 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Diffusions in Augmented Spaces: A Complete Recipe
Mar 03, 2023



Score-based Generative Models (SGMs) have achieved state-of-the-art synthesis results on diverse tasks. However, the current design space of the forward diffusion process is largely unexplored and often relies on physical intuition or simplifying assumptions. Leveraging results from the design of scalable Bayesian posterior samplers, we present a complete recipe for constructing forward processes in SGMs, all of which are guaranteed to converge to the target distribution of interest. We show that several existing SGMs can be cast as specific instantiations of this parameterization. Furthermore, building on this recipe, we construct a novel SGM: Phase Space Langevin Diffusion (PSLD), which performs score-based modeling in a space augmented with auxiliary variables akin to a physical phase space. We show that PSLD outperforms competing baselines in terms of sample quality and the speed-vs-quality tradeoff across different samplers on various standard image synthesis benchmarks. Moreover, we show that PSLD achieves sample quality comparable to state-of-the-art SGMs (FID: 2.10 on unconditional CIFAR-10 generation), providing an attractive alternative as an SGM backbone for further development. We will publish our code and model checkpoints for reproducibility at https://github.com/mandt-lab/PSLD.
Zero-Shot Anomaly Detection without Foundation Models
Feb 15, 2023



Anomaly detection (AD) tries to identify data instances that deviate from the norm in a given data set. Since data distributions are subject to distribution shifts, our concept of ``normality" may also drift, raising the need for zero-shot adaptation approaches for anomaly detection. However, the fact that current zero-shot AD methods rely on foundation models that are restricted in their domain (natural language and natural images), are costly, and oftentimes proprietary, asks for alternative approaches. In this paper, we propose a simple and highly effective zero-shot AD approach compatible with a variety of established AD methods. Our solution relies on training an off-the-shelf anomaly detector (such as a deep SVDD) on a set of inter-related data distributions in combination with batch normalization. This simple recipe--batch normalization plus meta-training--is a highly effective and versatile tool. Our results demonstrate the first zero-shot anomaly detection results for tabular data and SOTA zero-shot AD results for image data from specialized domains.
Deep Anomaly Detection under Labeling Budget Constraints
Feb 15, 2023



Selecting informative data points for expert feedback can significantly improve the performance of anomaly detection (AD) in various contexts, such as medical diagnostics or fraud detection. In this paper, we determine a set of theoretical conditions under which anomaly scores generalize from labeled queries to unlabeled data. Motivated by these results, we propose a data labeling strategy with optimal data coverage under labeling budget constraints. In addition, we propose a new learning framework for semi-supervised AD. Extensive experiments on image, tabular, and video data sets show that our approach results in state-of-the-art semi-supervised AD performance under labeling budget constraints.
Fully Bayesian Autoencoders with Latent Sparse Gaussian Processes
Feb 09, 2023



Autoencoders and their variants are among the most widely used models in representation learning and generative modeling. However, autoencoder-based models usually assume that the learned representations are i.i.d. and fail to capture the correlations between the data samples. To address this issue, we propose a novel Sparse Gaussian Process Bayesian Autoencoder (SGPBAE) model in which we impose fully Bayesian sparse Gaussian Process priors on the latent space of a Bayesian Autoencoder. We perform posterior estimation for this model via stochastic gradient Hamiltonian Monte Carlo. We evaluate our approach qualitatively and quantitatively on a wide range of representation learning and generative modeling tasks and show that our approach consistently outperforms multiple alternatives relying on Variational Autoencoders.
Probabilistic Querying of Continuous-Time Event Sequences
Nov 15, 2022



Continuous-time event sequences, i.e., sequences consisting of continuous time stamps and associated event types ("marks"), are an important type of sequential data with many applications, e.g., in clinical medicine or user behavior modeling. Since these data are typically modeled autoregressively (e.g., using neural Hawkes processes or their classical counterparts), it is natural to ask questions about future scenarios such as "what kind of event will occur next" or "will an event of type $A$ occur before one of type $B$". Unfortunately, some of these queries are notoriously hard to address since current methods are limited to naive simulation, which can be highly inefficient. This paper introduces a new typology of query types and a framework for addressing them using importance sampling. Example queries include predicting the $n^\text{th}$ event type in a sequence and the hitting time distribution of one or more event types. We also leverage these findings further to be applicable for estimating general "$A$ before $B$" type of queries. We prove theoretically that our estimation method is effectively always better than naive simulation and show empirically based on three real-world datasets that it is on average 1,000 times more efficient than existing approaches.
Predictive Querying for Autoregressive Neural Sequence Models
Oct 13, 2022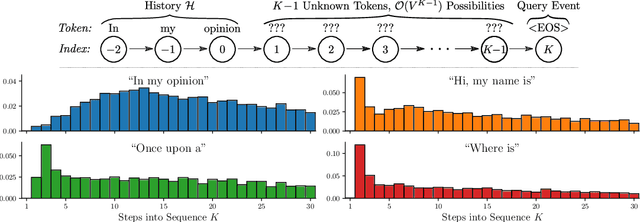

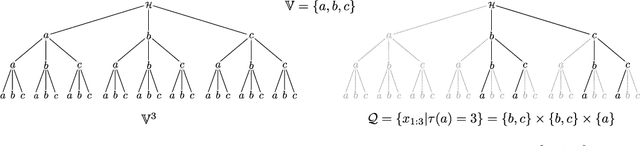
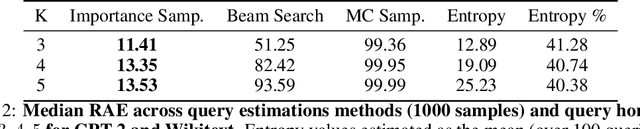
In reasoning about sequential events it is natural to pose probabilistic queries such as "when will event A occur next" or "what is the probability of A occurring before B", with applications in areas such as user modeling, medicine, and finance. However, with machine learning shifting towards neural autoregressive models such as RNNs and transformers, probabilistic querying has been largely restricted to simple cases such as next-event prediction. This is in part due to the fact that future querying involves marginalization over large path spaces, which is not straightforward to do efficiently in such models. In this paper we introduce a general typology for predictive queries in neural autoregressive sequence models and show that such queries can be systematically represented by sets of elementary building blocks. We leverage this typology to develop new query estimation methods based on beam search, importance sampling, and hybrids. Across four large-scale sequence datasets from different application domains, as well as for the GPT-2 language model, we demonstrate the ability to make query answering tractable for arbitrary queries in exponentially-large predictive path-spaces, and find clear differences in cost-accuracy tradeoffs between search and sampling methods.
Lossy Image Compression with Conditional Diffusion Models
Sep 14, 2022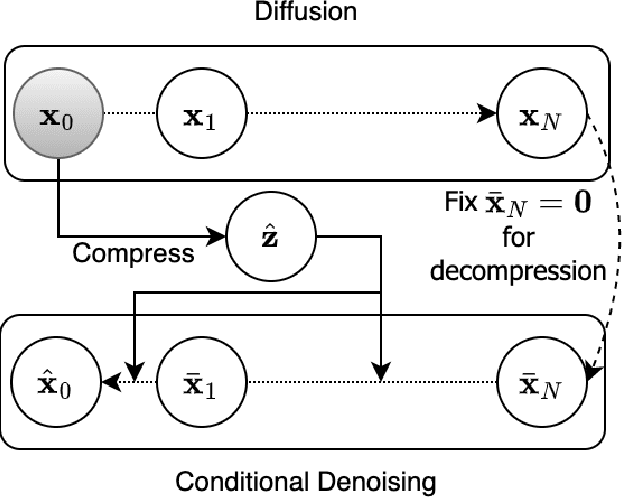

Diffusion models are a new class of generative models that mark a milestone in high-quality image generation while relying on solid probabilistic principles. This makes them promising candidate models for neural image compression. This paper outlines an end-to-end optimized framework based on a conditional diffusion model for image compression. Besides latent variables inherent to the diffusion process, the model introduces an additional per-instance "content" latent variable to condition the denoising process. Upon decoding, the diffusion process conditionally generates/reconstructs an image using ancestral sampling. Our experiments show that this approach outperforms one of the best-performing conventional image codecs (BPG) and one neural codec on two compression benchmarks, where we focus on rate-perception tradeoffs. Qualitatively, our approach shows fewer decompression artifacts than the classical approach.
Raising the Bar in Graph-level Anomaly Detection
May 27, 2022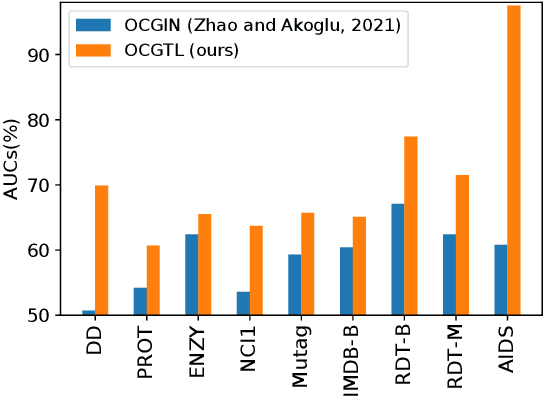
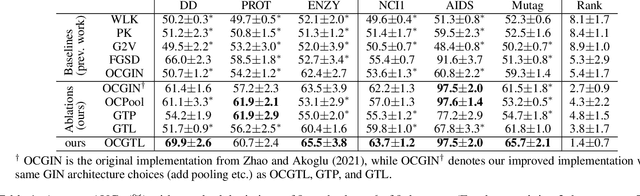
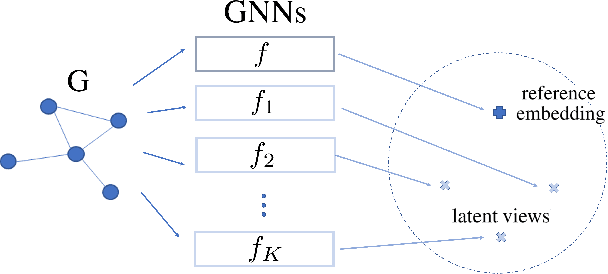

Graph-level anomaly detection has become a critical topic in diverse areas, such as financial fraud detection and detecting anomalous activities in social networks. While most research has focused on anomaly detection for visual data such as images, where high detection accuracies have been obtained, existing deep learning approaches for graphs currently show considerably worse performance. This paper raises the bar on graph-level anomaly detection, i.e., the task of detecting abnormal graphs in a set of graphs. By drawing on ideas from self-supervised learning and transformation learning, we present a new deep learning approach that significantly improves existing deep one-class approaches by fixing some of their known problems, including hypersphere collapse and performance flip. Experiments on nine real-world data sets involving nine techniques reveal that our method achieves an average performance improvement of 11.8% AUC compared to the best existing approach.
Diffusion Probabilistic Modeling for Video Generation
Mar 31, 2022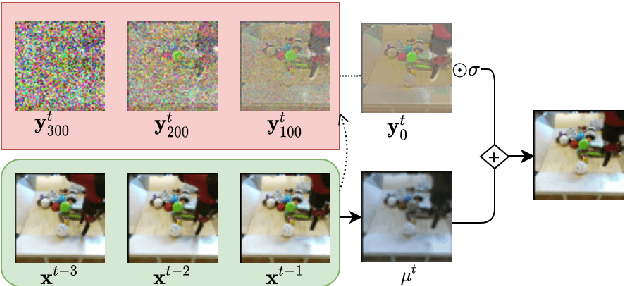
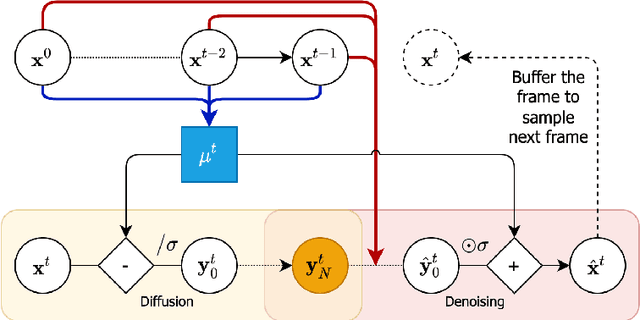

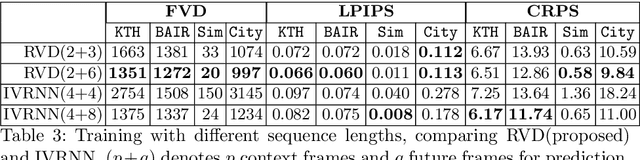
Denoising diffusion probabilistic models are a promising new class of generative models that are competitive with GANs on perceptual metrics. In this paper, we explore their potential for sequentially generating video. Inspired by recent advances in neural video compression, we use denoising diffusion models to stochastically generate a residual to a deterministic next-frame prediction. We compare this approach to two sequential VAE and two GAN baselines on four datasets, where we test the generated frames for perceptual quality and forecasting accuracy against ground truth frames. We find significant improvements in terms of perceptual quality on all data and improvements in terms of frame forecasting for complex high-resolution videos.
SC2: Supervised Compression for Split Computing
Mar 16, 2022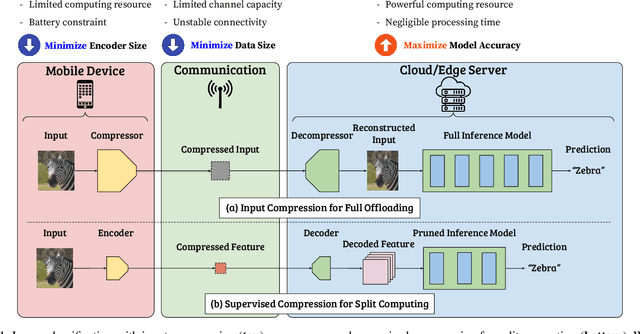
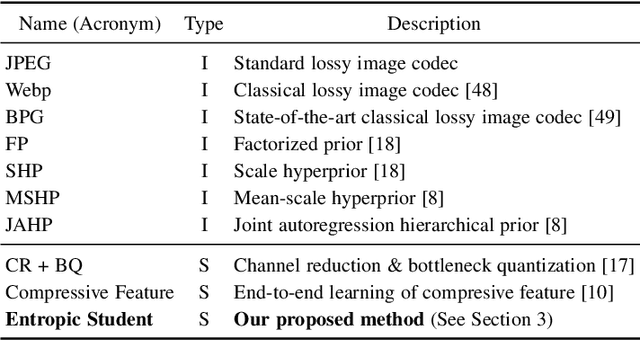
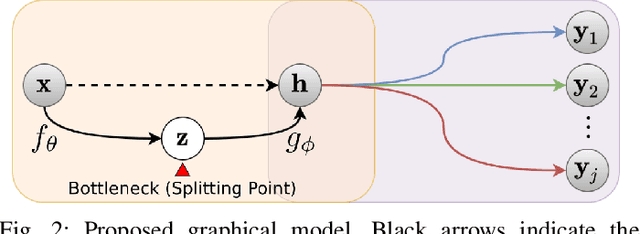
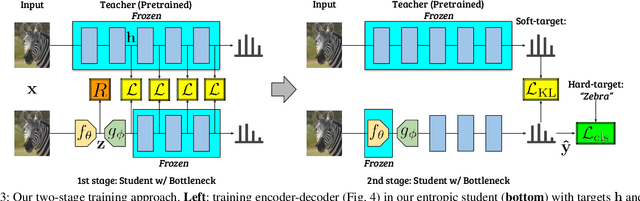
Split computing distributes the execution of a neural network (e.g., for a classification task) between a mobile device and a more powerful edge server. A simple alternative to splitting the network is to carry out the supervised task purely on the edge server while compressing and transmitting the full data, and most approaches have barely outperformed this baseline. This paper proposes a new approach for discretizing and entropy-coding intermediate feature activations to efficiently transmit them from the mobile device to the edge server. We show that a efficient splittable network architecture results from a three-way tradeoff between (a) minimizing the computation on the mobile device, (b) minimizing the size of the data to be transmitted, and (c) maximizing the model's prediction performance. We propose an architecture based on this tradeoff and train the splittable network and entropy model in a knowledge distillation framework. In an extensive set of experiments involving three vision tasks, three datasets, nine baselines, and more than 180 trained models, we show that our approach improves supervised rate-distortion tradeoffs while maintaining a considerably smaller encoder size. We also release sc2bench, an installable Python package, to encourage and facilitate future studies on supervised compression for split computing (SC2).