 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Adversarially Robust Deepfake Detection: An Ensemble Approach
Feb 11, 2022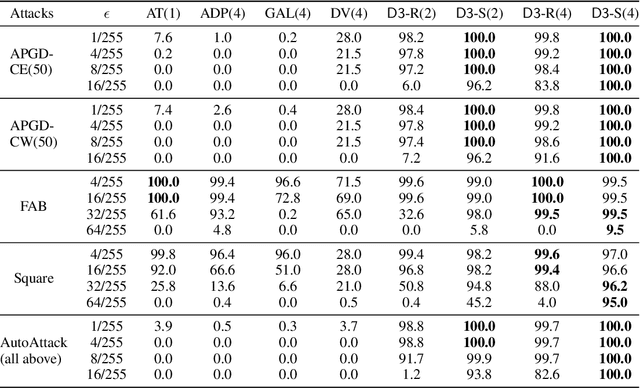
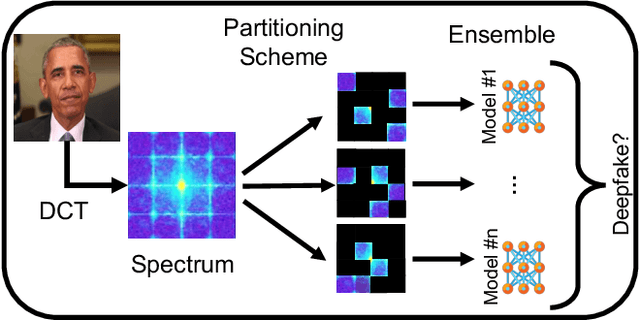
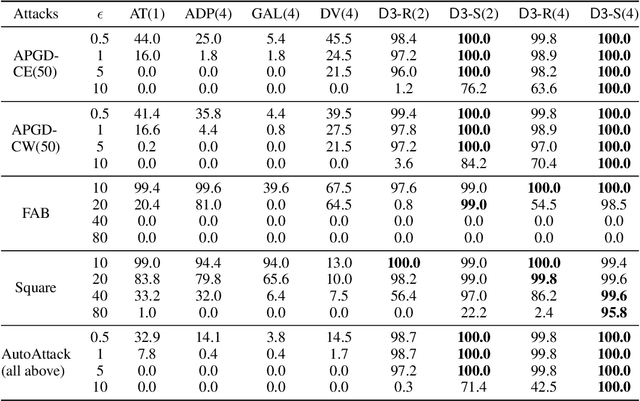
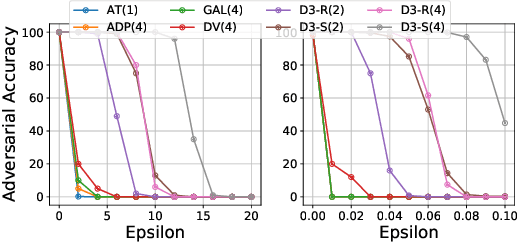
Detecting deepfakes is an important problem, but recent work has shown that DNN-based deepfake detectors are brittle against adversarial deepfakes, in which an adversary adds imperceptible perturbations to a deepfake to evade detection. In this work, we show that a modification to the detection strategy in which we replace a single classifier with a carefully chosen ensemble, in which input transformations for each model in the ensemble induces pairwise orthogonal gradients, can significantly improve robustness beyond the de facto solution of adversarial training. We present theoretical results to show that such orthogonal gradients can help thwart a first-order adversary by reducing the dimensionality of the input subspace in which adversarial deepfakes lie. We validate the results empirically by instantiating and evaluating a randomized version of such "orthogonal" ensembles for adversarial deepfake detection and find that these randomized ensembles exhibit significantly higher robustness as deepfake detectors compared to state-of-the-art deepfake detectors against adversarial deepfakes, even those created using strong PGD-500 attacks.
An Exploration of Multicalibration Uniform Convergence Bounds
Feb 09, 2022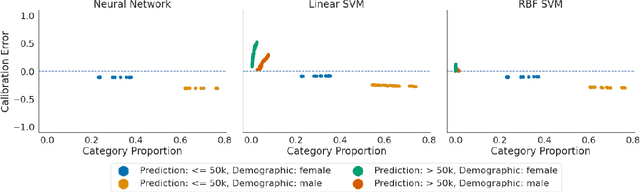
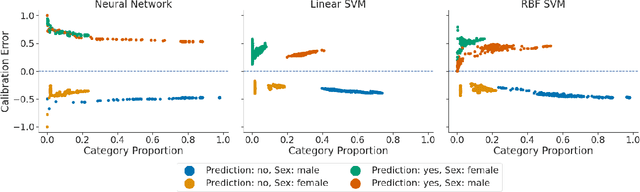
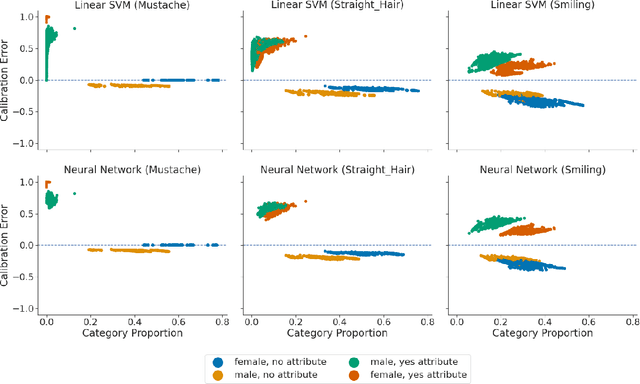
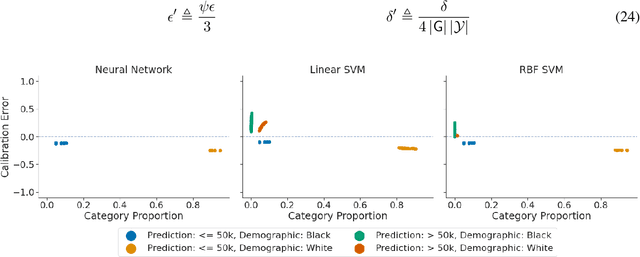
Recent works have investigated the sample complexity necessary for fair machine learning. The most advanced of such sample complexity bounds are developed by analyzing multicalibration uniform convergence for a given predictor class. We present a framework which yields multicalibration error uniform convergence bounds by reparametrizing sample complexities for Empirical Risk Minimization (ERM) learning. From this framework, we demonstrate that multicalibration error exhibits dependence on the classifier architecture as well as the underlying data distribution. We perform an experimental evaluation to investigate the behavior of multicalibration error for different families of classifiers. We compare the results of this evaluation to multicalibration error concentration bounds. Our investigation provides additional perspective on both algorithmic fairness and multicalibration error convergence bounds. Given the prevalence of ERM sample complexity bounds, our proposed framework enables machine learning practitioners to easily understand the convergence behavior of multicalibration error for a myriad of classifier architectures.
Towards Evaluating the Robustness of Neural Networks Learned by Transduction
Oct 27, 2021
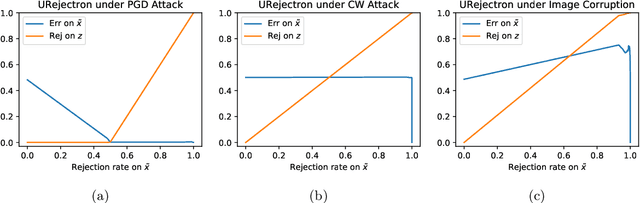
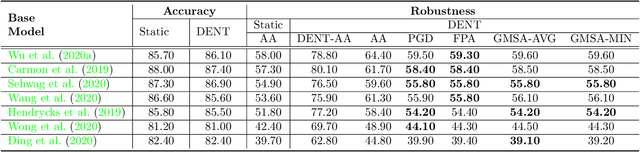

There has been emerging interest in using transductive learning for adversarial robustness (Goldwasser et al., NeurIPS 2020; Wu et al., ICML 2020; Wang et al., ArXiv 2021). Compared to traditional defenses, these defense mechanisms "dynamically learn" the model based on test-time input; and theoretically, attacking these defenses reduces to solving a bilevel optimization problem, which poses difficulty in crafting adaptive attacks. In this paper, we examine these defense mechanisms from a principled threat analysis perspective. We formulate and analyze threat models for transductive-learning based defenses, and point out important subtleties. We propose the principle of attacking model space for solving bilevel attack objectives, and present Greedy Model Space Attack (GMSA), an attack framework that can serve as a new baseline for evaluating transductive-learning based defenses. Through systematic evaluation, we show that GMSA, even with weak instantiations, can break previous transductive-learning based defenses, which were resilient to previous attacks, such as AutoAttack (Croce and Hein, ICML 2020). On the positive side, we report a somewhat surprising empirical result of "transductive adversarial training": Adversarially retraining the model using fresh randomness at the test time gives a significant increase in robustness against attacks we consider.
Fairness Properties of Face Recognition and Obfuscation Systems
Aug 05, 2021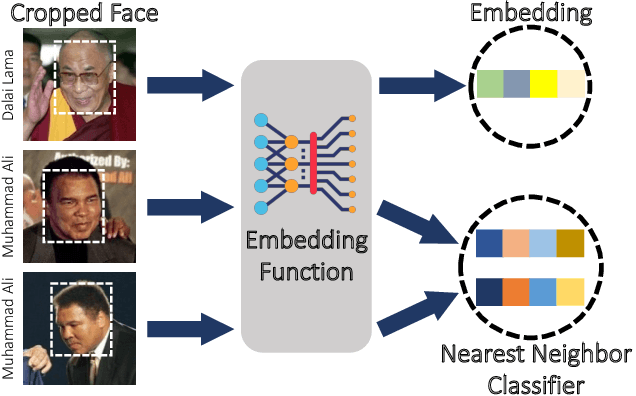
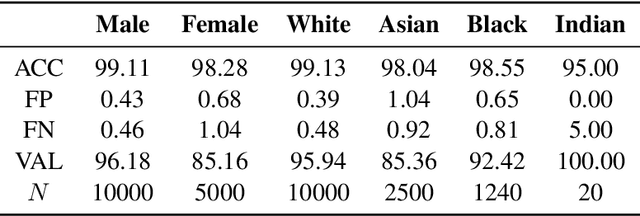
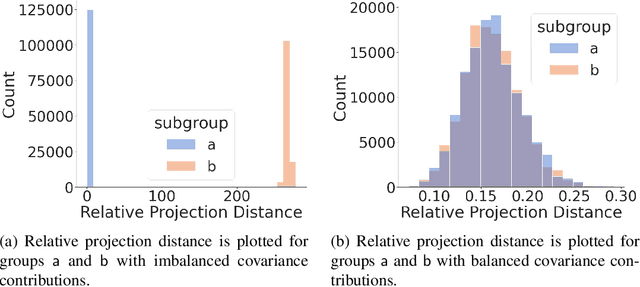
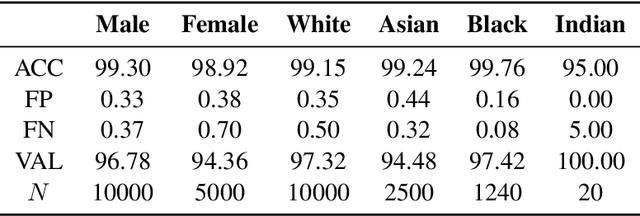
The proliferation of automated facial recognition in various commercial and government sectors has caused significant privacy concerns for individuals. A recent and popular approach to address these privacy concerns is to employ evasion attacks against the metric embedding networks powering facial recognition systems. Face obfuscation systems generate imperceptible perturbations, when added to an image, cause the facial recognition system to misidentify the user. The key to these approaches is the generation of perturbations using a pre-trained metric embedding network followed by their application to an online system, whose model might be proprietary. This dependence of face obfuscation on metric embedding networks, which are known to be unfair in the context of facial recognition, surfaces the question of demographic fairness -- \textit{are there demographic disparities in the performance of face obfuscation systems?} To address this question, we perform an analytical and empirical exploration of the performance of recent face obfuscation systems that rely on deep embedding networks. We find that metric embedding networks are demographically aware; they cluster faces in the embedding space based on their demographic attributes. We observe that this effect carries through to the face obfuscation systems: faces belonging to minority groups incur reduced utility compared to those from majority groups. For example, the disparity in average obfuscation success rate on the online Face++ API can reach up to 20 percentage points. Further, for some demographic groups, the average perturbation size increases by up to 17\% when choosing a target identity belonging to a different demographic group versus the same demographic group. Finally, we present a simple analytical model to provide insights into these phenomena.
Domain Adaptation for Autoencoder-Based End-to-End Communication Over Wireless Channels
Aug 02, 2021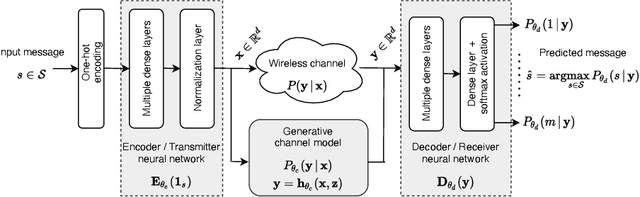
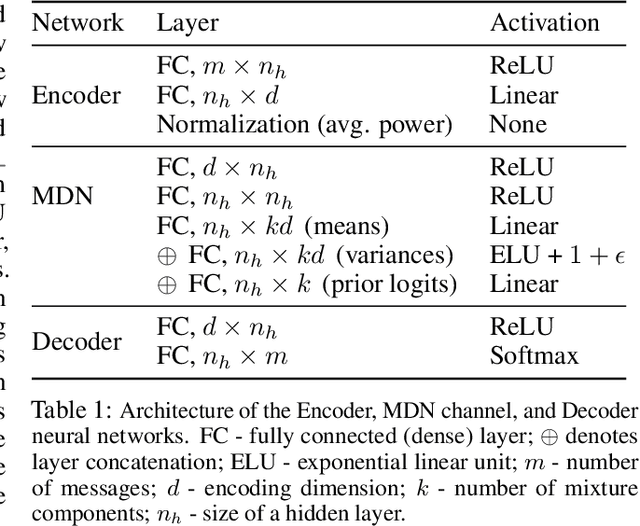
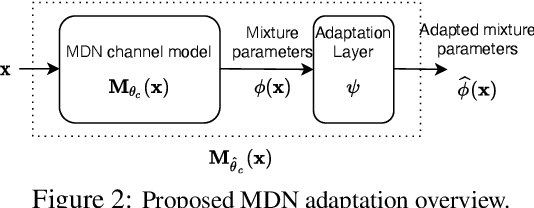
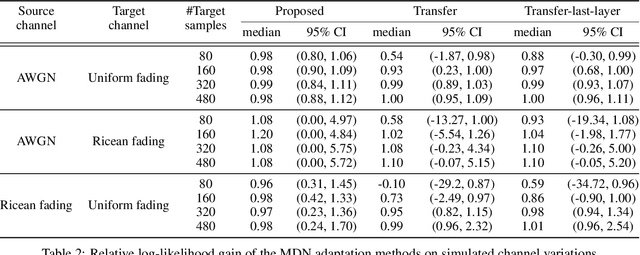
The problem of domain adaptation conventionally considers the setting where a source domain has plenty of labeled data, and a target domain (with a different data distribution) has plenty of unlabeled data but none or very limited labeled data. In this paper, we address the setting where the target domain has only limited labeled data from a distribution that is expected to change frequently. We first propose a fast and light-weight method for adapting a Gaussian mixture density network (MDN) using only a small set of target domain samples. This method is well-suited for the setting where the distribution of target data changes rapidly (e.g., a wireless channel), making it challenging to collect a large number of samples and retrain. We then apply the proposed MDN adaptation method to the problem of end-of-end learning of a wireless communication autoencoder. A communication autoencoder models the encoder, decoder, and the channel using neural networks, and learns them jointly to minimize the overall decoding error rate. However, the error rate of an autoencoder trained on a particular (source) channel distribution can degrade as the channel distribution changes frequently, not allowing enough time for data collection and retraining of the autoencoder to the target channel distribution. We propose a method for adapting the autoencoder without modifying the encoder and decoder neural networks, and adapting only the MDN model of the channel. The method utilizes feature transformations at the decoder to compensate for changes in the channel distribution, and effectively present to the decoder samples close to the source distribution. Experimental evaluation on simulated datasets and real mmWave wireless channels demonstrate that the proposed methods can quickly adapt the MDN model, and improve or maintain the error rate of the autoencoder under changing channel conditions.
Detecting Errors and Estimating Accuracy on Unlabeled Data with Self-training Ensembles
Jun 29, 2021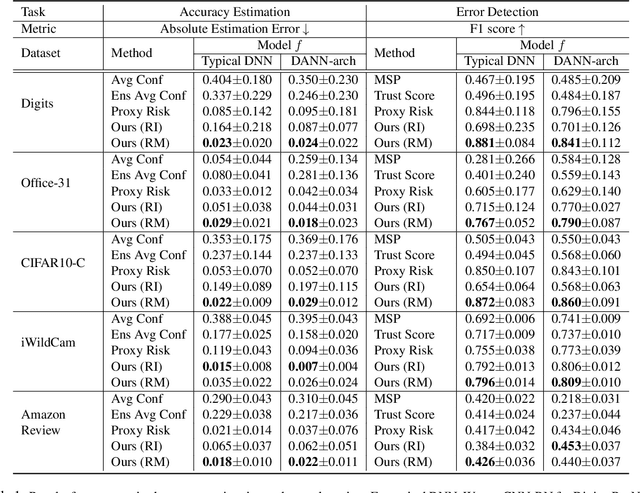
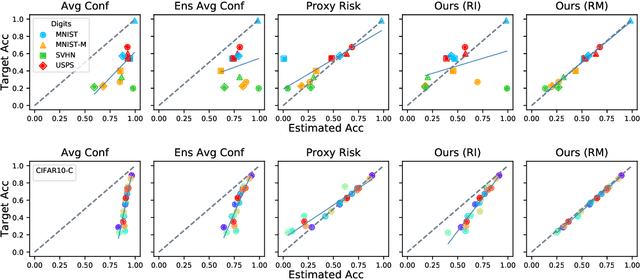
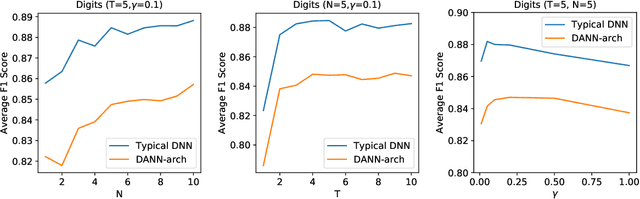
When a deep learning model is deployed in the wild, it can encounter test data drawn from distributions different from the training data distribution and suffer drop in performance. For safe deployment, it is essential to estimate the accuracy of the pre-trained model on the test data. However, the labels for the test inputs are usually not immediately available in practice, and obtaining them can be expensive. This observation leads to two challenging tasks: (1) unsupervised accuracy estimation, which aims to estimate the accuracy of a pre-trained classifier on a set of unlabeled test inputs; (2) error detection, which aims to identify mis-classified test inputs. In this paper, we propose a principled and practically effective framework that simultaneously addresses the two tasks. The proposed framework iteratively learns an ensemble of models to identify mis-classified data points and performs self-training to improve the ensemble with the identified points. Theoretical analysis demonstrates that our framework enjoys provable guarantees for both accuracy estimation and error detection under mild conditions readily satisfied by practical deep learning models. Along with the framework, we proposed and experimented with two instantiations and achieved state-of-the-art results on 59 tasks. For example, on iWildCam, one instantiation reduces the estimation error for unsupervised accuracy estimation by at least 70% and improves the F1 score for error detection by at least 4.7% compared to existing methods.
Towards Adversarial Robustness via Transductive Learning
Jun 15, 2021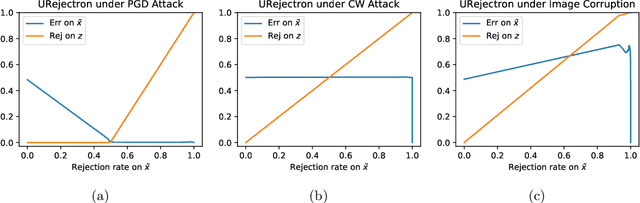
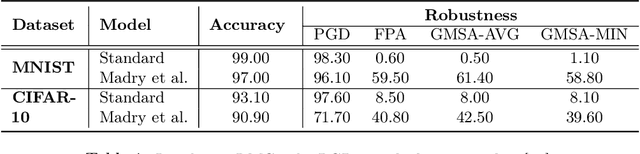
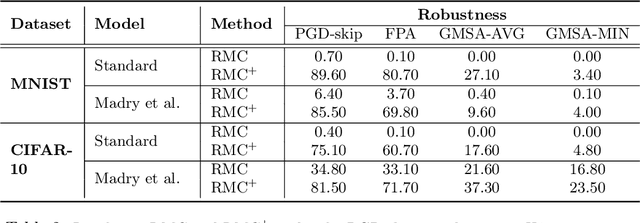
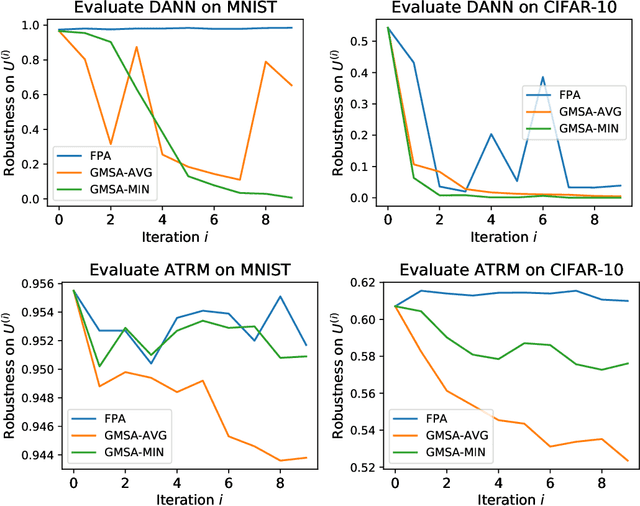
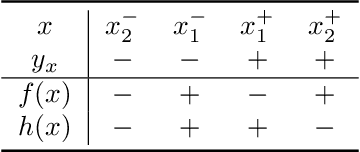
There has been emerging interest to use transductive learning for adversarial robustness (Goldwasser et al., NeurIPS 2020; Wu et al., ICML 2020). Compared to traditional "test-time" defenses, these defense mechanisms "dynamically retrain" the model based on test time input via transductive learning; and theoretically, attacking these defenses boils down to bilevel optimization, which seems to raise the difficulty for adaptive attacks. In this paper, we first formalize and analyze modeling aspects of transductive robustness. Then, we propose the principle of attacking model space for solving bilevel attack objectives, and present an instantiation of the principle which breaks previous transductive defenses. These attacks thus point to significant difficulties in the use of transductive learning to improve adversarial robustness. To this end, we present new theoretical and empirical evidence in support of the utility of transductive learning.
A Shuffling Framework for Local Differential Privacy
Jun 11, 2021
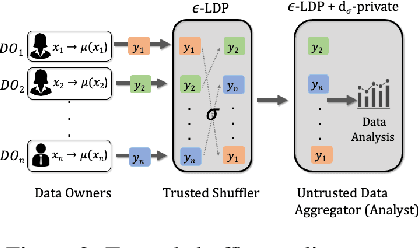
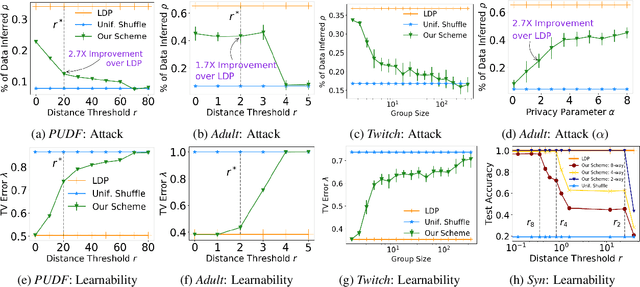
ldp deployments are vulnerable to inference attacks as an adversary can link the noisy responses to their identity and subsequently, auxiliary information using the order of the data. An alternative model, shuffle DP, prevents this by shuffling the noisy responses uniformly at random. However, this limits the data learnability -- only symmetric functions (input order agnostic) can be learned. In this paper, we strike a balance and propose a generalized shuffling framework that interpolates between the two deployment models. We show that systematic shuffling of the noisy responses can thwart specific inference attacks while retaining some meaningful data learnability. To this end, we propose a novel privacy guarantee, d-sigma privacy, that captures the privacy of the order of a data sequence. d-sigma privacy allows tuning the granularity at which the ordinal information is maintained, which formalizes the degree the resistance to inference attacks trading it off with data learnability. Additionally, we propose a novel shuffling mechanism that can achieve d-sigma privacy and demonstrate the practicality of our mechanism via evaluation on real-world datasets.
Causally Constrained Data Synthesis for Private Data Release
May 27, 2021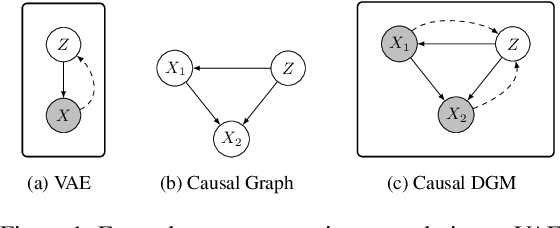
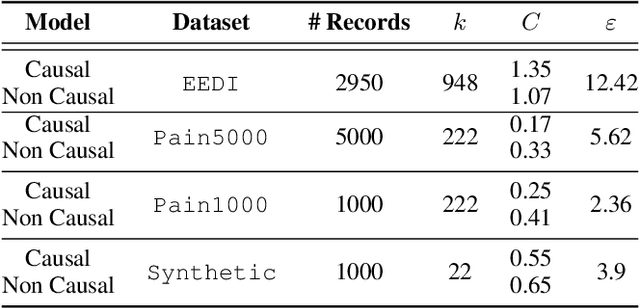
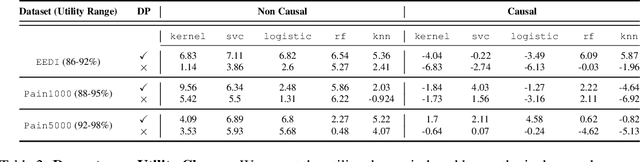
Making evidence based decisions requires data. However for real-world applications, the privacy of data is critical. Using synthetic data which reflects certain statistical properties of the original data preserves the privacy of the original data. To this end, prior works utilize differentially private data release mechanisms to provide formal privacy guarantees. However, such mechanisms have unacceptable privacy vs. utility trade-offs. We propose incorporating causal information into the training process to favorably modify the aforementioned trade-off. We theoretically prove that generative models trained with additional causal knowledge provide stronger differential privacy guarantees. Empirically, we evaluate our solution comparing different models based on variational auto-encoders (VAEs), and show that causal information improves resilience to membership inference, with improvements in downstream utility.
Hard-label Manifolds: Unexpected Advantages of Query Efficiency for Finding On-manifold Adversarial Examples
Mar 04, 2021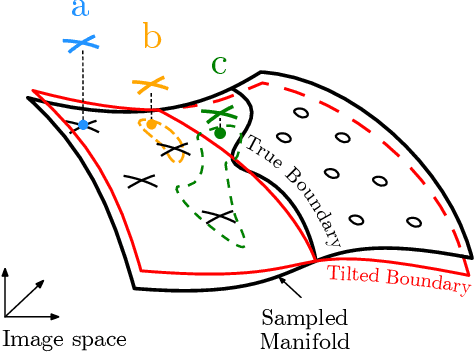
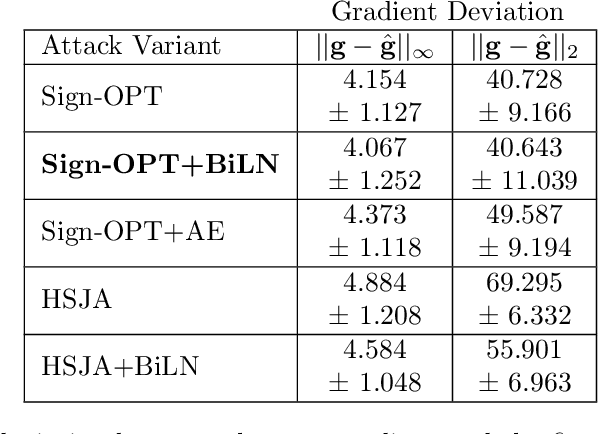
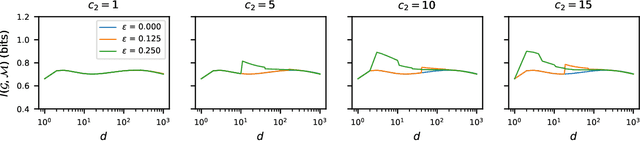
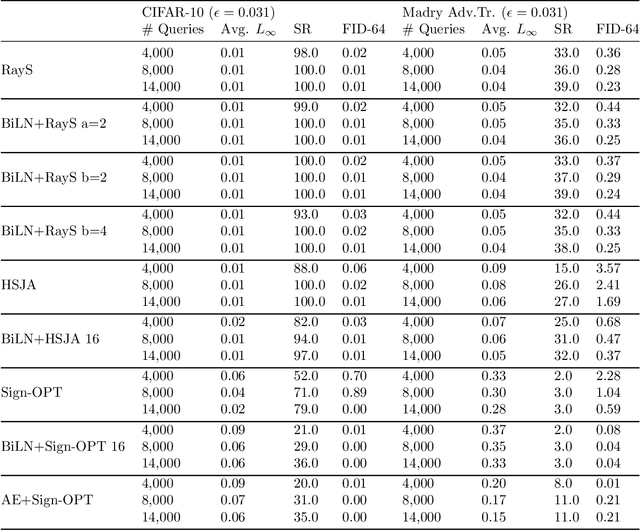
Designing deep networks robust to adversarial examples remains an open problem. Likewise, recent zeroth order hard-label attacks on image classification models have shown comparable performance to their first-order, gradient-level alternatives. It was recently shown in the gradient-level setting that regular adversarial examples leave the data manifold, while their on-manifold counterparts are in fact generalization errors. In this paper, we argue that query efficiency in the zeroth-order setting is connected to an adversary's traversal through the data manifold. To explain this behavior, we propose an information-theoretic argument based on a noisy manifold distance oracle, which leaks manifold information through the adversary's gradient estimate. Through numerical experiments of manifold-gradient mutual information, we show this behavior acts as a function of the effective problem dimensionality and number of training points. On real-world datasets and multiple zeroth-order attacks using dimension-reduction, we observe the same universal behavior to produce samples closer to the data manifold. This results in up to two-fold decrease in the manifold distance measure, regardless of the model robustness. Our results suggest that taking the manifold-gradient mutual information into account can thus inform better robust model design in the future, and avoid leakage of the sensitive data manifold.