 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUBERT: A Novel Language Model for Synonymy Prediction at Scale in the UMLS Metathesaurus
Apr 27, 2022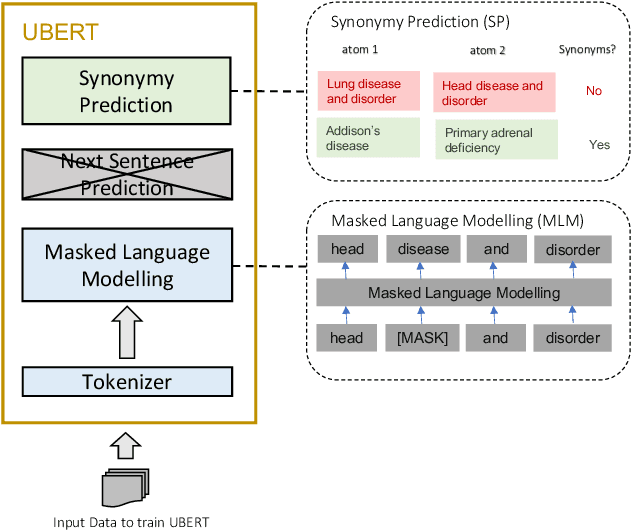
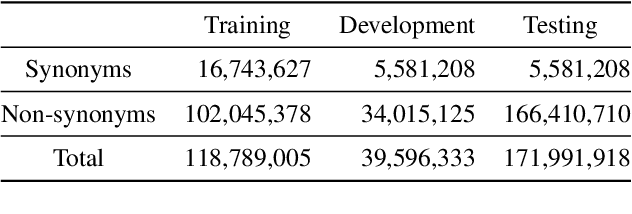
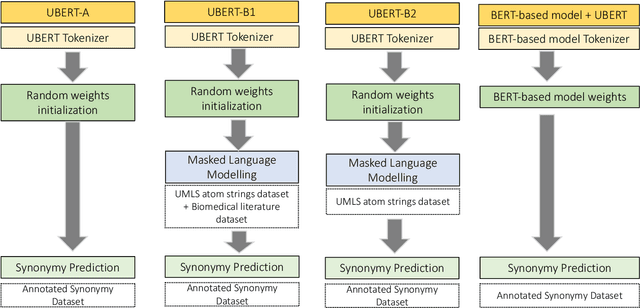

The UMLS Metathesaurus integrates more than 200 biomedical source vocabularies. During the Metathesaurus construction process, synonymous terms are clustered into concepts by human editors, assisted by lexical similarity algorithms. This process is error-prone and time-consuming. Recently, a deep learning model (LexLM) has been developed for the UMLS Vocabulary Alignment (UVA) task. This work introduces UBERT, a BERT-based language model, pretrained on UMLS terms via a supervised Synonymy Prediction (SP) task replacing the original Next Sentence Prediction (NSP) task. The effectiveness of UBERT for UMLS Metathesaurus construction process is evaluated using the UMLS Vocabulary Alignment (UVA) task. We show that UBERT outperforms the LexLM, as well as biomedical BERT-based models. Key to the performance of UBERT are the synonymy prediction task specifically developed for UBERT, the tight alignment of training data to the UVA task, and the similarity of the models used for pretrained UBERT.
FairMod: Fair Link Prediction and Recommendation via Graph Modification
Jan 27, 2022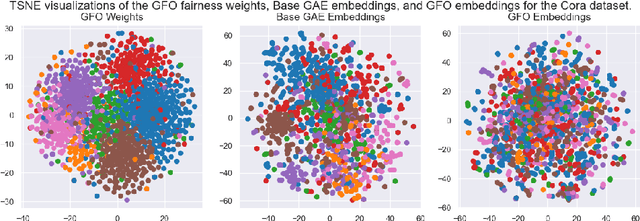
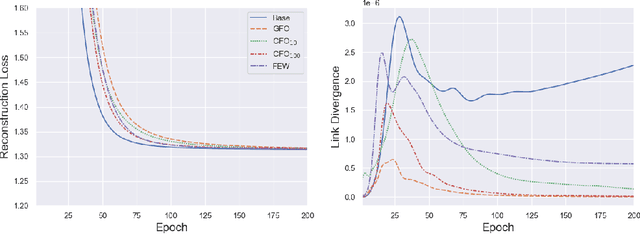
As machine learning becomes more widely adopted across domains, it is critical that researchers and ML engineers think about the inherent biases in the data that may be perpetuated by the model. Recently, many studies have shown that such biases are also imbibed in Graph Neural Network (GNN) models if the input graph is biased. In this work, we aim to mitigate the bias learned by GNNs through modifying the input graph. To that end, we propose FairMod, a Fair Graph Modification methodology with three formulations: the Global Fairness Optimization (GFO), Community Fairness Optimization (CFO), and Fair Edge Weighting (FEW) models. Our proposed models perform either microscopic or macroscopic edits to the input graph while training GNNs and learn node embeddings that are both accurate and fair under the context of link recommendations. We demonstrate the effectiveness of our approach on four real world datasets and show that we can improve the recommendation fairness by several factors at negligible cost to link prediction accuracy.
Semi-Supervised Deep Learning for Multiplex Networks
Oct 05, 2021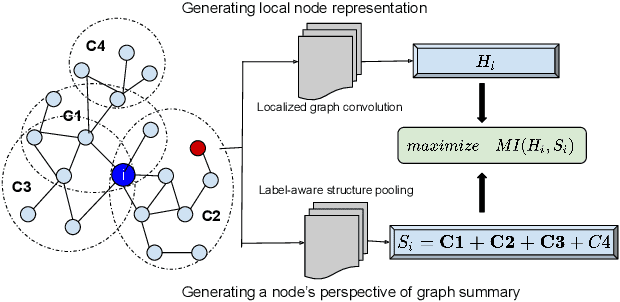
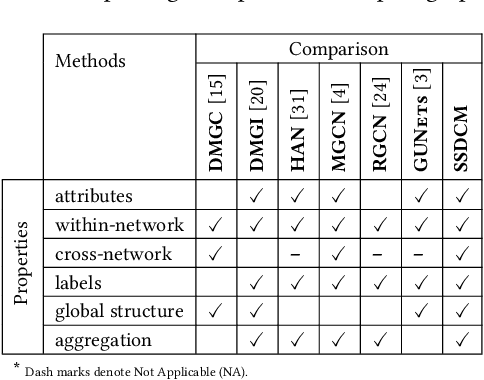
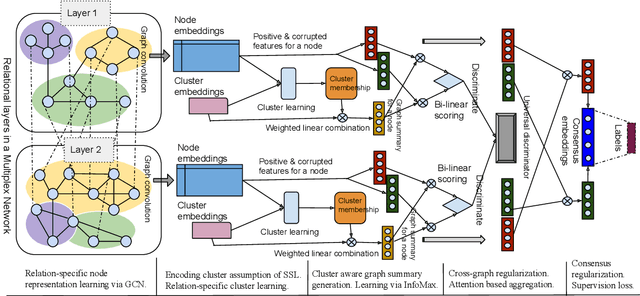
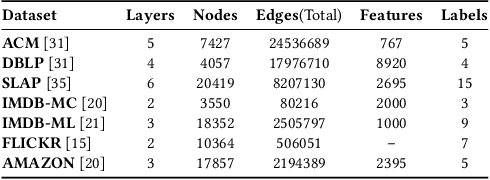
Multiplex networks are complex graph structures in which a set of entities are connected to each other via multiple types of relations, each relation representing a distinct layer. Such graphs are used to investigate many complex biological, social, and technological systems. In this work, we present a novel semi-supervised approach for structure-aware representation learning on multiplex networks. Our approach relies on maximizing the mutual information between local node-wise patch representations and label correlated structure-aware global graph representations to model the nodes and cluster structures jointly. Specifically, it leverages a novel cluster-aware, node-contextualized global graph summary generation strategy for effective joint-modeling of node and cluster representations across the layers of a multiplex network. Empirically, we demonstrate that the proposed architecture outperforms state-of-the-art methods in a range of tasks: classification, clustering, visualization, and similarity search on seven real-world multiplex networks for various experiment settings.
Privacy Policy Question Answering Assistant: A Query-Guided Extractive Summarization Approach
Sep 29, 2021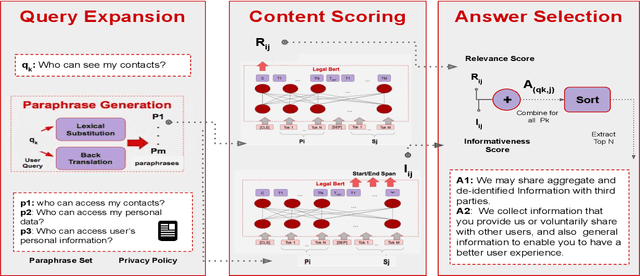

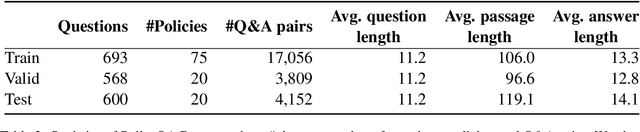

Existing work on making privacy policies accessible has explored new presentation forms such as color-coding based on the risk factors or summarization to assist users with conscious agreement. To facilitate a more personalized interaction with the policies, in this work, we propose an automated privacy policy question answering assistant that extracts a summary in response to the input user query. This is a challenging task because users articulate their privacy-related questions in a very different language than the legal language of the policy, making it difficult for the system to understand their inquiry. Moreover, existing annotated data in this domain are limited. We address these problems by paraphrasing to bring the style and language of the user's question closer to the language of privacy policies. Our content scoring module uses the existing in-domain data to find relevant information in the policy and incorporates it in a summary. Our pipeline is able to find an answer for 89% of the user queries in the privacyQA dataset.
Evaluating Biomedical BERT Models for Vocabulary Alignment at Scale in the UMLS Metathesaurus
Sep 14, 2021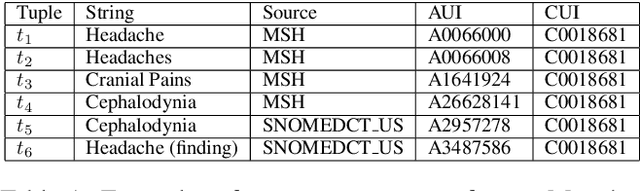
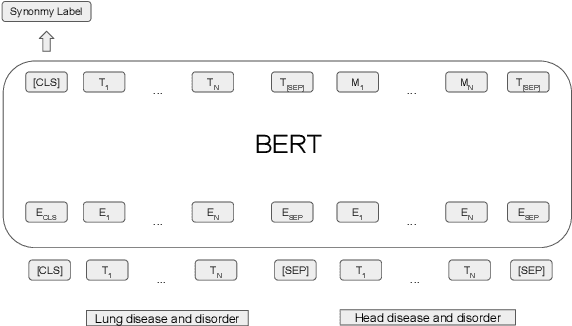

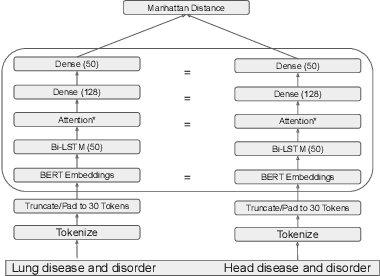
The current UMLS (Unified Medical Language System) Metathesaurus construction process for integrating over 200 biomedical source vocabularies is expensive and error-prone as it relies on the lexical algorithms and human editors for deciding if the two biomedical terms are synonymous. Recent advances in Natural Language Processing such as Transformer models like BERT and its biomedical variants with contextualized word embeddings have achieved state-of-the-art (SOTA) performance on downstream tasks. We aim to validate if these approaches using the BERT models can actually outperform the existing approaches for predicting synonymy in the UMLS Metathesaurus. In the existing Siamese Networks with LSTM and BioWordVec embeddings, we replace the BioWordVec embeddings with the biomedical BERT embeddings extracted from each BERT model using different ways of extraction. In the Transformer architecture, we evaluate the use of the different biomedical BERT models that have been pre-trained using different datasets and tasks. Given the SOTA performance of these BERT models for other downstream tasks, our experiments yield surprisingly interesting results: (1) in both model architectures, the approaches employing these biomedical BERT-based models do not outperform the existing approaches using Siamese Network with BioWordVec embeddings for the UMLS synonymy prediction task, (2) the original BioBERT large model that has not been pre-trained with the UMLS outperforms the SapBERT models that have been pre-trained with the UMLS, and (3) using the Siamese Networks yields better performance for synonymy prediction when compared to using the biomedical BERT models.
Fairness-aware Summarization for Justified Decision-Making
Jul 13, 2021
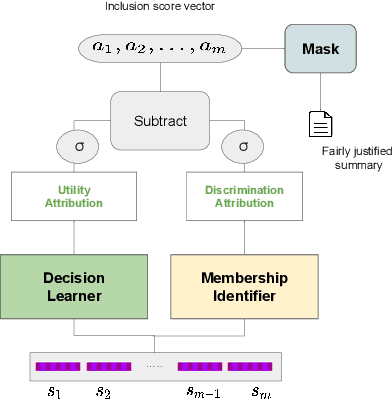

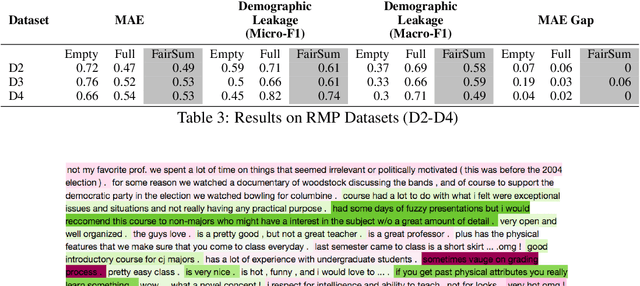
In many applications such as recidivism prediction, facility inspection, and benefit assignment, it's important for individuals to know the decision-relevant information for the model's prediction. In addition, the model's predictions should be fairly justified. Essentially, decision-relevant features should provide sufficient information for the predicted outcome and should be independent of the membership of individuals in protected groups such as race and gender. In this work, we focus on the problem of (un)fairness in the justification of the text-based neural models. We tie the explanatory power of the model to fairness in the outcome and propose a fairness-aware summarization mechanism to detect and counteract the bias in such models. Given a potentially biased natural language explanation for a decision, we use a multi-task neural model and an attribution mechanism based on integrated gradients to extract the high-utility and discrimination-free justifications in the form of a summary. The extracted summary is then used for training a model to make decisions for individuals. Results on several real-world datasets suggests that our method: (i) assists users to understand what information is used for the model's decision and (ii) enhances the fairness in outcomes while significantly reducing the demographic leakage.
StyleML: Stylometry with Structure and Multitask Learning for Darkweb Markets
Apr 01, 2021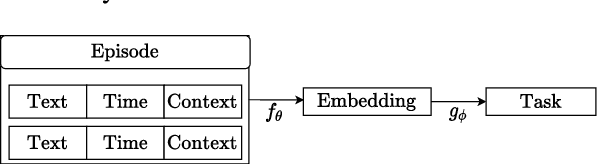
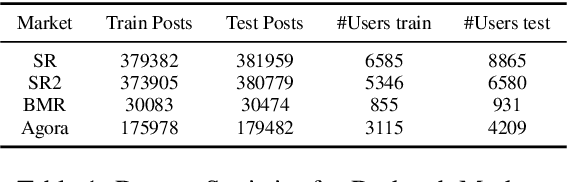
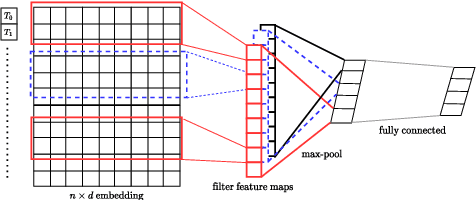
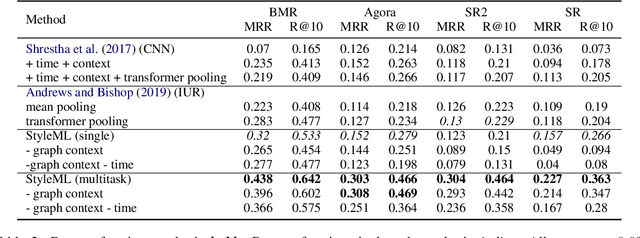
Darknet market forums are frequently used to exchange illegal goods and services between parties who use encryption to conceal their identities. The Tor network is used to host these markets, which guarantees additional anonymization from IP and location tracking, making it challenging to link across malicious users using multiple accounts (sybils). Additionally, users migrate to new forums when one is closed, making it difficult to link users across multiple forums. We develop a novel stylometry-based multitask learning approach for natural language and interaction modeling using graph embeddings to construct low-dimensional representations of short episodes of user activity for authorship attribution. We provide a comprehensive evaluation of our methods across four different darknet forums demonstrating its efficacy over the state-of-the-art, with a lift of up to 2.5X on Mean Retrieval Rank and 2X on Recall@10.
eDarkTrends: Harnessing Social Media Trends in Substance use disorders for Opioid Listings on Cryptomarket
Mar 29, 2021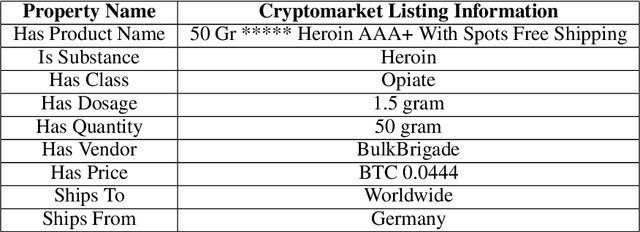
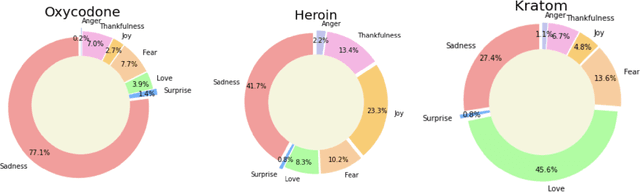

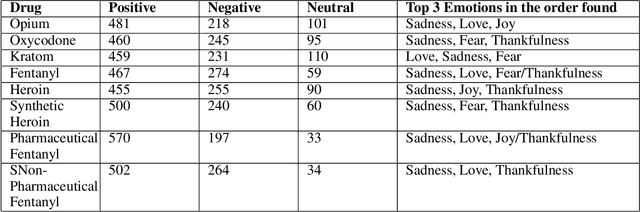
Opioid and substance misuse is rampant in the United States today, with the phenomenon known as the opioid crisis. The relationship between substance use and mental health has been extensively studied, with one possible relationship being substance misuse causes poor mental health. However, the lack of evidence on the relationship has resulted in opioids being largely inaccessible through legal means. This study analyzes the substance misuse posts on social media with the opioids being sold through crypto market listings. We use the Drug Abuse Ontology, state-of-the-art deep learning, and BERT-based models to generate sentiment and emotion for the social media posts to understand user perception on social media by investigating questions such as, which synthetic opioids people are optimistic, neutral, or negative about or what kind of drugs induced fear and sorrow or what kind of drugs people love or thankful about or which drug people think negatively about or which opioids cause little to no sentimental reaction. We also perform topic analysis associated with the generated sentiments and emotions to understand which topics correlate with people's responses to various drugs. Our findings can help shape policy to help isolate opioid use cases where timely intervention may be required to prevent adverse consequences, prevent overdose-related deaths, and worsen the epidemic.
Driving Style Representation in Convolutional Recurrent Neural Network Model of Driver Identification
Feb 11, 2021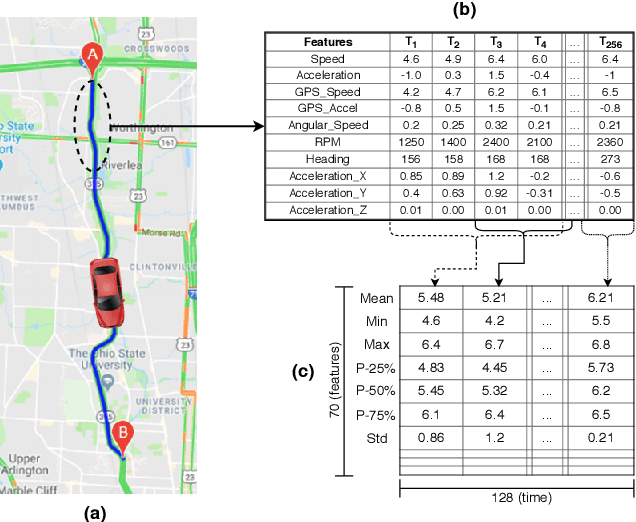
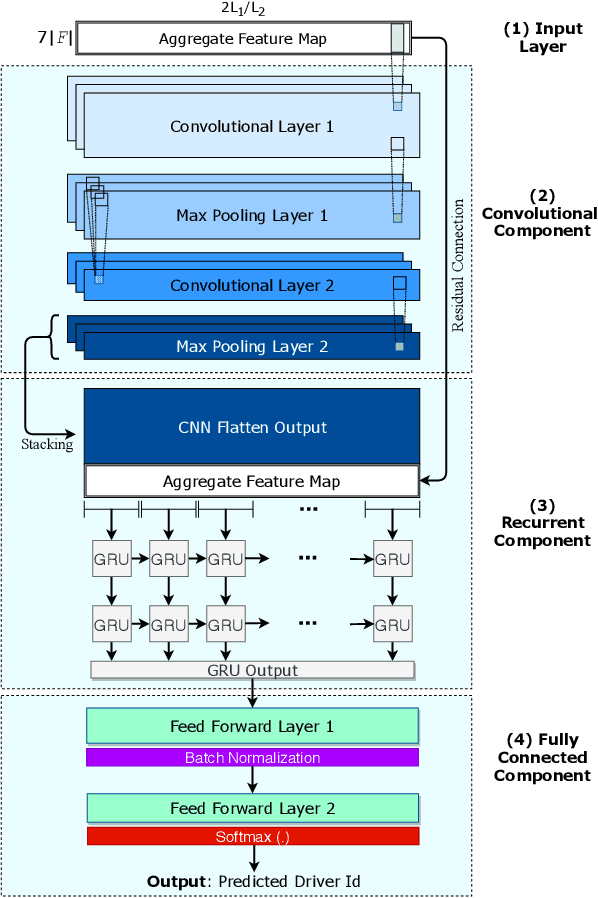
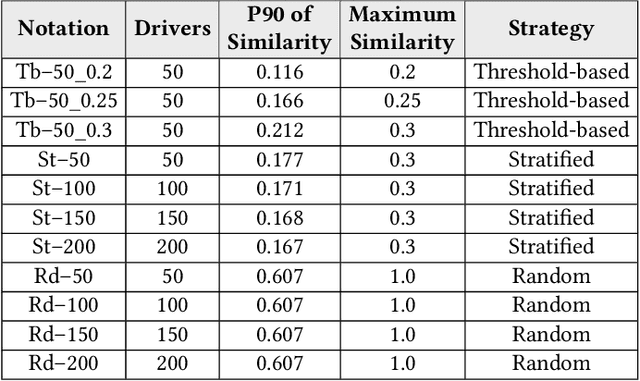
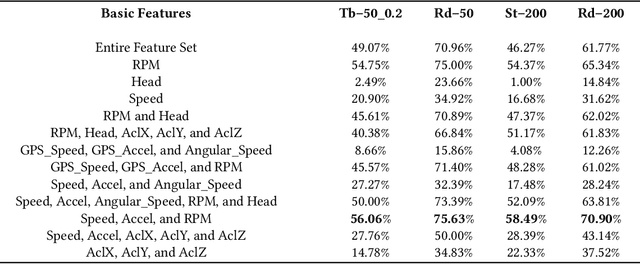
Identifying driving styles is the task of analyzing the behavior of drivers in order to capture variations that will serve to discriminate different drivers from each other. This task has become a prerequisite for a variety of applications, including usage-based insurance, driver coaching, driver action prediction, and even in designing autonomous vehicles; because driving style encodes essential information needed by these applications. In this paper, we present a deep-neural-network architecture, we term D-CRNN, for building high-fidelity representations for driving style, that combine the power of convolutional neural networks (CNN) and recurrent neural networks (RNN). Using CNN, we capture semantic patterns of driver behavior from trajectories (such as a turn or a braking event). We then find temporal dependencies between these semantic patterns using RNN to encode driving style. We demonstrate the effectiveness of these techniques for driver identification by learning driving style through extensive experiments conducted on several large, real-world datasets, and comparing the results with the state-of-the-art deep-learning and non-deep-learning solutions. These experiments also demonstrate a useful example of bias removal, by presenting how we preprocess the input data by sampling dissimilar trajectories for each driver to prevent spatial memorization. Finally, this paper presents an analysis of the contribution of different attributes for driver identification; we find that engine RPM, Speed, and Acceleration are the best combination of features.
A Tight Bound for Stochastic Submodular Cover
Feb 01, 2021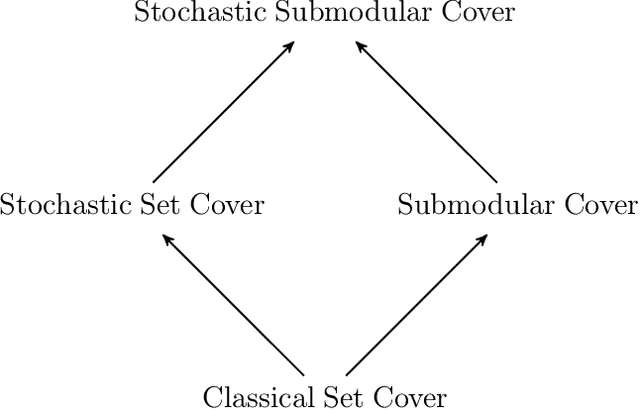

We show that the Adaptive Greedy algorithm of Golovin and Krause (2011) achieves an approximation bound of $(\ln (Q/\eta)+1)$ for Stochastic Submodular Cover: here $Q$ is the "goal value" and $\eta$ is the smallest non-zero marginal increase in utility deliverable by an item. (For integer-valued utility functions, we show a bound of $H(Q)$, where $H(Q)$ is the $Q^{th}$ Harmonic number.) Although this bound was claimed by Golovin and Krause in the original version of their paper, the proof was later shown to be incorrect by Nan and Saligrama (2017). The subsequent corrected proof of Golovin and Krause (2017) gives a quadratic bound of $(\ln(Q/\eta) + 1)^2$. Other previous bounds for the problem are $56(\ln(Q/\eta) + 1)$, implied by work of Im et al. (2016) on a related problem, and $k(\ln (Q/\eta)+1)$, due to Deshpande et al. (2016) and Hellerstein and Kletenik (2018), where $k$ is the number of states. Our bound generalizes the well-known $(\ln~m + 1)$ approximation bound on the greedy algorithm for the classical Set Cover problem, where $m$ is the size of the ground set.