Contrastive Learning of Disentangled Seasonal-Trend Representations for Time Series Forecasting
Feb 03, 2022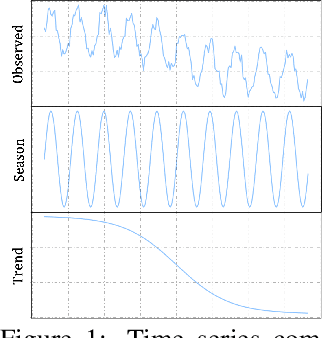
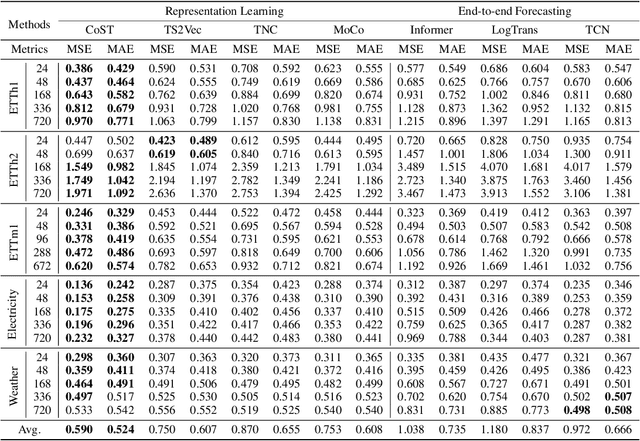
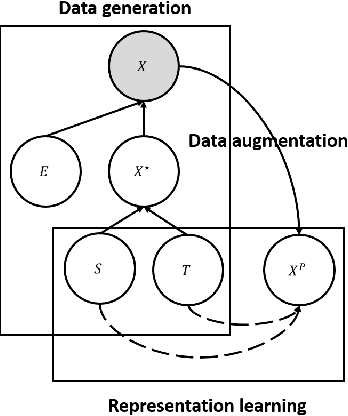
Deep learning has been actively studied for time series forecasting, and the mainstream paradigm is based on the end-to-end training of neural network architectures, ranging from classical LSTM/RNNs to more recent TCNs and Transformers. Motivated by the recent success of representation learning in computer vision and natural language processing, we argue that a more promising paradigm for time series forecasting, is to first learn disentangled feature representations, followed by a simple regression fine-tuning step -- we justify such a paradigm from a causal perspective. Following this principle, we propose a new time series representation learning framework for time series forecasting named CoST, which applies contrastive learning methods to learn disentangled seasonal-trend representations. CoST comprises both time domain and frequency domain contrastive losses to learn discriminative trend and seasonal representations, respectively. Extensive experiments on real-world datasets show that CoST consistently outperforms the state-of-the-art methods by a considerable margin, achieving a 21.3\% improvement in MSE on multivariate benchmarks. It is also robust to various choices of backbone encoders, as well as downstream regressors.
ETSformer: Exponential Smoothing Transformers for Time-series Forecasting
Feb 03, 2022
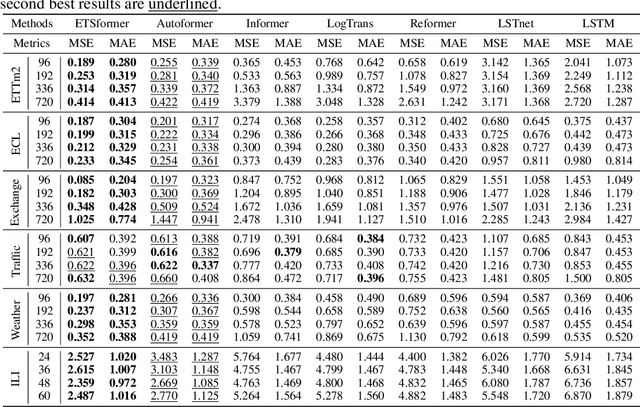

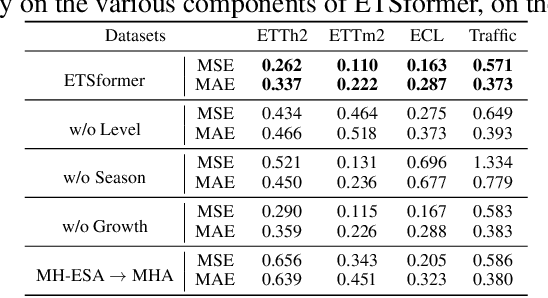
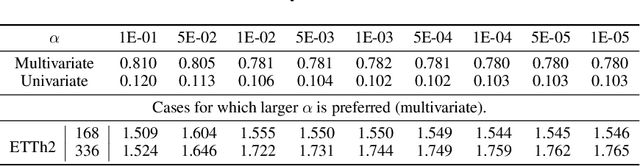
Transformers have been actively studied for time-series forecasting in recent years. While often showing promising results in various scenarios, traditional Transformers are not designed to fully exploit the characteristics of time-series data and thus suffer some fundamental limitations, e.g., they generally lack of decomposition capability and interpretability, and are neither effective nor efficient for long-term forecasting. In this paper, we propose ETSFormer, a novel time-series Transformer architecture, which exploits the principle of exponential smoothing in improving Transformers for time-series forecasting. In particular, inspired by the classical exponential smoothing methods in time-series forecasting, we propose the novel exponential smoothing attention (ESA) and frequency attention (FA) to replace the self-attention mechanism in vanilla Transformers, thus improving both accuracy and efficiency. Based on these, we redesign the Transformer architecture with modular decomposition blocks such that it can learn to decompose the time-series data into interpretable time-series components such as level, growth and seasonality. Extensive experiments on various time-series benchmarks validate the efficacy and advantages of the proposed method. The code and models of our implementations will be released.