 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePortfolio Optimization for Cointelated Pairs: SDEs vs. Machine Learning
Dec 26, 2018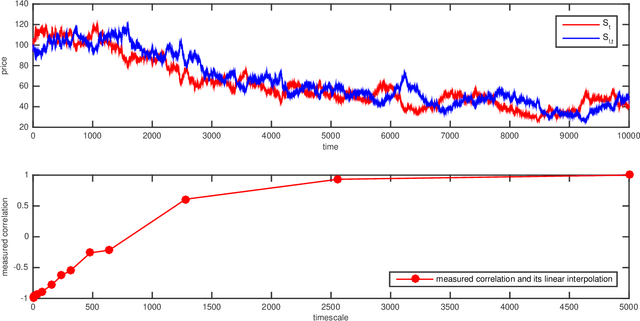
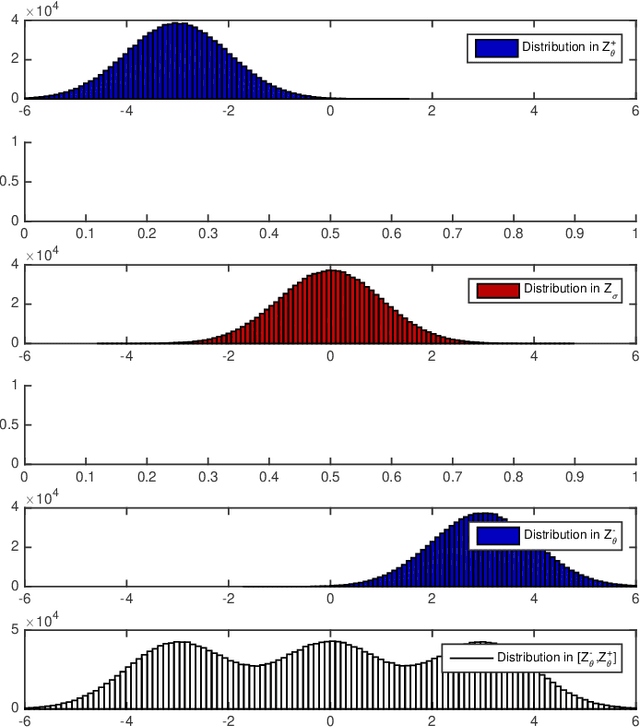
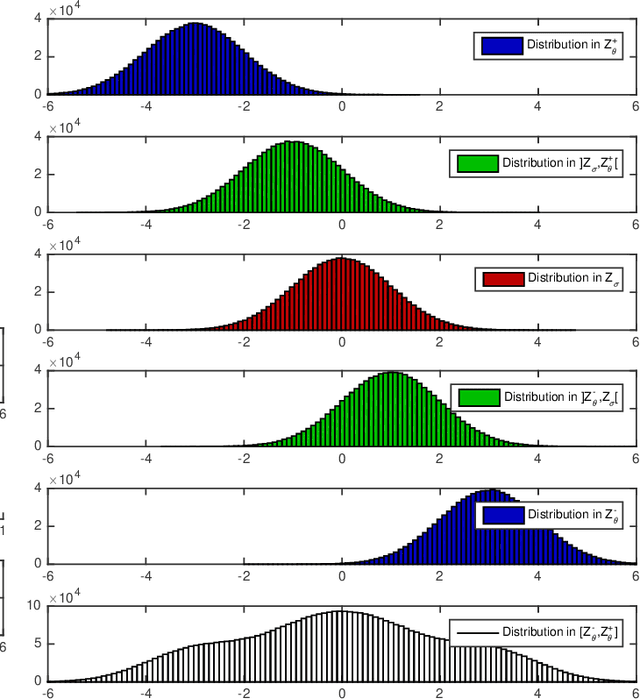
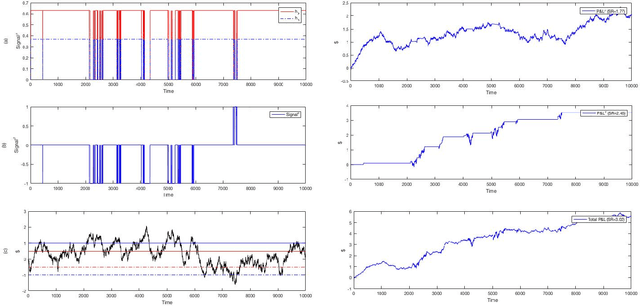
We investigate the problem of dynamic portfolio optimization in continuous-time, finite-horizon setting for a portfolio of two stocks and one risk-free asset. The stocks follow the Cointelation model. The proposed optimization methods are twofold. In what we call an Stochastic Differential Equation approach, we compute the optimal weights using mean-variance criterion and power utility maximization. We show that dynamically switching between these two optimal strategies by introducing a triggering function can further improve the portfolio returns. We contrast this with the machine learning clustering methodology inspired by the band-wise Gaussian mixture model. The first benefit of the machine learning over the Stochastic Differential Equation approach is that we were able to achieve the same results though a simpler channel. The second advantage is a flexibility to regime change.
Bayesian deep neural networks for low-cost neurophysiological markers of Alzheimer's disease severity
Dec 13, 2018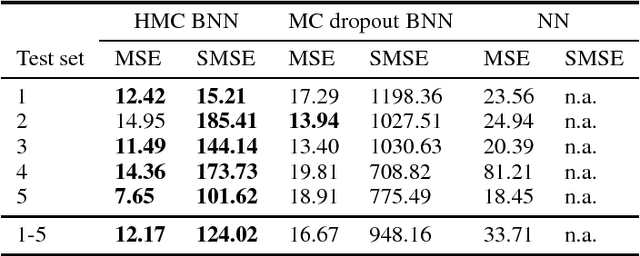
As societies around the world are ageing, the number of Alzheimer's disease (AD) patients is rapidly increasing. To date, no low-cost, non-invasive biomarkers have been established to advance the objectivization of AD diagnosis and progression assessment. Here, we utilize Bayesian neural networks to develop a multivariate predictor for AD severity using a wide range of quantitative EEG (QEEG) markers. The Bayesian treatment of neural networks both automatically controls model complexity and provides a predictive distribution over the target function, giving uncertainty bounds for our regression task. It is therefore well suited to clinical neuroscience, where data sets are typically sparse and practitioners require a precise assessment of the predictive uncertainty. We use data of one of the largest prospective AD EEG trials ever conducted to demonstrate the potential of Bayesian deep learning in this domain, while comparing two distinct Bayesian neural network approaches, i.e., Monte Carlo dropout and Hamiltonian Monte Carlo.
Intersectionality: Multiple Group Fairness in Expectation Constraints
Nov 25, 2018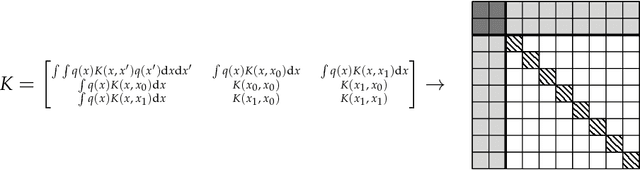


Group fairness is an important concern for machine learning researchers, developers, and regulators. However, the strictness to which models must be constrained to be considered fair is still under debate. The focus of this work is on constraining the expected outcome of subpopulations in kernel regression and, in particular, decision tree regression, with application to random forests, boosted trees and other ensemble models. While individual constraints were previously addressed, this work addresses concerns about incorporating multiple constraints simultaneously. The proposed solution does not affect the order of computational or memory complexity of the decision trees and is easily integrated into models post training.
Practical Bayesian Learning of Neural Networks via Adaptive Subgradient Methods
Nov 08, 2018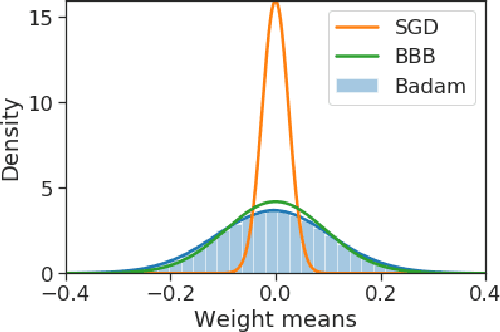

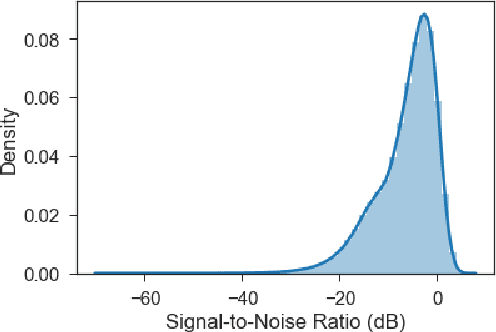
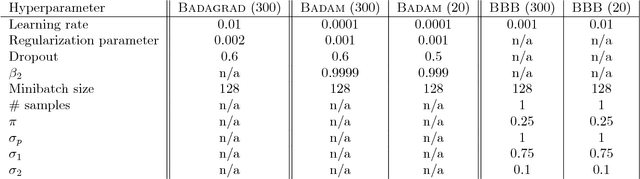
We introduce a novel framework for the estimation of the posterior distribution of the weights of a neural network, based on a new probabilistic interpretation of adaptive subgradient algorithms such as AdaGrad and Adam. Having a confidence measure of the weights allows several shortcomings of neural networks to be addressed. In particular, the robustness of the network can be improved by performing weight pruning based on signal-to-noise ratios from the weight posterior distribution. Using the MNIST dataset, we demonstrate that the empirical performance of Badam, a particular instance of our framework based on Adam, is competitive in comparison to related Bayesian approaches such as Bayes By Backprop.
Semi-unsupervised Learning of Human Activity using Deep Generative Models
Oct 29, 2018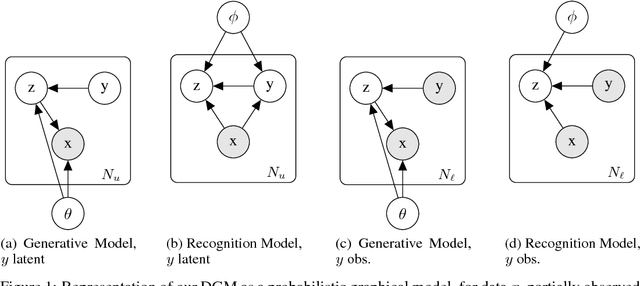
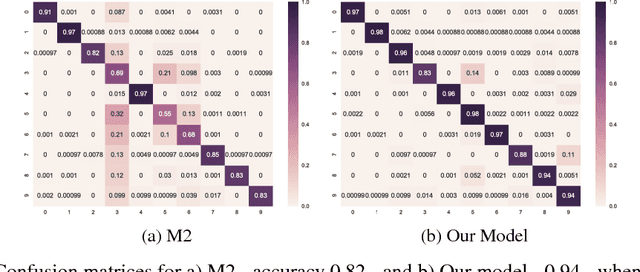
Here we demonstrate a new deep generative model for classification. We introduce `semi-unsupervised learning', a problem regime related to transfer learning and zero/few shot learning where, in the training data, some classes are sparsely labelled and others entirely unlabelled. Models able to learn from training data of this type are potentially of great use, as many medical datasets are `semi-unsupervised'. Our model demonstrates superior semi-unsupervised classification performance on MNIST to model M2 from Kingma and Welling (2014). We apply the model to human accelerometer data, performing activity classification and structure discovery on windows of time series data.
MOrdReD: Memory-based Ordinal Regression Deep Neural Networks for Time Series Forecasting
Oct 24, 2018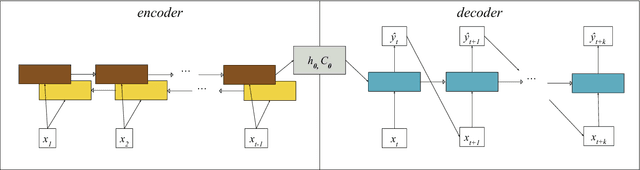


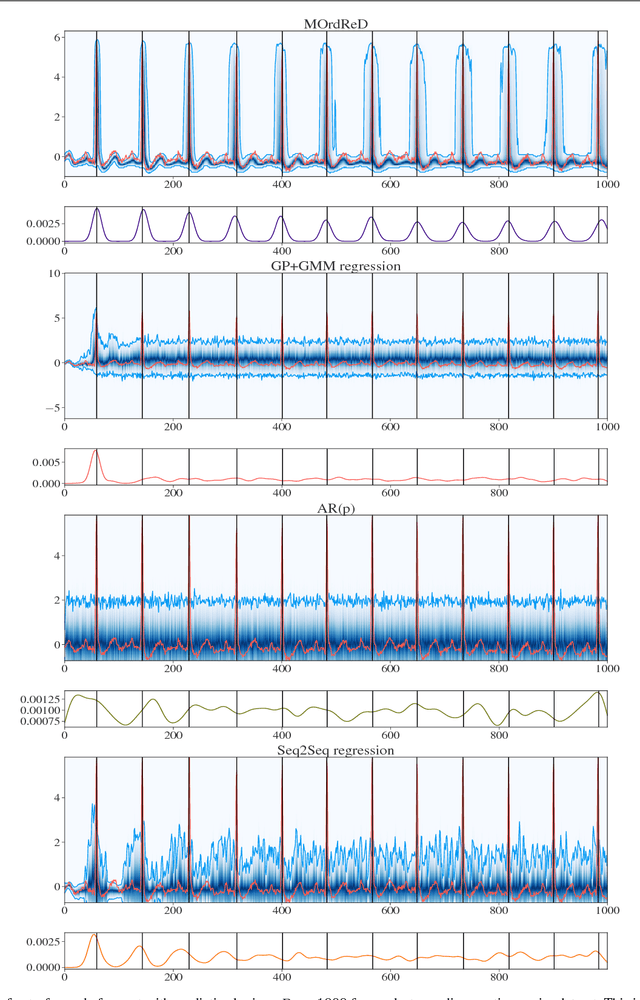
Time series forecasting is ubiquitous in the modern world. Applications range from health care to astronomy, and include climate modelling, financial trading and monitoring of critical engineering equipment. To offer value over this range of activities, models must not only provide accurate forecasts, but also quantify and adjust their uncertainty over time. In this work, we directly tackle this task with a novel, fully end-to-end deep learning method for time series forecasting. By recasting time series forecasting as an ordinal regression task, we develop a principled methodology to assess long-term predictive uncertainty and describe rich multimodal, non-Gaussian behaviour, which arises regularly in applied settings. Notably, our framework is a wholly general-purpose approach that requires little to no user intervention to be used. We showcase this key feature in a large-scale benchmark test with 45 datasets drawn from both, a wide range of real-world application domains, as well as a comprehensive list of synthetic maps. This wide comparison encompasses state-of-the-art methods in both the Machine Learning and Statistics modelling literature, such as the Gaussian Process. We find that our approach does not only provide excellent predictive forecasts, shadowing true future values, but also allows us to infer valuable information, such as the predictive distribution of the occurrence of critical events of interest, accurately and reliably even over long time horizons.
Equality Constrained Decision Trees: For the Algorithmic Enforcement of Group Fairness
Oct 10, 2018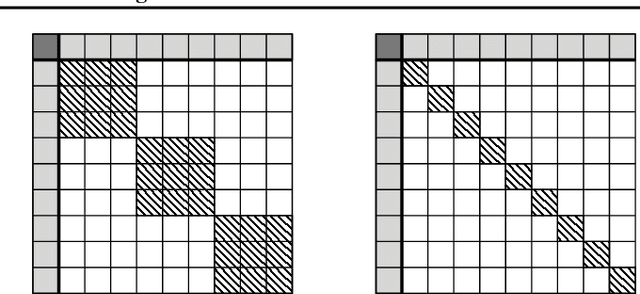
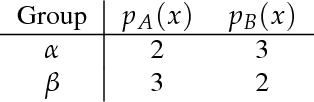
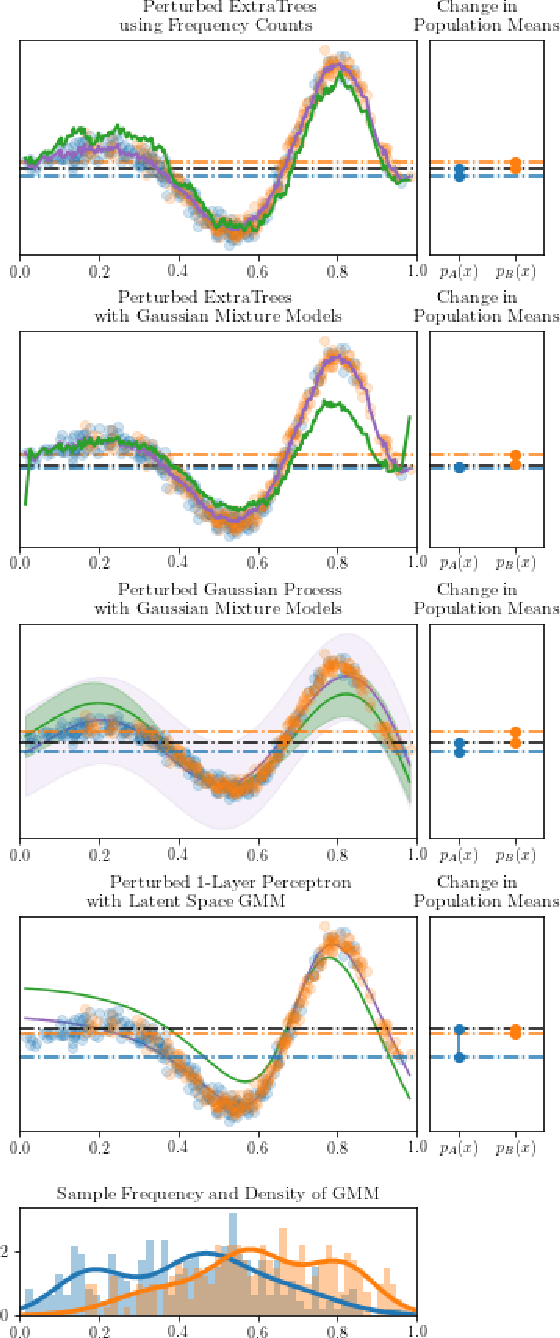

Fairness, through its many forms and definitions, has become an important issue facing the machine learning community. In this work, we consider how to incorporate group fairness constraints in kernel regression methods. More specifically, we focus on examining the incorporation of these constraints in decision tree regression when cast as a form of kernel regression, with direct applications to random forests and boosted trees amongst other widespread popular inference techniques. We show that order of complexity of memory and computation is preserved for such models and bounds the expected perturbations to the model in terms of the number of leaves of the trees. Importantly, the approach works on trained models and hence can be easily applied to models in current use.
Sequential sampling of Gaussian process latent variable models
Jul 20, 2018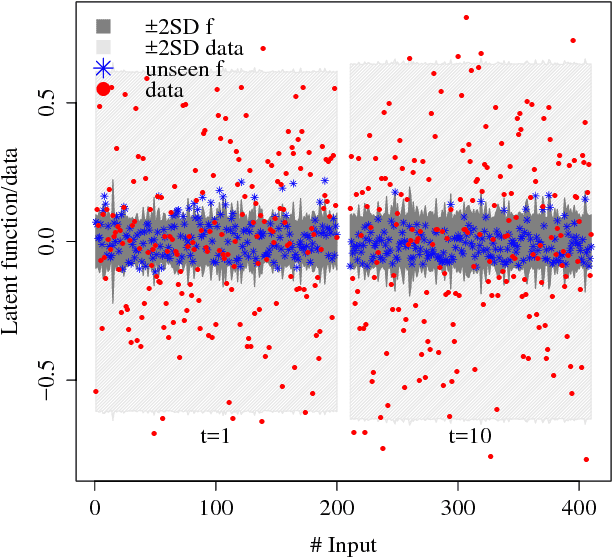
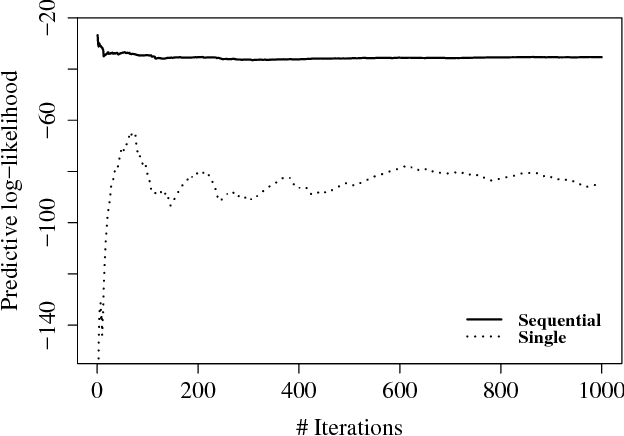
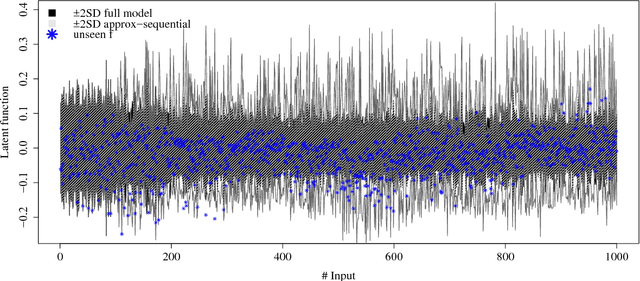
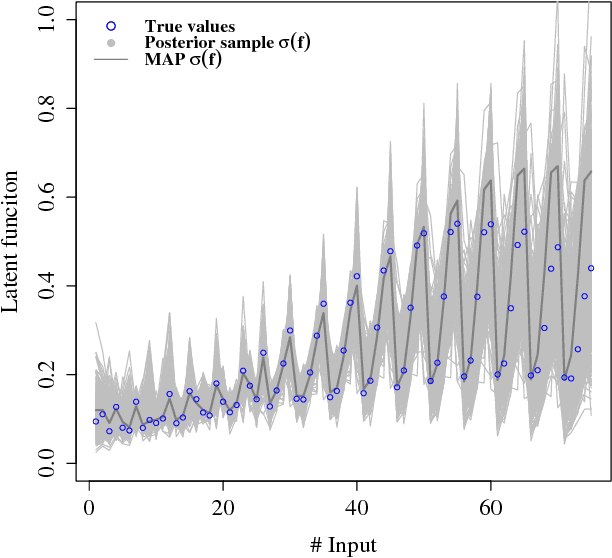
We consider the problem of inferring a latent function in a probabilistic model of data. When dependencies of the latent function are specified by a Gaussian process and the data likelihood is complex, efficient computation often involve Markov chain Monte Carlo sampling with limited applicability to large data sets. We extend some of these techniques to scale efficiently when the problem exhibits a sequential structure. We propose an approximation that enables sequential sampling of both latent variables and associated parameters. We demonstrate strong performance in growing-data settings that would otherwise be unfeasible with naive, non-sequential sampling.
Extracting Predictive Information from Heterogeneous Data Streams using Gaussian Processes
Jul 11, 2018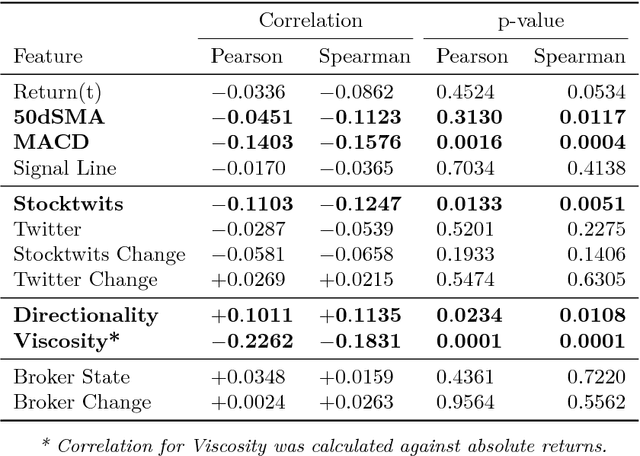
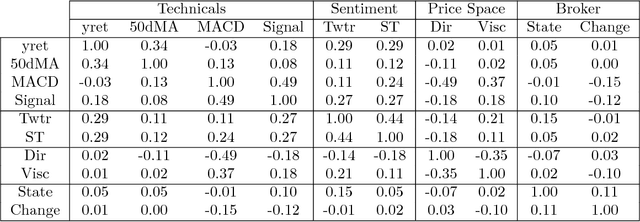
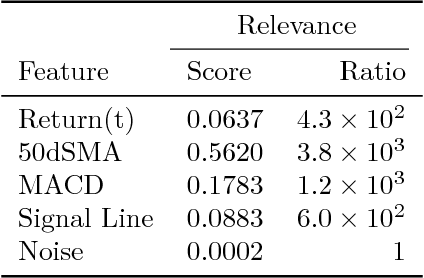
Financial markets are notoriously complex environments, presenting vast amounts of noisy, yet potentially informative data. We consider the problem of forecasting financial time series from a wide range of information sources using online Gaussian Processes with Automatic Relevance Determination (ARD) kernels. We measure the performance gain, quantified in terms of Normalised Root Mean Square Error (NRMSE), Median Absolute Deviation (MAD) and Pearson correlation, from fusing each of four separate data domains: time series technicals, sentiment analysis, options market data and broker recommendations. We show evidence that ARD kernels produce meaningful feature rankings that help retain salient inputs and reduce input dimensionality, providing a framework for sifting through financial complexity. We measure the performance gain from fusing each domain's heterogeneous data streams into a single probabilistic model. In particular our findings highlight the critical value of options data in mapping out the curvature of price space and inspire an intuitive, novel direction for research in financial prediction.
Entropic Spectral Learning in Large Scale Networks
Apr 18, 2018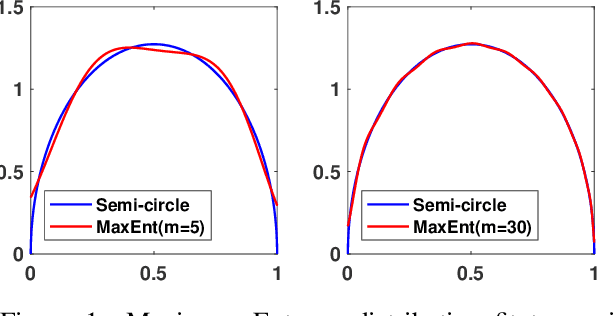

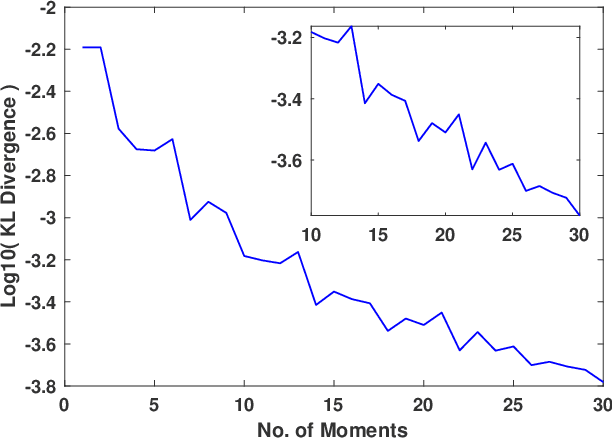
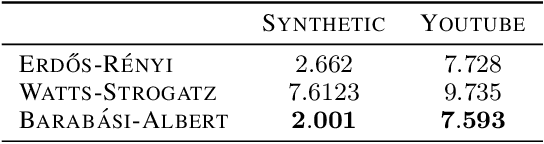
We present a novel algorithm for learning the spectral density of large scale networks using stochastic trace estimation and the method of maximum entropy. The complexity of the algorithm is linear in the number of non-zero elements of the matrix, offering a computational advantage over other algorithms. We apply our algorithm to the problem of community detection in large networks. We show state-of-the-art performance on both synthetic and real datasets.