 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Prompts to Propositions: A Logic-Based Lens on Student-LLM Interactions
Apr 25, 2025Background and Context. The increasing integration of large language models (LLMs) in computing education presents an emerging challenge in understanding how students use LLMs and craft prompts to solve computational tasks. Prior research has used both qualitative and quantitative methods to analyze prompting behavior, but these approaches lack scalability or fail to effectively capture the semantic evolution of prompts. Objective. In this paper, we investigate whether students prompts can be systematically analyzed using propositional logic constraints. We examine whether this approach can identify patterns in prompt evolution, detect struggling students, and provide insights into effective and ineffective strategies. Method. We introduce Prompt2Constraints, a novel method that translates students prompts into logical constraints. The constraints are able to represent the intent of the prompts in succinct and quantifiable ways. We used this approach to analyze a dataset of 1,872 prompts from 203 students solving introductory programming tasks. Findings. We find that while successful and unsuccessful attempts tend to use a similar number of constraints overall, when students fail, they often modify their prompts more significantly, shifting problem-solving strategies midway. We also identify points where specific interventions could be most helpful to students for refining their prompts. Implications. This work offers a new and scalable way to detect students who struggle in solving natural language programming tasks. This work could be extended to investigate more complex tasks and integrated into programming tools to provide real-time support.
A Measure Based Generalizable Approach to Understandability
Mar 27, 2025Successful agent-human partnerships require that any agent generated information is understandable to the human, and that the human can easily steer the agent towards a goal. Such effective communication requires the agent to develop a finer-level notion of what is understandable to the human. State-of-the-art agents, including LLMs, lack this detailed notion of understandability because they only capture average human sensibilities from the training data, and therefore afford limited steerability (e.g., requiring non-trivial prompt engineering). In this paper, instead of only relying on data, we argue for developing generalizable, domain-agnostic measures of understandability that can be used as directives for these agents. Existing research on understandability measures is fragmented, we survey various such efforts across domains, and lay a cognitive-science-rooted groundwork for more coherent and domain-agnostic research investigations in future.
Webvs. LLMs: An Empirical Study of Learning Behaviors of CS2 Students
Jan 21, 2025



LLMs such as ChatGPT have been widely adopted by students in higher education as tools for learning programming and related concepts. However, it remains unclear how effective students are and what strategies students use while learning with LLMs. Since the majority of students' experiences in online self-learning have come through using search engines such as Google, evaluating AI tools in this context can help us address these gaps. In this mixed methods research, we conducted an exploratory within-subjects study to understand how CS2 students learn programming concepts using both LLMs as well as traditional online methods such as educational websites and videos to examine how students approach learning within and across both scenarios. We discovered that students found it easier to learn a more difficult concept using traditional methods than using ChatGPT. We also found that students ask fewer follow-ups and use more keyword-based queries for search engines while their prompts to LLMs tend to explicitly ask for information.
What is it like to program with artificial intelligence?
Aug 12, 2022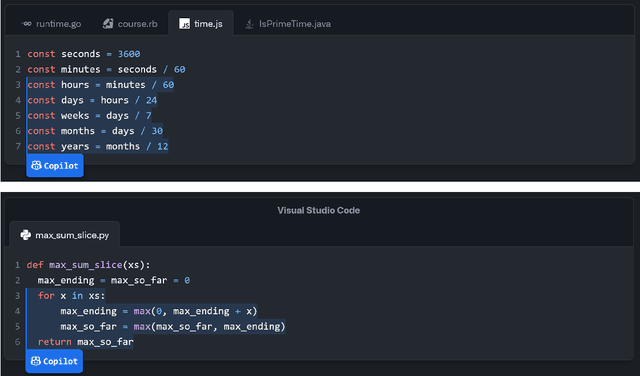
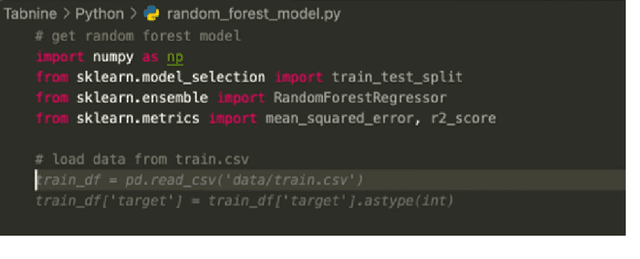
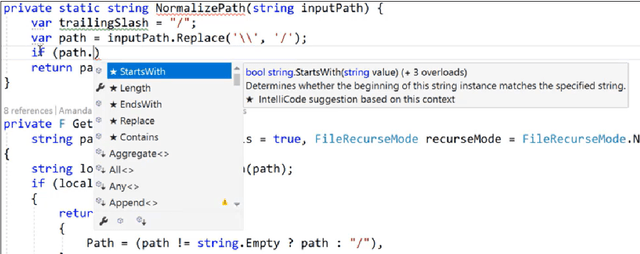
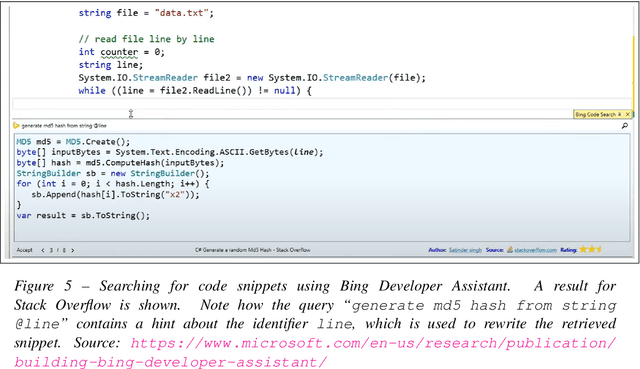
Large language models, such as OpenAI's codex and Deepmind's AlphaCode, can generate code to solve a variety of problems expressed in natural language. This technology has already been commercialised in at least one widely-used programming editor extension: GitHub Copilot. In this paper, we explore how programming with large language models (LLM-assisted programming) is similar to, and differs from, prior conceptualisations of programmer assistance. We draw upon publicly available experience reports of LLM-assisted programming, as well as prior usability and design studies. We find that while LLM-assisted programming shares some properties of compilation, pair programming, and programming via search and reuse, there are fundamental differences both in the technical possibilities as well as the practical experience. Thus, LLM-assisted programming ought to be viewed as a new way of programming with its own distinct properties and challenges. Finally, we draw upon observations from a user study in which non-expert end user programmers use LLM-assisted tools for solving data tasks in spreadsheets. We discuss the issues that might arise, and open research challenges, in applying large language models to end-user programming, particularly with users who have little or no programming expertise.