 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStefan Wermter
Curious Hierarchical Actor-Critic Reinforcement Learning
May 27, 2020
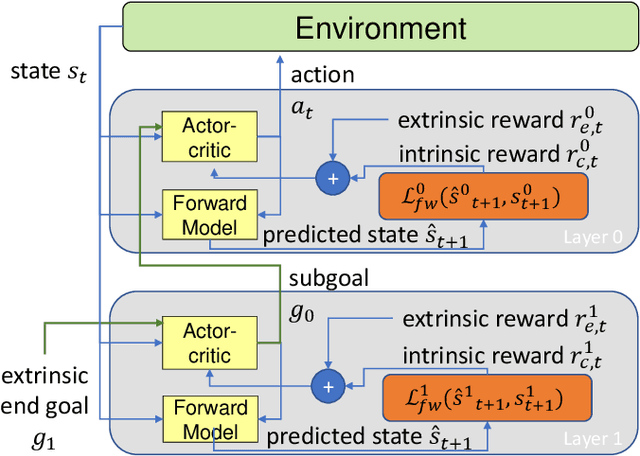
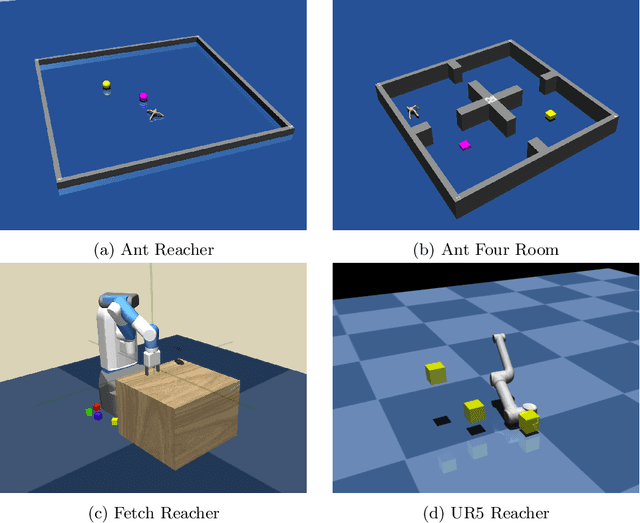
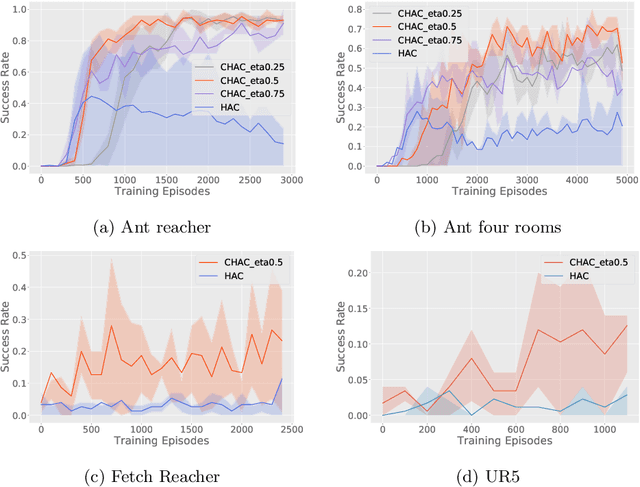
Hierarchical abstraction and curiosity-driven exploration are two common paradigms in current reinforcement learning approaches to break down difficult problems into a sequence of simpler ones and to overcome reward sparsity. However, there is a lack of approaches that combine these paradigms, and it is currently unknown whether curiosity also helps to perform the hierarchical abstraction. As a novelty and scientific contribution, we tackle this issue and develop a method that combines hierarchical reinforcement learning with curiosity. Herein, we extend a contemporary hierarchical actor-critic approach with a forward model to develop a hierarchical notion of curiosity. We demonstrate in several continuous-space environments that curiosity approximately doubles the learning performance and success rates for most of the investigated benchmarking problems.
Explainable Goal-Driven Agents and Robots- A Comprehensive Review and New Framework
Apr 21, 2020
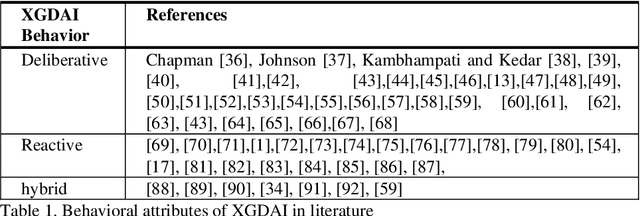
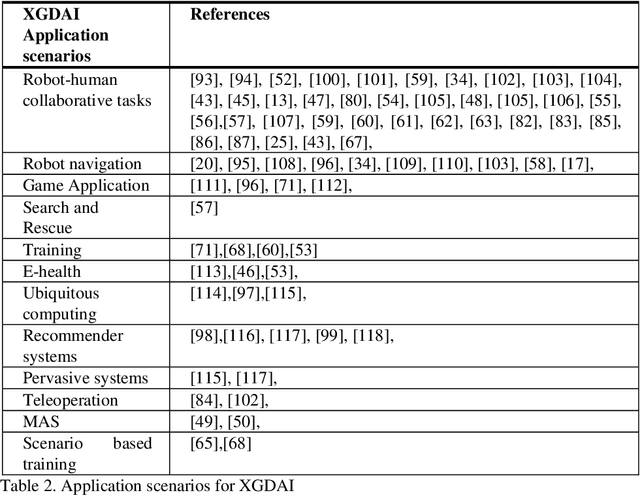
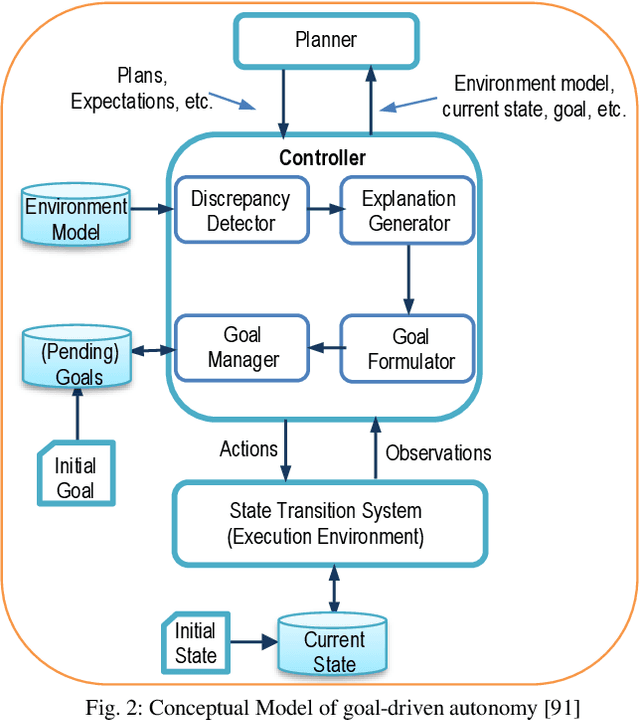
Recent applications of autonomous agents and robots, for example, self-driving cars, scenario-based trainers, exploration robots, service robots, have brought attention to crucial trust-related problems associated with the current generation of artificial intelligence (AI) systems. AI systems particularly dominated by the connectionist deep learning neural network approach lack capabilities of explaining their decisions and actions to others, despite their great successes. They are fundamentally non-intuitive black boxes, which renders their decision or actions opaque, making it difficult to trust them in safety-critical applications. The recent stance on the explainability of AI systems has witnessed several works on eXplainable Artificial Intelligence; however, most of the studies have focused on data-driven XAI systems applied in computational sciences. Studies addressing the increasingly pervasive goal-driven agents and robots are still missing. This paper reviews works on explainable goal-driven intelligent agents and robots, focusing on techniques for explaining and communicating agents perceptual functions (for example, senses, vision, etc.) and cognitive reasoning (for example, beliefs, desires, intention, plans, and goals) with humans in the loop. The review highlights key strategies that emphasize transparency and understandability, and continual learning for explainability. Finally, the paper presents requirements for explainability and suggests a roadmap for the possible realization of effective goal-driven explainable agents and robots
Improving Robot Dual-System Motor Learning with Intrinsically Motivated Meta-Control and Latent-Space Experience Imagination
Apr 19, 2020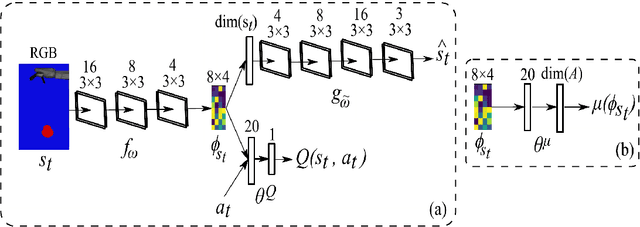
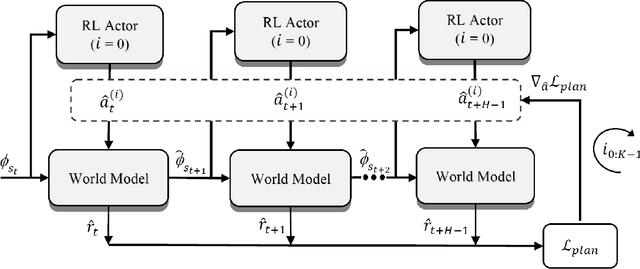

Combining model-based and model-free learning systems has been shown to improve the sample efficiency of learning to perform complex robotic tasks. However, dual-system approaches fail to consider the reliability of the learned model when it is applied to make multiple-step predictions, resulting in a compounding of prediction errors and performance degradation. In this paper, we present a novel dual-system motor learning approach where a meta-controller arbitrates online between model-based and model-free decisions based on an estimate of the local reliability of the learned model. The reliability estimate is used in computing an intrinsic feedback signal, encouraging actions that lead to data that improves the model. Our approach also integrates arbitration with imagination where a learned latent-space model generates imagined experiences, based on its local reliability, to be used as additional training data. We evaluate our approach against baseline and state-of-the-art methods on learning vision-based robotic grasping in simulation and real world. The results show that our approach outperforms the compared methods and learns near-optimal grasping policies in dense- and sparse-reward environments.
Improved Techniques for Training Single-Image GANs
Mar 25, 2020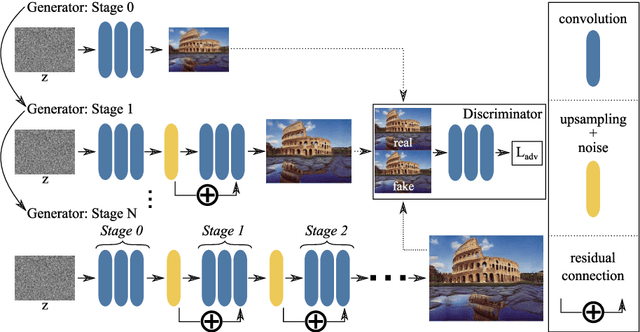



Recently there has been an interest in the potential of learning generative models from a single image, as opposed to from a large dataset. This task is of practical significance, as it means that generative models can be used in domains where collecting a large dataset is not feasible. However, training a model capable of generating realistic images from only a single sample is a difficult problem. In this work, we conduct a number of experiments to understand the challenges of training these methods and propose some best practices that we found allowed us to generate improved results over previous work in this space. One key piece is that unlike prior single image generation methods, we concurrently train several stages in a sequential multi-stage manner, allowing us to learn models with fewer stages of increasing image resolution. Compared to a recent state of the art baseline, our model is up to six times faster to train, has fewer parameters, and can better capture the global structure of images.
Efficient Facial Feature Learning with Wide Ensemble-based Convolutional Neural Networks
Jan 17, 2020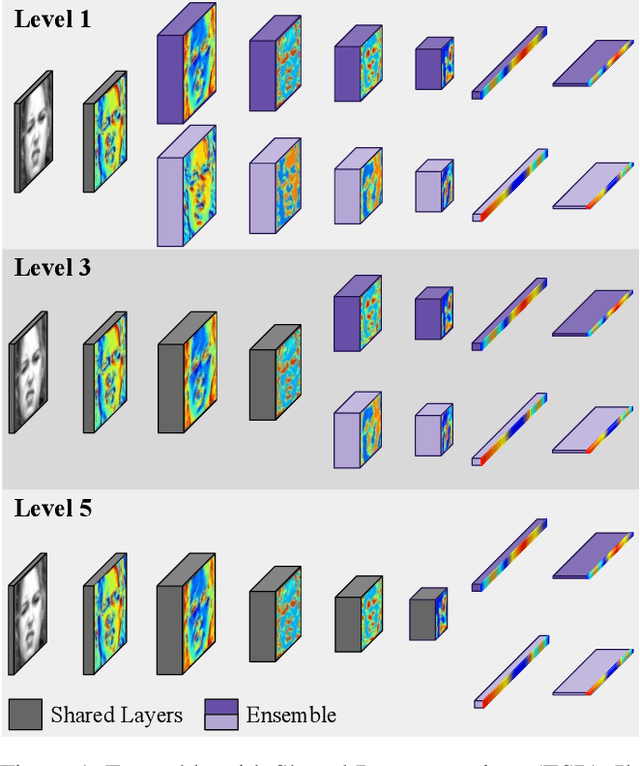
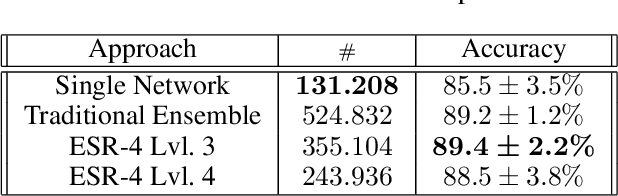
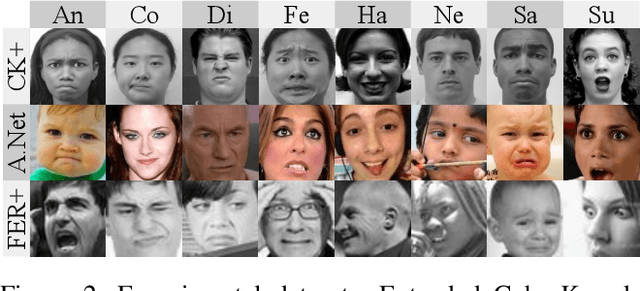
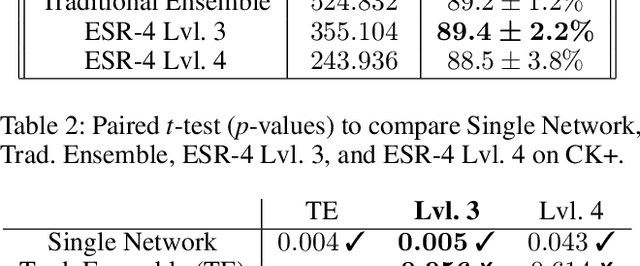
Ensemble methods, traditionally built with independently trained de-correlated models, have proven to be efficient methods for reducing the remaining residual generalization error, which results in robust and accurate methods for real-world applications. In the context of deep learning, however, training an ensemble of deep networks is costly and generates high redundancy which is inefficient. In this paper, we present experiments on Ensembles with Shared Representations (ESRs) based on convolutional networks to demonstrate, quantitatively and qualitatively, their data processing efficiency and scalability to large-scale datasets of facial expressions. We show that redundancy and computational load can be dramatically reduced by varying the branching level of the ESR without loss of diversity and generalization power, which are both important for ensemble performance. Experiments on large-scale datasets suggest that ESRs reduce the remaining residual generalization error on the AffectNet and FER+ datasets, reach human-level performance, and outperform state-of-the-art methods on facial expression recognition in the wild using emotion and affect concepts.
Solving Visual Object Ambiguities when Pointing: An Unsupervised Learning Approach
Dec 13, 2019
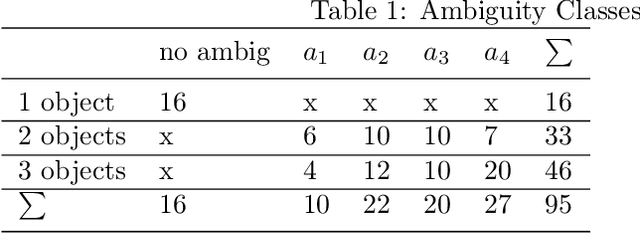
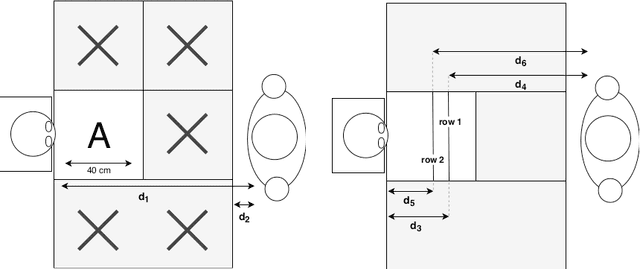
Whenever we are addressing a specific object or refer to a certain spatial location, we are using referential or deictic gestures usually accompanied by some verbal description. Especially pointing gestures are necessary to dissolve ambiguities in a scene and they are of crucial importance when verbal communication may fail due to environmental conditions or when two persons simply do not speak the same language. With the currently increasing advances of humanoid robots and their future integration in domestic domains, the development of gesture interfaces complementing human-robot interaction scenarios is of substantial interest. The implementation of an intuitive gesture scenario is still challenging because both the pointing intention and the corresponding object have to be correctly recognized in real-time. The demand increases when considering pointing gestures in a cluttered environment, as is the case in households. Also, humans perform pointing in many different ways and those variations have to be captured. Research in this field often proposes a set of geometrical computations which do not scale well with the number of gestures and objects, use specific markers or a predefined set of pointing directions. In this paper, we propose an unsupervised learning approach to model the distribution of pointing gestures using a growing-when-required (GWR) network. We introduce an interaction scenario with a humanoid robot and define so-called ambiguity classes. Our implementation for the hand and object detection is independent of any markers or skeleton models, thus it can be easily reproduced. Our evaluation comparing a baseline computer vision approach with our GWR model shows that the pointing-object association is well learned even in cases of ambiguities resulting from close object proximity.
Enriching Existing Conversational Emotion Datasets with Dialogue Acts using Neural Annotators
Dec 05, 2019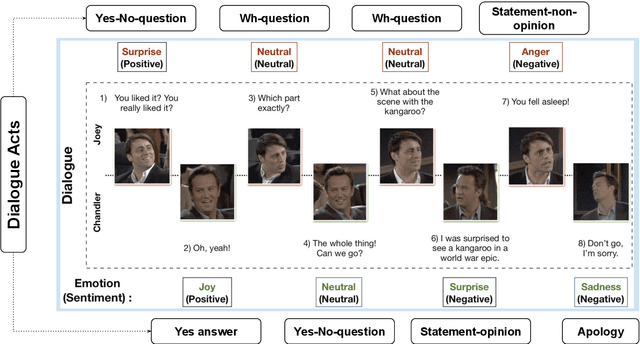

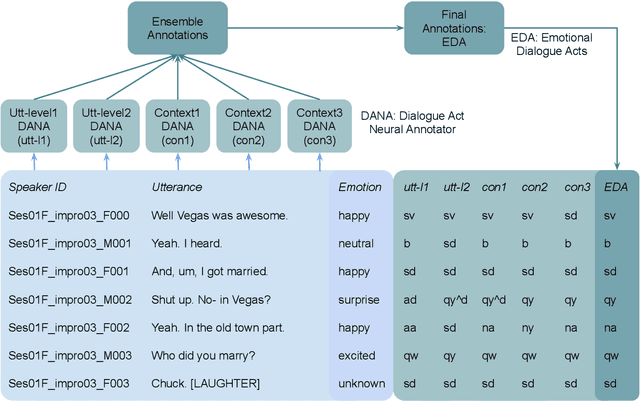
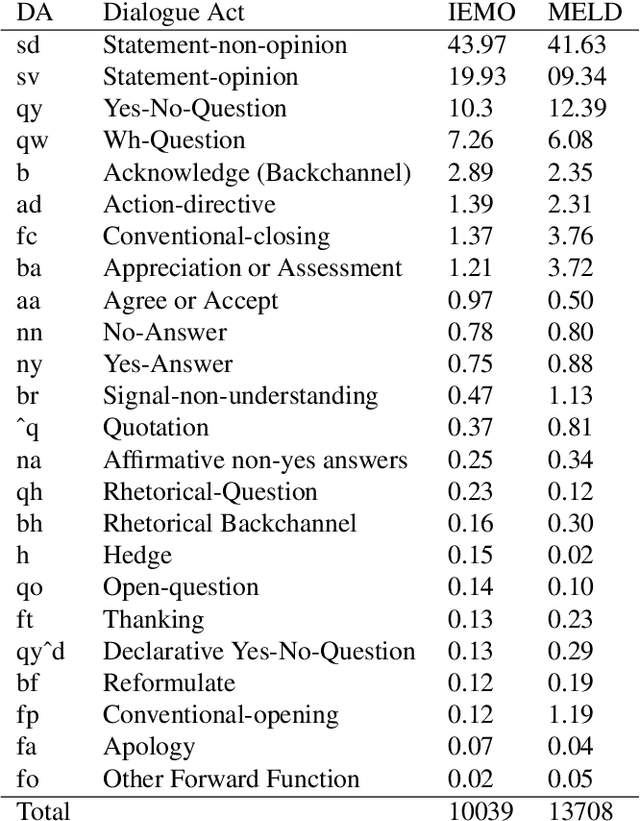
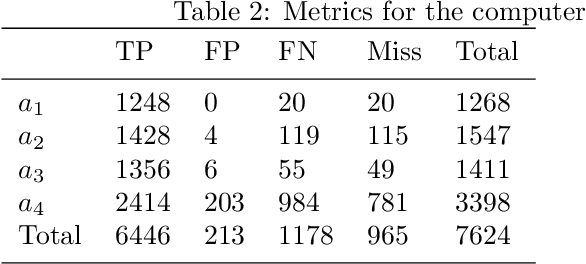
The recognition of emotion and dialogue acts enrich conversational analysis and help to build natural dialogue systems. Emotion makes us understand feelings and dialogue acts reflect the intentions and performative functions in the utterances. However, most of the textual and multi-modal conversational emotion datasets contain only emotion labels but not dialogue acts. To address this problem, we propose to use a pool of various recurrent neural models trained on a dialogue act corpus, with or without context. These neural models annotate the emotion corpus with dialogue act labels and an ensemble annotator extracts the final dialogue act label. We annotated two popular multi-modal emotion datasets: IEMOCAP and MELD. We analysed the co-occurrence of emotion and dialogue act labels and discovered specific relations. For example, Accept/Agree dialogue acts often occur with the Joy emotion, Apology with Sadness, and Thanking with Joy. We make the Emotional Dialogue Act (EDA) corpus publicly available to the research community for further study and analysis.
Semantic Object Accuracy for Generative Text-to-Image Synthesis
Oct 29, 2019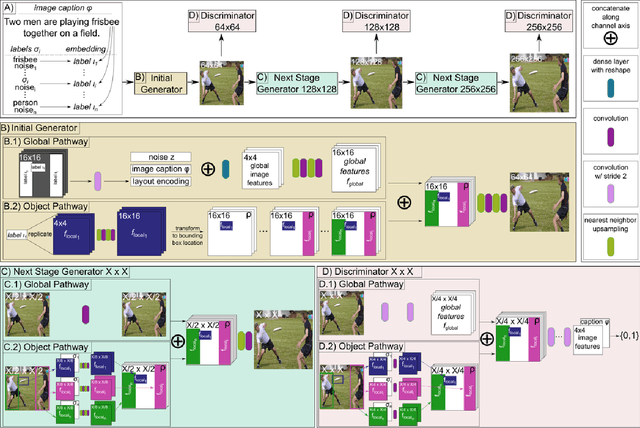
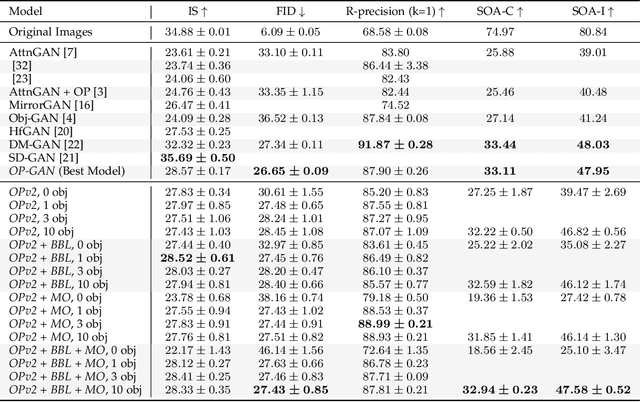

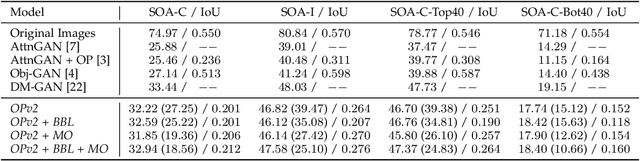
Generative adversarial networks conditioned on simple textual image descriptions are capable of generating realistic-looking images. However, current methods still struggle to generate images based on complex image captions from a heterogeneous domain. Furthermore, quantitatively evaluating these text-to-image synthesis models is still challenging, as most evaluation metrics only judge image quality but not the conformity between the image and its caption. To address the aforementioned challenges we introduce both a new model that explicitly models individual objects within an image and a new evaluation metric called Semantic Object Accuracy (SOA) that specifically evaluates images given an image caption. Our model adds an object pathway to both the generator and the discriminator to explicitly learn features of individual objects. The SOA uses a pre-trained object detector to evaluate if a generated image contains objects that are specifically mentioned in the image caption, e.g. whether an image generated from "a car driving down the street" contains a car. Our evaluation shows that models which explicitly model individual objects outperform models which only model global image characteristics. However, the SOA also shows that despite this increased performance current models still struggle to generate images that contain realistic objects of multiple different domains.