 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust High-Resolution Video Matting with Temporal Guidance
Aug 25, 2021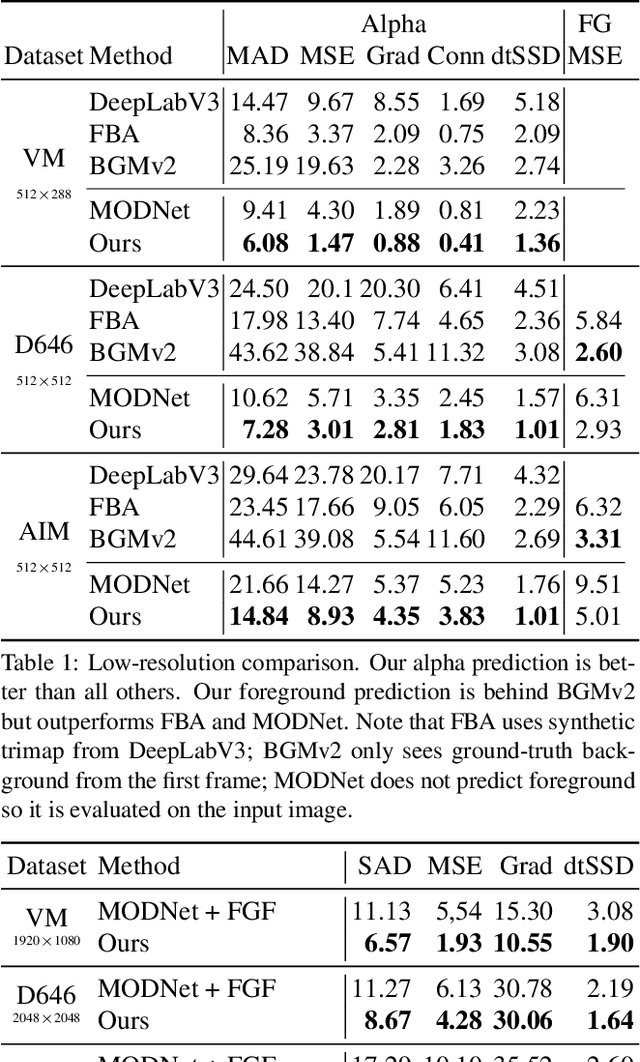
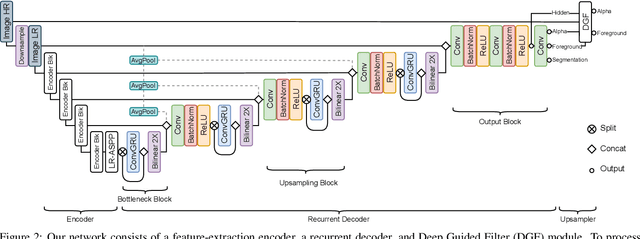
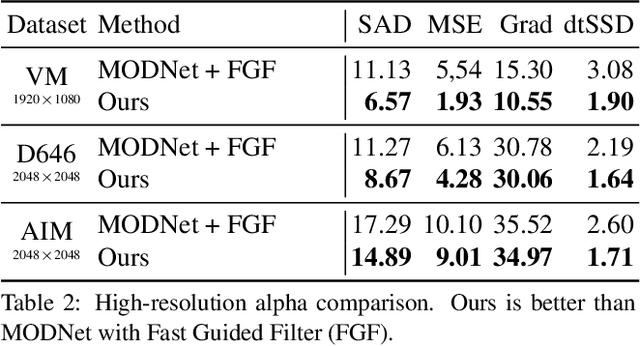
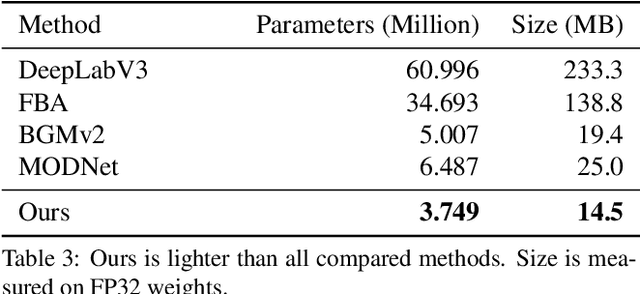
We introduce a robust, real-time, high-resolution human video matting method that achieves new state-of-the-art performance. Our method is much lighter than previous approaches and can process 4K at 76 FPS and HD at 104 FPS on an Nvidia GTX 1080Ti GPU. Unlike most existing methods that perform video matting frame-by-frame as independent images, our method uses a recurrent architecture to exploit temporal information in videos and achieves significant improvements in temporal coherence and matting quality. Furthermore, we propose a novel training strategy that enforces our network on both matting and segmentation objectives. This significantly improves our model's robustness. Our method does not require any auxiliary inputs such as a trimap or a pre-captured background image, so it can be widely applied to existing human matting applications.
A Light Stage on Every Desk
May 17, 2021
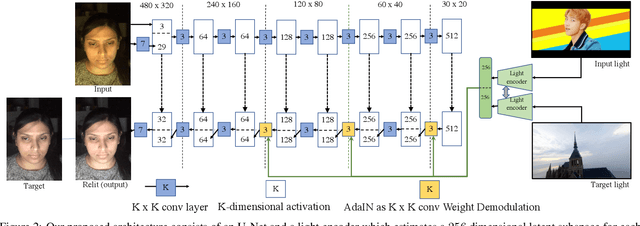
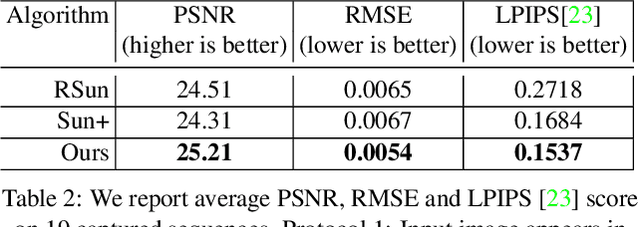
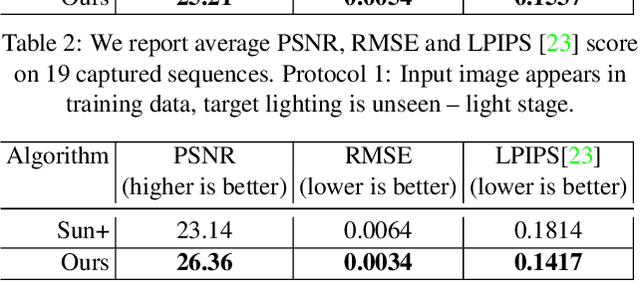
Every time you sit in front of a TV or monitor, your face is actively illuminated by time-varying patterns of light. This paper proposes to use this time-varying illumination for synthetic relighting of your face with any new illumination condition. In doing so, we take inspiration from the light stage work of Debevec et al., who first demonstrated the ability to relight people captured in a controlled lighting environment. Whereas existing light stages require expensive, room-scale spherical capture gantries and exist in only a few labs in the world, we demonstrate how to acquire useful data from a normal TV or desktop monitor. Instead of subjecting the user to uncomfortable rapidly flashing light patterns, we operate on images of the user watching a YouTube video or other standard content. We train a deep network on images plus monitor patterns of a given user and learn to predict images of that user under any target illumination (monitor pattern). Experimental evaluation shows that our method produces realistic relighting results. Video results are available at http://grail.cs.washington.edu/projects/Light_Stage_on_Every_Desk/.
Shape and Material Capture at Home
Apr 13, 2021

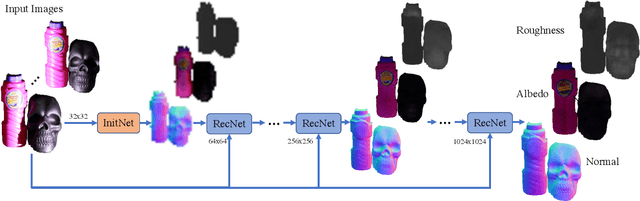

In this paper, we present a technique for estimating the geometry and reflectance of objects using only a camera, flashlight, and optionally a tripod. We propose a simple data capture technique in which the user goes around the object, illuminating it with a flashlight and capturing only a few images. Our main technical contribution is the introduction of a recursive neural architecture, which can predict geometry and reflectance at 2^{k}*2^{k} resolution given an input image at 2^{k}*2^{k} and estimated geometry and reflectance from the previous step at 2^{k-1}*2^{k-1}. This recursive architecture, termed RecNet, is trained with 256x256 resolution but can easily operate on 1024x1024 images during inference. We show that our method produces more accurate surface normal and albedo, especially in regions of specular highlights and cast shadows, compared to previous approaches, given three or fewer input images. For the video and code, please visit the project website http://dlichy.github.io/ShapeAndMaterialAtHome/.
Real-Time High-Resolution Background Matting
Dec 14, 2020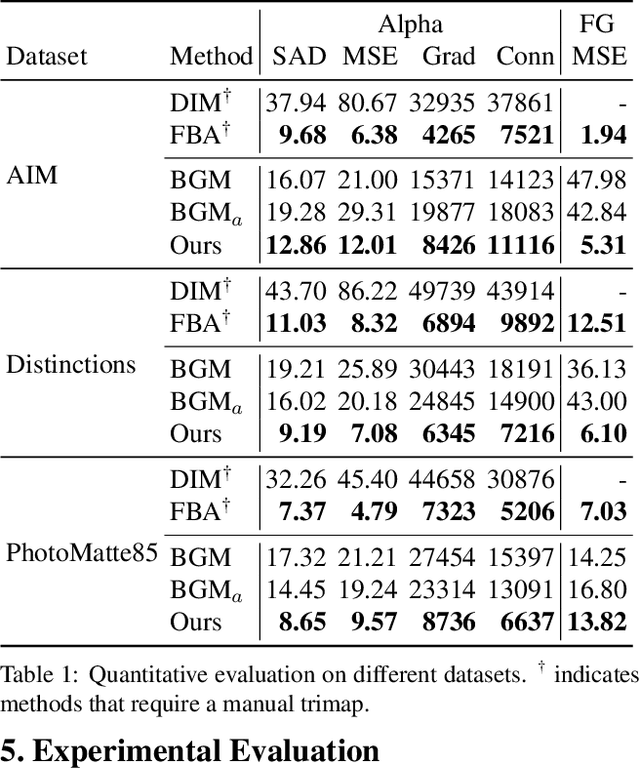

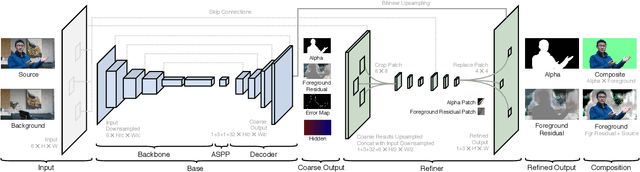
We introduce a real-time, high-resolution background replacement technique which operates at 30fps in 4K resolution, and 60fps for HD on a modern GPU. Our technique is based on background matting, where an additional frame of the background is captured and used in recovering the alpha matte and the foreground layer. The main challenge is to compute a high-quality alpha matte, preserving strand-level hair details, while processing high-resolution images in real-time. To achieve this goal, we employ two neural networks; a base network computes a low-resolution result which is refined by a second network operating at high-resolution on selective patches. We introduce two largescale video and image matting datasets: VideoMatte240K and PhotoMatte13K/85. Our approach yields higher quality results compared to the previous state-of-the-art in background matting, while simultaneously yielding a dramatic boost in both speed and resolution.
Background Matting: The World is Your Green Screen
Apr 10, 2020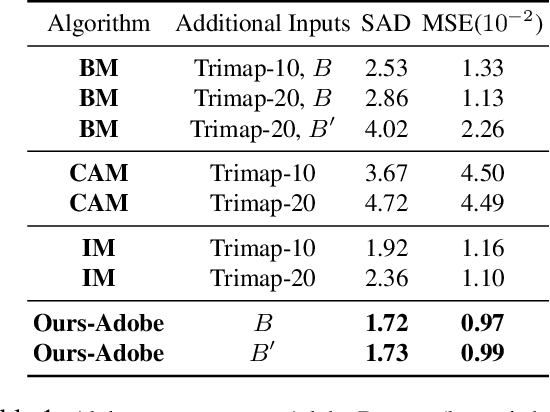
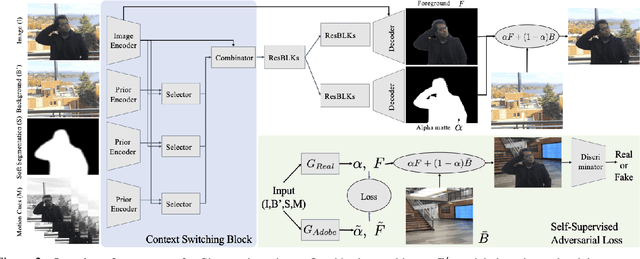
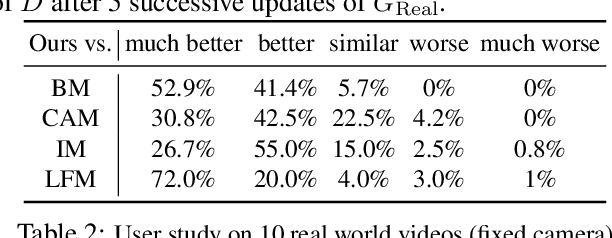

We propose a method for creating a matte -- the per-pixel foreground color and alpha -- of a person by taking photos or videos in an everyday setting with a handheld camera. Most existing matting methods require a green screen background or a manually created trimap to produce a good matte. Automatic, trimap-free methods are appearing, but are not of comparable quality. In our trimap free approach, we ask the user to take an additional photo of the background without the subject at the time of capture. This step requires a small amount of foresight but is far less time-consuming than creating a trimap. We train a deep network with an adversarial loss to predict the matte. We first train a matting network with supervised loss on ground truth data with synthetic composites. To bridge the domain gap to real imagery with no labeling, we train another matting network guided by the first network and by a discriminator that judges the quality of composites. We demonstrate results on a wide variety of photos and videos and show significant improvement over the state of the art.
Lifespan Age Transformation Synthesis
Mar 21, 2020

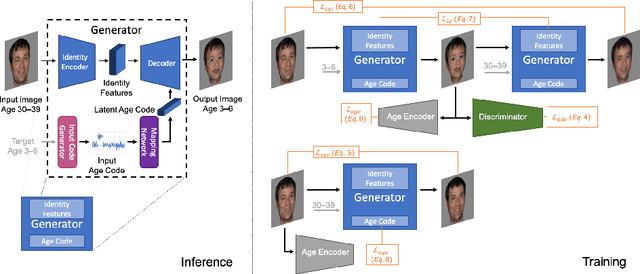
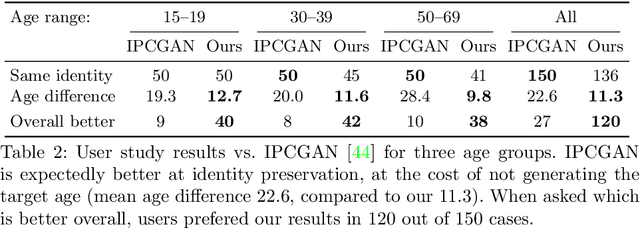
We address the problem of single photo age progression and regression-the prediction of how a person might look in the future, or how they looked in the past. Most existing aging methods are limited to changing the texture, overlooking transformations in head shape that occur during the human aging and growth process. This limits the applicability of previous methods to aging of adults to slightly older adults, and application of those methods to photos of children does not produce quality results. We propose a novel multi-domain image-to-image generative adversarial network architecture, whose learned latent space models a continuous bi-directional aging process. The network is trained on the FFHQ dataset, which we labeled for ages, gender, and semantic segmentation. Fixed age classes are used as anchors to approximate continuous age transformation. Our framework can predict a full head portrait for ages 0-70 from a single photo, modifying both texture and shape of the head. We demonstrate results on a wide variety of photos and datasets, and show significant improvement over the state of the art.
Neural Inverse Rendering of an Indoor Scene from a Single Image
Jan 08, 2019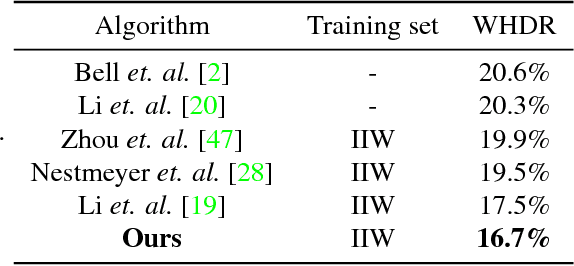
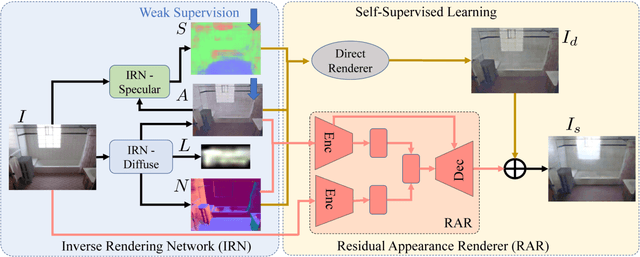


Inverse rendering aims to estimate physical scene attributes (e.g., reflectance, geometry, and lighting) from image(s). As a long-standing, highly ill-posed problem, inverse rendering has been studied primarily for single 3D objects or with methods that solve for only one of the scene attributes. To our knowledge, we are the first to propose a holistic approach for inverse rendering of an indoor scene from a single image with CNNs, which jointly estimates reflectance (albedo and gloss), surface normals and illumination. To address the lack of labeled real-world images, we create a large-scale synthetic dataset, named SUNCG-PBR, with physically-based rendering, which is a significant improvement over prior datasets. For fine-tuning on real images, we perform self-supervised learning using the reconstruction loss, which re-synthesizes the input images from the estimated components. To enable self-supervised learning on real data, our key contribution is the Residual Appearance Renderer (RAR), which can be trained to synthesize complex appearance effects (e.g., inter-reflection, cast shadows, near-field illumination, and realistic shading), which would be neglected otherwise. Experimental results show that our approach outperforms state-of-the-art methods, especially on real images.
SfSNet: Learning Shape, Reflectance and Illuminance of Faces in the Wild
Apr 19, 2018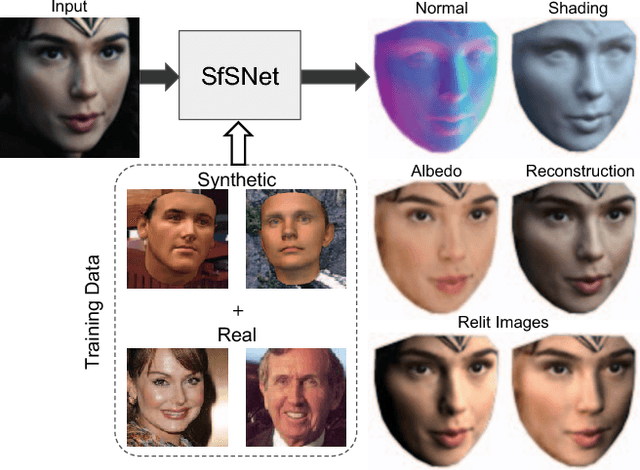
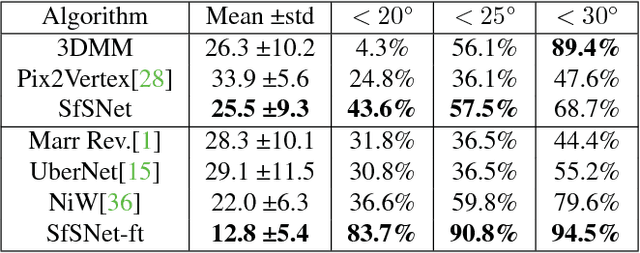
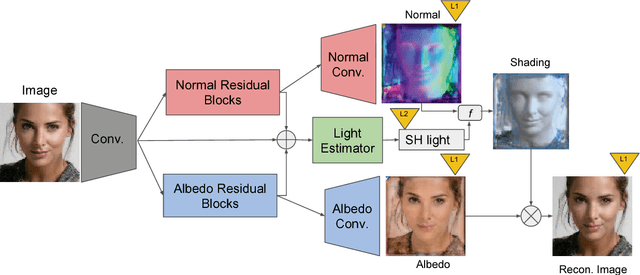
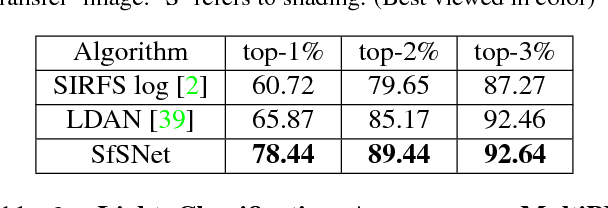
We present SfSNet, an end-to-end learning framework for producing an accurate decomposition of an unconstrained human face image into shape, reflectance and illuminance. SfSNet is designed to reflect a physical lambertian rendering model. SfSNet learns from a mixture of labeled synthetic and unlabeled real world images. This allows the network to capture low frequency variations from synthetic and high frequency details from real images through the photometric reconstruction loss. SfSNet consists of a new decomposition architecture with residual blocks that learns a complete separation of albedo and normal. This is used along with the original image to predict lighting. SfSNet produces significantly better quantitative and qualitative results than state-of-the-art methods for inverse rendering and independent normal and illumination estimation.
A New Rank Constraint on Multi-view Fundamental Matrices, and its Application to Camera Location Recovery
Feb 10, 2017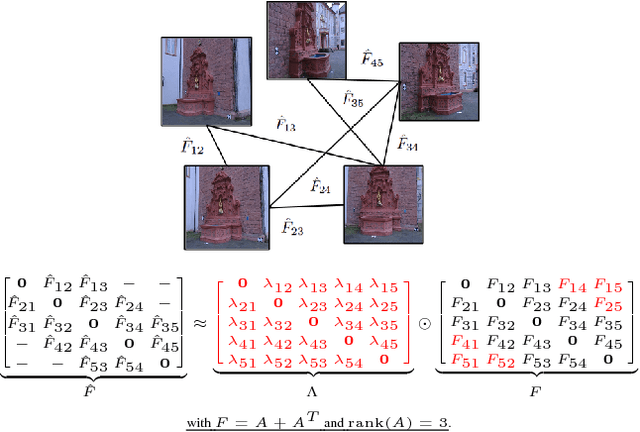
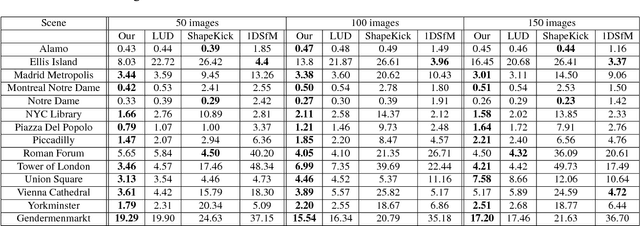
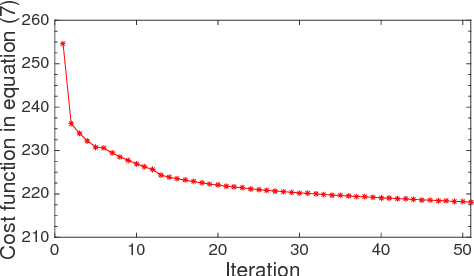
Accurate estimation of camera matrices is an important step in structure from motion algorithms. In this paper we introduce a novel rank constraint on collections of fundamental matrices in multi-view settings. We show that in general, with the selection of proper scale factors, a matrix formed by stacking fundamental matrices between pairs of images has rank 6. Moreover, this matrix forms the symmetric part of a rank 3 matrix whose factors relate directly to the corresponding camera matrices. We use this new characterization to produce better estimations of fundamental matrices by optimizing an L1-cost function using Iterative Re-weighted Least Squares and Alternate Direction Method of Multiplier. We further show that this procedure can improve the recovery of camera locations, particularly in multi-view settings in which fewer images are available.
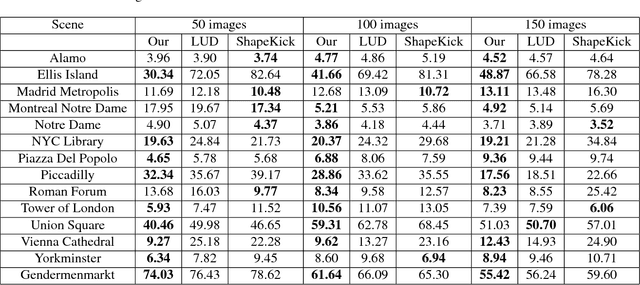
Solving Uncalibrated Photometric Stereo Using Fewer Images by Jointly Optimizing Low-rank Matrix Completion and Integrability
Feb 02, 2017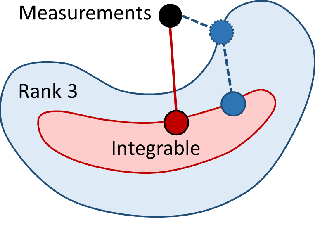
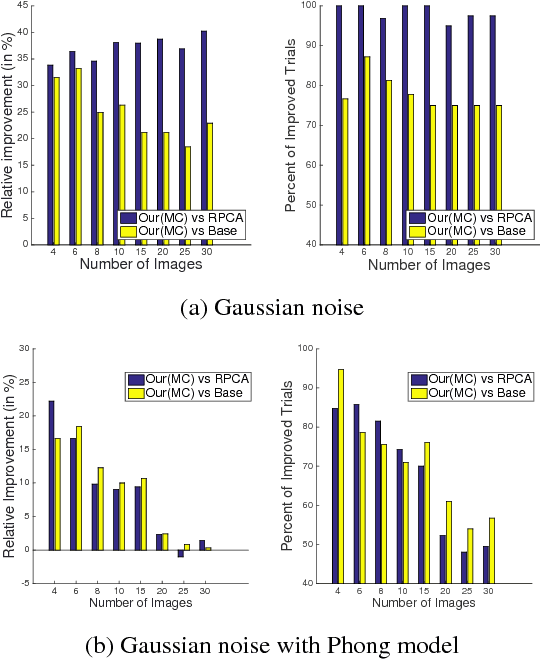
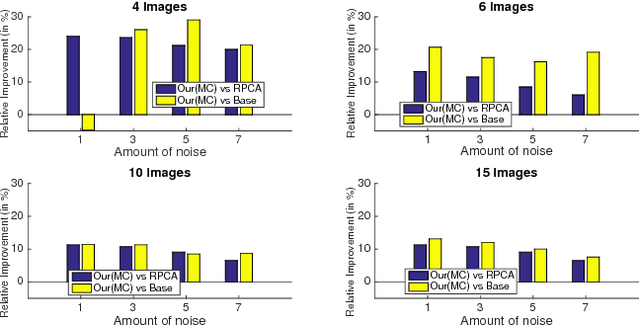
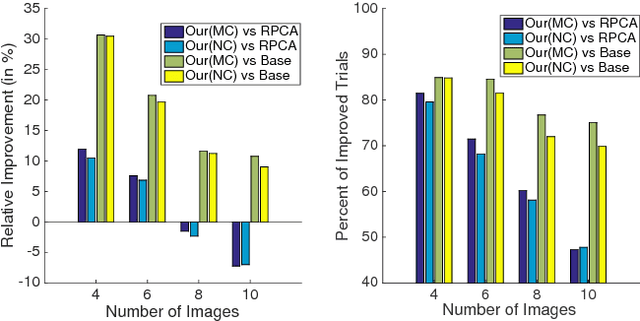
We introduce a new, integrated approach to uncalibrated photometric stereo. We perform 3D reconstruction of Lambertian objects using multiple images produced by unknown, directional light sources. We show how to formulate a single optimization that includes rank and integrability constraints, allowing also for missing data. We then solve this optimization using the Alternate Direction Method of Multipliers (ADMM). We conduct extensive experimental evaluation on real and synthetic data sets. Our integrated approach is particularly valuable when performing photometric stereo using as few as 4-6 images, since the integrability constraint is capable of improving estimation of the linear subspace of possible solutions. We show good improvements over prior work in these cases.