 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Heterogeneous Transfer Learning from Recommender Systems to Cold-Start Search Retrieval
Aug 19, 2020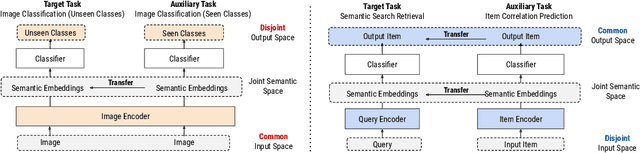

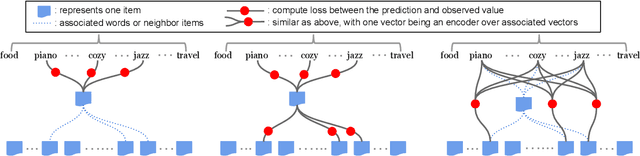
Many recent advances in neural information retrieval models, which predict top-K items given a query, learn directly from a large training set of (query, item) pairs. However, they are often insufficient when there are many previously unseen (query, item) combinations, often referred to as the cold start problem. Furthermore, the search system can be biased towards items that are frequently shown to a query previously, also known as the 'rich get richer' (a.k.a. feedback loop) problem. In light of these problems, we observed that most online content platforms have both a search and a recommender system that, while having heterogeneous input spaces, can be connected through their common output item space and a shared semantic representation. In this paper, we propose a new Zero-Shot Heterogeneous Transfer Learning framework that transfers learned knowledge from the recommender system component to improve the search component of a content platform. First, it learns representations of items and their natural-language features by predicting (item, item) correlation graphs derived from the recommender system as an auxiliary task. Then, the learned representations are transferred to solve the target search retrieval task, performing query-to-item prediction without having seen any (query, item) pairs in training. We conduct online and offline experiments on one of the world's largest search and recommender systems from Google, and present the results and lessons learned. We demonstrate that the proposed approach can achieve high performance on offline search retrieval tasks, and more importantly, achieved significant improvements on relevance and user interactions over the highly-optimized production system in online experiments.
Neural Collaborative Filtering vs. Matrix Factorization Revisited
Jun 01, 2020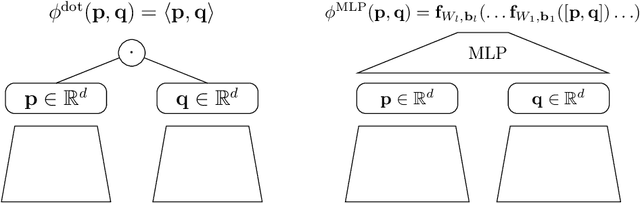
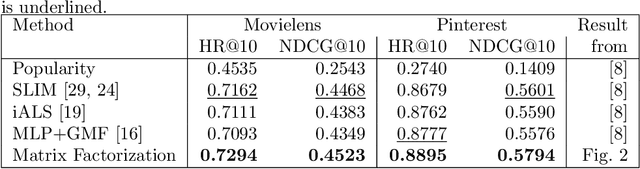
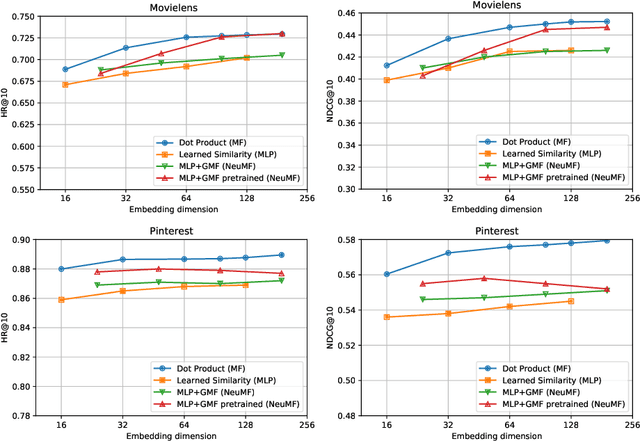
Embedding based models have been the state of the art in collaborative filtering for over a decade. Traditionally, the dot product or higher order equivalents have been used to combine two or more embeddings, e.g., most notably in matrix factorization. In recent years, it was suggested to replace the dot product with a learned similarity e.g. using a multilayer perceptron (MLP). This approach is often referred to as neural collaborative filtering (NCF). In this work, we revisit the experiments of the NCF paper that popularized learned similarities using MLPs. First, we show that with a proper hyperparameter selection, a simple dot product substantially outperforms the proposed learned similarities. Second, while a MLP can in theory approximate any function, we show that it is non-trivial to learn a dot product with an MLP. Finally, we discuss practical issues that arise when applying MLP based similarities and show that MLPs are too costly to use for item recommendation in production environments while dot products allow to apply very efficient retrieval algorithms. We conclude that MLPs should be used with care as embedding combiner and that dot products might be a better default choice.
Superbloom: Bloom filter meets Transformer
Feb 11, 2020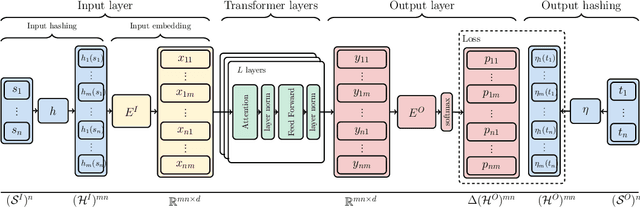

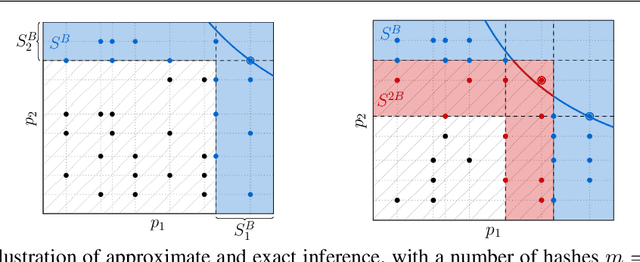
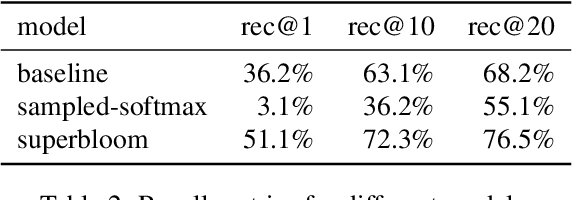
We extend the idea of word pieces in natural language models to machine learning tasks on opaque ids. This is achieved by applying hash functions to map each id to multiple hash tokens in a much smaller space, similarly to a Bloom filter. We show that by applying a multi-layer Transformer to these Bloom filter digests, we are able to obtain models with high accuracy. They outperform models of a similar size without hashing and, to a large degree, models of a much larger size trained using sampled softmax with the same computational budget. Our key observation is that it is important to use a multi-layer Transformer for Bloom filter digests to remove ambiguity in the hashed input. We believe this provides an alternative method to solving problems with large vocabulary size.
Evaluation Metrics for Item Recommendation under Sampling
Dec 04, 2019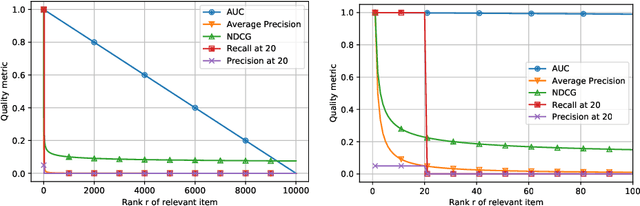
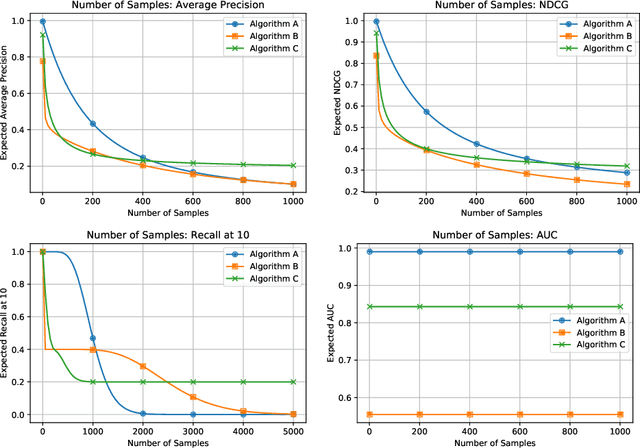
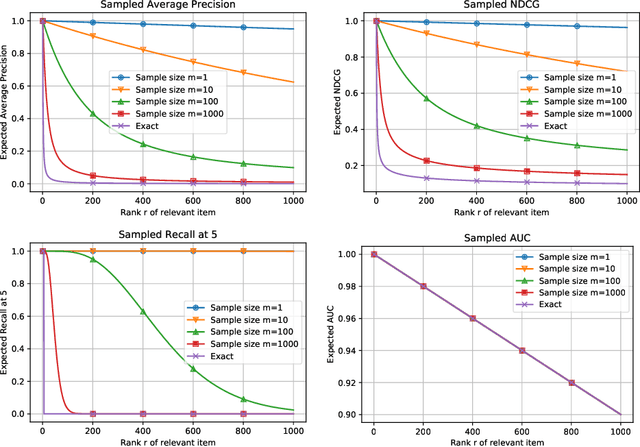
The task of item recommendation requires ranking a large catalogue of items given a context. Item recommendation algorithms are evaluated using ranking metrics that depend on the positions of relevant items. To speed up the computation of metrics, recent work often uses sampled metrics where only a smaller set of random items and the relevant items are ranked. This paper investigates sampled metrics in more detail and shows that sampled metrics are inconsistent with their exact version. Sampled metrics do not persist relative statements, e.g., 'algorithm A is better than B', not even in expectation. Moreover the smaller the sampling size, the less difference between metrics, and for very small sampling size, all metrics collapse to the AUC metric.
On the Difficulty of Evaluating Baselines: A Study on Recommender Systems
May 04, 2019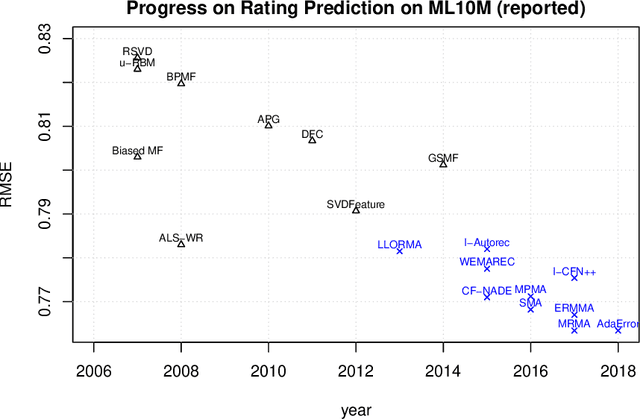
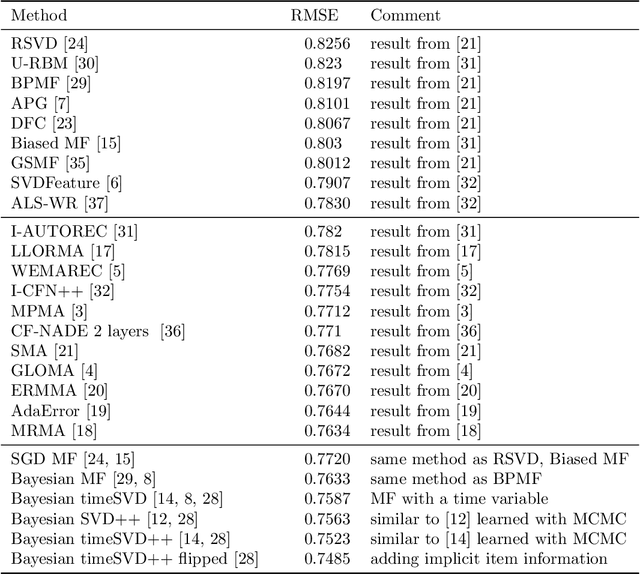
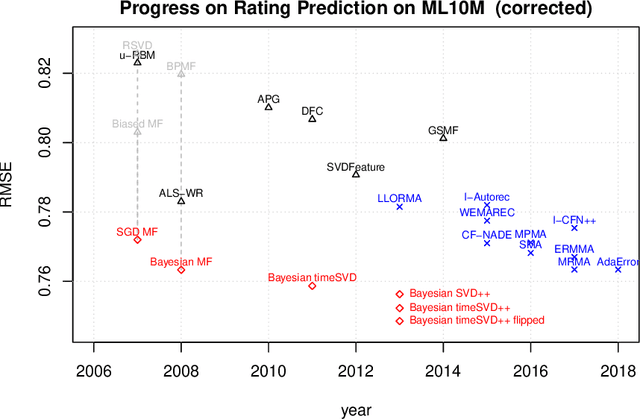
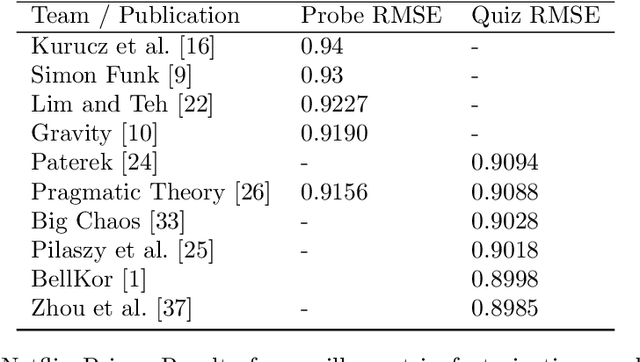
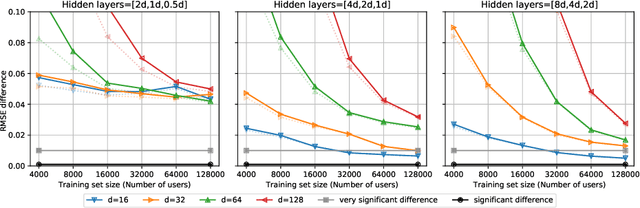
Numerical evaluations with comparisons to baselines play a central role when judging research in recommender systems. In this paper, we show that running baselines properly is difficult. We demonstrate this issue on two extensively studied datasets. First, we show that results for baselines that have been used in numerous publications over the past five years for the Movielens 10M benchmark are suboptimal. With a careful setup of a vanilla matrix factorization baseline, we are not only able to improve upon the reported results for this baseline but even outperform the reported results of any newly proposed method. Secondly, we recap the tremendous effort that was required by the community to obtain high quality results for simple methods on the Netflix Prize. Our results indicate that empirical findings in research papers are questionable unless they were obtained on standardized benchmarks where baselines have been tuned extensively by the research community.
Adaptive Sampled Softmax with Kernel Based Sampling
Aug 01, 2018

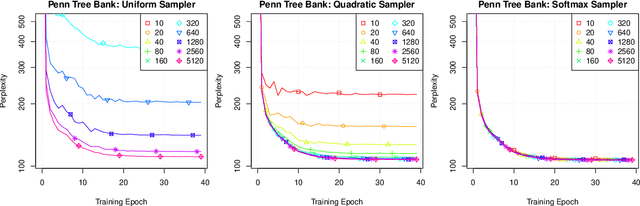
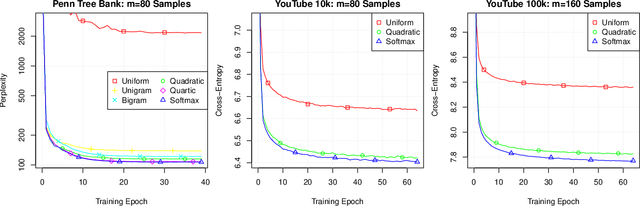
Softmax is the most commonly used output function for multiclass problems and is widely used in areas such as vision, natural language processing, and recommendation. A softmax model has linear costs in the number of classes which makes it too expensive for many real-world problems. A common approach to speed up training involves sampling only some of the classes at each training step. It is known that this method is biased and that the bias increases the more the sampling distribution deviates from the output distribution. Nevertheless, almost any recent work uses simple sampling distributions that require a large sample size to mitigate the bias. In this work, we propose a new class of kernel based sampling methods and develop an efficient sampling algorithm. Kernel based sampling adapts to the model as it is trained, thus resulting in low bias. Kernel based sampling can be easily applied to many models because it relies only on the model's last hidden layer. We empirically study the trade-off of bias, sampling distribution and sample size and show that kernel based sampling results in low bias with few samples.
Efficient Training on Very Large Corpora via Gramian Estimation
Jul 18, 2018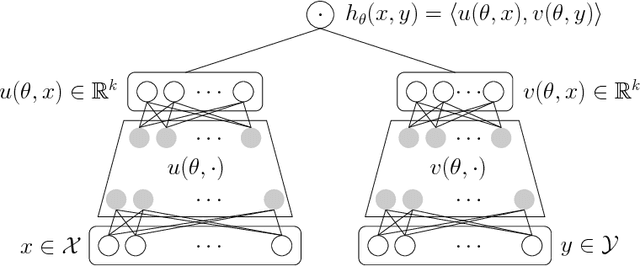

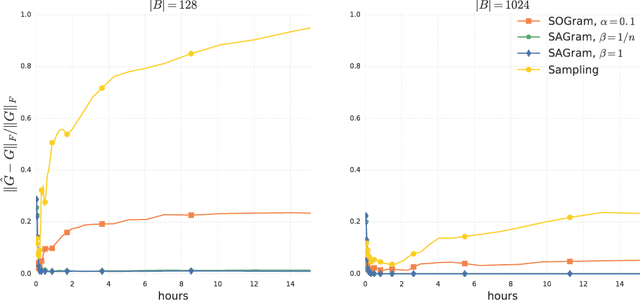

We study the problem of learning similarity functions over very large corpora using neural network embedding models. These models are typically trained using SGD with sampling of random observed and unobserved pairs, with a number of samples that grows quadratically with the corpus size, making it expensive to scale to very large corpora. We propose new efficient methods to train these models without having to sample unobserved pairs. Inspired by matrix factorization, our approach relies on adding a global quadratic penalty to all pairs of examples and expressing this term as the matrix-inner-product of two generalized Gramians. We show that the gradient of this term can be efficiently computed by maintaining estimates of the Gramians, and develop variance reduction schemes to improve the quality of the estimates. We conduct large-scale experiments that show a significant improvement in training time and generalization quality compared to traditional sampling methods.
Graph Based Relational Features for Collective Classification
Feb 09, 2017
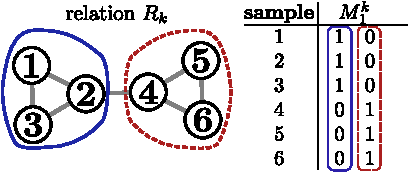
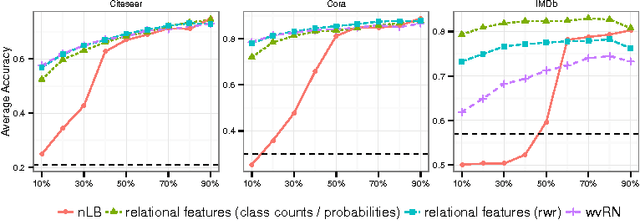
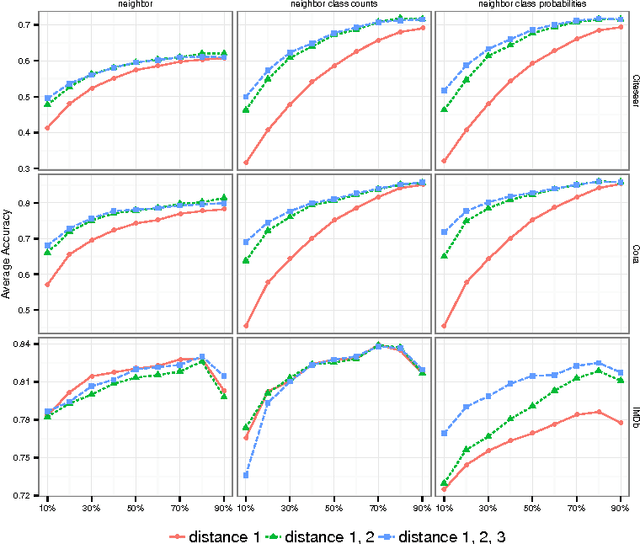
Statistical Relational Learning (SRL) methods have shown that classification accuracy can be improved by integrating relations between samples. Techniques such as iterative classification or relaxation labeling achieve this by propagating information between related samples during the inference process. When only a few samples are labeled and connections between samples are sparse, collective inference methods have shown large improvements over standard feature-based ML methods. However, in contrast to feature based ML, collective inference methods require complex inference procedures and often depend on the strong assumption of label consistency among related samples. In this paper, we introduce new relational features for standard ML methods by extracting information from direct and indirect relations. We show empirically on three standard benchmark datasets that our relational features yield results comparable to collective inference methods. Finally we show that our proposal outperforms these methods when additional information is available.
A Generic Coordinate Descent Framework for Learning from Implicit Feedback
Nov 15, 2016
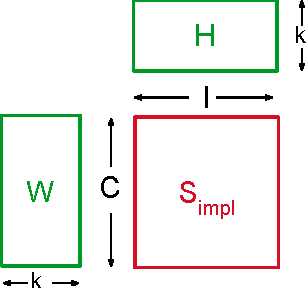
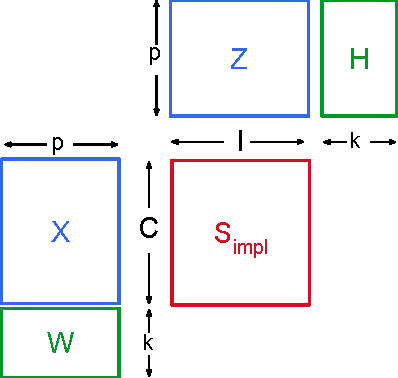
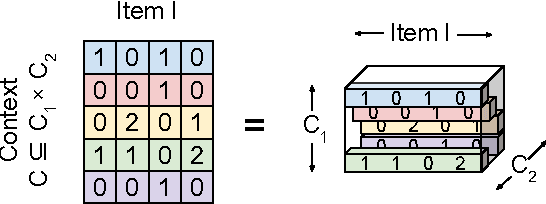
In recent years, interest in recommender research has shifted from explicit feedback towards implicit feedback data. A diversity of complex models has been proposed for a wide variety of applications. Despite this, learning from implicit feedback is still computationally challenging. So far, most work relies on stochastic gradient descent (SGD) solvers which are easy to derive, but in practice challenging to apply, especially for tasks with many items. For the simple matrix factorization model, an efficient coordinate descent (CD) solver has been previously proposed. However, efficient CD approaches have not been derived for more complex models. In this paper, we provide a new framework for deriving efficient CD algorithms for complex recommender models. We identify and introduce the property of k-separable models. We show that k-separability is a sufficient property to allow efficient optimization of implicit recommender problems with CD. We illustrate this framework on a variety of state-of-the-art models including factorization machines and Tucker decomposition. To summarize, our work provides the theory and building blocks to derive efficient implicit CD algorithms for complex recommender models.
BPR: Bayesian Personalized Ranking from Implicit Feedback
May 09, 2012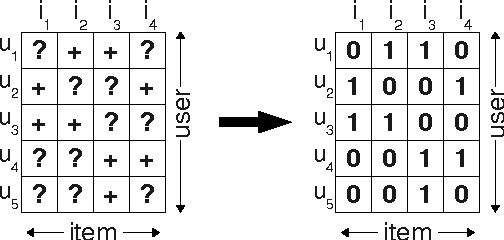
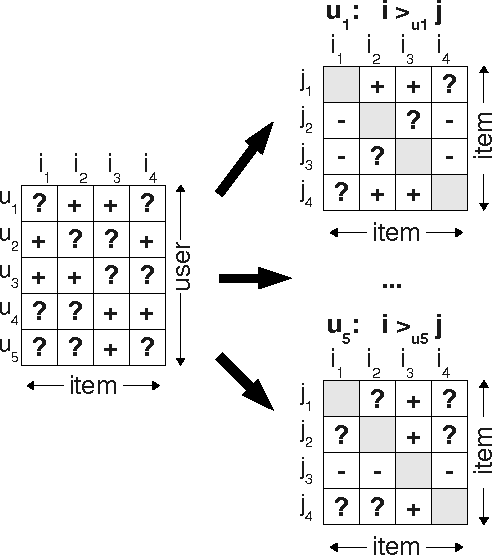
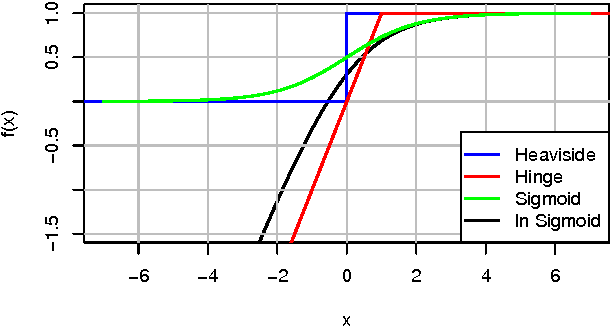
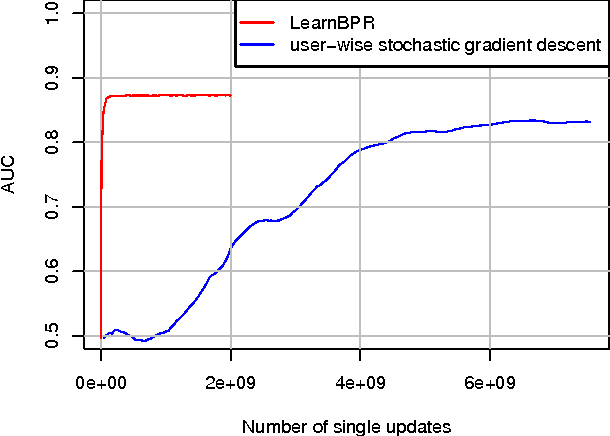
Item recommendation is the task of predicting a personalized ranking on a set of items (e.g. websites, movies, products). In this paper, we investigate the most common scenario with implicit feedback (e.g. clicks, purchases). There are many methods for item recommendation from implicit feedback like matrix factorization (MF) or adaptive knearest-neighbor (kNN). Even though these methods are designed for the item prediction task of personalized ranking, none of them is directly optimized for ranking. In this paper we present a generic optimization criterion BPR-Opt for personalized ranking that is the maximum posterior estimator derived from a Bayesian analysis of the problem. We also provide a generic learning algorithm for optimizing models with respect to BPR-Opt. The learning method is based on stochastic gradient descent with bootstrap sampling. We show how to apply our method to two state-of-the-art recommender models: matrix factorization and adaptive kNN. Our experiments indicate that for the task of personalized ranking our optimization method outperforms the standard learning techniques for MF and kNN. The results show the importance of optimizing models for the right criterion.