 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStacked Dense U-Nets with Dual Transformers for Robust Face Alignment
Dec 05, 2018
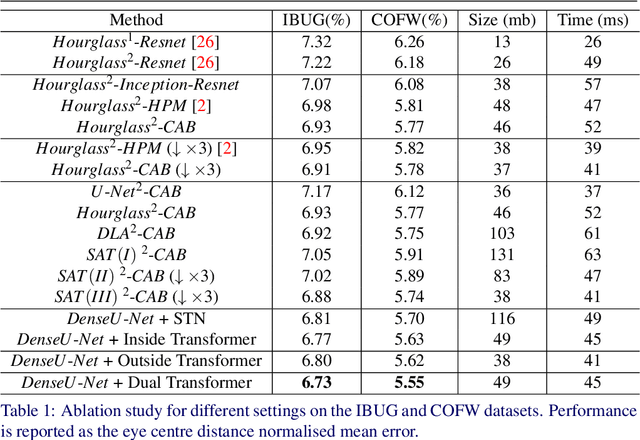
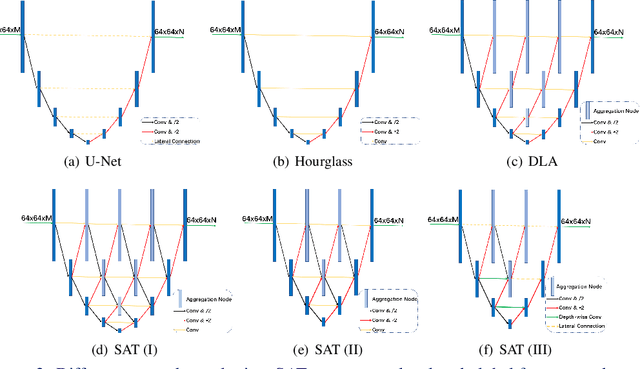

Facial landmark localisation in images captured in-the-wild is an important and challenging problem. The current state-of-the-art revolves around certain kinds of Deep Convolutional Neural Networks (DCNNs) such as stacked U-Nets and Hourglass networks. In this work, we innovatively propose stacked dense U-Nets for this task. We design a novel scale aggregation network topology structure and a channel aggregation building block to improve the model's capacity without sacrificing the computational complexity and model size. With the assistance of deformable convolutions inside the stacked dense U-Nets and coherent loss for outside data transformation, our model obtains the ability to be spatially invariant to arbitrary input face images. Extensive experiments on many in-the-wild datasets, validate the robustness of the proposed method under extreme poses, exaggerated expressions and heavy occlusions. Finally, we show that accurate 3D face alignment can assist pose-invariant face recognition where we achieve a new state-of-the-art accuracy on CFP-FP.
Generating faces for affect analysis
Nov 12, 2018
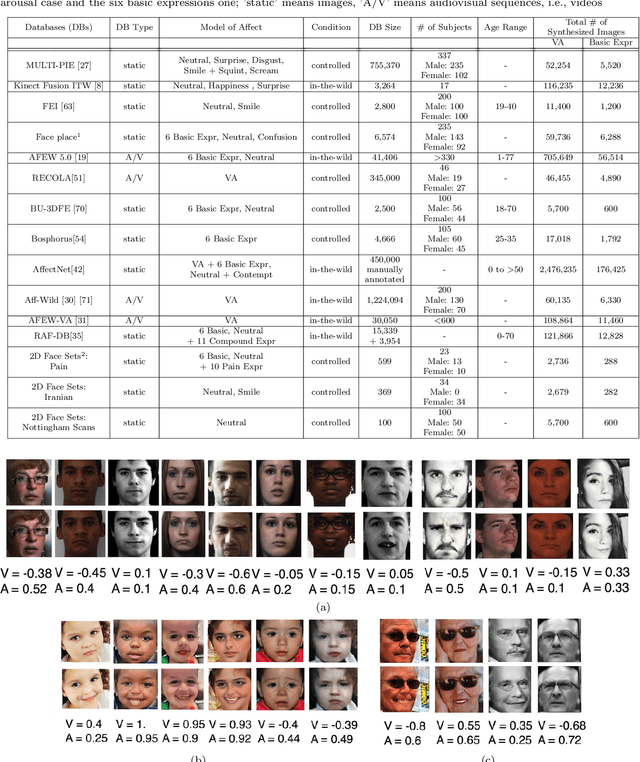

This paper presents a novel approach for synthesizing facial affect; either categorical, in terms of the six basic expressions (i.e., anger, disgust, fear, happiness, sadness and surprise), or dimensional, in terms of valence (i.e., how positive or negative is an emotion) and arousal (i.e., power of the emotion activation). In the Valence-Arousal case, a system is created, based on VA annotation of 600,000 frames from the 4DFAB database; in the categorical case, the system is based on the selection of apex frames of posed expression sequences from the 4DFAB. The proposed system accepts at its input: i) either the basic facial expression, or the pair of valence-arousal emotional state descriptors, which need to be synthesized and ii) a neutral 2D image of a person on which the corresponding affect will be synthesized. The proposed approach consists of the following steps: First, based on the provided desired emotional state, a set of 3D facial meshes is produced from the 4DFAB database and is used to build a blendshape model that generates the new facial affect. To synthesize this affect on the 2D neutral image, 3D Morphable Models fitting is performed and the reconstructed face is then deformed to generate the target facial expressions. Finally, the new face is rendered into the original image. Qualitative experimental studies illustrate the generation of realistic images, when the neutral image is sampled from a variety of well known lab-controlled or in-the-wild databases, including Aff-Wild, RECOLA, AffectNet, AFEW, Multi-PIE, AFEW-VA, BU-3DFE, Bosphorus, RAF-DB. Also, quantitative experiments are conducted, in which deep neural networks, trained using the generated images from each of the above databases in a data-augmentation framework, provide affect recognition; better performances are achieved through the presented approach when compared with the current state-of-the-art.
A Multi-Task Learning & Generation Framework: Valence-Arousal, Action Units & Primary Expressions
Nov 11, 2018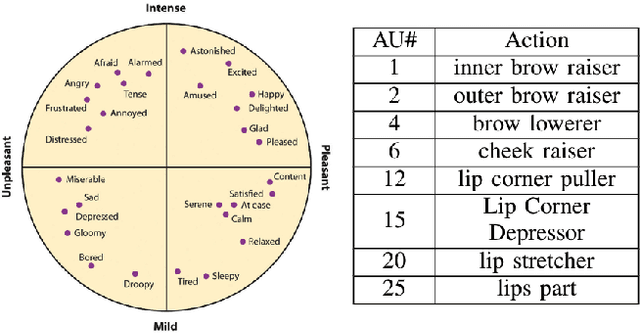
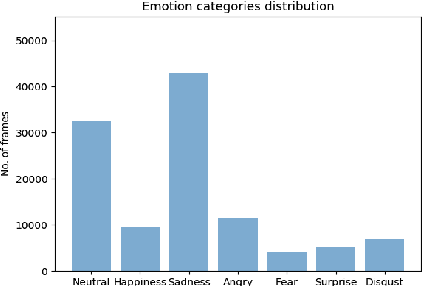
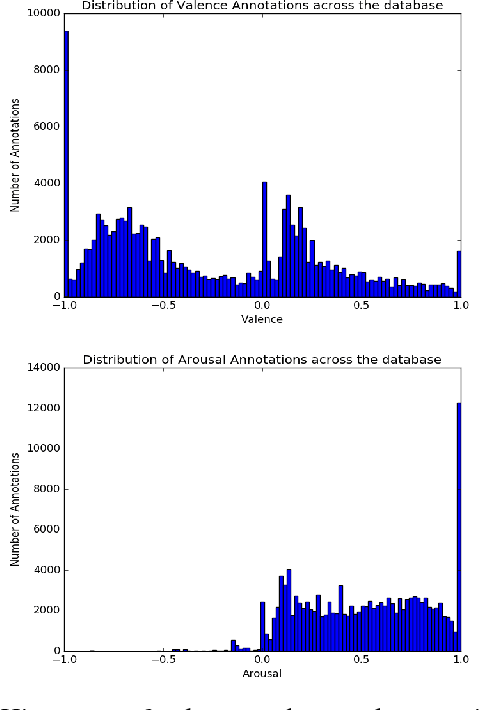
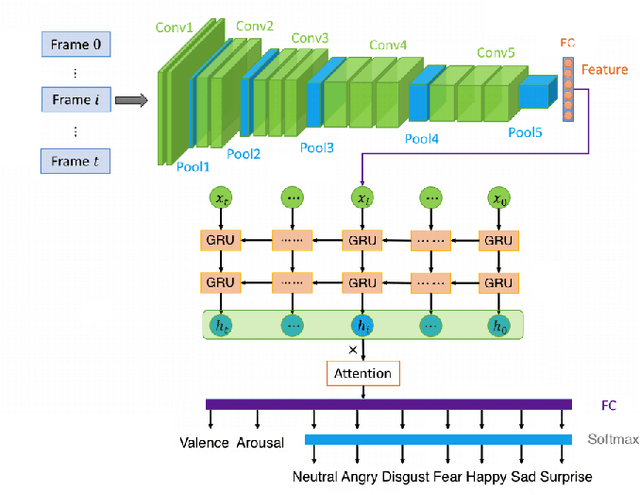
Over the past few years many research efforts have been devoted to the field of affect analysis. Various approaches have been proposed for: i) discrete emotion recognition in terms of the primary facial expressions; ii) emotion analysis in terms of facial Action Units (AUs), assuming a fixed expression intensity; iii) dimensional emotion analysis, in terms of valence and arousal (VA). These approaches can only be effective, if they are developed using large, appropriately annotated databases, showing behaviors of people in-the-wild, i.e., in uncontrolled environments. Aff-Wild has been the first, large-scale, in-the-wild database (including around 1,200,000 frames of 300 videos), annotated in terms of VA. In the vast majority of existing emotion databases, their annotation is limited to either primary expressions, or valence-arousal, or action units. In this paper, we first annotate a part (around $234,000$ frames) of the Aff-Wild database in terms of $8$ AUs and another part (around $288,000$ frames) in terms of the $7$ basic emotion categories, so that parts of this database are annotated in terms of VA, as well as AUs, or primary expressions. Then, we set up and tackle multi-task learning for emotion recognition, as well as for facial image generation. Multi-task learning is performed using: i) a deep neural network with shared hidden layers, which learns emotional attributes by exploiting their inter-dependencies; ii) a discriminator of a generative adversarial network (GAN). On the other hand, image generation is implemented through the generator of the GAN. For these two tasks, we carefully design loss functions that fit the examined set-up. Experiments are presented which illustrate the good performance of the proposed approach when applied to the new annotated parts of the Aff-Wild database.
Aff-Wild2: Extending the Aff-Wild Database for Affect Recognition
Nov 11, 2018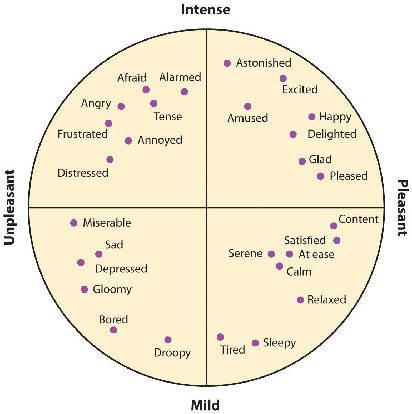


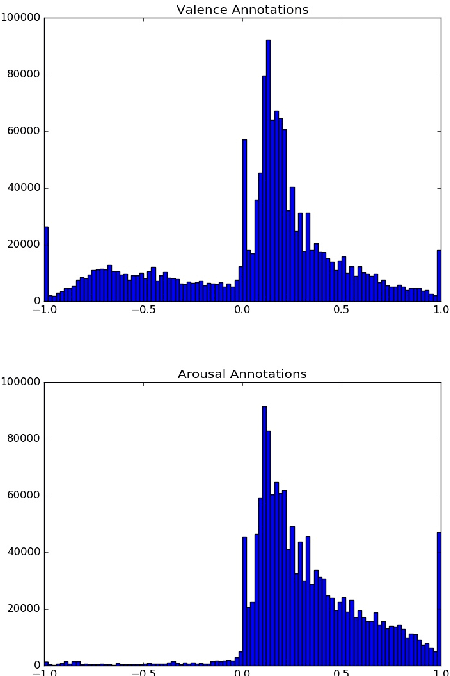
Automatic understanding of human affect using visual signals is a problem that has attracted significant interest over the past 20 years. However, human emotional states are quite complex. To appraise such states displayed in real-world settings, we need expressive emotional descriptors that are capable of capturing and describing this complexity. The circumplex model of affect, which is described in terms of valence (i.e., how positive or negative is an emotion) and arousal (i.e., power of the activation of the emotion), can be used for this purpose. Recent progress in the emotion recognition domain has been achieved through the development of deep neural architectures and the availability of very large training databases. To this end, Aff-Wild has been the first large-scale "in-the-wild" database, containing around 1,200,000 frames. In this paper, we build upon this database, extending it with 260 more subjects and 1,413,000 new video frames. We call the union of Aff-Wild with the additional data, Aff-Wild2. The videos are downloaded from Youtube and have large variations in pose, age, illumination conditions, ethnicity and profession. Both database-specific as well as cross-database experiments are performed in this paper, by utilizing the Aff-Wild2, along with the RECOLA database. The developed deep neural architectures are based on the joint training of state-of-the-art convolutional and recurrent neural networks with attention mechanism; thus exploiting both the invariant properties of convolutional features, while modeling temporal dynamics that arise in human behaviour via the recurrent layers. The obtained results show premise for utilization of the extended Aff-Wild, as well as of the developed deep neural architectures for visual analysis of human behaviour in terms of continuous emotion dimensions.
Photorealistic Facial Synthesis in the Dimensional Affect Space
Nov 11, 2018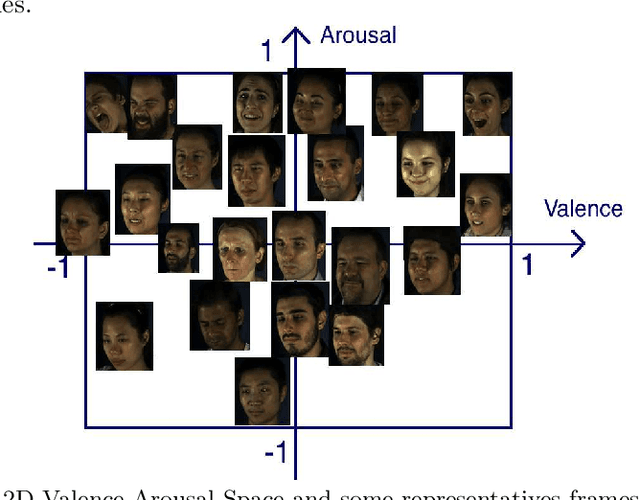
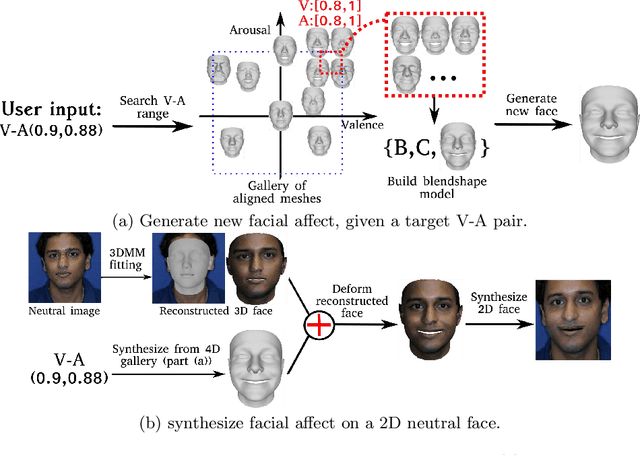

This paper presents a novel approach for synthesizing facial affect, which is based on our annotating 600,000 frames of the 4DFAB database in terms of valence and arousal. The input of this approach is a pair of these emotional state descriptors and a neutral 2D image of a person to whom the corresponding affect will be synthesized. Given this target pair, a set of 3D facial meshes is selected, which is used to build a blendshape model and generate the new facial affect. To synthesize the affect on the 2D neutral image, 3DMM fitting is performed and the reconstructed face is deformed to generate the target facial expressions. Last, the new face is rendered into the original image. Both qualitative and quantitative experimental studies illustrate the generation of realistic images, when the neutral image is sampled from a variety of well known databases, such as the Aff-Wild, AFEW, Multi-PIE, AFEW-VA, BU-3DFE, Bosphorus.
Training Deep Neural Networks with Different Datasets In-the-wild: The Emotion Recognition Paradigm
Sep 12, 2018

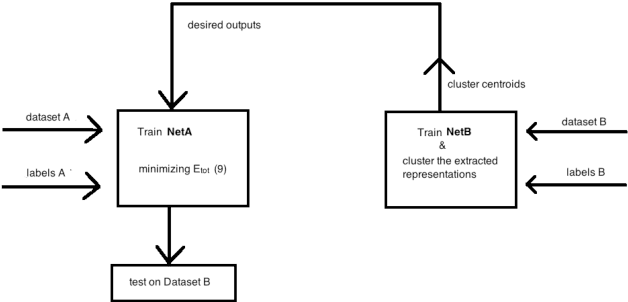
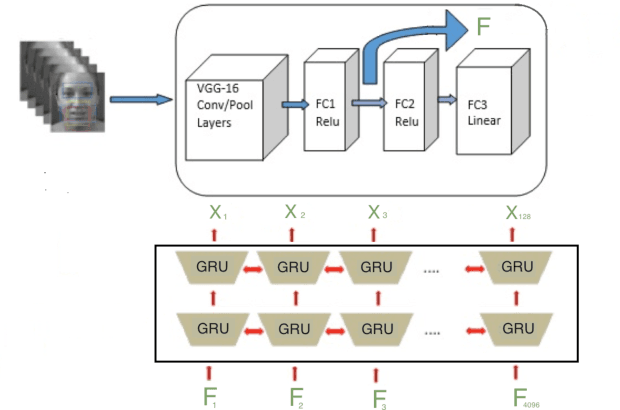
A novel procedure is presented in this paper, for training a deep convolutional and recurrent neural network, taking into account both the available training data set and some information extracted from similar networks trained with other relevant data sets. This information is included in an extended loss function used for the network training, so that the network can have an improved performance when applied to the other data sets, without forgetting the learned knowledge from the original data set. Facial expression and emotion recognition in-the-wild is the test bed application that is used to demonstrate the improved performance achieved using the proposed approach. In this framework, we provide an experimental study on categorical emotion recognition using datasets from a very recent related emotion recognition challenge.
Deep Affect Prediction in-the-wild: Aff-Wild Database and Challenge, Deep Architectures, and Beyond
Sep 01, 2018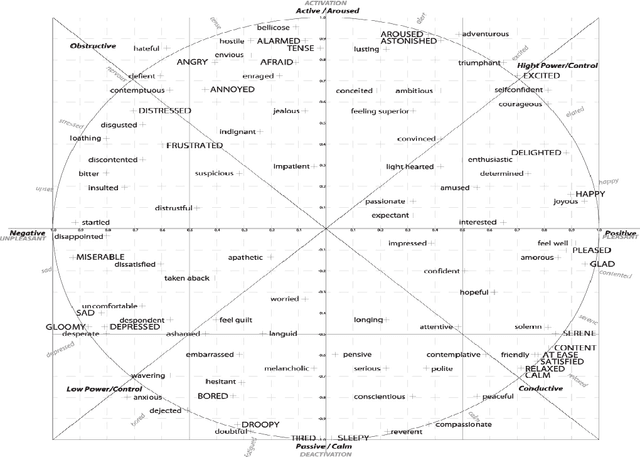
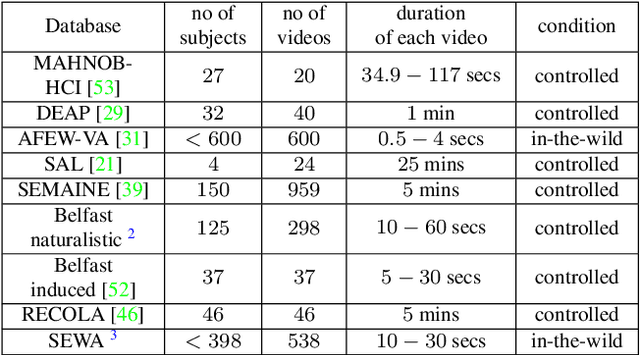
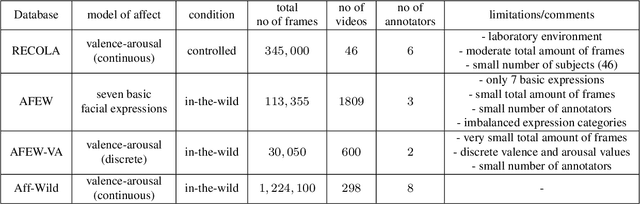

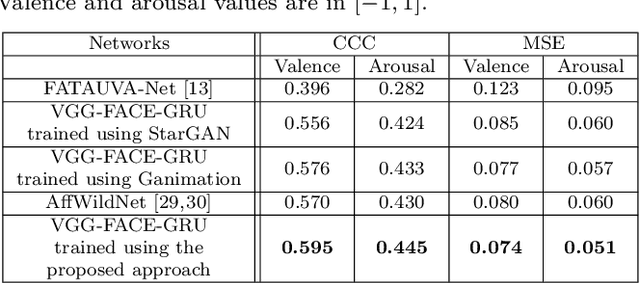
Automatic understanding of human affect using visual signals is of great importance in everyday human-machine interactions. Appraising human emotional states, behaviors and reactions displayed in real-world settings, can be accomplished using latent continuous dimensions (e.g., the circumplex model of affect). Valence (i.e., how positive or negative is an emotion) and arousal (i.e., power of the activation of the emotion) constitute the most popular and effective affect representations. Nevertheless, the majority of collected datasets this far, although containing naturalistic emotional states, have been captured in highly controlled recording conditions. In this paper, we introduce the Aff-Wild benchmark for training and evaluating affect recognition algorithms. We also report on the results of the First Affect-in-the-wild Challenge (Aff-Wild Challenge) that was recently organized on the Aff-Wild database, and was the first ever challenge on the estimation of valence and arousal in-the-wild. Furthermore, we design and extensively train an end-to-end deep neural architecture which performs prediction of continuous emotion dimensions based on visual cues. The proposed deep learning architecture, AffWildNet, includes convolutional and recurrent neural network (CNN-RNN) layers, exploiting the invariant properties of convolutional features, while also modeling temporal dynamics that arise in human behavior via the recurrent layers. The AffWildNet produced state-of-the-art results on the Aff-Wild Challenge. We then exploit the AffWild database for learning features, which can be used as priors for achieving best performances both for dimensional, as well as categorical emotion recognition, using the RECOLA, AFEW-VA and EmotiW 2017 datasets, compared to all other methods designed for the same goal.
4DFAB: A Large Scale 4D Facial Expression Database for Biometric Applications
Jun 14, 2018
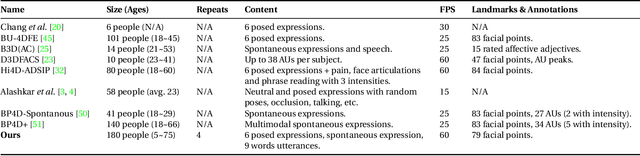


The progress we are currently witnessing in many computer vision applications, including automatic face analysis, would not be made possible without tremendous efforts in collecting and annotating large scale visual databases. To this end, we propose 4DFAB, a new large scale database of dynamic high-resolution 3D faces (over 1,800,000 3D meshes). 4DFAB contains recordings of 180 subjects captured in four different sessions spanning over a five-year period. It contains 4D videos of subjects displaying both spontaneous and posed facial behaviours. The database can be used for both face and facial expression recognition, as well as behavioural biometrics. It can also be used to learn very powerful blendshapes for parametrising facial behaviour. In this paper, we conduct several experiments and demonstrate the usefulness of the database for various applications. The database will be made publicly available for research purposes.
Robust Conditional Generative Adversarial Networks
May 22, 2018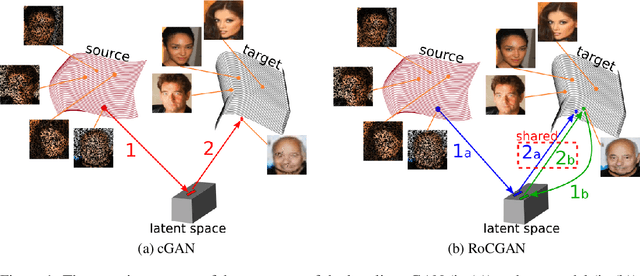
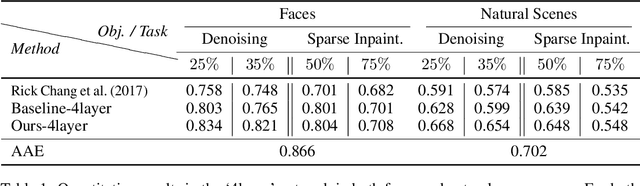
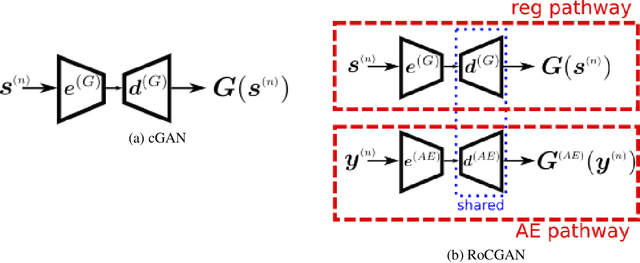
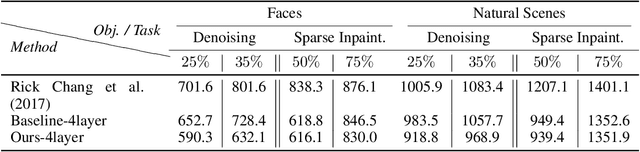
Conditional generative adversarial networks (cGAN) have led to large improvements in the task of conditional image generation, which lies at the heart of computer vision. The major focus so far has been on performance improvement, while there has been little effort in making cGAN more robust to noise or leveraging structure in the output space of the model. The end-to-end regression (of the generator) might lead to arbitrarily large errors in the output, which is unsuitable for the application of such networks to real-world systems. In this work, we introduce a novel conditional GAN, called RoCGAN, which adds implicit constraints to address the issue. Our proposed model augments the generator with an unsupervised pathway, which encourages the outputs of the generator to span the target manifold even in the presence of large amounts of noise. We prove that RoCGAN shares similar theoretical properties as GAN and experimentally verify that the proposed model outperforms existing state-of-the-art cGAN architectures by a large margin in a variety of domains including images from natural scenes and faces.
A Multi-component CNN-RNN Approach for Dimensional Emotion Recognition in-the-wild
May 08, 2018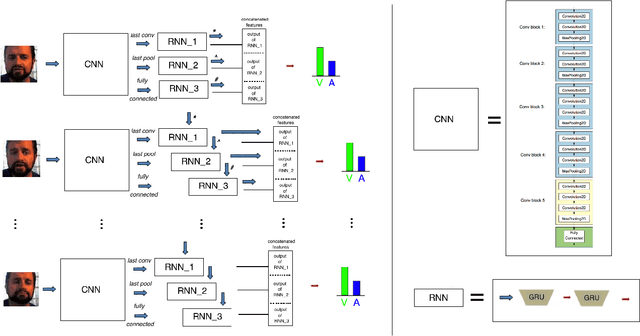
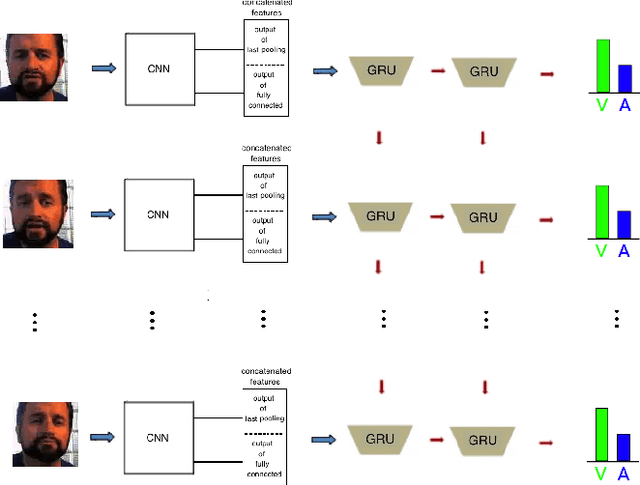
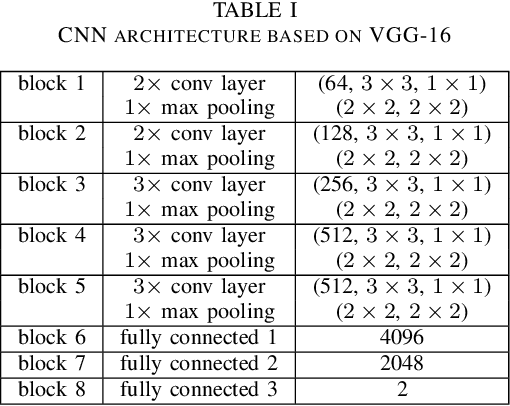

This paper presents our approach to the One-Minute Gradual-Emotion Recognition (OMG-Emotion) Challenge, focusing on dimensional emotion recognition through visual analysis of the provided emotion videos. The approach is based on a Convolutional and Recurrent (CNN-RNN) deep neural architecture we have developed for the relevant large AffWild Emotion Database. We extended and adapted this architecture, by letting a combination of multiple features generated in the CNN component be explored by RNN subnets. Our target has been to obtain best performance on the OMG-Emotion visual validation data set, while learning the respective visual training data set. Extended experimentation has led to best architectures for the estimation of the values of the valence and arousal emotion dimensions over these data sets.