 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bayesian latent class reinforcement learning framework to capture adaptive, feedback-driven travel behaviour
Dec 08, 2025



Many travel decisions involve a degree of experience formation, where individuals learn their preferences over time. At the same time, there is extensive scope for heterogeneity across individual travellers, both in their underlying preferences and in how these evolve. The present paper puts forward a Latent Class Reinforcement Learning (LCRL) model that allows analysts to capture both of these phenomena. We apply the model to a driving simulator dataset and estimate the parameters through Variational Bayes. We identify three distinct classes of individuals that differ markedly in how they adapt their preferences: the first displays context-dependent preferences with context-specific exploitative tendencies; the second follows a persistent exploitative strategy regardless of context; and the third engages in an exploratory strategy combined with context-specific preferences.
Can large language models assist choice modelling? Insights into prompting strategies and current models capabilities
Jul 29, 2025Large Language Models (LLMs) are widely used to support various workflows across different disciplines, yet their potential in choice modelling remains relatively unexplored. This work examines the potential of LLMs as assistive agents in the specification and, where technically feasible, estimation of Multinomial Logit models. We implement a systematic experimental framework involving thirteen versions of six leading LLMs (ChatGPT, Claude, DeepSeek, Gemini, Gemma, and Llama) evaluated under five experimental configurations. These configurations vary along three dimensions: modelling goal (suggesting vs. suggesting and estimating MNLs); prompting strategy (Zero-Shot vs. Chain-of-Thoughts); and information availability (full dataset vs. data dictionary only). Each LLM-suggested specification is implemented, estimated, and evaluated based on goodness-of-fit metrics, behavioural plausibility, and model complexity. Findings reveal that proprietary LLMs can generate valid and behaviourally sound utility specifications, particularly when guided by structured prompts. Open-weight models such as Llama and Gemma struggled to produce meaningful specifications. Claude 4 Sonnet consistently produced the best-fitting and most complex models, while GPT models suggested models with robust and stable modelling outcomes. Some LLMs performed better when provided with just data dictionary, suggesting that limiting raw data access may enhance internal reasoning capabilities. Among all LLMs, GPT o3 was uniquely capable of correctly estimating its own specifications by executing self-generated code. Overall, the results demonstrate both the promise and current limitations of LLMs as assistive agents in choice modelling, not only for model specification but also for supporting modelling decision and estimation, and provide practical guidance for integrating these tools into choice modellers' workflows.
Improving choice model specification using reinforcement learning
Jun 06, 2025



Discrete choice modelling is a theory-driven modelling framework for understanding and forecasting choice behaviour. To obtain behavioural insights, modellers test several competing model specifications in their attempts to discover the 'true' data generation process. This trial-and-error process requires expertise, is time-consuming, and relies on subjective theoretical assumptions. Although metaheuristics have been proposed to assist choice modellers, they treat model specification as a classic optimisation problem, relying on static strategies, applying predefined rules, and neglecting outcomes from previous estimated models. As a result, current metaheuristics struggle to prioritise promising search regions, adapt exploration dynamically, and transfer knowledge to other modelling tasks. To address these limitations, we introduce a deep reinforcement learning-based framework where an 'agent' specifies models by estimating them and receiving rewards based on goodness-of-fit and parsimony. Results demonstrate the agent dynamically adapts its strategies to identify promising specifications across data generation processes, showing robustness and potential transferability, without prior domain knowledge.
Comparing hundreds of machine learning classifiers and discrete choice models in predicting travel behavior: an empirical benchmark
Feb 01, 2021

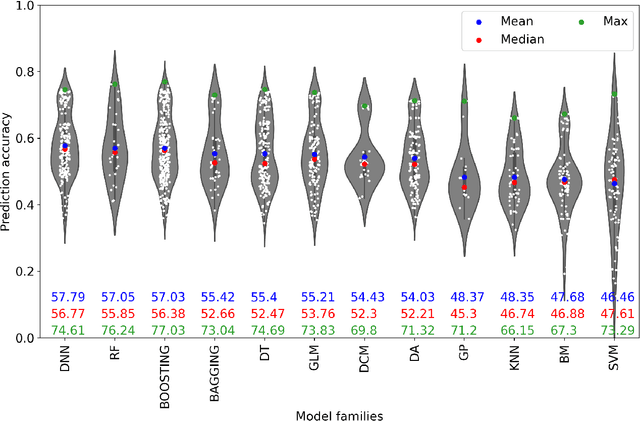
Researchers have compared machine learning (ML) classifiers and discrete choice models (DCMs) in predicting travel behavior, but the generalizability of the findings is limited by the specifics of data, contexts, and authors' expertise. This study seeks to provide a generalizable empirical benchmark by comparing hundreds of ML and DCM classifiers in a highly structured manner. The experiments evaluate both prediction accuracy and computational cost by spanning four hyper-dimensions, including 105 ML and DCM classifiers from 12 model families, 3 datasets, 3 sample sizes, and 3 outputs. This experimental design leads to an immense number of 6,970 experiments, which are corroborated with a meta dataset of 136 experiment points from 35 previous studies. This study is hitherto the most comprehensive and almost exhaustive comparison of the classifiers for travel behavioral prediction. We found that the ensemble methods and deep neural networks achieve the highest predictive performance, but at a relatively high computational cost. Random forests are the most computationally efficient, balancing between prediction and computation. While discrete choice models offer accuracy with only 3-4 percentage points lower than the top ML classifiers, they have much longer computational time and become computationally impossible with large sample size, high input dimensions, or simulation-based estimation. The relative ranking of the ML and DCM classifiers is highly stable, while the absolute values of the prediction accuracy and computational time have large variations. Overall, this paper suggests using deep neural networks, model ensembles, and random forests as baseline models for future travel behavior prediction. For choice modeling, the DCM community should switch more attention from fitting models to improving computational efficiency, so that the DCMs can be widely adopted in the big data context.
Uncovering life-course patterns with causal discovery and survival analysis
Jan 30, 2020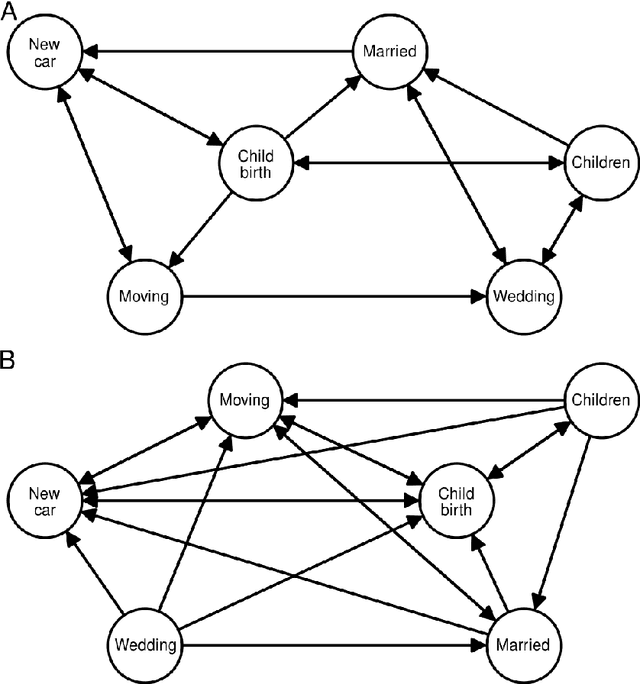
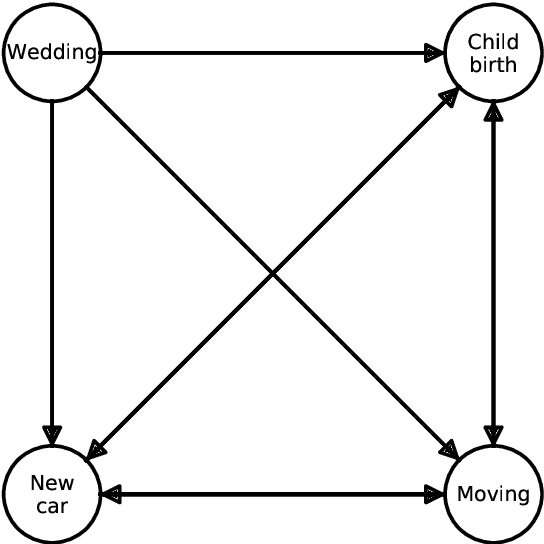
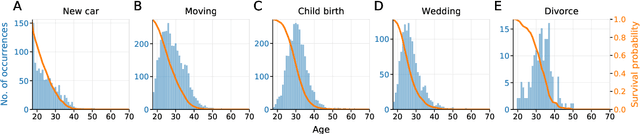
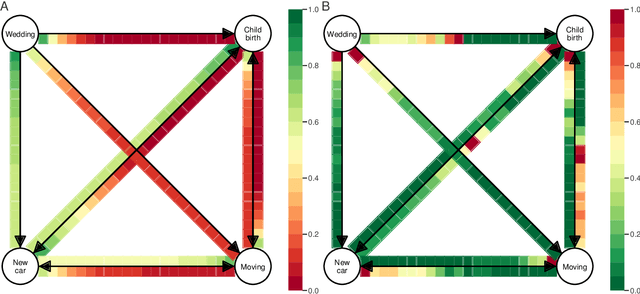
We provide a novel approach and an exploratory study for modelling life event choices and occurrence from a probabilistic perspective through causal discovery and survival analysis. Our approach is formulated as a bi-level problem. In the upper level, we build the life events graph, using causal discovery tools. In the lower level, for the pairs of life events, time-to-event modelling through survival analysis is applied to model time-dependent transition probabilities. Several life events were analysed, such as getting married, buying a new car, child birth, home relocation and divorce, together with the socio-demographic attributes for survival modelling, some of which are age, nationality, number of children, number of cars and home ownership. The data originates from a survey conducted in Dortmund, Germany, with the questionnaire containing a series of retrospective questions about residential and employment biography, travel behaviour and holiday trips, as well as socio-economic characteristic. Although survival analysis has been used in the past to analyse life-course data, this is the first time that a bi-level model has been formulated. The inclusion of a causal discovery algorithm in the upper-level allows us to first identify causal relationships between life-course events and then understand the factors that might influence transition rates between events. This is very different from more classic choice models where causal relationships are subject to expert interpretations based on model results.