 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLP Service APIs and Models for Efficient Registration of New Clients
Oct 04, 2020
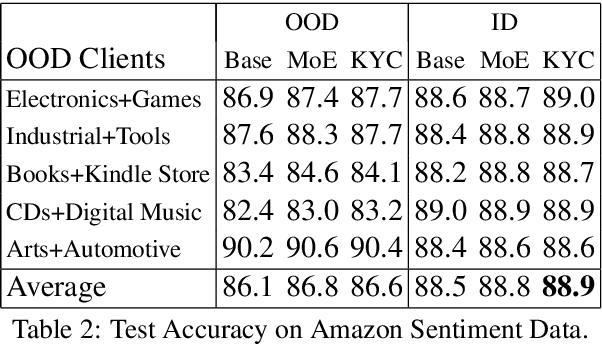
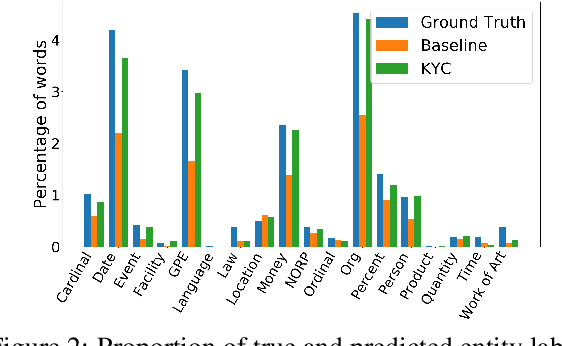
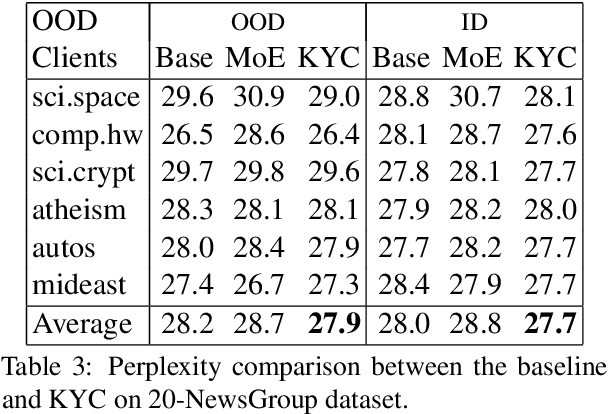
State-of-the-art NLP inference uses enormous neural architectures and models trained for GPU-months, well beyond the reach of most consumers of NLP. This has led to one-size-fits-all public API-based NLP service models by major AI companies, serving large numbers of clients. Neither (hardware deficient) clients nor (heavily subscribed) servers can afford traditional fine tuning. Many clients own little or no labeled data. We initiate a study of adaptation of centralized NLP services to clients, and present one practical and lightweight approach. Each client uses an unsupervised, corpus-based sketch to register to the service. The server uses an auxiliary network to map the sketch to an abstract vector representation, which then informs the main labeling network. When a new client registers with its sketch, it gets immediate accuracy benefits. We demonstrate the success of the proposed architecture using sentiment labeling, NER, and predictive language modeling
IMoJIE: Iterative Memory-Based Joint Open Information Extraction
May 17, 2020
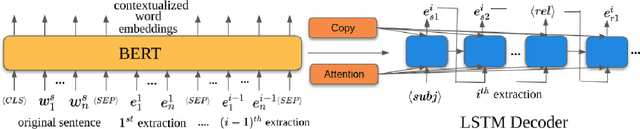


While traditional systems for Open Information Extraction were statistical and rule-based, recently neural models have been introduced for the task. Our work builds upon CopyAttention, a sequence generation OpenIE model (Cui et. al., 2018). Our analysis reveals that CopyAttention produces a constant number of extractions per sentence, and its extracted tuples often express redundant information. We present IMoJIE, an extension to CopyAttention, which produces the next extraction conditioned on all previously extracted tuples. This approach overcomes both shortcomings of CopyAttention, resulting in a variable number of diverse extractions per sentence. We train IMoJIE on training data bootstrapped from extractions of several non-neural systems, which have been automatically filtered to reduce redundancy and noise. IMoJIE outperforms CopyAttention by about 18 F1 pts, and a BERT-based strong baseline by 2 F1 pts, establishing a new state of the art for the task.
Knowledge Base Completion: Baseline strikes back (Again)
May 02, 2020
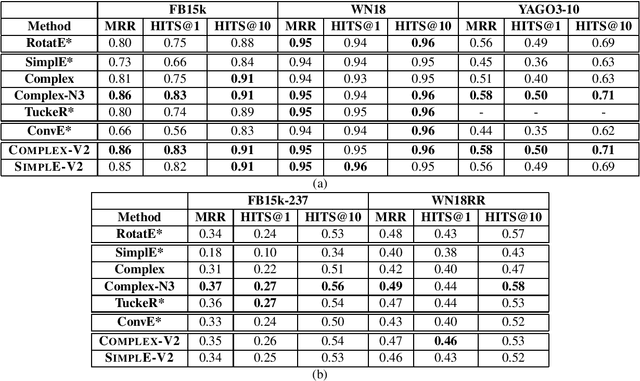
Knowledge Base Completion has been a very active area recently, where multiplicative models have generally outperformed additive and other deep learning methods -- like GNN, CNN, path-based models. Several recent KBC papers propose architectural changes, new training methods, or even a new problem reformulation. They evaluate their methods on standard benchmark datasets - FB15k, FB15k-237, WN18, WN18RR, and Yago3-10. Recently, some papers discussed how 1-N scoring can speed up training and evaluation. In this paper, we discuss how by just applying this training regime to a basic model like Complex gives near SOTA performance on all the datasets -- we call this model COMPLEX-V2. We also highlight how various multiplicative methods recently proposed in literature benefit from this trick and become indistinguishable in terms of performance on most datasets. This paper calls for a reassessment of their individual value, in light of these findings.
Temporal Knowledge Base Completion: New Algorithms and Evaluation Protocols
May 02, 2020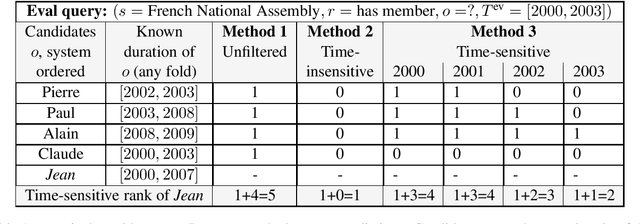
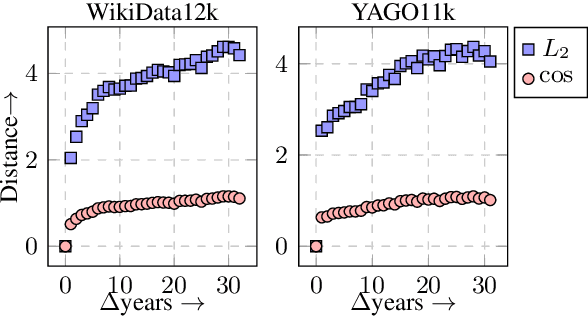
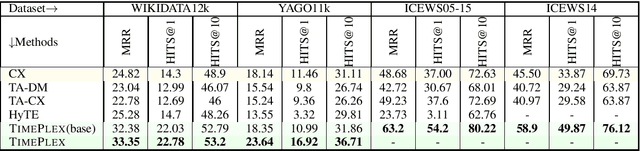
Temporal knowledge bases associate relational (s,r,o) triples with a set of times (or a single time instant) when the relation is valid. While time-agnostic KB completion (KBC) has witnessed significant research, temporal KB completion (TKBC) is in its early days. In this paper, we consider predicting missing entities (link prediction) and missing time intervals (time prediction) as joint TKBC tasks where entities, relations, and time are all embedded in a uniform, compatible space. We present TIMEPLEX, a novel time-aware KBC method, that also automatically exploits the recurrent nature of some relations and temporal interactions between pairs of relations. TIMEPLEX achieves state-of-the-art performance on both prediction tasks. We also find that existing TKBC models heavily overestimate link prediction performance due to imperfect evaluation mechanisms. In response, we propose improved TKBC evaluation protocols for both link and time prediction tasks, dealing with subtle issues that arise from the partial overlap of time intervals in gold instances and system predictions.
Scene Graph based Image Retrieval -- A case study on the CLEVR Dataset
Nov 03, 2019With the prolification of multimodal interaction in various domains, recently there has been much interest in text based image retrieval in the computer vision community. However most of the state of the art techniques model this problem in a purely neural way, which makes it difficult to incorporate pragmatic strategies in searching a large scale catalog especially when the search requirements are insufficient and the model needs to resort to an interactive retrieval process through multiple iterations of question-answering. Motivated by this, we propose a neural-symbolic approach for a one-shot retrieval of images from a large scale catalog, given the caption description. To facilitate this, we represent the catalog and caption as scene-graphs and model the retrieval task as a learnable graph matching problem, trained end-to-end with a REINFORCE algorithm. Further, we briefly describe an extension of this pipeline to an iterative retrieval framework, based on interactive questioning and answering.
Topic Sensitive Attention on Generic Corpora Corrects Sense Bias in Pretrained Embeddings
Jul 24, 2019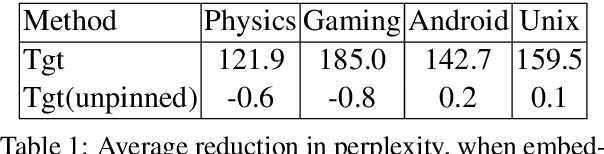
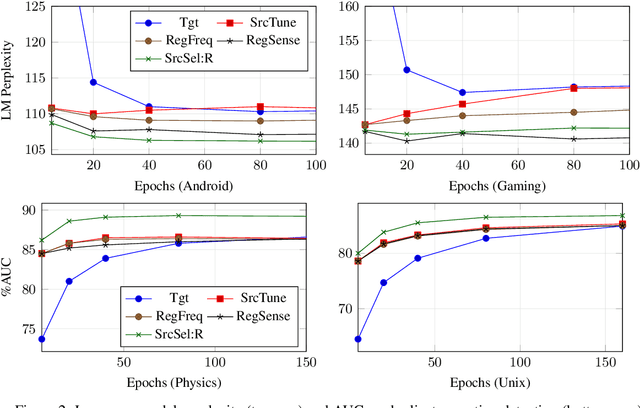
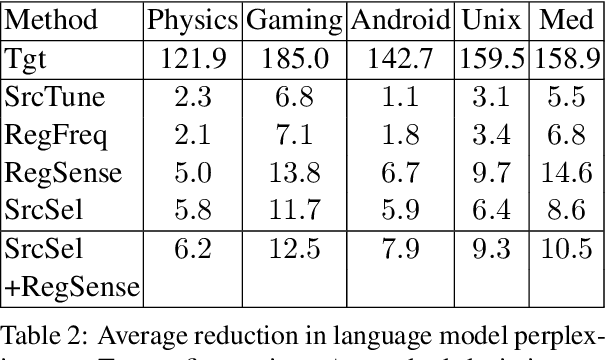
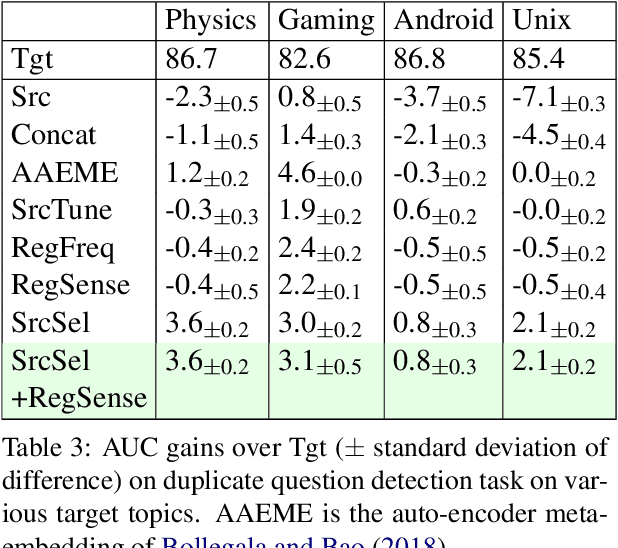
Given a small corpus $\mathcal D_T$ pertaining to a limited set of focused topics, our goal is to train embeddings that accurately capture the sense of words in the topic in spite of the limited size of $\mathcal D_T$. These embeddings may be used in various tasks involving $\mathcal D_T$. A popular strategy in limited data settings is to adapt pre-trained embeddings $\mathcal E$ trained on a large corpus. To correct for sense drift, fine-tuning, regularization, projection, and pivoting have been proposed recently. Among these, regularization informed by a word's corpus frequency performed well, but we improve upon it using a new regularizer based on the stability of its cooccurrence with other words. However, a thorough comparison across ten topics, spanning three tasks, with standardized settings of hyper-parameters, reveals that even the best embedding adaptation strategies provide small gains beyond well-tuned baselines, which many earlier comparisons ignored. In a bold departure from adapting pretrained embeddings, we propose using $\mathcal D_T$ to probe, attend to, and borrow fragments from any large, topic-rich source corpus (such as Wikipedia), which need not be the corpus used to pretrain embeddings. This step is made scalable and practical by suitable indexing. We reach the surprising conclusion that even limited corpus augmentation is more useful than adapting embeddings, which suggests that non-dominant sense information may be irrevocably obliterated from pretrained embeddings and cannot be salvaged by adaptation.
Privacy Preserving Link Prediction with Latent Geometric Network Models
Jul 20, 2019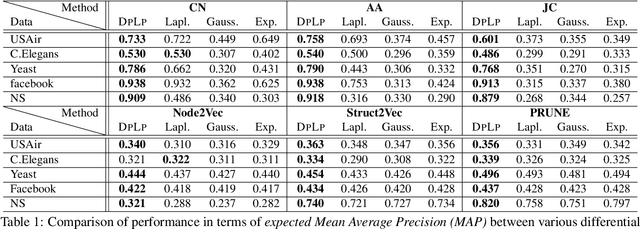
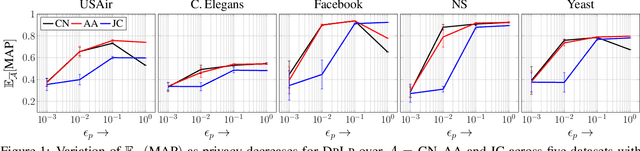
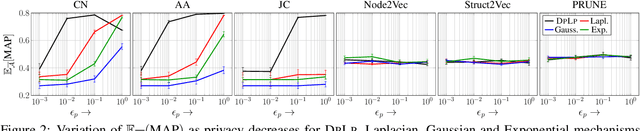
Link prediction is an important task in social network analysis, with a wide variety of applications ranging from graph search to recommendation. The usual paradigm is to propose to each node a ranked list of nodes that are currently non-neighbors, as the most likely candidates for future linkage. Owing to increasing concerns about privacy, users (nodes) may prefer to keep some or all their connections private. Most link prediction heuristics, such as common neighbor, Jaccard coefficient, and Adamic-Adar, can leak private link information in making predictions. We present D P L P , a generic framework to protect differential privacy for these popular heuristics under the ranking objective. Under a recently-introduced latent node embedding model, we also analyze the trade-off between privacy and link prediction utility. Extensive experiments with eight diverse real-life graphs and several link prediction heuristics show that D P L P can trade off between privacy and predictive performance more effectively than several alternatives.
A Deep Generative Model for Code-Switched Text
Jun 21, 2019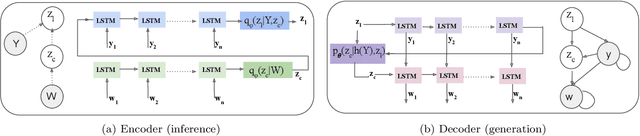
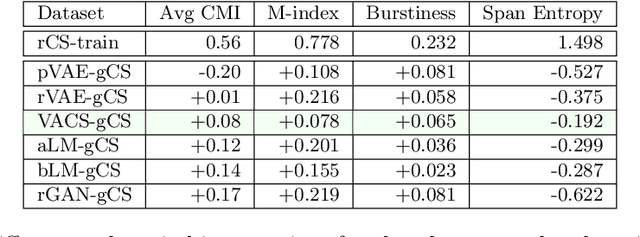
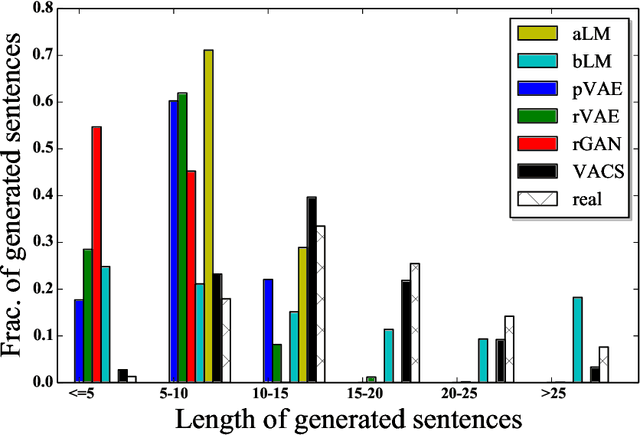
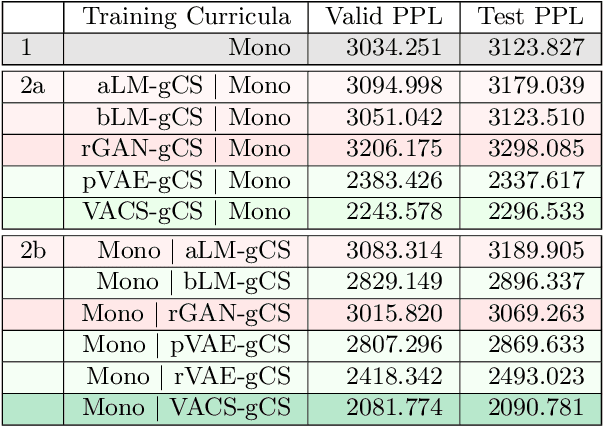
Code-switching, the interleaving of two or more languages within a sentence or discourse is pervasive in multilingual societies. Accurate language models for code-switched text are critical for NLP tasks. State-of-the-art data-intensive neural language models are difficult to train well from scarce language-labeled code-switched text. A potential solution is to use deep generative models to synthesize large volumes of realistic code-switched text. Although generative adversarial networks and variational autoencoders can synthesize plausible monolingual text from continuous latent space, they cannot adequately address code-switched text, owing to their informal style and complex interplay between the constituent languages. We introduce VACS, a novel variational autoencoder architecture specifically tailored to code-switching phenomena. VACS encodes to and decodes from a two-level hierarchical representation, which models syntactic contextual signals in the lower level, and language switching signals in the upper layer. Sampling representations from the prior and decoding them produced well-formed, diverse code-switched sentences. Extensive experiments show that using synthetic code-switched text with natural monolingual data results in significant (33.06%) drop in perplexity.
Improved Sentiment Detection via Label Transfer from Monolingual to Synthetic Code-Switched Text
Jun 13, 2019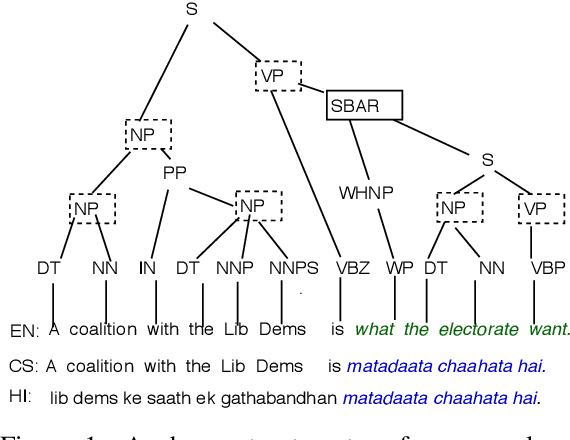
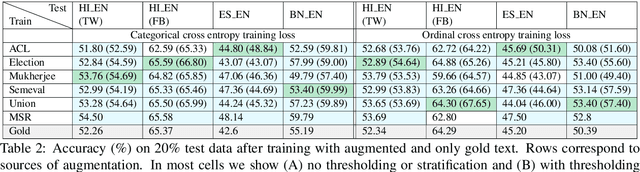
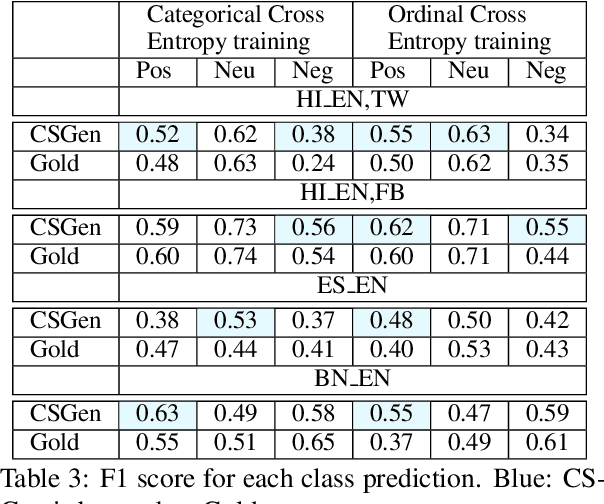
Multilingual writers and speakers often alternate between two languages in a single discourse, a practice called "code-switching". Existing sentiment detection methods are usually trained on sentiment-labeled monolingual text. Manually labeled code-switched text, especially involving minority languages, is extremely rare. Consequently, the best monolingual methods perform relatively poorly on code-switched text. We present an effective technique for synthesizing labeled code-switched text from labeled monolingual text, which is more readily available. The idea is to replace carefully selected subtrees of constituency parses of sentences in the resource-rich language with suitable token spans selected from automatic translations to the resource-poor language. By augmenting scarce human-labeled code-switched text with plentiful synthetic code-switched text, we achieve significant improvements in sentiment labeling accuracy (1.5%, 5.11%, 7.20%) for three different language pairs (English-Hindi, English-Spanish and English-Bengali). We also get significant gains for hate speech detection: 4% improvement using only synthetic text and 6% if augmented with real text.
Multi-task Learning for Target-dependent Sentiment Classification
Feb 08, 2019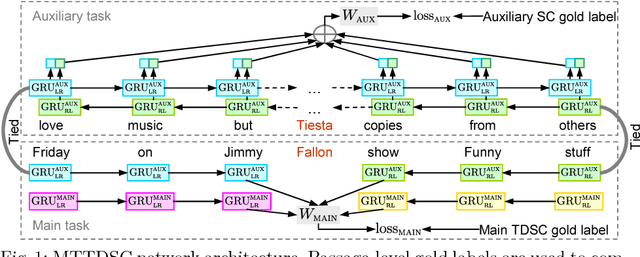
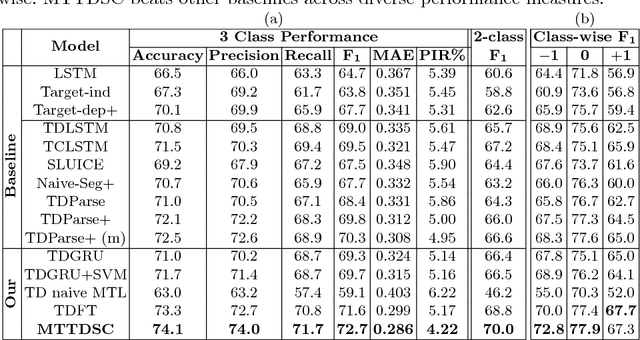
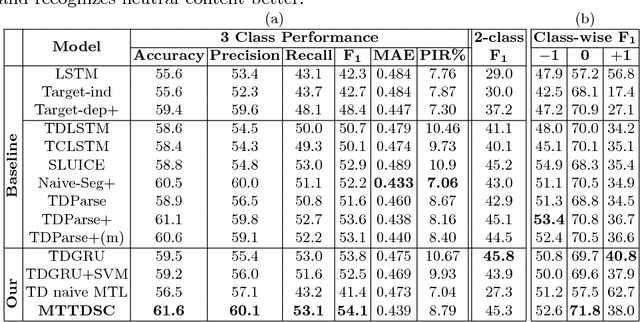
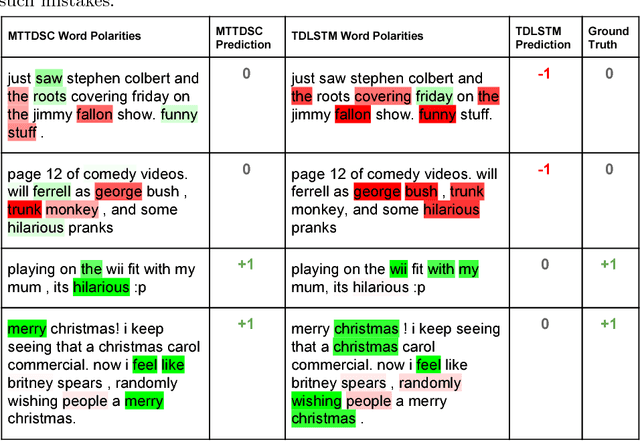
Detecting and aggregating sentiments toward people, organizations, and events expressed in unstructured social media have become critical text mining operations. Early systems detected sentiments over whole passages, whereas more recently, target-specific sentiments have been of greater interest. In this paper, we present MTTDSC, a multi-task target-dependent sentiment classification system that is informed by feature representation learnt for the related auxiliary task of passage-level sentiment classification. The auxiliary task uses a gated recurrent unit (GRU) and pools GRU states, followed by an auxiliary fully-connected layer that outputs passage-level predictions. In the main task, these GRUs contribute auxiliary per-token representations over and above word embeddings. The main task has its own, separate GRUs. The auxiliary and main GRUs send their states to a different fully connected layer, trained for the main task. Extensive experiments using two auxiliary datasets and three benchmark datasets (of which one is new, introduced by us) for the main task demonstrate that MTTDSC outperforms state-of-the-art baselines. Using word-level sensitivity analysis, we present anecdotal evidence that prior systems can make incorrect target-specific predictions because they miss sentiments expressed by words independent of target.