 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Invariance to Spurious Correlations: Why and How to Pass Stress Tests
Jun 02, 2021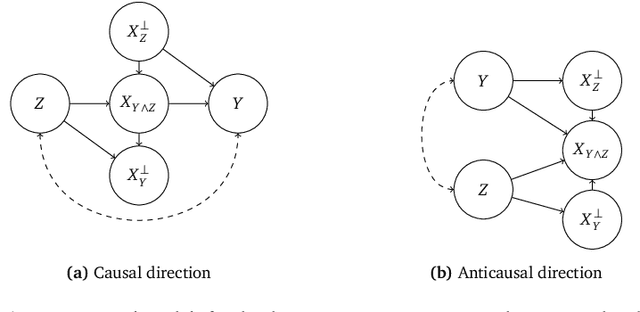

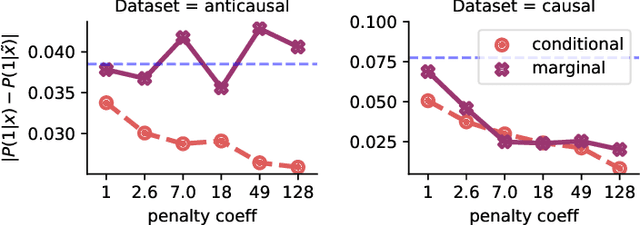
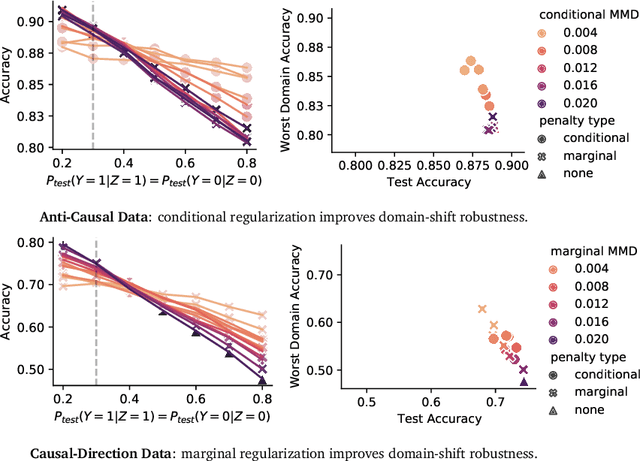
Informally, a `spurious correlation' is the dependence of a model on some aspect of the input data that an analyst thinks shouldn't matter. In machine learning, these have a know-it-when-you-see-it character; e.g., changing the gender of a sentence's subject changes a sentiment predictor's output. To check for spurious correlations, we can `stress test' models by perturbing irrelevant parts of input data and seeing if model predictions change. In this paper, we study stress testing using the tools of causal inference. We introduce \emph{counterfactual invariance} as a formalization of the requirement that changing irrelevant parts of the input shouldn't change model predictions. We connect counterfactual invariance to out-of-domain model performance, and provide practical schemes for learning (approximately) counterfactual invariant predictors (without access to counterfactual examples). It turns out that both the means and implications of counterfactual invariance depend fundamentally on the true underlying causal structure of the data. Distinct causal structures require distinct regularization schemes to induce counterfactual invariance. Similarly, counterfactual invariance implies different domain shift guarantees depending on the underlying causal structure. This theory is supported by empirical results on text classification.
SLOE: A Faster Method for Statistical Inference in High-Dimensional Logistic Regression
Mar 23, 2021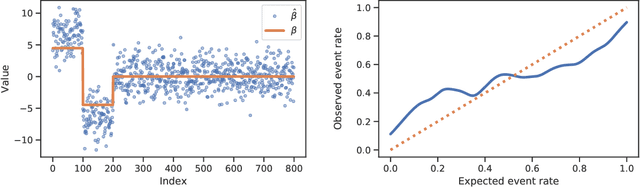
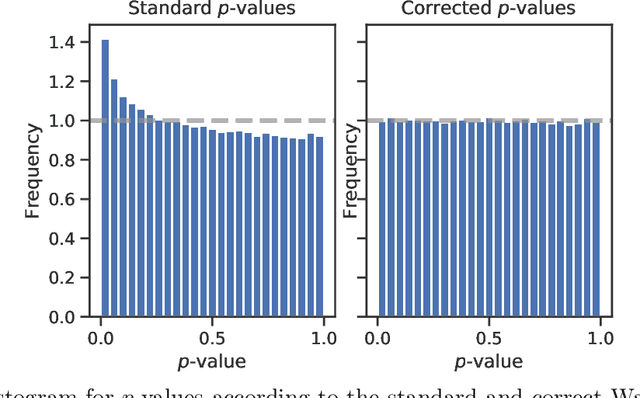
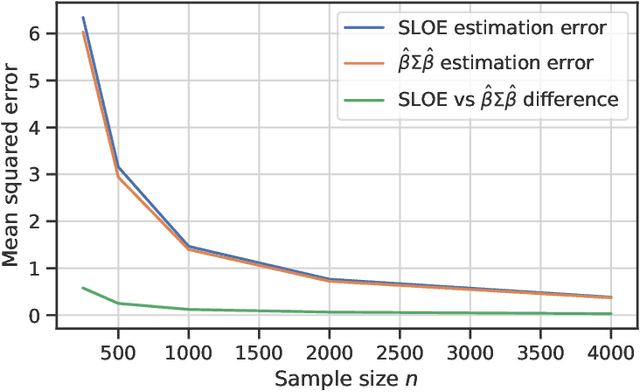
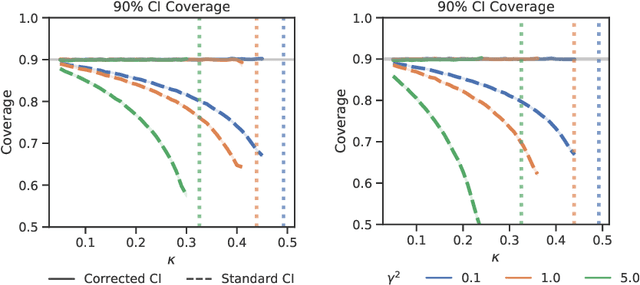
Logistic regression remains one of the most widely used tools in applied statistics, machine learning and data science. Practical datasets often have a substantial number of features $d$ relative to the sample size $n$. In these cases, the logistic regression maximum likelihood estimator (MLE) is biased, and its standard large-sample approximation is poor. In this paper, we develop an improved method for debiasing predictions and estimating frequentist uncertainty for such datasets. We build on recent work characterizing the asymptotic statistical behavior of the MLE in the regime where the aspect ratio $d / n$, instead of the number of features $d$, remains fixed as $n$ grows. In principle, this approximation facilitates bias and uncertainty corrections, but in practice, these corrections require an estimate of the signal strength of the predictors. Our main contribution is SLOE, an estimator of the signal strength with convergence guarantees that reduces the computation time of estimation and inference by orders of magnitude. The bias correction that this facilitates also reduces the variance of the predictions, yielding narrower confidence intervals with higher (valid) coverage of the true underlying probabilities and parameters. We provide an open source package for this method, available at https://github.com/google-research/sloe-logistic.
Deep Cox Mixtures for Survival Regression
Jan 16, 2021

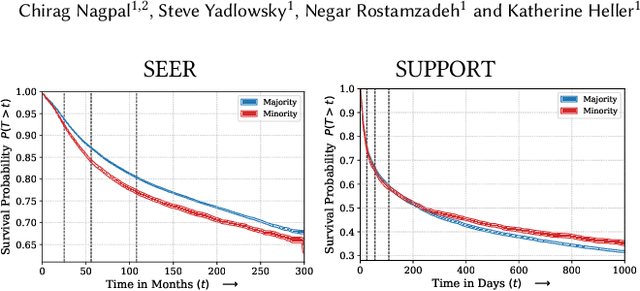

Survival analysis is a challenging variation of regression modeling because of the presence of censoring, where the outcome measurement is only partially known, due to, for example, loss to follow up. Such problems come up frequently in medical applications, making survival analysis a key endeavor in biostatistics and machine learning for healthcare, with Cox regression models being amongst the most commonly employed models. We describe a new approach for survival analysis regression models, based on learning mixtures of Cox regressions to model individual survival distributions. We propose an approximation to the Expectation Maximization algorithm for this model that does hard assignments to mixture groups to make optimization efficient. In each group assignment, we fit the hazard ratios within each group using deep neural networks, and the baseline hazard for each mixture component non-parametrically. We perform experiments on multiple real world datasets, and look at the mortality rates of patients across ethnicity and gender. We emphasize the importance of calibration in healthcare settings and demonstrate that our approach outperforms classical and modern survival analysis baselines, both in terms of discriminative performance and calibration, with large gains in performance on the minority demographics.
Underspecification Presents Challenges for Credibility in Modern Machine Learning
Nov 06, 2020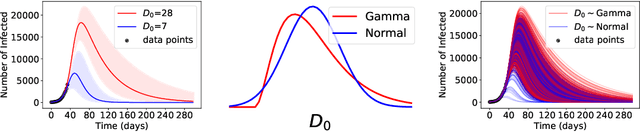


ML models often exhibit unexpectedly poor behavior when they are deployed in real-world domains. We identify underspecification as a key reason for these failures. An ML pipeline is underspecified when it can return many predictors with equivalently strong held-out performance in the training domain. Underspecification is common in modern ML pipelines, such as those based on deep learning. Predictors returned by underspecified pipelines are often treated as equivalent based on their training domain performance, but we show here that such predictors can behave very differently in deployment domains. This ambiguity can lead to instability and poor model behavior in practice, and is a distinct failure mode from previously identified issues arising from structural mismatch between training and deployment domains. We show that this problem appears in a wide variety of practical ML pipelines, using examples from computer vision, medical imaging, natural language processing, clinical risk prediction based on electronic health records, and medical genomics. Our results show the need to explicitly account for underspecification in modeling pipelines that are intended for real-world deployment in any domain.
Off-policy Policy Evaluation For Sequential Decisions Under Unobserved Confounding
Mar 12, 2020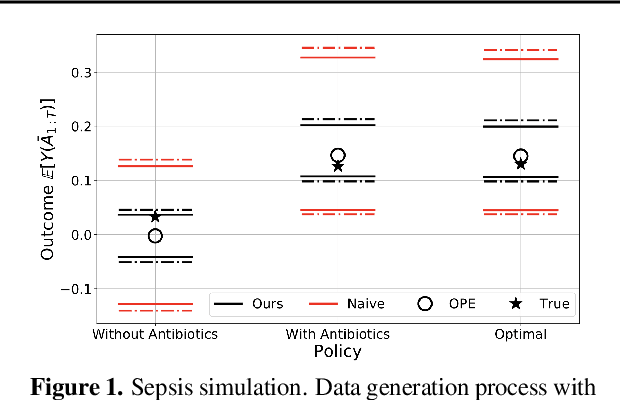
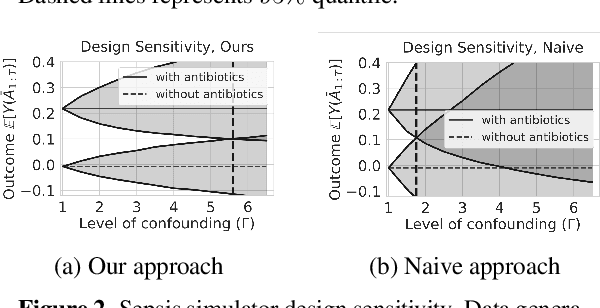
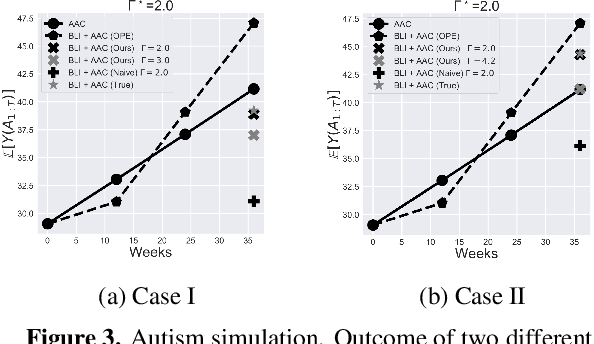
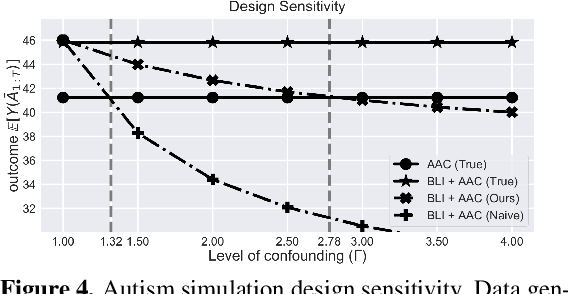
When observed decisions depend only on observed features, off-policy policy evaluation (OPE) methods for sequential decision making problems can estimate the performance of evaluation policies before deploying them. This assumption is frequently violated due to unobserved confounders, unrecorded variables that impact both the decisions and their outcomes. We assess robustness of OPE methods under unobserved confounding by developing worst-case bounds on the performance of an evaluation policy. When unobserved confounders can affect every decision in an episode, we demonstrate that even small amounts of per-decision confounding can heavily bias OPE methods. Fortunately, in a number of important settings found in healthcare, policy-making, operations, and technology, unobserved confounders may primarily affect only one of the many decisions made. Under this less pessimistic model of one-decision confounding, we propose an efficient loss-minimization-based procedure for computing worst-case bounds, and prove its statistical consistency. On two simulated healthcare examples---management of sepsis patients and developmental interventions for autistic children---where this is a reasonable model of confounding, we demonstrate that our method invalidates non-robust results and provides meaningful certificates of robustness, allowing reliable selection of policies even under unobserved confounding.
Estimation and Validation of a Class of Conditional Average Treatment Effects Using Observational Data
Dec 15, 2019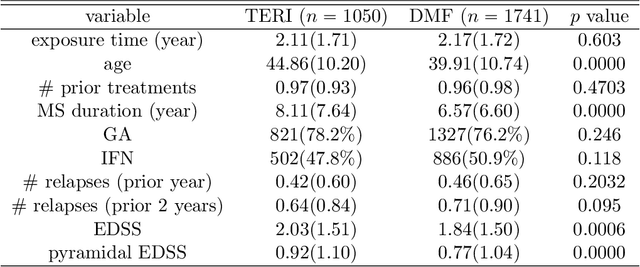
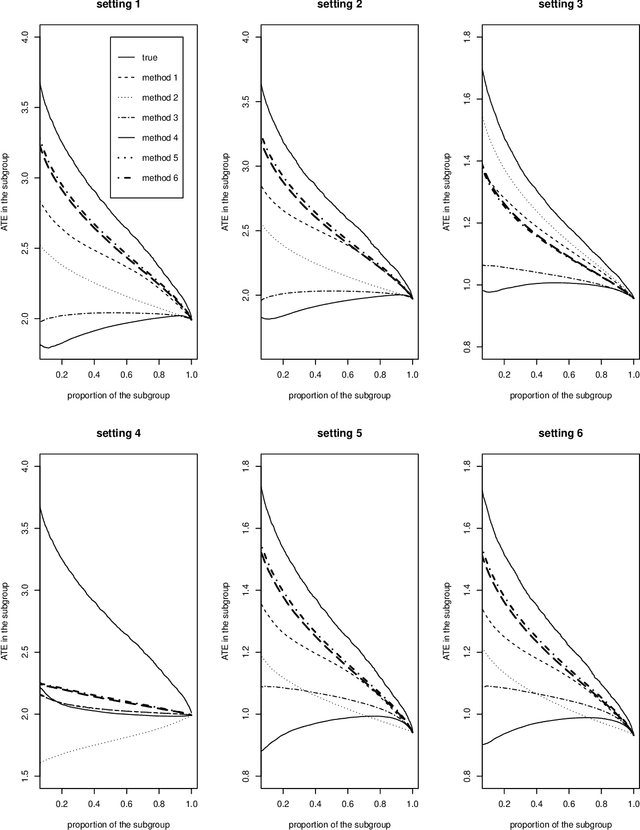
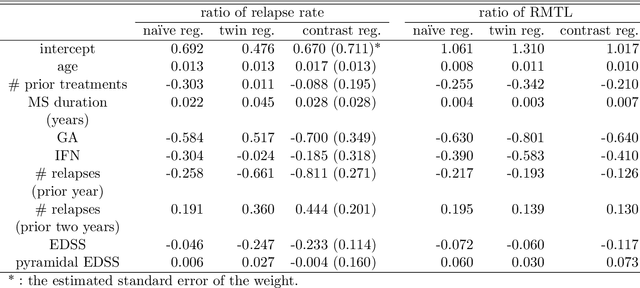
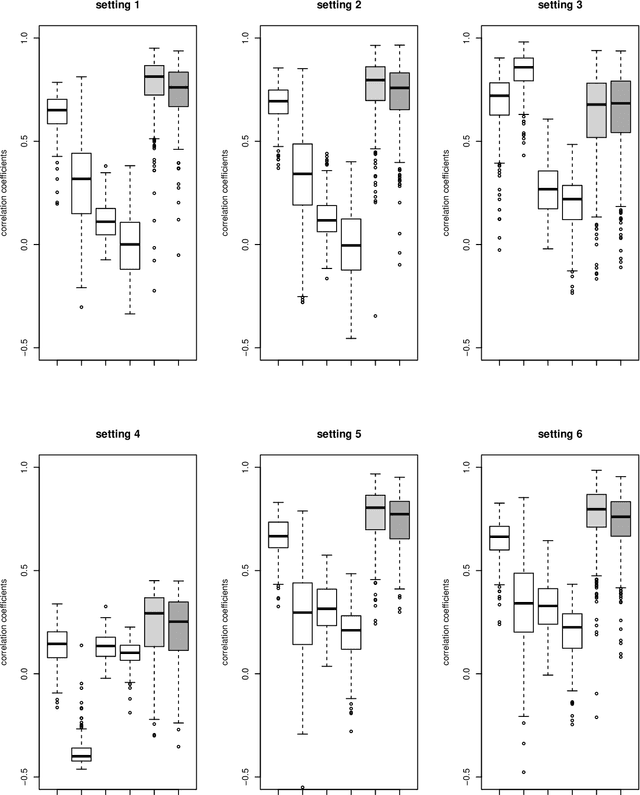
While sample sizes in randomized clinical trials are large enough to estimate the average treatment effect well, they are often insufficient for estimation of treatment-covariate interactions critical to studying data-driven precision medicine. Observational data from real world practice may play an important role in alleviating this problem. One common approach in trials is to predict the outcome of interest with separate regression models in each treatment arm, and recommend interventions based on the contrast of the predicted outcomes. Unfortunately, this simple approach may induce spurious treatment-covariate interaction in observational studies when the regression model is misspecified. Motivated by the need of modeling the number of relapses in multiple sclerosis patients, where the ratio of relapse rates is a natural choice of the treatment effect, we propose to estimate the conditional average treatment effect (CATE) as the relative ratio of the potential outcomes, and derive a doubly robust estimator of this CATE in a semiparametric model of treatment-covariate interactions. We also provide a validation procedure to check the quality of the estimator on an independent sample. We conduct simulations to demonstrate the finite sample performance of the proposed methods, and illustrate the advantage of this approach on real data examining the treatment effect of dimethyl fumarate compared to teriflunomide in multiple sclerosis patients.
Derivative free optimization via repeated classification
Apr 11, 2018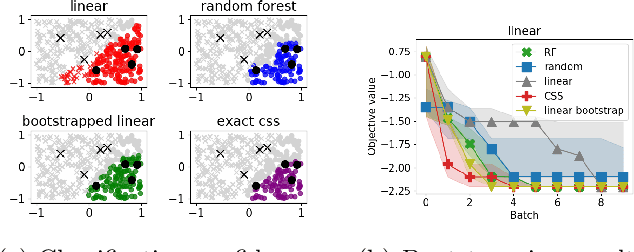
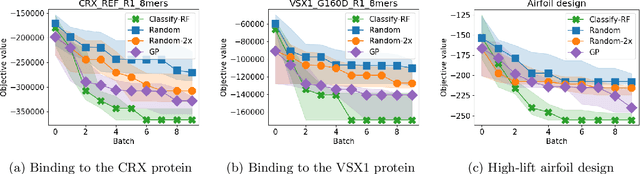
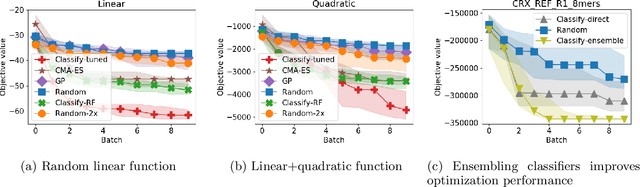
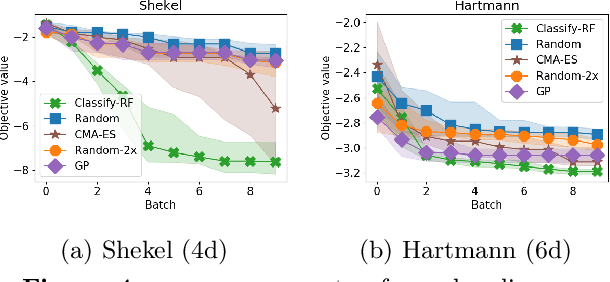
We develop an algorithm for minimizing a function using $n$ batched function value measurements at each of $T$ rounds by using classifiers to identify a function's sublevel set. We show that sufficiently accurate classifiers can achieve linear convergence rates, and show that the convergence rate is tied to the difficulty of active learning sublevel sets. Further, we show that the bootstrap is a computationally efficient approximation to the necessary classification scheme. The end result is a computationally efficient derivative-free algorithm requiring no tuning that consistently outperforms other approaches on simulations, standard benchmarks, real-world DNA binding optimization, and airfoil design problems whenever batched function queries are natural.