 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Multi-task Learning with Cyclical Self-Regulation for Face Parsing
Mar 28, 2022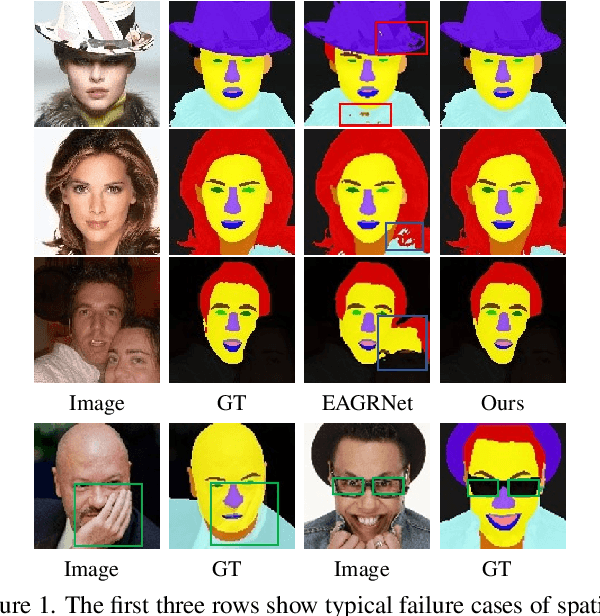
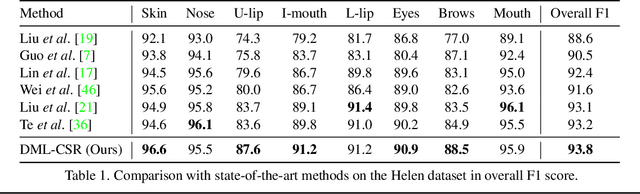
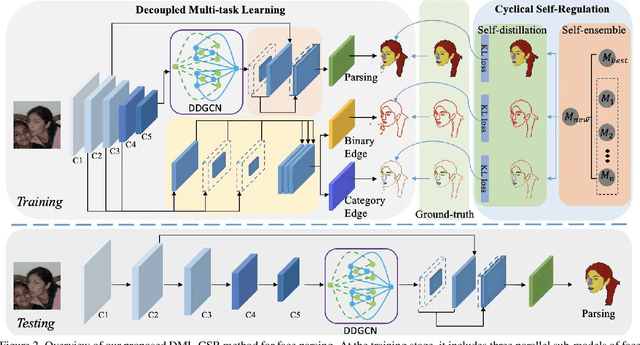
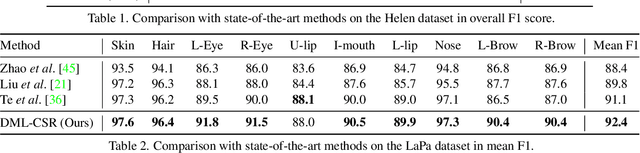
This paper probes intrinsic factors behind typical failure cases (e.g. spatial inconsistency and boundary confusion) produced by the existing state-of-the-art method in face parsing. To tackle these problems, we propose a novel Decoupled Multi-task Learning with Cyclical Self-Regulation (DML-CSR) for face parsing. Specifically, DML-CSR designs a multi-task model which comprises face parsing, binary edge, and category edge detection. These tasks only share low-level encoder weights without high-level interactions between each other, enabling to decouple auxiliary modules from the whole network at the inference stage. To address spatial inconsistency, we develop a dynamic dual graph convolutional network to capture global contextual information without using any extra pooling operation. To handle boundary confusion in both single and multiple face scenarios, we exploit binary and category edge detection to jointly obtain generic geometric structure and fine-grained semantic clues of human faces. Besides, to prevent noisy labels from degrading model generalization during training, cyclical self-regulation is proposed to self-ensemble several model instances to get a new model and the resulting model then is used to self-distill subsequent models, through alternating iterations. Experiments show that our method achieves the new state-of-the-art performance on the Helen, CelebAMask-HQ, and Lapa datasets. The source code is available at https://github.com/deepinsight/insightface/tree/master/parsing/dml_csr.
Facial Geometric Detail Recovery via Implicit Representation
Mar 18, 2022
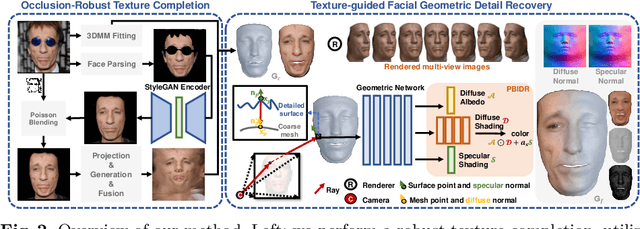


Learning a dense 3D model with fine-scale details from a single facial image is highly challenging and ill-posed. To address this problem, many approaches fit smooth geometries through facial prior while learning details as additional displacement maps or personalized basis. However, these techniques typically require vast datasets of paired multi-view data or 3D scans, whereas such datasets are scarce and expensive. To alleviate heavy data dependency, we present a robust texture-guided geometric detail recovery approach using only a single in-the-wild facial image. More specifically, our method combines high-quality texture completion with the powerful expressiveness of implicit surfaces. Initially, we inpaint occluded facial parts, generate complete textures, and build an accurate multi-view dataset of the same subject. In order to estimate the detailed geometry, we define an implicit signed distance function and employ a physically-based implicit renderer to reconstruct fine geometric details from the generated multi-view images. Our method not only recovers accurate facial details but also decomposes normals, albedos, and shading parts in a self-supervised way. Finally, we register the implicit shape details to a 3D Morphable Model template, which can be used in traditional modeling and rendering pipelines. Extensive experiments demonstrate that the proposed approach can reconstruct impressive facial details from a single image, especially when compared with state-of-the-art methods trained on large datasets.
Embedding Earth: Self-supervised contrastive pre-training for dense land cover classification
Mar 11, 2022
In training machine learning models for land cover semantic segmentation there is a stark contrast between the availability of satellite imagery to be used as inputs and ground truth data to enable supervised learning. While thousands of new satellite images become freely available on a daily basis, getting ground truth data is still very challenging, time consuming and costly. In this paper we present Embedding Earth a self-supervised contrastive pre-training method for leveraging the large availability of satellite imagery to improve performance on downstream dense land cover classification tasks. Performing an extensive experimental evaluation spanning four countries and two continents we use models pre-trained with our proposed method as initialization points for supervised land cover semantic segmentation and observe significant improvements up to 25% absolute mIoU. In every case tested we outperform random initialization, especially so when ground truth data are scarse. Through a series of ablation studies we explore the qualities of the proposed approach and find that learnt features can generalize between disparate regions opening up the possibility of using the proposed pre-training scheme as a replacement to random initialization for Earth observation tasks. Code will be uploaded soon at https://github.com/michaeltrs/DeepSatModels.
2021 BEETL Competition: Advancing Transfer Learning for Subject Independence & Heterogenous EEG Data Sets
Feb 14, 2022
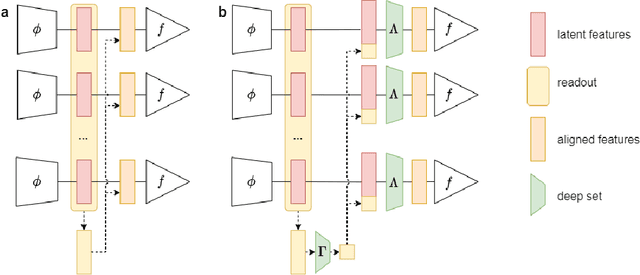
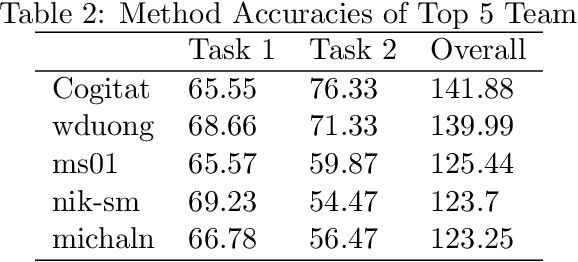
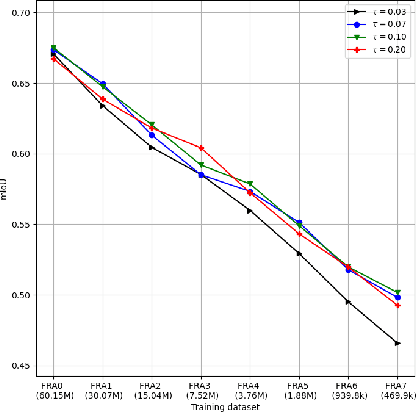
Transfer learning and meta-learning offer some of the most promising avenues to unlock the scalability of healthcare and consumer technologies driven by biosignal data. This is because current methods cannot generalise well across human subjects' data and handle learning from different heterogeneously collected data sets, thus limiting the scale of training data. On the other side, developments in transfer learning would benefit significantly from a real-world benchmark with immediate practical application. Therefore, we pick electroencephalography (EEG) as an exemplar for what makes biosignal machine learning hard. We design two transfer learning challenges around diagnostics and Brain-Computer-Interfacing (BCI), that have to be solved in the face of low signal-to-noise ratios, major variability among subjects, differences in the data recording sessions and techniques, and even between the specific BCI tasks recorded in the dataset. Task 1 is centred on the field of medical diagnostics, addressing automatic sleep stage annotation across subjects. Task 2 is centred on Brain-Computer Interfacing (BCI), addressing motor imagery decoding across both subjects and data sets. The BEETL competition with its over 30 competing teams and its 3 winning entries brought attention to the potential of deep transfer learning and combinations of set theory and conventional machine learning techniques to overcome the challenges. The results set a new state-of-the-art for the real-world BEETL benchmark.
Team Cogitat at NeurIPS 2021: Benchmarks for EEG Transfer Learning Competition
Feb 01, 2022

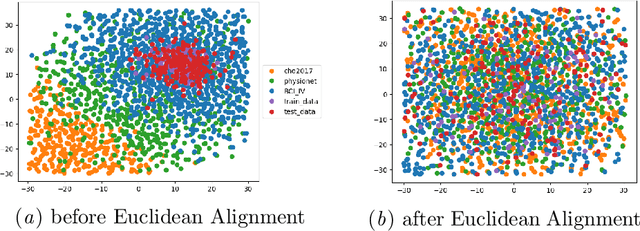
Building subject-independent deep learning models for EEG decoding faces the challenge of strong covariate-shift across different datasets, subjects and recording sessions. Our approach to address this difficulty is to explicitly align feature distributions at various layers of the deep learning model, using both simple statistical techniques as well as trainable methods with more representational capacity. This follows in a similar vein as covariance-based alignment methods, often used in a Riemannian manifold context. The methodology proposed herein won first place in the 2021 Benchmarks in EEG Transfer Learning (BEETL) competition, hosted at the NeurIPS conference. The first task of the competition consisted of sleep stage classification, which required the transfer of models trained on younger subjects to perform inference on multiple subjects of older age groups without personalized calibration data, requiring subject-independent models. The second task required to transfer models trained on the subjects of one or more source motor imagery datasets to perform inference on two target datasets, providing a small set of personalized calibration data for multiple test subjects.
AvatarMe++: Facial Shape and BRDF Inference with Photorealistic Rendering-Aware GANs
Dec 11, 2021
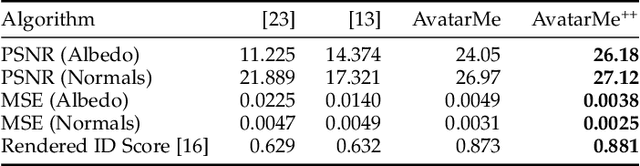


Over the last years, many face analysis tasks have accomplished astounding performance, with applications including face generation and 3D face reconstruction from a single "in-the-wild" image. Nevertheless, to the best of our knowledge, there is no method which can produce render-ready high-resolution 3D faces from "in-the-wild" images and this can be attributed to the: (a) scarcity of available data for training, and (b) lack of robust methodologies that can successfully be applied on very high-resolution data. In this work, we introduce the first method that is able to reconstruct photorealistic render-ready 3D facial geometry and BRDF from a single "in-the-wild" image. We capture a large dataset of facial shape and reflectance, which we have made public. We define a fast facial photorealistic differentiable rendering methodology with accurate facial skin diffuse and specular reflection, self-occlusion and subsurface scattering approximation. With this, we train a network that disentangles the facial diffuse and specular BRDF components from a shape and texture with baked illumination, reconstructed with a state-of-the-art 3DMM fitting method. Our method outperforms the existing arts by a significant margin and reconstructs high-resolution 3D faces from a single low-resolution image, that can be rendered in various applications, and bridge the uncanny valley.
EEGminer: Discovering Interpretable Features of Brain Activity with Learnable Filters
Oct 19, 2021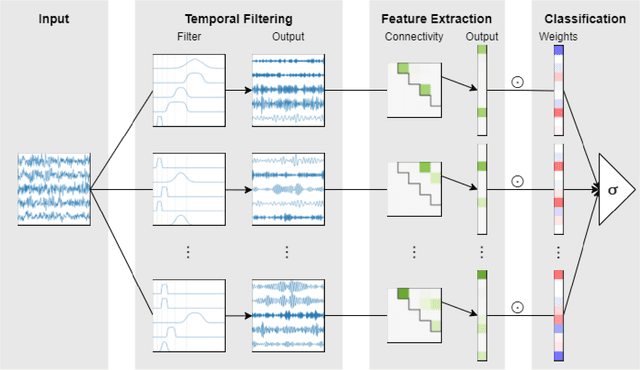
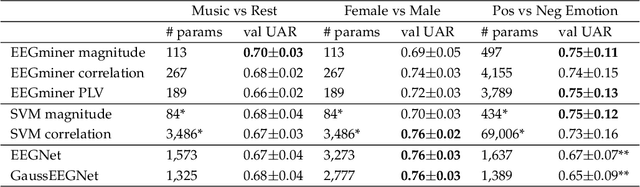

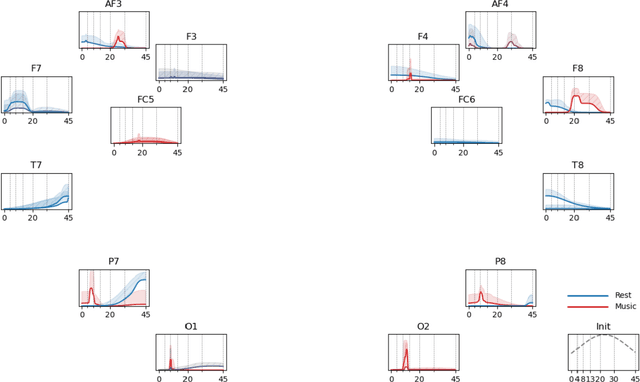
Patterns of brain activity are associated with different brain processes and can be used to identify different brain states and make behavioral predictions. However, the relevant features are not readily apparent and accessible. To mine informative latent representations from multichannel EEG recordings, we propose a novel differentiable EEG decoding pipeline consisting of learnable filters and a pre-determined feature extraction module. Specifically, we introduce filters parameterized by generalized Gaussian functions that offer a smooth derivative for stable end-to-end model training and allow for learning interpretable features. For the feature module, we use signal magnitude and functional connectivity. We demonstrate the utility of our model towards emotion recognition from EEG signals on the SEED dataset, as well as on a new EEG dataset of unprecedented size (i.e., 763 subjects), where we identify consistent trends of music perception and related individual differences. The discovered features align with previous neuroscience studies and offer new insights, such as marked differences in the functional connectivity profile between left and right temporal areas during music listening. This agrees with the respective specialisation of the temporal lobes regarding music perception proposed in the literature.
EDFace-Celeb-1M: Benchmarking Face Hallucination with a Million-scale Dataset
Oct 11, 2021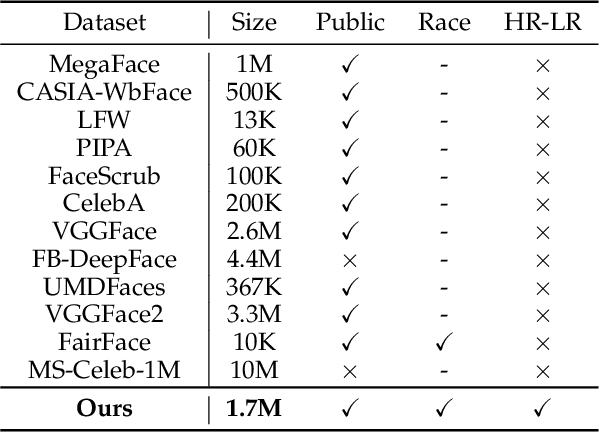

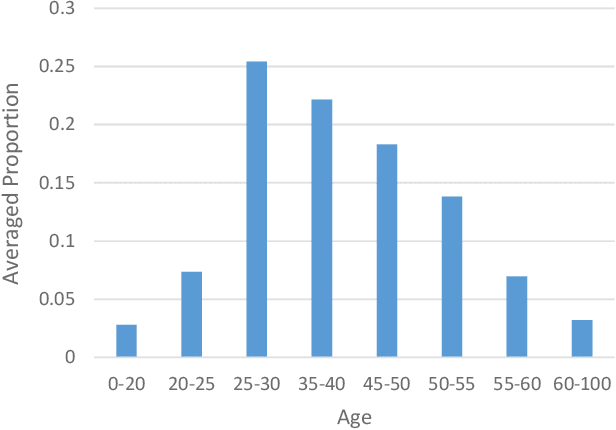

Recent deep face hallucination methods show stunning performance in super-resolving severely degraded facial images, even surpassing human ability. However, these algorithms are mainly evaluated on non-public synthetic datasets. It is thus unclear how these algorithms perform on public face hallucination datasets. Meanwhile, most of the existing datasets do not well consider the distribution of races, which makes face hallucination methods trained on these datasets biased toward some specific races. To address the above two problems, in this paper, we build a public Ethnically Diverse Face dataset, EDFace-Celeb-1M, and design a benchmark task for face hallucination. Our dataset includes 1.7 million photos that cover different countries, with balanced race composition. To the best of our knowledge, it is the largest and publicly available face hallucination dataset in the wild. Associated with this dataset, this paper also contributes various evaluation protocols and provides comprehensive analysis to benchmark the existing state-of-the-art methods. The benchmark evaluations demonstrate the performance and limitations of state-of-the-art algorithms.
Revisiting Point Cloud Simplification: A Learnable Feature Preserving Approach
Sep 30, 2021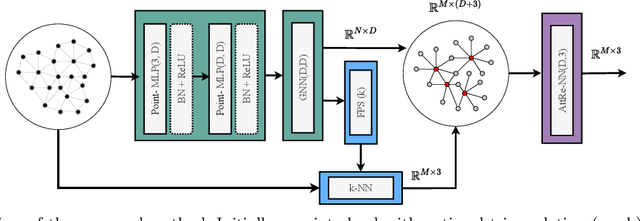
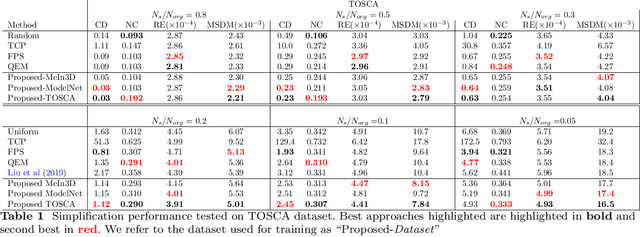

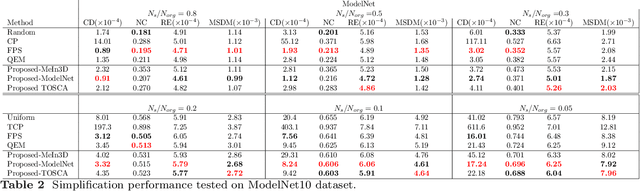
The recent advances in 3D sensing technology have made possible the capture of point clouds in significantly high resolution. However, increased detail usually comes at the expense of high storage, as well as computational costs in terms of processing and visualization operations. Mesh and Point Cloud simplification methods aim to reduce the complexity of 3D models while retaining visual quality and relevant salient features. Traditional simplification techniques usually rely on solving a time-consuming optimization problem, hence they are impractical for large-scale datasets. In an attempt to alleviate this computational burden, we propose a fast point cloud simplification method by learning to sample salient points. The proposed method relies on a graph neural network architecture trained to select an arbitrary, user-defined, number of points from the input space and to re-arrange their positions so as to minimize the visual perception error. The approach is extensively evaluated on various datasets using several perceptual metrics. Importantly, our method is able to generalize to out-of-distribution shapes, hence demonstrating zero-shot capabilities.
Masked Face Recognition Challenge: The InsightFace Track Report
Aug 18, 2021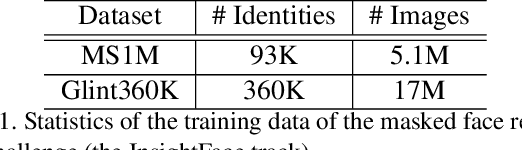

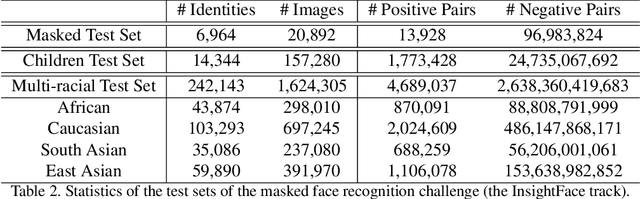
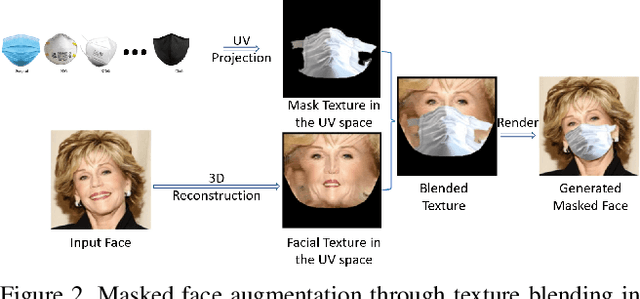
During the COVID-19 coronavirus epidemic, almost everyone wears a facial mask, which poses a huge challenge to deep face recognition. In this workshop, we organize Masked Face Recognition (MFR) challenge and focus on bench-marking deep face recognition methods under the existence of facial masks. In the MFR challenge, there are two main tracks: the InsightFace track and the WebFace260M track. For the InsightFace track, we manually collect a large-scale masked face test set with 7K identities. In addition, we also collect a children test set including 14K identities and a multi-racial test set containing 242K identities. By using these three test sets, we build up an online model testing system, which can give a comprehensive evaluation of face recognition models. To avoid data privacy problems, no test image is released to the public. As the challenge is still under-going, we will keep on updating the top-ranked solutions as well as this report on the arxiv.