 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Combinatorial Brain Surgeon: Pruning Weights That Cancel One Another in Neural Networks
Mar 12, 2022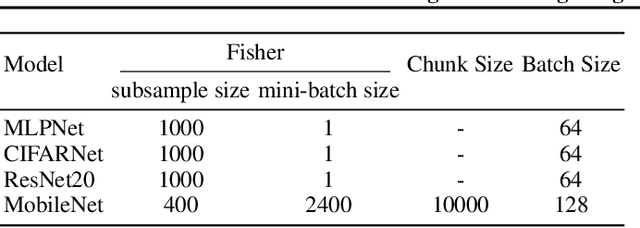
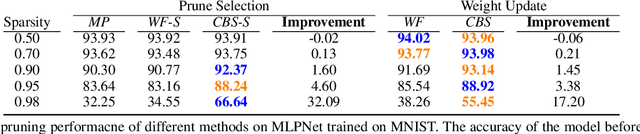
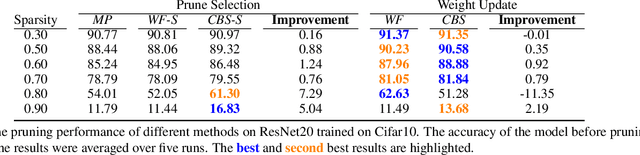
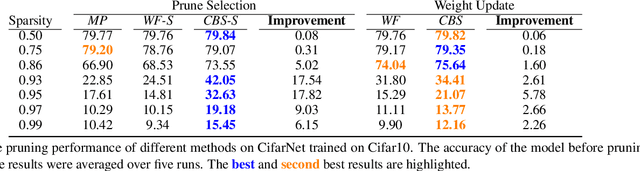
Neural networks tend to achieve better accuracy with training if they are larger -- even if the resulting models are overparameterized. Nevertheless, carefully removing such excess parameters before, during, or after training may also produce models with similar or even improved accuracy. In many cases, that can be curiously achieved by heuristics as simple as removing a percentage of the weights with the smallest absolute value -- even though magnitude is not a perfect proxy for weight relevance. With the premise that obtaining significantly better performance from pruning depends on accounting for the combined effect of removing multiple weights, we revisit one of the classic approaches for impact-based pruning: the Optimal Brain Surgeon(OBS). We propose a tractable heuristic for solving the combinatorial extension of OBS, in which we select weights for simultaneous removal, as well as a systematic update of the remaining weights. Our selection method outperforms other methods under high sparsity, and the weight update is advantageous even when combined with the other methods.
Implicit-PDF: Non-Parametric Representation of Probability Distributions on the Rotation Manifold
Jun 10, 2021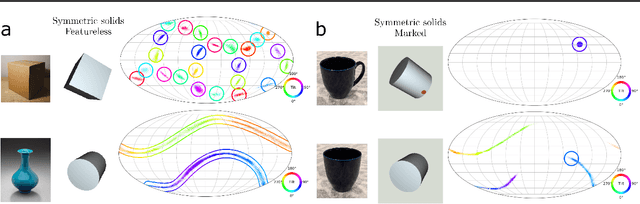
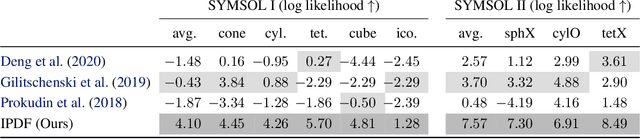
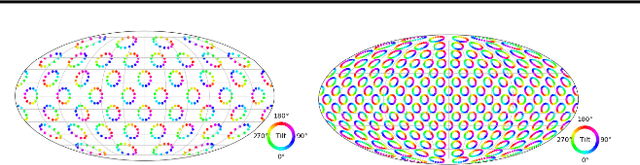
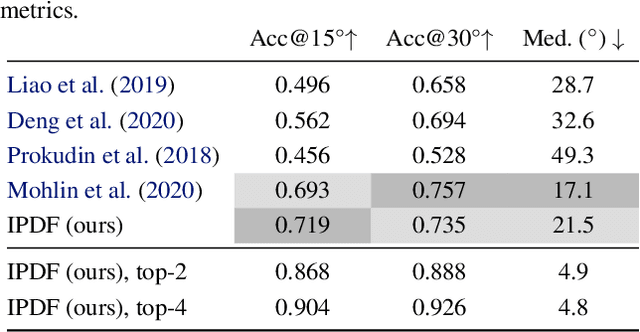
Single image pose estimation is a fundamental problem in many vision and robotics tasks, and existing deep learning approaches suffer by not completely modeling and handling: i) uncertainty about the predictions, and ii) symmetric objects with multiple (sometimes infinite) correct poses. To this end, we introduce a method to estimate arbitrary, non-parametric distributions on SO(3). Our key idea is to represent the distributions implicitly, with a neural network that estimates the probability given the input image and a candidate pose. Grid sampling or gradient ascent can be used to find the most likely pose, but it is also possible to evaluate the probability at any pose, enabling reasoning about symmetries and uncertainty. This is the most general way of representing distributions on manifolds, and to showcase the rich expressive power, we introduce a dataset of challenging symmetric and nearly-symmetric objects. We require no supervision on pose uncertainty -- the model trains only with a single pose per example. Nonetheless, our implicit model is highly expressive to handle complex distributions over 3D poses, while still obtaining accurate pose estimation on standard non-ambiguous environments, achieving state-of-the-art performance on Pascal3D+ and ModelNet10-SO(3) benchmarks.
Balancing Robustness and Sensitivity using Feature Contrastive Learning
May 19, 2021
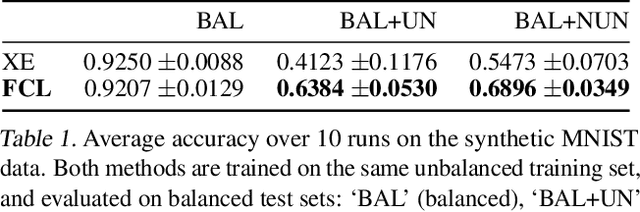
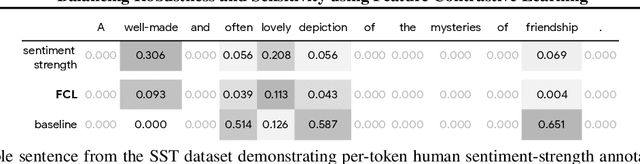
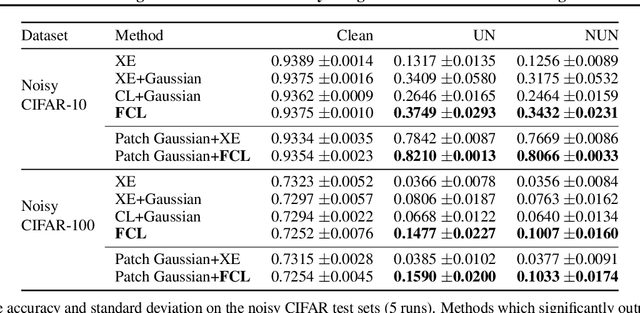
It is generally believed that robust training of extremely large networks is critical to their success in real-world applications. However, when taken to the extreme, methods that promote robustness can hurt the model's sensitivity to rare or underrepresented patterns. In this paper, we discuss this trade-off between sensitivity and robustness to natural (non-adversarial) perturbations by introducing two notions: contextual feature utility and contextual feature sensitivity. We propose Feature Contrastive Learning (FCL) that encourages a model to be more sensitive to the features that have higher contextual utility. Empirical results demonstrate that models trained with FCL achieve a better balance of robustness and sensitivity, leading to improved generalization in the presence of noise on both vision and NLP datasets.
Balancing Constraints and Submodularity in Data Subset Selection
Apr 26, 2021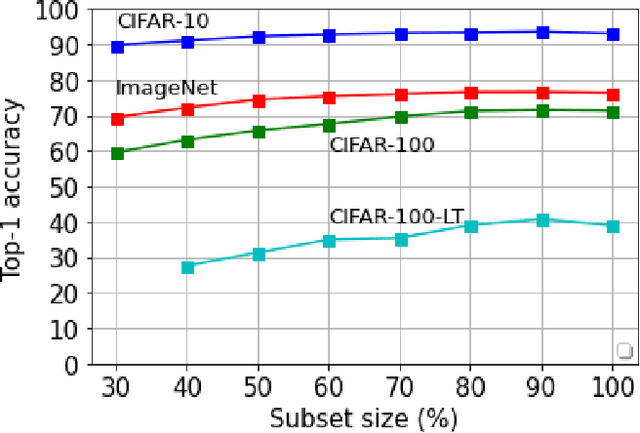
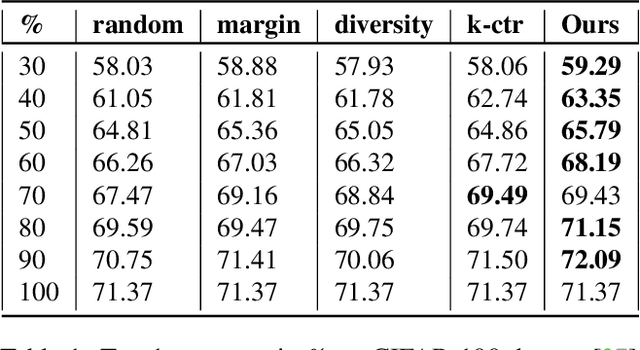
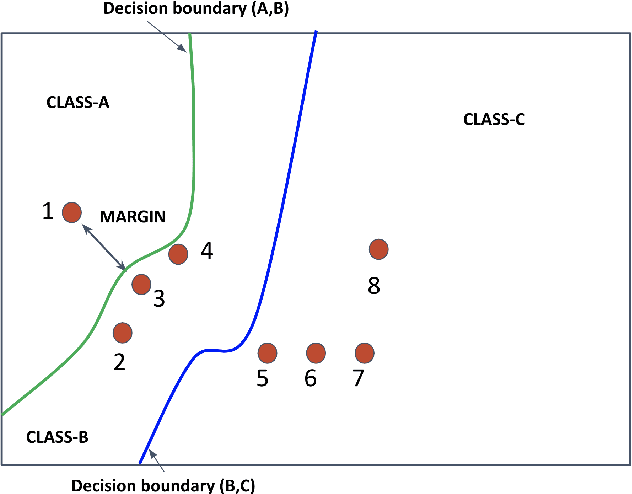
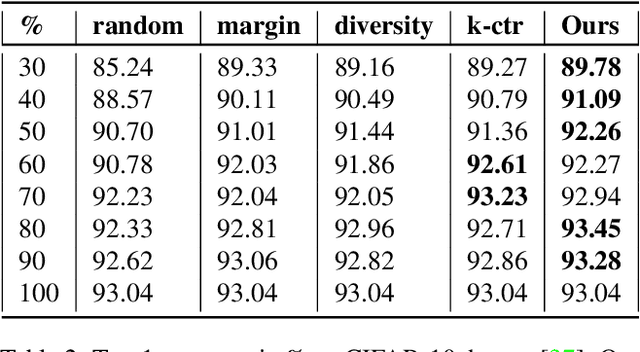
Deep learning has yielded extraordinary results in vision and natural language processing, but this achievement comes at a cost. Most deep learning models require enormous resources during training, both in terms of computation and in human labeling effort. In this paper, we show that one can achieve similar accuracy to traditional deep-learning models, while using less training data. Much of the previous work in this area relies on using uncertainty or some form of diversity to select subsets of a larger training set. Submodularity, a discrete analogue of convexity, has been exploited to model diversity in various settings including data subset selection. In contrast to prior methods, we propose a novel diversity driven objective function, and balancing constraints on class labels and decision boundaries using matroids. This allows us to use efficient greedy algorithms with approximation guarantees for subset selection. We outperform baselines on standard image classification datasets such as CIFAR-10, CIFAR-100, and ImageNet. In addition, we also show that the proposed balancing constraints can play a key role in boosting the performance in long-tailed datasets such as CIFAR-100-LT.
There and back again: Cycle consistency across sets for isolating factors of variation
Mar 04, 2021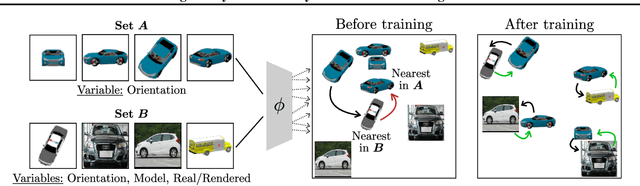



Representational learning hinges on the task of unraveling the set of underlying explanatory factors of variation in data. In this work, we operate in the setting where limited information is known about the data in the form of groupings, or set membership, where the underlying factors of variation is restricted to a subset. Our goal is to learn representations which isolate the factors of variation that are common across the groupings. Our key insight is the use of cycle consistency across sets(CCS) between the learned embeddings of images belonging to different sets. In contrast to other methods utilizing set supervision, CCS can be applied with significantly fewer constraints on the factors of variation, across a remarkably broad range of settings, and only utilizing set membership for some fraction of the training data. By curating datasets from Shapes3D, we quantify the effectiveness of CCS through mutual information between the learned representations and the known generative factors. In addition, we demonstrate the applicability of CCS to the tasks of digit style isolation and synthetic-to-real object pose transfer and compare to generative approaches utilizing the same supervision.
Scaling Up Exact Neural Network Compression by ReLU Stability
Feb 15, 2021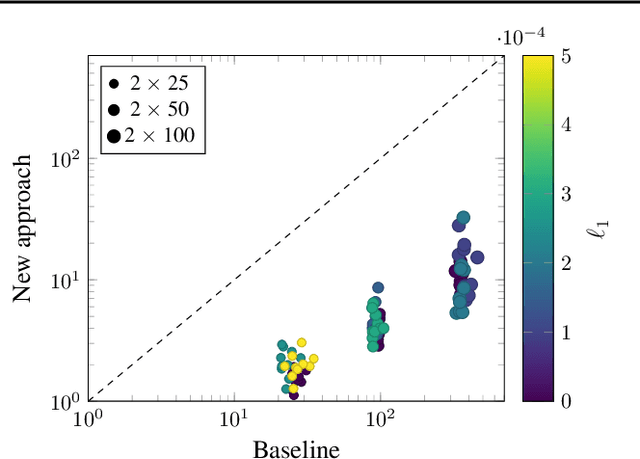
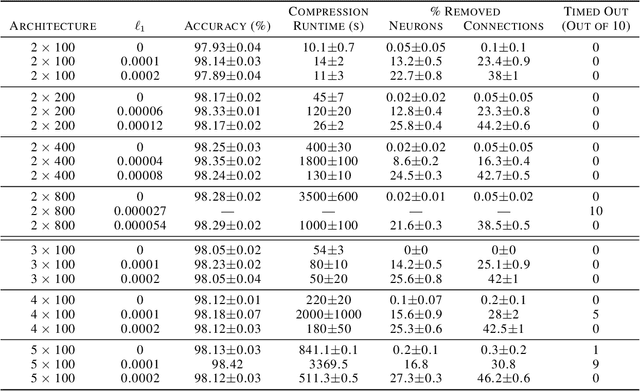
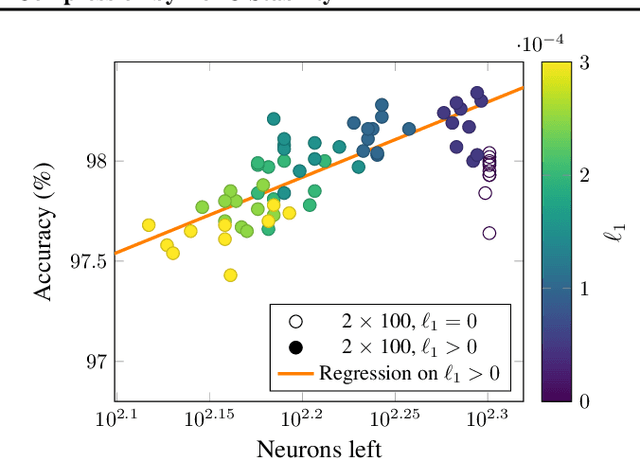
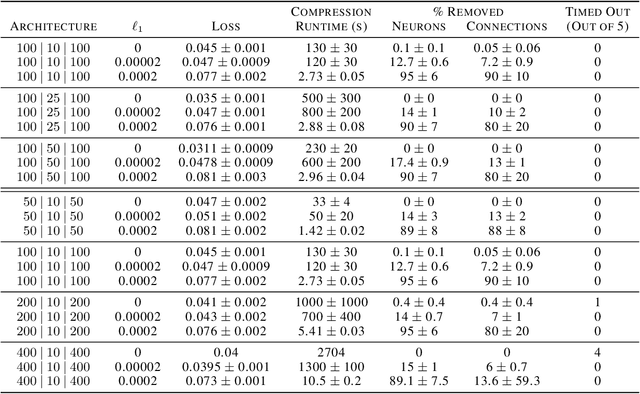
We can compress a neural network while exactly preserving its underlying functionality with respect to a given input domain if some of its neurons are stable. However, current approaches to determine the stability of neurons in networks with Rectified Linear Unit (ReLU) activations require solving or finding a good approximation to multiple discrete optimization problems. In this work, we introduce an algorithm based on solving a single optimization problem to identify all stable neurons. Our approach is on median 21 times faster than the state-of-art method, which allows us to explore exact compression on deeper (5 x 100) and wider (2 x 800) networks within minutes. For classifiers trained under an amount of L1 regularization that does not worsen accuracy, we can remove up to 40% of the connections.
Kernelized Classification in Deep Networks
Dec 08, 2020

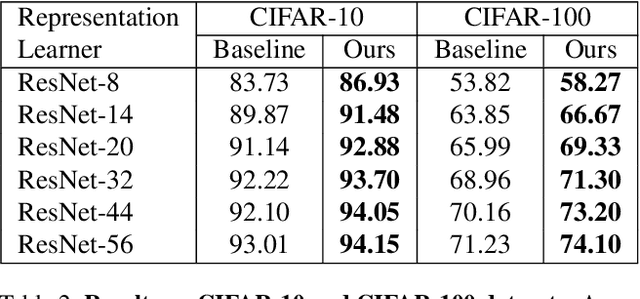
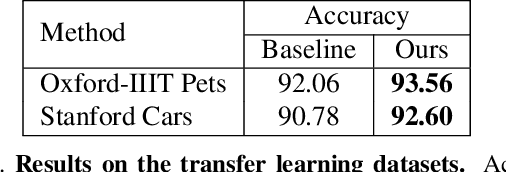
In this paper, we propose a kernelized classification layer for deep networks. Although conventional deep networks introduce an abundance of nonlinearity for representation (feature) learning, they almost universally use a linear classifier on the learned feature vectors. We introduce a nonlinear classification layer by using the kernel trick on the softmax cross-entropy loss function during training and the scorer function during testing. Furthermore, we study the choice of kernel functions one could use with this framework and show that the optimal kernel function for a given problem can be learned automatically within the deep network itself using the usual backpropagation and gradient descent methods. To this end, we exploit a classic mathematical result on the positive definite kernels on the unit n-sphere embedded in the (n+1)-dimensional Euclidean space. We show the usefulness of the proposed nonlinear classification layer on several vision datasets and tasks.
Mapping of Sparse 3D Data using Alternating Projection
Oct 09, 2020
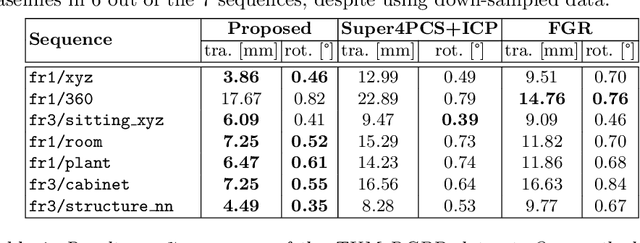
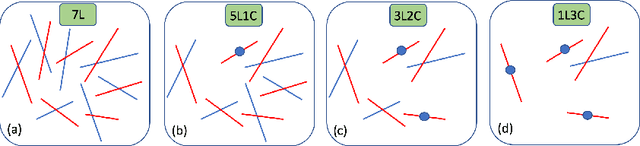
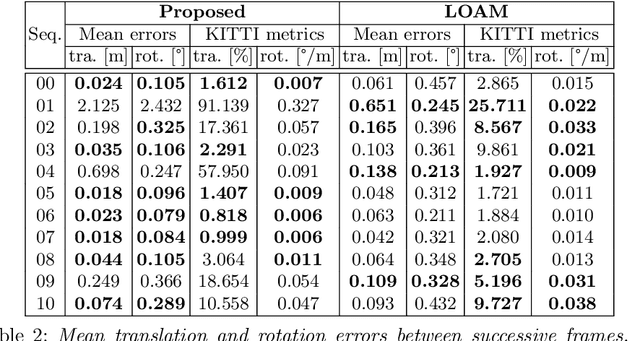
We propose a novel technique to register sparse 3D scans in the absence of texture. While existing methods such as KinectFusion or Iterative Closest Points (ICP) heavily rely on dense point clouds, this task is particularly challenging under sparse conditions without RGB data. Sparse texture-less data does not come with high-quality boundary signal, and this prohibits the use of correspondences from corners, junctions, or boundary lines. Moreover, in the case of sparse data, it is incorrect to assume that the same point will be captured in two consecutive scans. We take a different approach and first re-parameterize the point-cloud using a large number of line segments. In this re-parameterized data, there exists a large number of line intersection (and not correspondence) constraints that allow us to solve the registration task. We propose the use of a two-step alternating projection algorithm by formulating the registration as the simultaneous satisfaction of intersection and rigidity constraints. The proposed approach outperforms other top-scoring algorithms on both Kinect and LiDAR datasets. In Kinect, we can use 100X downsampled sparse data and still outperform competing methods operating on full-resolution data.
Lossless Compression of Deep Neural Networks
Feb 22, 2020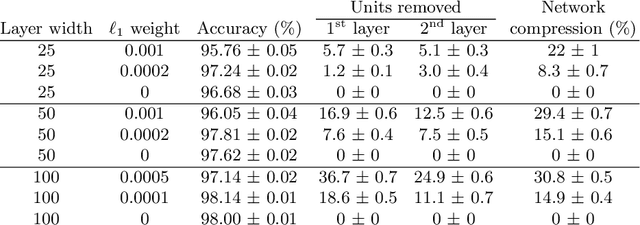

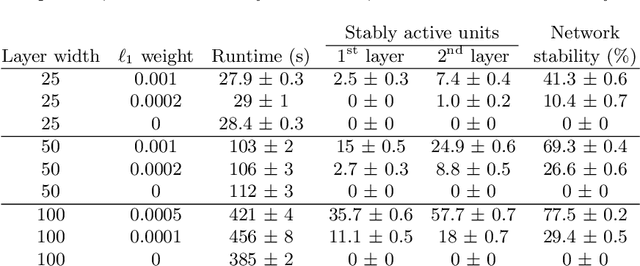
Deep neural networks have been successful in many predictive modeling tasks, such as image and language recognition, where large neural networks are often used to obtain good accuracy. Consequently, it is challenging to deploy these networks under limited computational resources, such as in mobile devices. In this work, we introduce an algorithm that removes units and layers of a neural network while not changing the output that is produced, which thus implies a lossless compression. This algorithm, which we denote as LEO (Lossless Expressiveness Optimization), relies on Mixed-Integer Linear Programming (MILP) to identify Rectified Linear Units (ReLUs) with linear behavior over the input domain. By using L1 regularization to induce such behavior, we can benefit from training over a larger architecture than we would later use in the environment where the trained neural network is deployed.
Can generalised relative pose estimation solve sparse 3D registration?
Jun 13, 2019
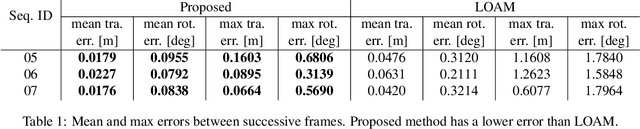
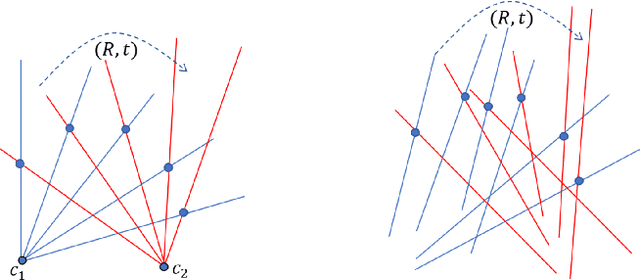
Popular 3D scan registration projects, such as Stanford digital Michelangelo or KinectFusion, exploit the high-resolution sensor data for scan alignment. It is particularly challenging to solve the registration of sparse 3D scans in the absence of RGB components. In this case, we can not establish point correspondences since the same 3D point cannot be captured in two successive scans. In contrast to correspondence based methods, we take a different viewpoint and formulate the sparse 3D registration problem based on the constraints from the intersection of line segments from adjacent scans. We obtain the line segments by modeling every horizontal and vertical scan-line as piece-wise linear segments. We propose a new alternating projection algorithm for solving the scan alignment problem using line intersection constraints. We develop two new minimal solvers for scan alignment in the presence of plane correspondences: 1) 3 line intersections and 1 plane correspondence, and 2) 1 line intersection and 2 plane correspondences. We outperform other competing methods on Kinect and LiDAR datasets.