 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Regression Loss for Non-Parametric Uncertainty Optimization
Jan 07, 2021
Quantification of uncertainty is one of the most promising approaches to establish safe machine learning. Despite its importance, it is far from being generally solved, especially for neural networks. One of the most commonly used approaches so far is Monte Carlo dropout, which is computationally cheap and easy to apply in practice. However, it can underestimate the uncertainty. We propose a new objective, referred to as second-moment loss (SML), to address this issue. While the full network is encouraged to model the mean, the dropout networks are explicitly used to optimize the model variance. We intensively study the performance of the new objective on various UCI regression datasets. Comparing to the state-of-the-art of deep ensembles, SML leads to comparable prediction accuracies and uncertainty estimates while only requiring a single model. Under distribution shift, we observe moderate improvements. As a side result, we introduce an intuitive Wasserstein distance-based uncertainty measure that is non-saturating and thus allows to resolve quality differences between any two uncertainty estimates.
Second-Moment Loss: A Novel Regression Objective for Improved Uncertainties
Dec 23, 2020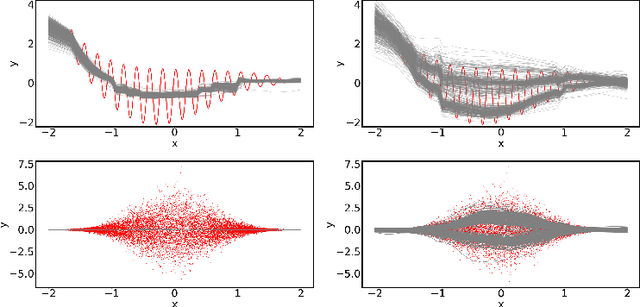
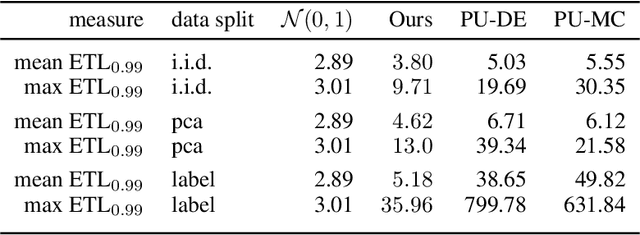
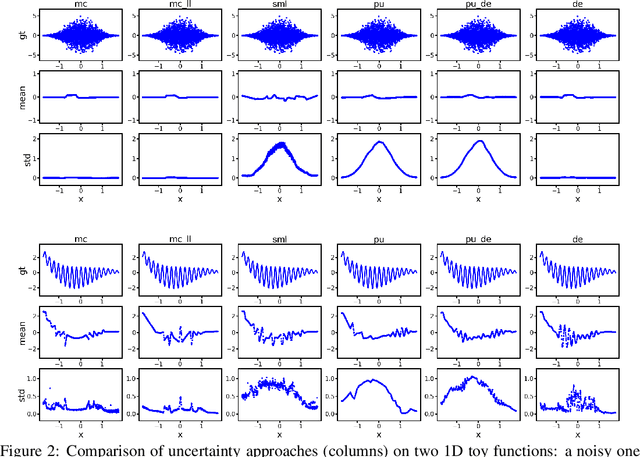
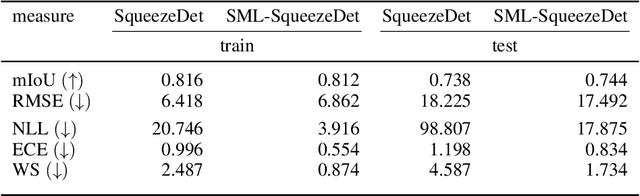
Quantification of uncertainty is one of the most promising approaches to establish safe machine learning. Despite its importance, it is far from being generally solved, especially for neural networks. One of the most commonly used approaches so far is Monte Carlo dropout, which is computationally cheap and easy to apply in practice. However, it can underestimate the uncertainty. We propose a new objective, referred to as second-moment loss (SML), to address this issue. While the full network is encouraged to model the mean, the dropout networks are explicitly used to optimize the model variance. We analyze the performance of the new objective on various toy and UCI regression datasets. Comparing to the state-of-the-art of deep ensembles, SML leads to comparable prediction accuracies and uncertainty estimates while only requiring a single model. Under distribution shift, we observe moderate improvements. From a safety perspective also the study of worst-case uncertainties is crucial. In this regard we improve considerably. Finally, we show that SML can be successfully applied to SqueezeDet, a modern object detection network. We improve on its uncertainty-related scores while not deteriorating regression quality. As a side result, we introduce an intuitive Wasserstein distance-based uncertainty measure that is non-saturating and thus allows to resolve quality differences between any two uncertainty estimates.
Learning Syllogism with Euler Neural-Networks
Jul 20, 2020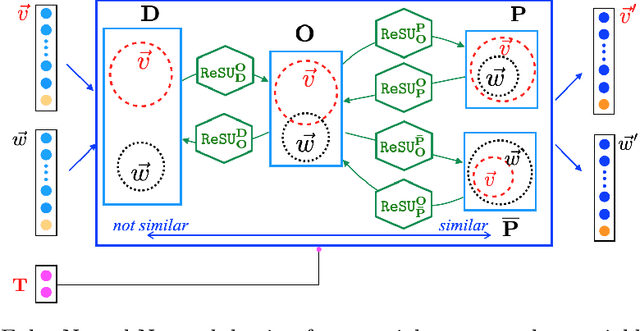
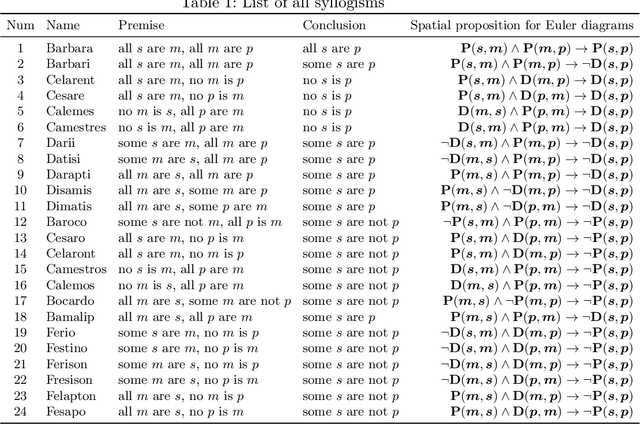
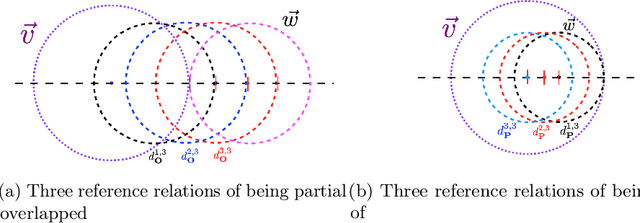

Traditional neural networks represent everything as a vector, and are able to approximate a subset of logical reasoning to a certain degree. As basic logic relations are better represented by topological relations between regions, we propose a novel neural network that represents everything as a ball and is able to learn topological configuration as an Euler diagram. So comes the name Euler Neural-Network (ENN). The central vector of a ball is a vector that can inherit representation power of traditional neural network. ENN distinguishes four spatial statuses between balls, namely, being disconnected, being partially overlapped, being part of, being inverse part of. Within each status, ideal values are defined for efficient reasoning. A novel back-propagation algorithm with six Rectified Spatial Units (ReSU) can optimize an Euler diagram representing logical premises, from which logical conclusion can be deduced. In contrast to traditional neural network, ENN can precisely represent all 24 different structures of Syllogism. Two large datasets are created: one extracted from WordNet-3.0 covers all types of Syllogism reasoning, the other extracted all family relations from DBpedia. Experiment results approve the superior power of ENN in logical representation and reasoning. Datasets and source code are available upon request.
Maximal Closed Set and Half-Space Separations in Finite Closure Systems
Jan 13, 2020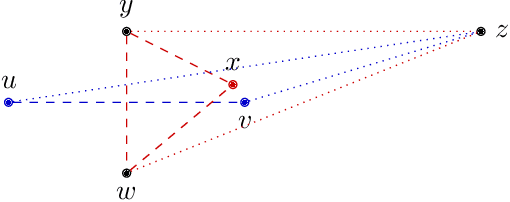
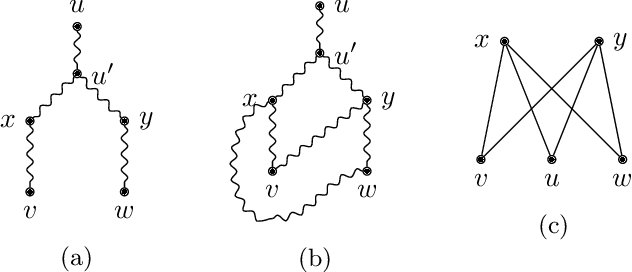
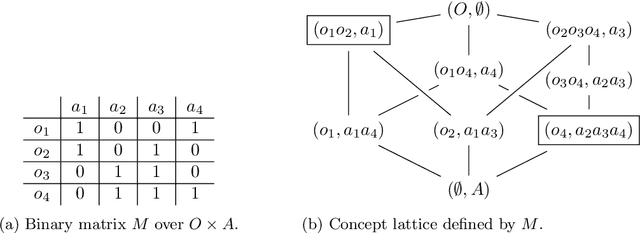
We investigate some algorithmic properties of closed set and half-space separation in abstract closure systems. Assuming that the underlying closure system is finite and given by the corresponding closure operator, we show that the half-space separation problem is NP-complete. In contrast, for the relaxed problem of maximal closed set separation we give a greedy algorithm using linear number of queries (i.e., closure operator calls) and show that this bound is sharp. For a second direction to overcome the negative result above, we consider Kakutani closure systems and prove that they are algorithmically characterized by the greedy algorithm. As one of the major potential application fields, we then focus on Kakutani closure systems over graphs and generalize a fundamental characterization result based on the Pasch axiom to graph structured partitioning of finite sets. In addition, we give a sufficient condition for Kakutani closure systems over graphs in terms of graph minors. For a second application field, we consider closure systems over finite lattices, present an adaptation of the generic greedy algorithm to this kind of closure systems, and consider two potential applications. We show that for the special case of subset lattices over finite ground sets, e.g., for formal concept lattices, its query complexity is only logarithmic in the size of the lattice. The second application is concerned with finite subsumption lattices in inductive logic programming. We show that our method for separating two sets of first-order clauses from each other extends the traditional approach based on least general generalizations of first-order clauses. Though our primary focus is on the generality of the results obtained, we experimentally demonstrate the practical usefulness of the greedy algorithm on binary classification problems in Kakutani and non-Kakutani closure systems.
Efficient Decentralized Deep Learning by Dynamic Model Averaging
Jul 09, 2018
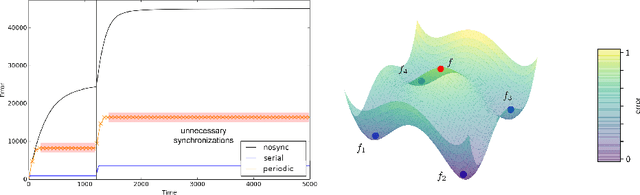
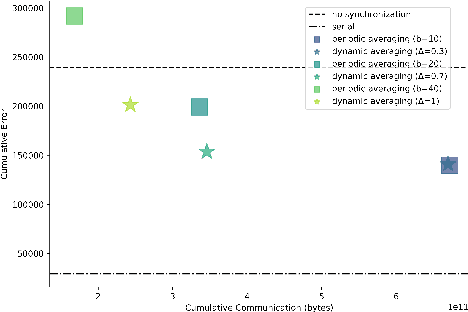
We propose an efficient protocol for decentralized training of deep neural networks from distributed data sources. The proposed protocol allows to handle different phases of model training equally well and to quickly adapt to concept drifts. This leads to a reduction of communication by an order of magnitude compared to periodically communicating state-of-the-art approaches. Moreover, we derive a communication bound that scales well with the hardness of the serialized learning problem. The reduction in communication comes at almost no cost, as the predictive performance remains virtually unchanged. Indeed, the proposed protocol retains loss bounds of periodically averaging schemes. An extensive empirical evaluation validates major improvement of the trade-off between model performance and communication which could be beneficial for numerous decentralized learning applications, such as autonomous driving, or voice recognition and image classification on mobile phones.
Adiabatic Quantum Computing for Binary Clustering
Jun 17, 2017
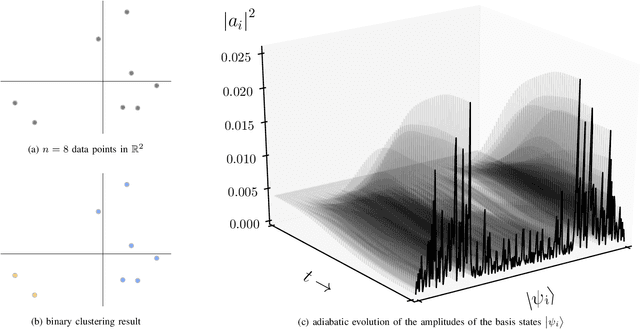
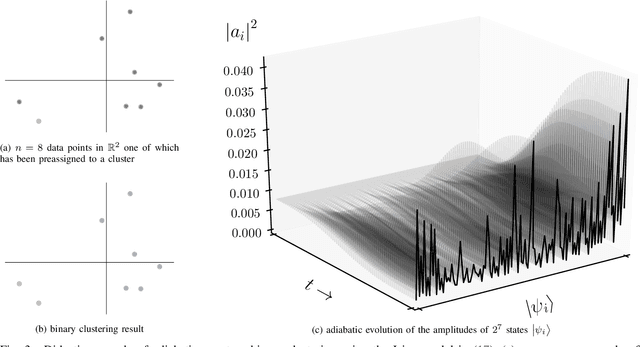
Quantum computing for machine learning attracts increasing attention and recent technological developments suggest that especially adiabatic quantum computing may soon be of practical interest. In this paper, we therefore consider this paradigm and discuss how to adopt it to the problem of binary clustering. Numerical simulations demonstrate the feasibility of our approach and illustrate how systems of qubits adiabatically evolve towards a solution.
Using Echo State Networks for Cryptography
Apr 04, 2017


Echo state networks are simple recurrent neural networks that are easy to implement and train. Despite their simplicity, they show a form of memory and can predict or regenerate sequences of data. We make use of this property to realize a novel neural cryptography scheme. The key idea is to assume that Alice and Bob share a copy of an echo state network. If Alice trains her copy to memorize a message, she can communicate the trained part of the network to Bob who plugs it into his copy to regenerate the message. Considering a byte-level representation of in- and output, the technique applies to arbitrary types of data (texts, images, audio files, etc.) and practical experiments reveal it to satisfy the fundamental cryptographic properties of diffusion and confusion.