 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bayesian latent class reinforcement learning framework to capture adaptive, feedback-driven travel behaviour
Dec 08, 2025



Many travel decisions involve a degree of experience formation, where individuals learn their preferences over time. At the same time, there is extensive scope for heterogeneity across individual travellers, both in their underlying preferences and in how these evolve. The present paper puts forward a Latent Class Reinforcement Learning (LCRL) model that allows analysts to capture both of these phenomena. We apply the model to a driving simulator dataset and estimate the parameters through Variational Bayes. We identify three distinct classes of individuals that differ markedly in how they adapt their preferences: the first displays context-dependent preferences with context-specific exploitative tendencies; the second follows a persistent exploitative strategy regardless of context; and the third engages in an exploratory strategy combined with context-specific preferences.
Can large language models assist choice modelling? Insights into prompting strategies and current models capabilities
Jul 29, 2025Large Language Models (LLMs) are widely used to support various workflows across different disciplines, yet their potential in choice modelling remains relatively unexplored. This work examines the potential of LLMs as assistive agents in the specification and, where technically feasible, estimation of Multinomial Logit models. We implement a systematic experimental framework involving thirteen versions of six leading LLMs (ChatGPT, Claude, DeepSeek, Gemini, Gemma, and Llama) evaluated under five experimental configurations. These configurations vary along three dimensions: modelling goal (suggesting vs. suggesting and estimating MNLs); prompting strategy (Zero-Shot vs. Chain-of-Thoughts); and information availability (full dataset vs. data dictionary only). Each LLM-suggested specification is implemented, estimated, and evaluated based on goodness-of-fit metrics, behavioural plausibility, and model complexity. Findings reveal that proprietary LLMs can generate valid and behaviourally sound utility specifications, particularly when guided by structured prompts. Open-weight models such as Llama and Gemma struggled to produce meaningful specifications. Claude 4 Sonnet consistently produced the best-fitting and most complex models, while GPT models suggested models with robust and stable modelling outcomes. Some LLMs performed better when provided with just data dictionary, suggesting that limiting raw data access may enhance internal reasoning capabilities. Among all LLMs, GPT o3 was uniquely capable of correctly estimating its own specifications by executing self-generated code. Overall, the results demonstrate both the promise and current limitations of LLMs as assistive agents in choice modelling, not only for model specification but also for supporting modelling decision and estimation, and provide practical guidance for integrating these tools into choice modellers' workflows.
Attitudes and Latent Class Choice Models using Machine learning
Feb 20, 2023Latent Class Choice Models (LCCM) are extensions of discrete choice models (DCMs) that capture unobserved heterogeneity in the choice process by segmenting the population based on the assumption of preference similarities. We present a method of efficiently incorporating attitudinal indicators in the specification of LCCM, by introducing Artificial Neural Networks (ANN) to formulate latent variables constructs. This formulation overcomes structural equations in its capability of exploring the relationship between the attitudinal indicators and the decision choice, given the Machine Learning (ML) flexibility and power in capturing unobserved and complex behavioural features, such as attitudes and beliefs. All of this while still maintaining the consistency of the theoretical assumptions presented in the Generalized Random Utility model and the interpretability of the estimated parameters. We test our proposed framework for estimating a Car-Sharing (CS) service subscription choice with stated preference data from Copenhagen, Denmark. The results show that our proposed approach provides a complete and realistic segmentation, which helps design better policies.
Gaussian Process Latent Class Choice Models
Jan 28, 2021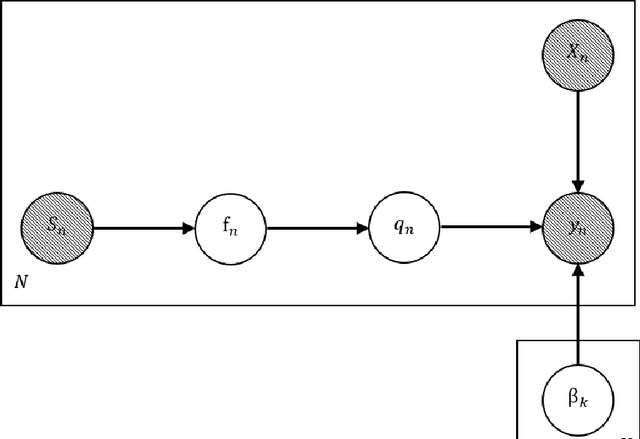
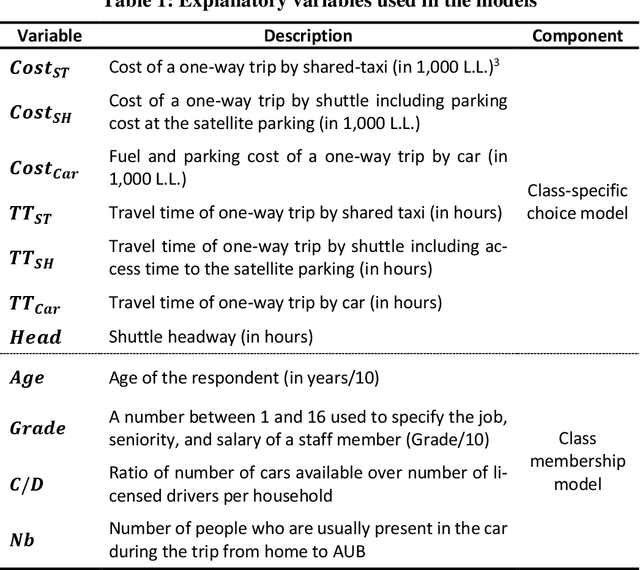
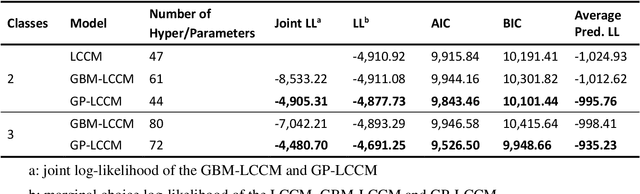
We present a Gaussian Process - Latent Class Choice Model (GP-LCCM) to integrate a non-parametric class of probabilistic machine learning within discrete choice models (DCMs). Gaussian Processes (GPs) are kernel-based algorithms that incorporate expert knowledge by assuming priors over latent functions rather than priors over parameters, which makes them more flexible in addressing nonlinear problems. By integrating a Gaussian Process within a LCCM structure, we aim at improving discrete representations of unobserved heterogeneity. The proposed model would assign individuals probabilistically to behaviorally homogeneous clusters (latent classes) using GPs and simultaneously estimate class-specific choice models by relying on random utility models. Furthermore, we derive and implement an Expectation-Maximization (EM) algorithm to jointly estimate/infer the hyperparameters of the GP kernel function and the class-specific choice parameters by relying on a Laplace approximation and gradient-based numerical optimization methods, respectively. The model is tested on two different mode choice applications and compared against different LCCM benchmarks. Results show that GP-LCCM allows for a more complex and flexible representation of heterogeneity and improves both in-sample fit and out-of-sample predictive power. Moreover, behavioral and economic interpretability is maintained at the class-specific choice model level while local interpretation of the latent classes can still be achieved, although the non-parametric characteristic of GPs lessens the transparency of the model.
Semi-nonparametric Latent Class Choice Model with a Flexible Class Membership Component: A Mixture Model Approach
Jul 06, 2020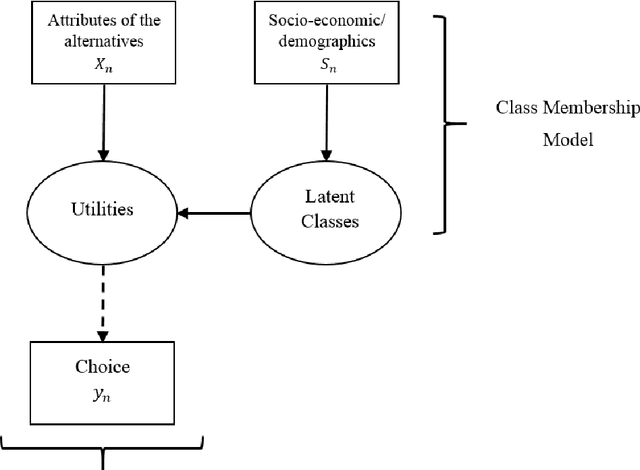
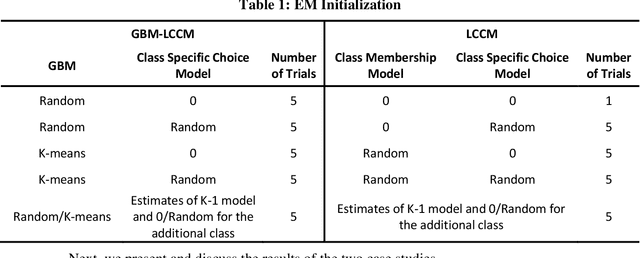
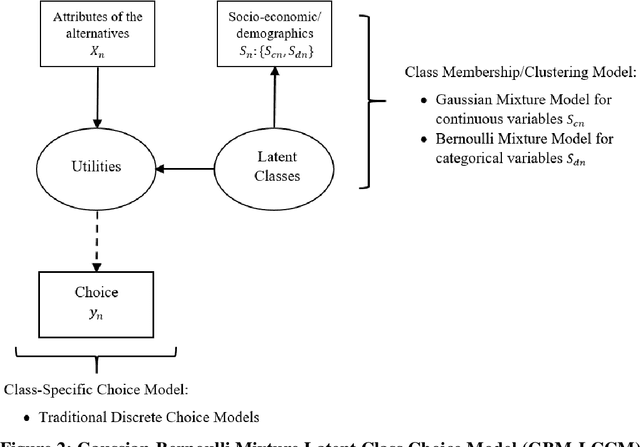
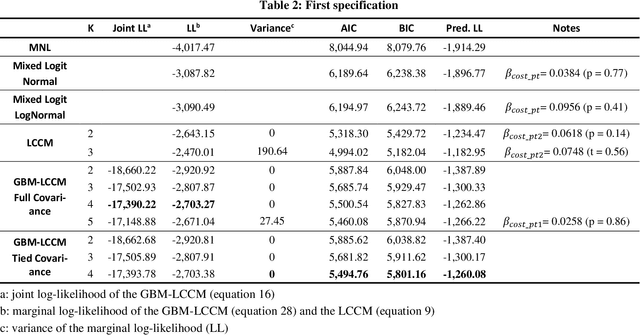
This study presents a semi-nonparametric Latent Class Choice Model (LCCM) with a flexible class membership component. The proposed model formulates the latent classes using mixture models as an alternative approach to the traditional random utility specification with the aim of comparing the two approaches on various measures including prediction accuracy and representation of heterogeneity in the choice process. Mixture models are parametric model-based clustering techniques that have been widely used in areas such as machine learning, data mining and patter recognition for clustering and classification problems. An Expectation-Maximization (EM) algorithm is derived for the estimation of the proposed model. Using two different case studies on travel mode choice behavior, the proposed model is compared to traditional discrete choice models on the basis of parameter estimates' signs, value of time, statistical goodness-of-fit measures, and cross-validation tests. Results show that mixture models improve the overall performance of latent class choice models by providing better out-of-sample prediction accuracy in addition to better representations of heterogeneity without weakening the behavioral and economic interpretability of the choice models.