 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Tokens to Steps: Verification-Aware Speculative Decoding for Efficient Multi-Step Reasoning
Apr 16, 2026Speculative decoding (SD) accelerates large language model inference by allowing a lightweight draft model to propose outputs that a stronger target model verifies. However, its token-centric nature allows erroneous steps to propagate. Prior approaches mitigate this using external reward models, but incur additional latency, computational overhead, and limit generalizability. We propose SpecGuard, a verification-aware speculative decoding framework that performs step-level verification using only model-internal signals. At each step, SpecGuard samples multiple draft candidates and selects the most consistent step, which is then validated using an ensemble of two lightweight model-internal signals: (i) an attention-based grounding score that measures attribution to the input and previously accepted steps, and (ii) a log-probability-based score that captures token-level confidence. These signals jointly determine whether a step is accepted or recomputed using the target, allocating compute selectively. Experiments across a range of reasoning benchmarks show that SpecGuard improves accuracy by 3.6% while reducing latency by ~11%, outperforming both SD and reward-guided SD.
Sample Efficient Demonstration Selection for In-Context Learning
Jun 10, 2025



The in-context learning paradigm with LLMs has been instrumental in advancing a wide range of natural language processing tasks. The selection of few-shot examples (exemplars / demonstration samples) is essential for constructing effective prompts under context-length budget constraints. In this paper, we formulate the exemplar selection task as a top-m best arms identification problem. A key challenge in this setup is the exponentially large number of arms that need to be evaluated to identify the m-best arms. We propose CASE (Challenger Arm Sampling for Exemplar selection), a novel sample-efficient selective exploration strategy that maintains a shortlist of "challenger" arms, which are current candidates for the top-m arms. In each iteration, only one of the arms from this shortlist or the current topm set is pulled, thereby reducing sample complexity and, consequently, the number of LLM evaluations. Furthermore, we model the scores of exemplar subsets (arms) using a parameterized linear scoring function, leading to stochastic linear bandits setting. CASE achieves remarkable efficiency gains of up to 7x speedup in runtime while requiring 7x fewer LLM calls (87% reduction) without sacrificing performance compared to state-of-the-art exemplar selection methods. We release our code and data at https://github.com/kiranpurohit/CASE
EXPLORA: Efficient Exemplar Subset Selection for Complex Reasoning
Nov 06, 2024



Answering reasoning-based complex questions over text and hybrid sources, including tables, is a challenging task. Recent advances in large language models (LLMs) have enabled in-context learning (ICL), allowing LLMs to acquire proficiency in a specific task using only a few demonstration samples (exemplars). A critical challenge in ICL is the selection of optimal exemplars, which can be either task-specific (static) or test-example-specific (dynamic). Static exemplars provide faster inference times and increased robustness across a distribution of test examples. In this paper, we propose an algorithm for static exemplar subset selection for complex reasoning tasks. We introduce EXPLORA, a novel exploration method designed to estimate the parameters of the scoring function, which evaluates exemplar subsets without incorporating confidence information. EXPLORA significantly reduces the number of LLM calls to ~11% of those required by state-of-the-art methods and achieves a substantial performance improvement of 12.24%. We open-source our code and data (https://github.com/kiranpurohit/EXPLORA).
LearnDefend: Learning to Defend against Targeted Model-Poisoning Attacks on Federated Learning
May 03, 2023



Targeted model poisoning attacks pose a significant threat to federated learning systems. Recent studies show that edge-case targeted attacks, which target a small fraction of the input space are nearly impossible to counter using existing fixed defense strategies. In this paper, we strive to design a learned-defense strategy against such attacks, using a small defense dataset. The defense dataset can be collected by the central authority of the federated learning task, and should contain a mix of poisoned and clean examples. The proposed framework, LearnDefend, estimates the probability of a client update being malicious. The examples in defense dataset need not be pre-marked as poisoned or clean. We also learn a poisoned data detector model which can be used to mark each example in the defense dataset as clean or poisoned. We estimate the poisoned data detector and the client importance models in a coupled optimization approach. Our experiments demonstrate that LearnDefend is capable of defending against state-of-the-art attacks where existing fixed defense strategies fail. We also show that LearnDefend is robust to size and noise in the marking of clean examples in the defense dataset.
Reproducibility Report: Contextualizing Hate Speech Classifiers with Post-hoc Explanation
May 24, 2021

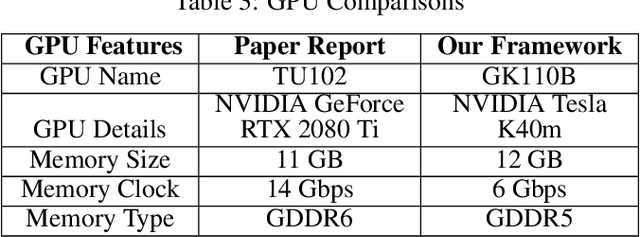
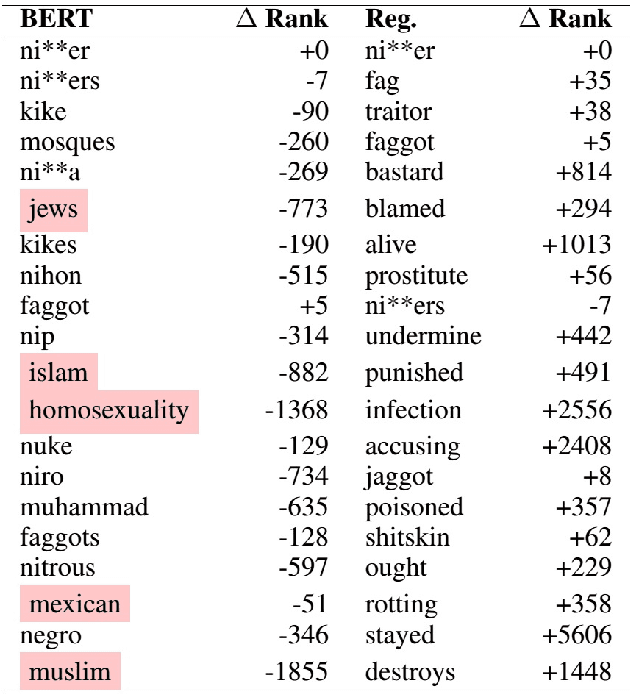
The presented report evaluates Contextualizing Hate Speech Classifiers with Post-hoc Explanation paper within the scope of ML Reproducibility Challenge 2020. Our work focuses on both aspects constituting the paper: the method itself and the validity of the stated results. In the following sections, we have described the paper, related works, algorithmic frameworks, our experiments and evaluations.