 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan large language models assist choice modelling? Insights into prompting strategies and current models capabilities
Jul 29, 2025Large Language Models (LLMs) are widely used to support various workflows across different disciplines, yet their potential in choice modelling remains relatively unexplored. This work examines the potential of LLMs as assistive agents in the specification and, where technically feasible, estimation of Multinomial Logit models. We implement a systematic experimental framework involving thirteen versions of six leading LLMs (ChatGPT, Claude, DeepSeek, Gemini, Gemma, and Llama) evaluated under five experimental configurations. These configurations vary along three dimensions: modelling goal (suggesting vs. suggesting and estimating MNLs); prompting strategy (Zero-Shot vs. Chain-of-Thoughts); and information availability (full dataset vs. data dictionary only). Each LLM-suggested specification is implemented, estimated, and evaluated based on goodness-of-fit metrics, behavioural plausibility, and model complexity. Findings reveal that proprietary LLMs can generate valid and behaviourally sound utility specifications, particularly when guided by structured prompts. Open-weight models such as Llama and Gemma struggled to produce meaningful specifications. Claude 4 Sonnet consistently produced the best-fitting and most complex models, while GPT models suggested models with robust and stable modelling outcomes. Some LLMs performed better when provided with just data dictionary, suggesting that limiting raw data access may enhance internal reasoning capabilities. Among all LLMs, GPT o3 was uniquely capable of correctly estimating its own specifications by executing self-generated code. Overall, the results demonstrate both the promise and current limitations of LLMs as assistive agents in choice modelling, not only for model specification but also for supporting modelling decision and estimation, and provide practical guidance for integrating these tools into choice modellers' workflows.
Improving choice model specification using reinforcement learning
Jun 06, 2025



Discrete choice modelling is a theory-driven modelling framework for understanding and forecasting choice behaviour. To obtain behavioural insights, modellers test several competing model specifications in their attempts to discover the 'true' data generation process. This trial-and-error process requires expertise, is time-consuming, and relies on subjective theoretical assumptions. Although metaheuristics have been proposed to assist choice modellers, they treat model specification as a classic optimisation problem, relying on static strategies, applying predefined rules, and neglecting outcomes from previous estimated models. As a result, current metaheuristics struggle to prioritise promising search regions, adapt exploration dynamically, and transfer knowledge to other modelling tasks. To address these limitations, we introduce a deep reinforcement learning-based framework where an 'agent' specifies models by estimating them and receiving rewards based on goodness-of-fit and parsimony. Results demonstrate the agent dynamically adapts its strategies to identify promising specifications across data generation processes, showing robustness and potential transferability, without prior domain knowledge.
Structure-preserving contrastive learning for spatial time series
Feb 10, 2025



Informative representations enhance model performance and generalisability in downstream tasks. However, learning self-supervised representations for spatially characterised time series, like traffic interactions, poses challenges as it requires maintaining fine-grained similarity relations in the latent space. In this study, we incorporate two structure-preserving regularisers for the contrastive learning of spatial time series: one regulariser preserves the topology of similarities between instances, and the other preserves the graph geometry of similarities across spatial and temporal dimensions. To balance contrastive learning and structure preservation, we propose a dynamic mechanism that adaptively weighs the trade-off and stabilises training. We conduct experiments on multivariate time series classification, as well as macroscopic and microscopic traffic prediction. For all three tasks, our approach preserves the structures of similarity relations more effectively and improves state-of-the-art task performances. The proposed approach can be applied to an arbitrary encoder and is particularly beneficial for time series with spatial or geographical features. Furthermore, this study suggests that higher similarity structure preservation indicates more informative and useful representations. This may help to understand the contribution of representation learning in pattern recognition with neural networks. Our code is made openly accessible with all resulting data at https://github.com/yiru-jiao/spclt.
A utility-based spatial analysis of residential street-level conditions; A case study of Rotterdam
Oct 23, 2024



Residential location choices are traditionally modelled using factors related to accessibility and socioeconomic environments, neglecting the importance of local street-level conditions. Arguably, this neglect is due to data practices. Today, however, street-level images -- which are highly effective at encoding street-level conditions -- are widely available. Additionally, recent advances in discrete choice models incorporating computer vision capabilities offer opportunities to integrate street-level conditions into residential location choice analysis. This study leverages these developments to investigate the spatial distribution of utility derived from street-level conditions in residential location choices on a city-wide scale. In our case study of Rotterdam, the Netherlands, we find that the utility derived from street-level conditions varies significantly on a highly localised scale, with conditions rapidly changing even within neighbourhoods. Our results also reveal that the high real-estate prices in the city centre cannot be attributed to attractive street-level conditions. Furthermore, whereas the city centre is characterised by relatively unattractive residential street-level conditions, neighbourhoods in the southern part of the city -- often perceived as problematic -- exhibit surprisingly appealing street-level environments. The methodological contribution of this paper is that it advances the discrete choice models incorporating computer vision capabilities by introducing a semantic regularisation layer to the model. Thereby, it adds explainability and eliminates the need for a separate pipeline to extract information from images, streamlining the analysis. As such, this paper's findings and methodological advancements pave the way for further studies to explore integrating street-level conditions in urban planning.
A unified theory and statistical learning approach for traffic conflict detection
Jul 15, 2024



This study proposes a unified theory and statistical learning approach for traffic conflict detection, addressing the long-existing call for a consistent and comprehensive methodology to evaluate the collision risk emerged in road user interactions. The proposed theory assumes a context-dependent probabilistic collision risk and frames conflict detection as estimating the risk by statistical learning from observed proximities and contextual variables. Three primary tasks are integrated: representing interaction context from selected observables, inferring proximity distributions in different contexts, and applying extreme value theory to relate conflict intensity with conflict probability. As a result, this methodology is adaptable to various road users and interaction scenarios, enhancing its applicability without the need for pre-labelled conflict data. Demonstration experiments are executed using real-world trajectory data, with the unified metric trained on lane-changing interactions on German highways and applied to near-crash events from the 100-Car Naturalistic Driving Study in the U.S. The experiments demonstrate the methodology's ability to provide effective collision warnings, generalise across different datasets and traffic environments, cover a broad range of conflicts, and deliver a long-tailed distribution of conflict intensity. This study contributes to traffic safety by offering a consistent and explainable methodology for conflict detection applicable across various scenarios. Its societal implications include enhanced safety evaluations of traffic infrastructures, more effective collision warning systems for autonomous and driving assistance systems, and a deeper understanding of road user behaviour in different traffic conditions, contributing to a potential reduction in accident rates and improving overall traffic safety.
An economically-consistent discrete choice model with flexible utility specification based on artificial neural networks
Apr 19, 2024



Random utility maximisation (RUM) models are one of the cornerstones of discrete choice modelling. However, specifying the utility function of RUM models is not straightforward and has a considerable impact on the resulting interpretable outcomes and welfare measures. In this paper, we propose a new discrete choice model based on artificial neural networks (ANNs) named "Alternative-Specific and Shared weights Neural Network (ASS-NN)", which provides a further balance between flexible utility approximation from the data and consistency with two assumptions: RUM theory and fungibility of money (i.e., "one euro is one euro"). Therefore, the ASS-NN can derive economically-consistent outcomes, such as marginal utilities or willingness to pay, without explicitly specifying the utility functional form. Using a Monte Carlo experiment and empirical data from the Swissmetro dataset, we show that ASS-NN outperforms (in terms of goodness of fit) conventional multinomial logit (MNL) models under different utility specifications. Furthermore, we show how the ASS-NN is used to derive marginal utilities and willingness to pay measures.
Computer vision-enriched discrete choice models, with an application to residential location choice
Aug 16, 2023



Visual imagery is indispensable to many multi-attribute decision situations. Examples of such decision situations in travel behaviour research include residential location choices, vehicle choices, tourist destination choices, and various safety-related choices. However, current discrete choice models cannot handle image data and thus cannot incorporate information embedded in images into their representations of choice behaviour. This gap between discrete choice models' capabilities and the real-world behaviour it seeks to model leads to incomplete and, possibly, misleading outcomes. To solve this gap, this study proposes "Computer Vision-enriched Discrete Choice Models" (CV-DCMs). CV-DCMs can handle choice tasks involving numeric attributes and images by integrating computer vision and traditional discrete choice models. Moreover, because CV-DCMs are grounded in random utility maximisation principles, they maintain the solid behavioural foundation of traditional discrete choice models. We demonstrate the proposed CV-DCM by applying it to data obtained through a novel stated choice experiment involving residential location choices. In this experiment, respondents faced choice tasks with trade-offs between commute time, monthly housing cost and street-level conditions, presented using images. As such, this research contributes to the growing body of literature in the travel behaviour field that seeks to integrate discrete choice modelling and machine learning.
Explainability of Deep Learning models for Urban Space perception
Aug 29, 2022
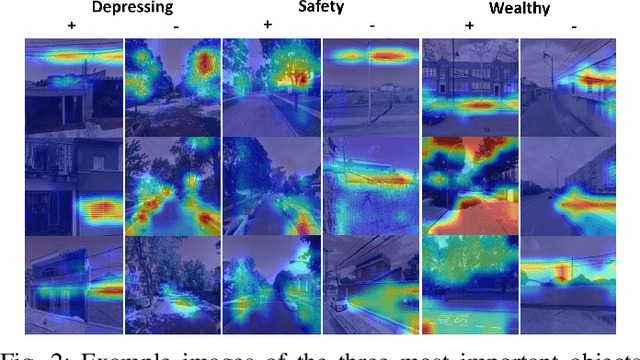
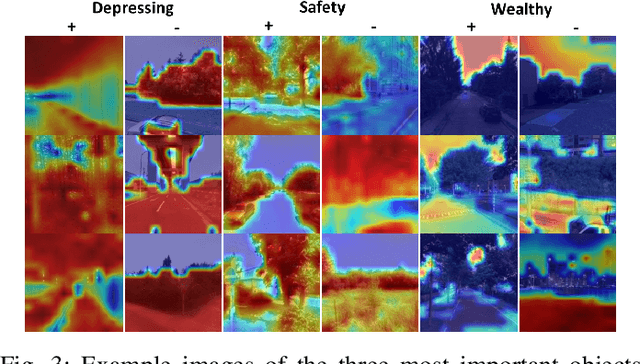
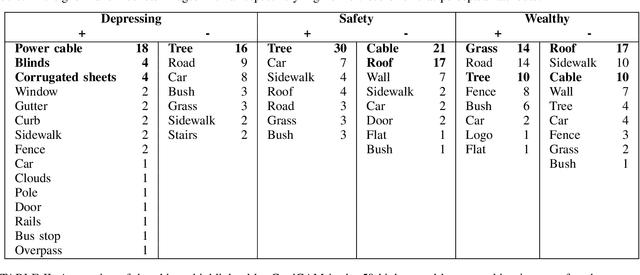
Deep learning based computer vision models are increasingly used by urban planners to support decision making for shaping urban environments. Such models predict how people perceive the urban environment quality in terms of e.g. its safety or beauty. However, the blackbox nature of deep learning models hampers urban planners to understand what landscape objects contribute to a particularly high quality or low quality urban space perception. This study investigates how computer vision models can be used to extract relevant policy information about peoples' perception of the urban space. To do so, we train two widely used computer vision architectures; a Convolutional Neural Network and a transformer, and apply GradCAM -- a well-known ex-post explainable AI technique -- to highlight the image regions important for the model's prediction. Using these GradCAM visualizations, we manually annotate the objects relevant to the models' perception predictions. As a result, we are able to discover new objects that are not represented in present object detection models used for annotation in previous studies. Moreover, our methodological results suggest that transformer architectures are better suited to be used in combination with GradCAM techniques. Code is available on Github.