 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERMAS: Becoming Robust to Reward Function Sim-to-Real Gaps in Multi-Agent Simulations
Jun 10, 2021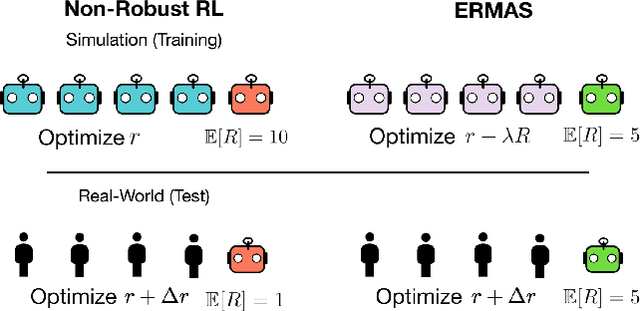
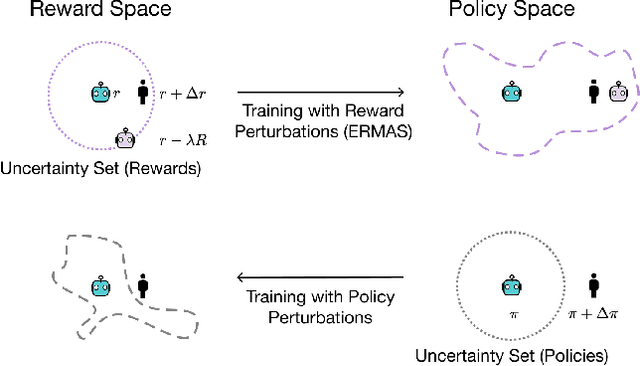
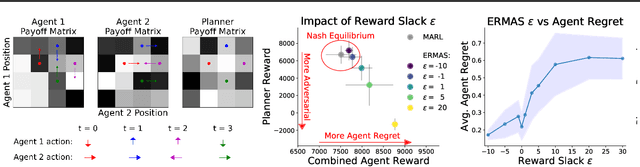
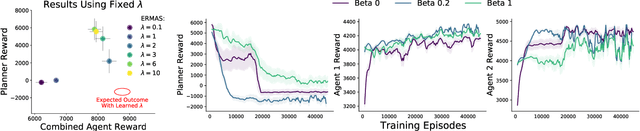
Multi-agent simulations provide a scalable environment for learning policies that interact with rational agents. However, such policies may fail to generalize to the real-world where agents may differ from simulated counterparts due to unmodeled irrationality and misspecified reward functions. We introduce Epsilon-Robust Multi-Agent Simulation (ERMAS), a robust optimization framework for learning AI policies that are robust to such multiagent sim-to-real gaps. While existing notions of multi-agent robustness concern perturbations in the actions of agents, we address a novel robustness objective concerning perturbations in the reward functions of agents. ERMAS provides this robustness by anticipating suboptimal behaviors from other agents, formalized as the worst-case epsilon-equilibrium. We show empirically that ERMAS yields robust policies for repeated bimatrix games and optimal taxation problems in economic simulations. In particular, in the two-level RL problem posed by the AI Economist (Zheng et al., 2020) ERMAS learns tax policies that are robust to changes in agent risk aversion, improving social welfare by up to 15% in complex spatiotemporal simulations.
Robustness Gym: Unifying the NLP Evaluation Landscape
Jan 13, 2021Despite impressive performance on standard benchmarks, deep neural networks are often brittle when deployed in real-world systems. Consequently, recent research has focused on testing the robustness of such models, resulting in a diverse set of evaluation methodologies ranging from adversarial attacks to rule-based data transformations. In this work, we identify challenges with evaluating NLP systems and propose a solution in the form of Robustness Gym (RG), a simple and extensible evaluation toolkit that unifies 4 standard evaluation paradigms: subpopulations, transformations, evaluation sets, and adversarial attacks. By providing a common platform for evaluation, Robustness Gym enables practitioners to compare results from all 4 evaluation paradigms with just a few clicks, and to easily develop and share novel evaluation methods using a built-in set of abstractions. To validate Robustness Gym's utility to practitioners, we conducted a real-world case study with a sentiment-modeling team, revealing performance degradations of 18%+. To verify that Robustness Gym can aid novel research analyses, we perform the first study of state-of-the-art commercial and academic named entity linking (NEL) systems, as well as a fine-grained analysis of state-of-the-art summarization models. For NEL, commercial systems struggle to link rare entities and lag their academic counterparts by 10%+, while state-of-the-art summarization models struggle on examples that require abstraction and distillation, degrading by 9%+. Robustness Gym can be found at https://robustnessgym.com/
The Rise of AI-Driven Simulators: Building a New Crystal Ball
Dec 11, 2020The use of computational simulation is by now so pervasive in society that it is no exaggeration to say that continued U.S. and international prosperity, security, and health depend in part on continued improvements in simulation capabilities. What if we could predict weather two weeks out, guide the design of new drugs for new viral diseases, or manage new manufacturing processes that cut production costs and times by an order of magnitude? What if we could predict collective human behavior, for example, response to an evacuation request during a natural disaster, or labor response to fiscal stimulus? (See also the companion CCC Quad Paper on Pandemic Informatics, which discusses features that would be essential to solving large-scale problems like preparation for, and response to, the inevitable next pandemic.) The past decade has brought remarkable advances in complementary areas: in sensors, which can now capture enormous amounts of data about the world, and in AI methods capable of learning to extract predictive patterns from those data. These advances may lead to a new era in computational simulation, in which sensors of many kinds are used to produce vast quantities of data, AI methods identify patterns in those data, and new AI-driven simulators combine machine-learned and mathematical rules to make accurate and actionable predictions. At the same time, there are new challenges -- computers in some important regards are no longer getting faster, and in some areas we are reaching the limits of mathematical understanding, or at least of our ability to translate mathematical understanding into efficient simulation. In this paper, we lay out some themes that we envision forming part of a cohesive, multi-disciplinary, and application-inspired research agenda on AI-driven simulators.
ESPRIT: Explaining Solutions to Physical Reasoning Tasks
May 14, 2020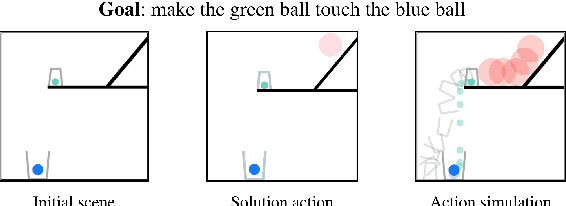

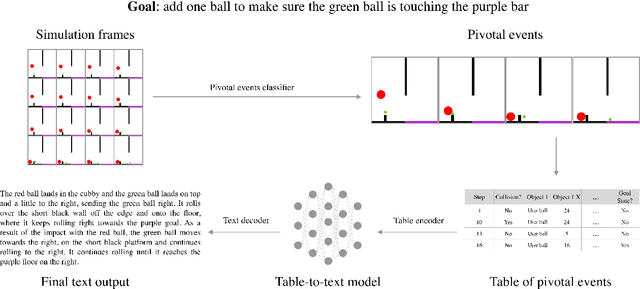
Neural networks lack the ability to reason about qualitative physics and so cannot generalize to scenarios and tasks unseen during training. We propose ESPRIT, a framework for commonsense reasoning about qualitative physics in natural language that generates interpretable descriptions of physical events. We use a two-step approach of first identifying the pivotal physical events in an environment and then generating natural language descriptions of those events using a data-to-text approach. Our framework learns to generate explanations of how the physical simulation will causally evolve so that an agent or a human can easily reason about a solution using those interpretable descriptions. Human evaluations indicate that ESPRIT produces crucial fine-grained details and has high coverage of physical concepts compared to even human annotations. Dataset, code and documentation are available at https://github.com/salesforce/esprit.
The AI Economist: Improving Equality and Productivity with AI-Driven Tax Policies
Apr 28, 2020
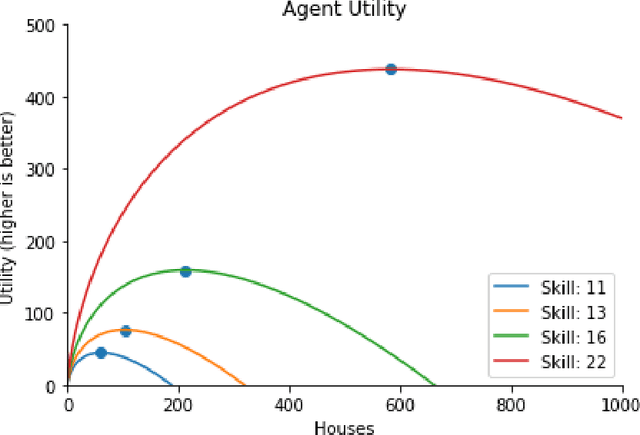
Tackling real-world socio-economic challenges requires designing and testing economic policies. However, this is hard in practice, due to a lack of appropriate (micro-level) economic data and limited opportunity to experiment. In this work, we train social planners that discover tax policies in dynamic economies that can effectively trade-off economic equality and productivity. We propose a two-level deep reinforcement learning approach to learn dynamic tax policies, based on economic simulations in which both agents and a government learn and adapt. Our data-driven approach does not make use of economic modeling assumptions, and learns from observational data alone. We make four main contributions. First, we present an economic simulation environment that features competitive pressures and market dynamics. We validate the simulation by showing that baseline tax systems perform in a way that is consistent with economic theory, including in regard to learned agent behaviors and specializations. Second, we show that AI-driven tax policies improve the trade-off between equality and productivity by 16% over baseline policies, including the prominent Saez tax framework. Third, we showcase several emergent features: AI-driven tax policies are qualitatively different from baselines, setting a higher top tax rate and higher net subsidies for low incomes. Moreover, AI-driven tax policies perform strongly in the face of emergent tax-gaming strategies learned by AI agents. Lastly, AI-driven tax policies are also effective when used in experiments with human participants. In experiments conducted on MTurk, an AI tax policy provides an equality-productivity trade-off that is similar to that provided by the Saez framework along with higher inverse-income weighted social welfare.
Multiresolution Tensor Learning for Efficient and Interpretable Spatial Analysis
Feb 15, 2020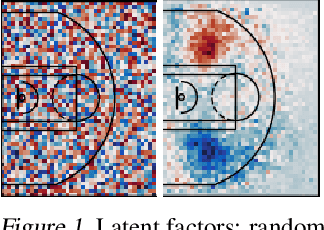
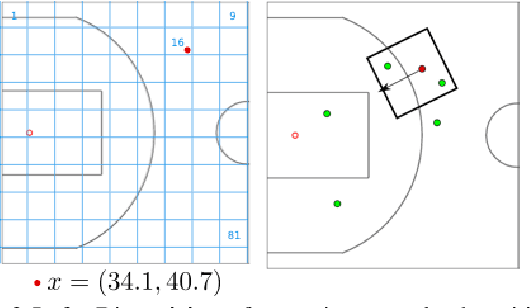

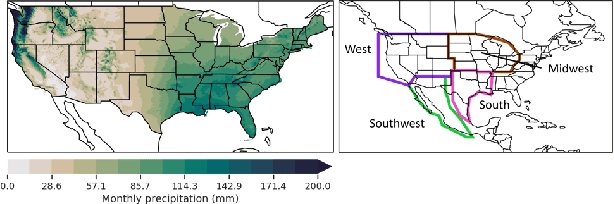
Efficient and interpretable spatial analysis is crucial in many fields such as geology, sports, and climate science. Large-scale spatial data often contains complex higher-order correlations across features and locations. While tensor latent factor models can describe higher-order correlations, they are inherently computationally expensive to train. Furthermore, for spatial analysis, these models should not only be predictive but also be spatially coherent. However, latent factor models are sensitive to initialization and can yield inexplicable results. We develop a novel Multi-resolution Tensor Learning (MRTL) algorithm for efficiently learning interpretable spatial patterns. MRTL initializes the latent factors from an approximate full-rank tensor model for improved interpretability and progressively learns from a coarse resolution to the fine resolution for an enormous computation speedup. We also prove the theoretical convergence and computational complexity of MRTL. When applied to two real-world datasets, MRTL demonstrates 4 ~ 5 times speedup compared to a fixed resolution while yielding accurate and interpretable models.
Keeping Your Distance: Solving Sparse Reward Tasks Using Self-Balancing Shaped Rewards
Nov 04, 2019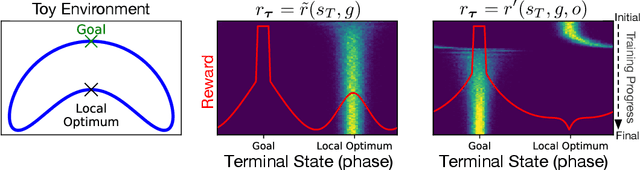
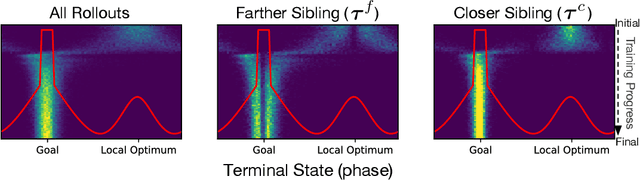
While using shaped rewards can be beneficial when solving sparse reward tasks, their successful application often requires careful engineering and is problem specific. For instance, in tasks where the agent must achieve some goal state, simple distance-to-goal reward shaping often fails, as it renders learning vulnerable to local optima. We introduce a simple and effective model-free method to learn from shaped distance-to-goal rewards on tasks where success depends on reaching a goal state. Our method introduces an auxiliary distance-based reward based on pairs of rollouts to encourage diverse exploration. This approach effectively prevents learning dynamics from stabilizing around local optima induced by the naive distance-to-goal reward shaping and enables policies to efficiently solve sparse reward tasks. Our augmented objective does not require any additional reward engineering or domain expertise to implement and converges to the original sparse objective as the agent learns to solve the task. We demonstrate that our method successfully solves a variety of hard-exploration tasks (including maze navigation and 3D construction in a Minecraft environment), where naive distance-based reward shaping otherwise fails, and intrinsic curiosity and reward relabeling strategies exhibit poor performance.
Sketch-Fill-A-R: A Persona-Grounded Chit-Chat Generation Framework
Oct 28, 2019

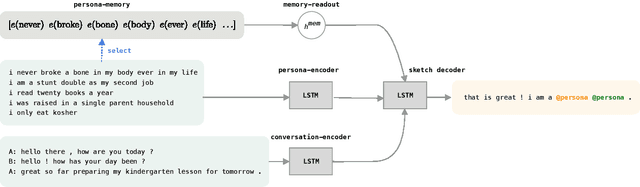

Human-like chit-chat conversation requires agents to generate responses that are fluent, engaging and consistent. We propose Sketch-Fill-A-R, a framework that uses a persona-memory to generate chit-chat responses in three phases. First, it generates dynamic sketch responses with open slots. Second, it generates candidate responses by filling slots with parts of its stored persona traits. Lastly, it ranks and selects the final response via a language model score. Sketch-Fill-A-R outperforms a state-of-the-art baseline both quantitatively (10-point lower perplexity) and qualitatively (preferred by 55% heads-up in single-turn and 20% higher in consistency in multi-turn user studies) on the Persona-Chat dataset. Finally, we extensively analyze Sketch-Fill-A-R's responses and human feedback, and show it is more consistent and engaging by using more relevant responses and questions.
Learning World Graphs to Accelerate Hierarchical Reinforcement Learning
Jul 01, 2019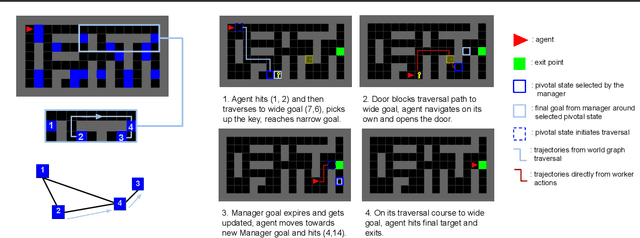
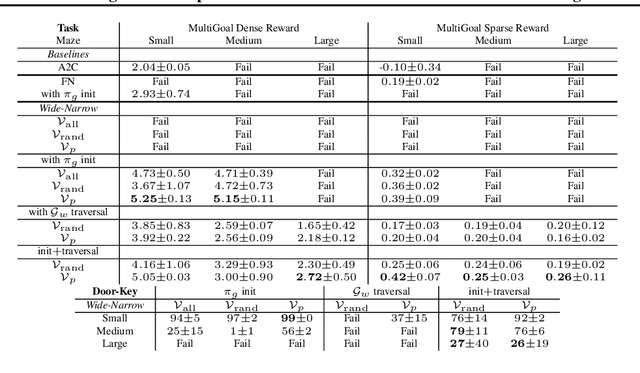
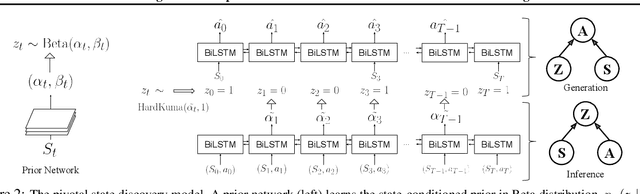
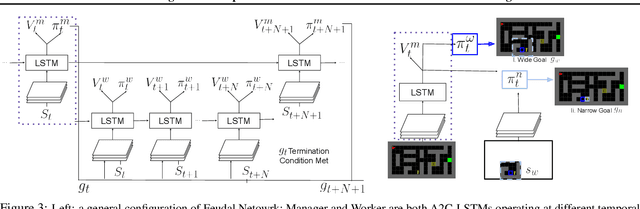
In many real-world scenarios, an autonomous agent often encounters various tasks within a single complex environment. We propose to build a graph abstraction over the environment structure to accelerate the learning of these tasks. Here, nodes are important points of interest (pivotal states) and edges represent feasible traversals between them. Our approach has two stages. First, we jointly train a latent pivotal state model and a curiosity-driven goal-conditioned policy in a task-agnostic manner. Second, provided with the information from the world graph, a high-level Manager quickly finds solution to new tasks and expresses subgoals in reference to pivotal states to a low-level Worker. The Worker can then also leverage the graph to easily traverse to the pivotal states of interest, even across long distance, and explore non-locally. We perform a thorough ablation study to evaluate our approach on a suite of challenging maze tasks, demonstrating significant advantages from the proposed framework over baselines that lack world graph knowledge in terms of performance and efficiency.
On the Generalization Gap in Reparameterizable Reinforcement Learning
May 29, 2019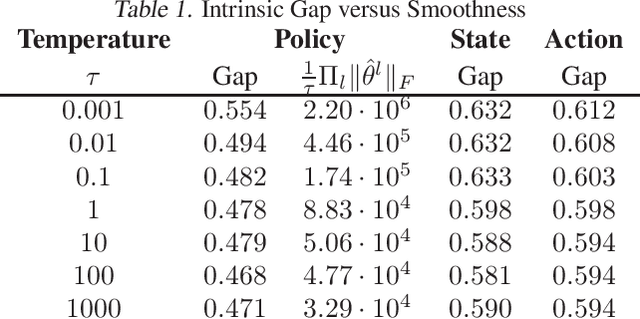
Understanding generalization in reinforcement learning (RL) is a significant challenge, as many common assumptions of traditional supervised learning theory do not apply. We focus on the special class of reparameterizable RL problems, where the trajectory distribution can be decomposed using the reparametrization trick. For this problem class, estimating the expected return is efficient and the trajectory can be computed deterministically given peripheral random variables, which enables us to study reparametrizable RL using supervised learning and transfer learning theory. Through these relationships, we derive guarantees on the gap between the expected and empirical return for both intrinsic and external errors, based on Rademacher complexity as well as the PAC-Bayes bound. Our bound suggests the generalization capability of reparameterizable RL is related to multiple factors including "smoothness" of the environment transition, reward and agent policy function class. We also empirically verify the relationship between the generalization gap and these factors through simulations.