 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling to Cluster: Gaussian Mixture Variational Ladder Autoencoders
Sep 25, 2019


In clustering we normally output one cluster variable for each datapoint. However it is not necessarily the case that there is only one way to partition a given dataset into cluster components. For example, one could cluster objects by their colour, or by their type. Different attributes form a hierarchy, and we could wish to cluster in any of them. By disentangling the learnt latent representations of some dataset into different layers for different attributes we can then cluster in those latent spaces. We call this "disentangled clustering". Extending Variational Ladder Autoencoders (Zhao et al., 2017), we propose a clustering algorithm, VLAC, that outperforms a Gaussian Mixture DGM in cluster accuracy over digit identity on the test set of SVHN. We also demonstrate learning clusters jointly over numerous layers of the hierarchy of latent variables for the data, and show component-wise generation from this hierarchical model.
Balancing Reconstruction Quality and Regularisation in ELBO for VAEs
Sep 09, 2019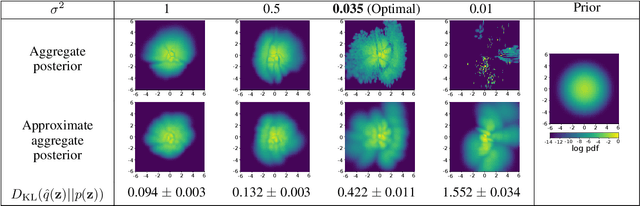
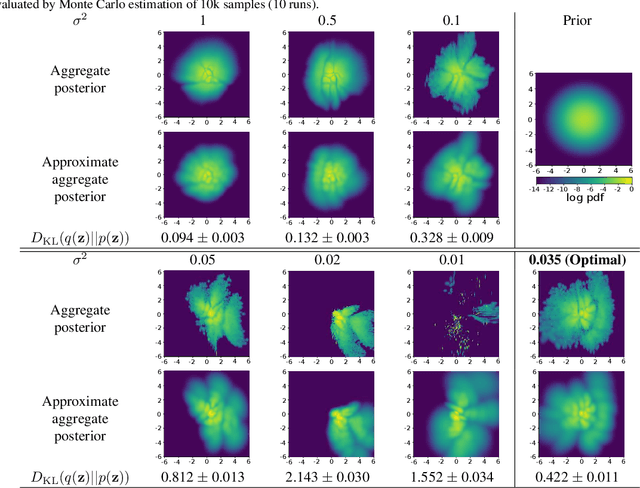


A trade-off exists between reconstruction quality and the prior regularisation in the Evidence Lower Bound (ELBO) loss that Variational Autoencoder (VAE) models use for learning. There are few satisfactory approaches to deal with a balance between the prior and reconstruction objective, with most methods dealing with this problem through heuristics. In this paper, we show that the noise variance (often set as a fixed value) in the Gaussian likelihood p(x|z) for real-valued data can naturally act to provide such a balance. By learning this noise variance so as to maximise the ELBO loss, we automatically obtain an optimal trade-off between the reconstruction error and the prior constraint on the posteriors. This variance can be interpreted intuitively as the necessary noise level for the current model to be the best explanation of the observed dataset. Further, by allowing the variance inference to be more flexible it can conveniently be used as an uncertainty estimator for reconstructed or generated samples. We demonstrate that optimising the noise variance is a crucial component of VAE learning, and showcase the performance on MNIST, Fashion MNIST and CelebA datasets. We find our approach can significantly improve the quality of generated samples whilst maintaining a smooth latent-space manifold to represent the data. The method also offers an indication of uncertainty in the final generative model.
MEMe: An Accurate Maximum Entropy Method for Efficient Approximations in Large-Scale Machine Learning
Jun 03, 2019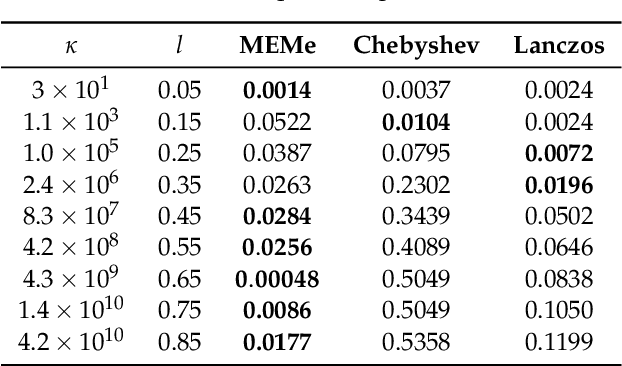
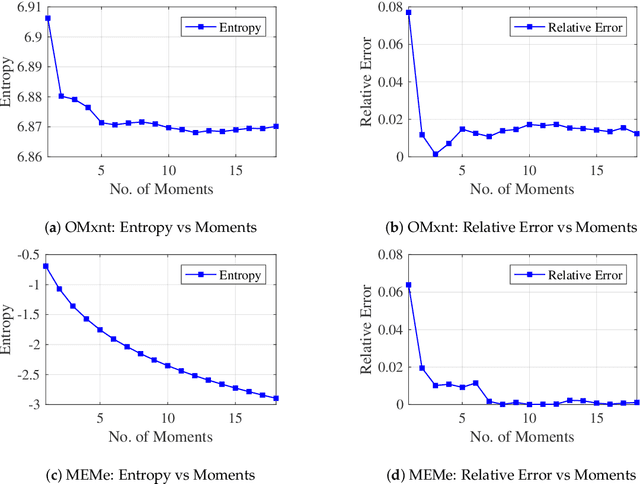
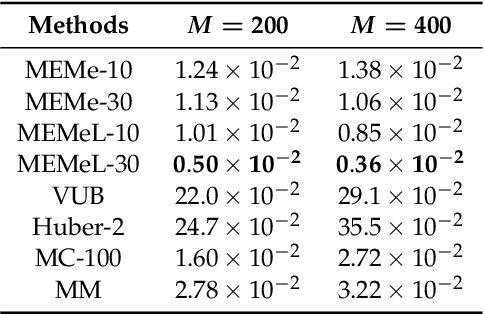
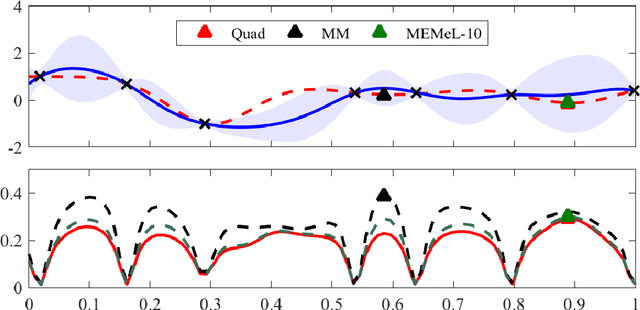
Efficient approximation lies at the heart of large-scale machine learning problems. In this paper, we propose a novel, robust maximum entropy algorithm, which is capable of dealing with hundreds of moments and allows for computationally efficient approximations. We showcase the usefulness of the proposed method, its equivalence to constrained Bayesian variational inference and demonstrate its superiority over existing approaches in two applications, namely, fast log determinant estimation and information-theoretic Bayesian optimisation.
* 18 pages, 3 figures, Published at Entropy 2019: Special Issue Entropy Based Inference and Optimization in Machine Learning
Disentangling Improves VAEs' Robustness to Adversarial Attacks
Jun 01, 2019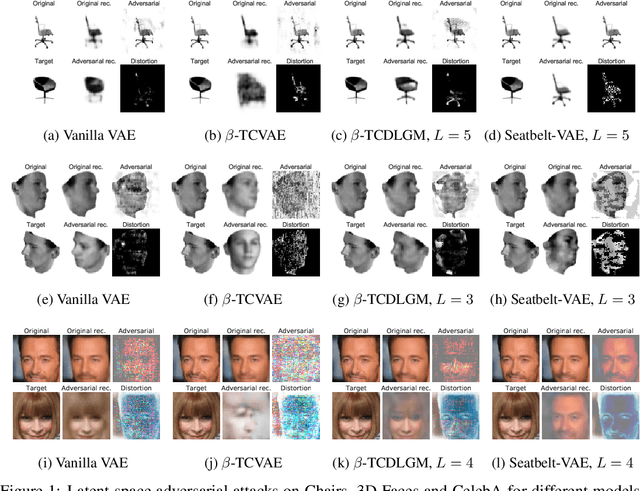

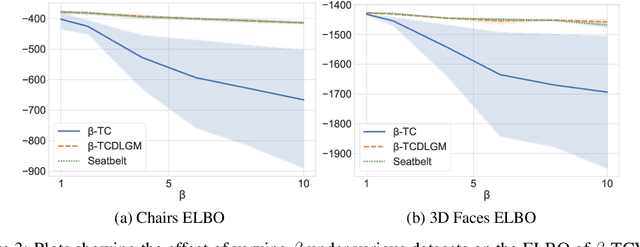

This paper is concerned with the robustness of VAEs to adversarial attacks. We highlight that conventional VAEs are brittle under attack but that methods recently introduced for disentanglement such as $\beta$-TCVAE (Chen et al., 2018) improve robustness, as demonstrated through a variety of previously proposed adversarial attacks (Tabacof et al. (2016); Gondim-Ribeiro et al. (2018); Kos et al.(2018)). This motivated us to develop Seatbelt-VAE, a new hierarchical disentangled VAE that is designed to be significantly more robust to adversarial attacks than existing approaches, while retaining high quality reconstructions.
Robustness Quantification for Classification with Gaussian Processes
May 28, 2019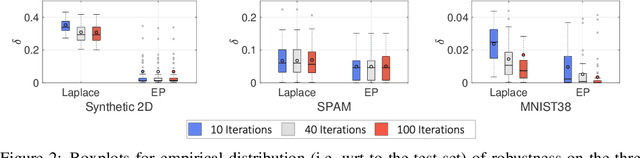
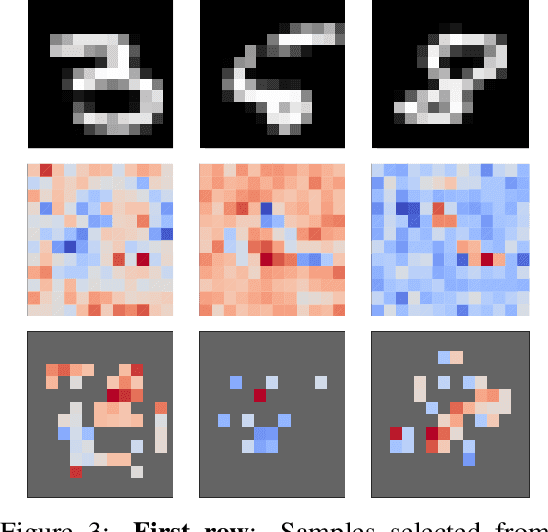
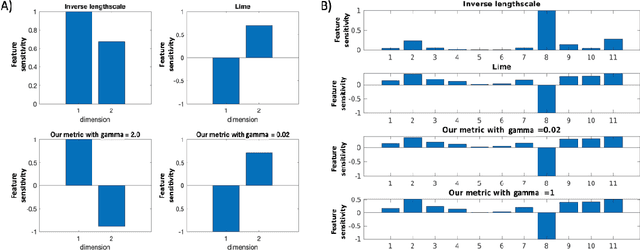
We consider Bayesian classification with Gaussian processes (GPs) and define robustness of a classifier in terms of the worst-case difference in the classification probabilities with respect to input perturbations. For a subset of the input space $T\subseteq \mathbb{R}^m$ such properties reduce to computing the infimum and supremum of the classification probabilities for all points in $T$. Unfortunately, computing the above values is very challenging, as the classification probabilities cannot be expressed analytically. Nevertheless, using the theory of Gaussian processes, we develop a framework that, for a given dataset $\mathcal{D}$, a compact set of input points $T\subseteq \mathbb{R}^m$ and an error threshold $\epsilon>0$, computes lower and upper bounds of the classification probabilities by over-approximating the exact range with an error bounded by $\epsilon$. We provide experimental comparison of several approximate inference methods for classification on tasks associated to MNIST and SPAM datasets showing that our results enable quantification of uncertainty in adversarial classification settings.
Population-based Global Optimisation Methods for Learning Long-term Dependencies with RNNs
May 23, 2019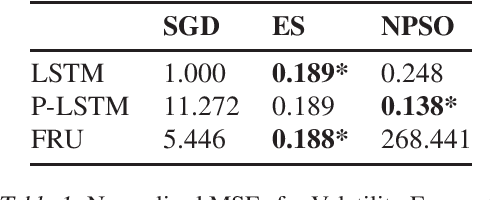
Despite recent innovations in network architectures and loss functions, training RNNs to learn long-term dependencies remains difficult due to challenges with gradient-based optimisation methods. Inspired by the success of Deep Neuroevolution in reinforcement learning (Such et al. 2017), we explore the use of gradient-free population-based global optimisation (PBO) techniques -- training RNNs to capture long-term dependencies in time-series data. Testing evolution strategies (ES) and particle swarm optimisation (PSO) on an application in volatility forecasting, we demonstrate that PBO methods lead to performance improvements in general, with ES exhibiting the most consistent results across a variety of architectures.
Enhancing Time Series Momentum Strategies Using Deep Neural Networks
Apr 09, 2019While time series momentum is a well-studied phenomenon in finance, common strategies require the explicit definition of both a trend estimator and a position sizing rule. In this paper, we introduce Deep Momentum Networks -- a hybrid approach which injects deep learning based trading rules into the volatility scaling framework of time series momentum. The model also simultaneously learns both trend estimation and position sizing in a data-driven manner, with networks directly trained by optimising the Sharpe ratio of the signal. Backtesting on a portfolio of 88 continuous futures contracts, we demonstrate that the Sharpe-optimised LSTM improved traditional methods by more than two times in the absence of transactions costs, and continue outperforming when considering transaction costs up to 2-3 basis points. To account for more illiquid assets, we also propose a turnover regularisation term which trains the network to factor in costs at run-time.
A Machine Learning approach to Risk Minimisation in Electricity Markets with Coregionalized Sparse Gaussian Processes
Apr 03, 2019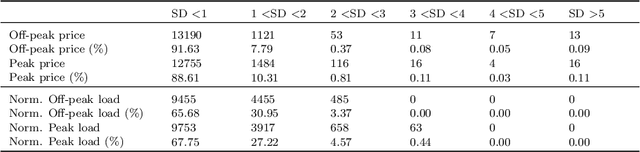
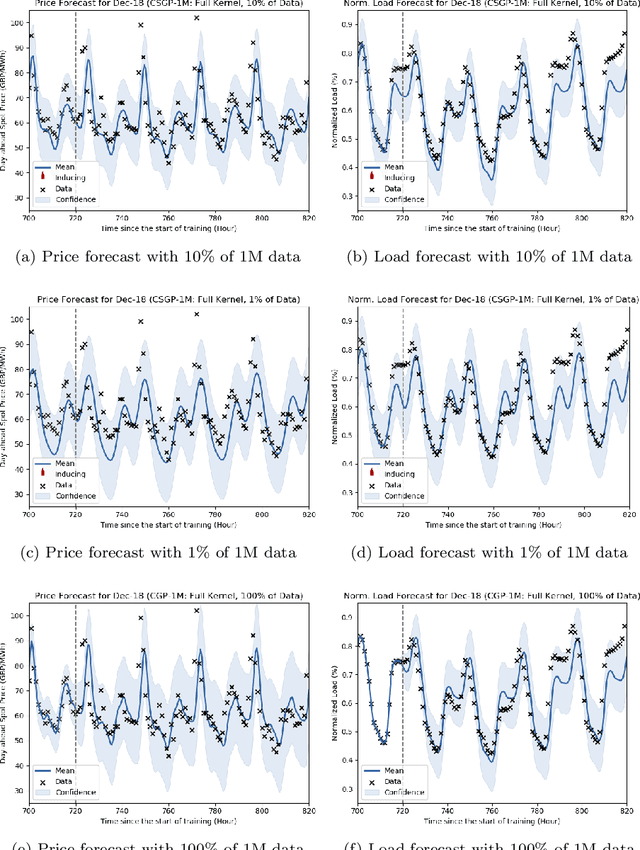
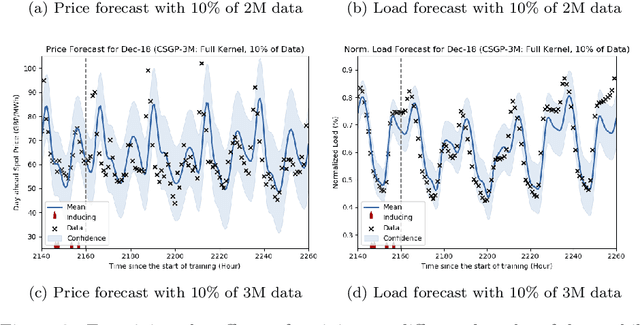
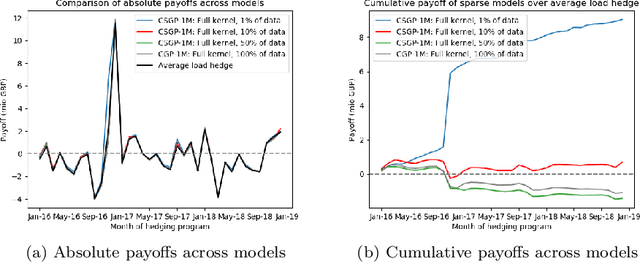
The non-storability of electricity makes it unique among commodity assets, and it is an important driver of its price behaviour in secondary financial markets. The instantaneous and continuous matching of power supply with demand is a key factor explaining its volatility. During periods of high demand, costlier generation capabilities are utilised since electricity cannot be stored and this has the impact of driving prices up very quickly. Furthermore, the non-storability also complicates physical hedging. Owing to these, the problem of joint price-quantity risk in electricity markets is a commonly studied theme. We propose using Gaussian Processes (GPs) to tackle this problem since GPs provide a versatile and elegant non-parametric approach for regression and time-series modelling. However, GPs scale poorly with the amount of training data due to a cubic complexity. These considerations suggest that knowledge transfer between price and load is vital for effective hedging, and that a computationally efficient method is required. To this end, we use the coregionalized (or multi-task) sparse GPs which addresses the aforementioned issues. To gauge the performance of our model, we use an average-load strategy as comparator. The latter is a robust approach commonly used by industry. If the spot and load are uncorrelated and Gaussian, then hedging with the expected load will result in the minimum variance position. Our main contributions are twofold. Firstly, in developing a coregionalized sparse GP-based approach for hedging. Secondly, in demonstrating that our model-based strategy outperforms the comparator, and can thus be employed for effective hedging in electricity markets.
WiSE-ALE: Wide Sample Estimator for Approximate Latent Embedding
Mar 18, 2019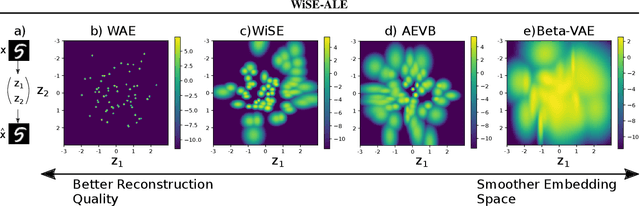
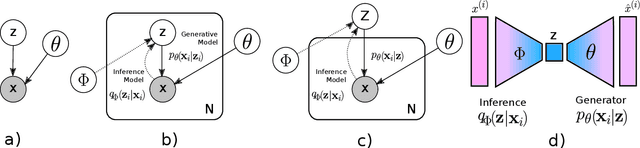
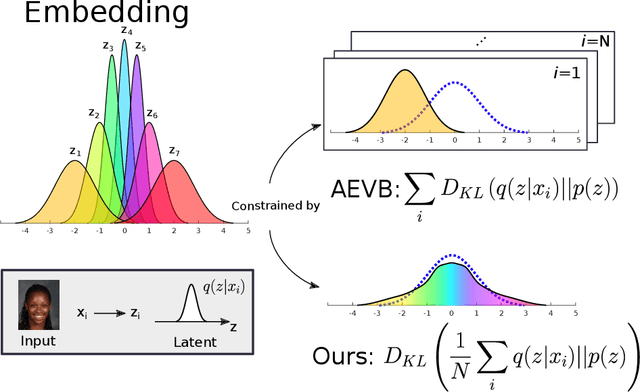
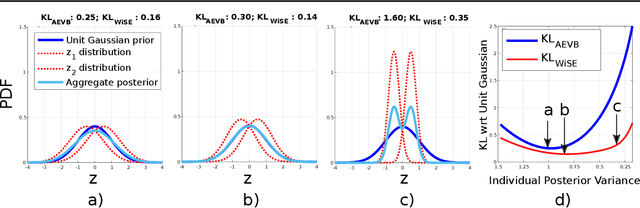
Variational Auto-encoders (VAEs) have been very successful as methods for forming compressed latent representations of complex, often high-dimensional, data. In this paper, we derive an alternative variational lower bound from the one common in VAEs, which aims to minimize aggregate information loss. Using our lower bound as the objective function for an auto-encoder enables us to place a prior on the bulk statistics, corresponding to an aggregate posterior for the entire dataset, as opposed to a single sample posterior as in the original VAE. This alternative form of prior constraint allows individual posteriors more flexibility to preserve necessary information for good reconstruction quality. We further derive an analytic approximation to our lower bound, leading to an efficient learning algorithm - WiSE-ALE. Through various examples, we demonstrate that WiSE-ALE can reach excellent reconstruction quality in comparison to other state-of-the-art VAE models, while still retaining the ability to learn a smooth, compact representation.
Recurrent Neural Filters: Learning Independent Bayesian Filtering Steps for Time Series Prediction
Jan 23, 2019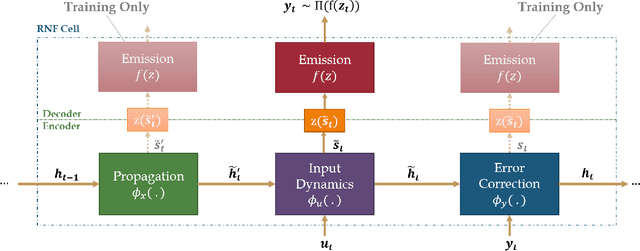
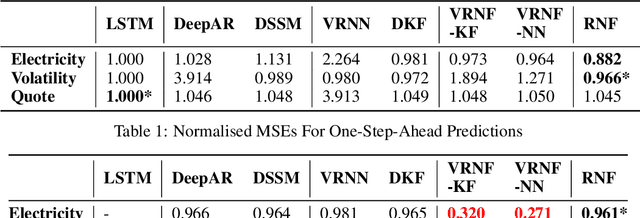
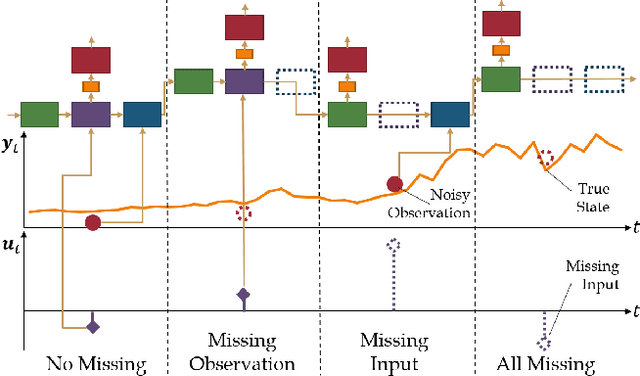
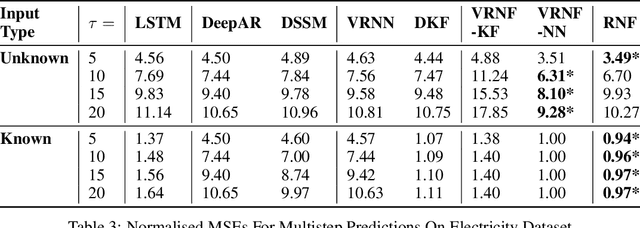
Despite the recent popularity of deep generative state space models, few comparisons have been made between network architectures and the inference steps of the Bayesian filtering framework -- with most models simultaneously approximating both state transition and update steps with a single recurrent neural network (RNN). In this paper, we introduce the Recurrent Neural Filter (RNF), a novel recurrent variational autoencoder architecture that learns distinct representations for each Bayesian filtering step, captured by a series of encoders and decoders. Testing this on three real-world time series datasets, we demonstrate that decoupling representations not only improves the accuracy of one-step-ahead forecasts while providing realistic uncertainty estimates, but also facilitates multistep prediction through the separation of encoder stages.