 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Stateful Defenses Against Black-Box Adversarial Examples
Mar 17, 2023



Defending machine-learning (ML) models against white-box adversarial attacks has proven to be extremely difficult. Instead, recent work has proposed stateful defenses in an attempt to defend against a more restricted black-box attacker. These defenses operate by tracking a history of incoming model queries, and rejecting those that are suspiciously similar. The current state-of-the-art stateful defense Blacklight was proposed at USENIX Security '22 and claims to prevent nearly 100% of attacks on both the CIFAR10 and ImageNet datasets. In this paper, we observe that an attacker can significantly reduce the accuracy of a Blacklight-protected classifier (e.g., from 82.2% to 6.4% on CIFAR10) by simply adjusting the parameters of an existing black-box attack. Motivated by this surprising observation, since existing attacks were evaluated by the Blacklight authors, we provide a systematization of stateful defenses to understand why existing stateful defense models fail. Finally, we propose a stronger evaluation strategy for stateful defenses comprised of adaptive score and hard-label based black-box attacks. We use these attacks to successfully reduce even reconfigured versions of Blacklight to as low as 0% robust accuracy.
The Trade-off between Universality and Label Efficiency of Representations from Contrastive Learning
Feb 28, 2023



Pre-training representations (a.k.a. foundation models) has recently become a prevalent learning paradigm, where one first pre-trains a representation using large-scale unlabeled data, and then learns simple predictors on top of the representation using small labeled data from the downstream tasks. There are two key desiderata for the representation: label efficiency (the ability to learn an accurate classifier on top of the representation with a small amount of labeled data) and universality (usefulness across a wide range of downstream tasks). In this paper, we focus on one of the most popular instantiations of this paradigm: contrastive learning with linear probing, i.e., learning a linear predictor on the representation pre-trained by contrastive learning. We show that there exists a trade-off between the two desiderata so that one may not be able to achieve both simultaneously. Specifically, we provide analysis using a theoretical data model and show that, while more diverse pre-training data result in more diverse features for different tasks (improving universality), it puts less emphasis on task-specific features, giving rise to larger sample complexity for down-stream supervised tasks, and thus worse prediction performance. Guided by this analysis, we propose a contrastive regularization method to improve the trade-off. We validate our analysis and method empirically with systematic experiments using real-world datasets and foundation models.
Learning Modulo Theories
Jan 26, 2023



Recent techniques that integrate \emph{solver layers} into Deep Neural Networks (DNNs) have shown promise in bridging a long-standing gap between inductive learning and symbolic reasoning techniques. In this paper we present a set of techniques for integrating \emph{Satisfiability Modulo Theories} (SMT) solvers into the forward and backward passes of a deep network layer, called SMTLayer. Using this approach, one can encode rich domain knowledge into the network in the form of mathematical formulas. In the forward pass, the solver uses symbols produced by prior layers, along with these formulas, to construct inferences; in the backward pass, the solver informs updates to the network, driving it towards representations that are compatible with the solver's theory. Notably, the solver need not be differentiable. We implement \layername as a Pytorch module, and our empirical results show that it leads to models that \emph{1)} require fewer training samples than conventional models, \emph{2)} that are robust to certain types of covariate shift, and \emph{3)} that ultimately learn representations that are consistent with symbolic knowledge, and thus naturally interpretable.
Private Multi-Winner Voting for Machine Learning
Nov 23, 2022



Private multi-winner voting is the task of revealing $k$-hot binary vectors satisfying a bounded differential privacy (DP) guarantee. This task has been understudied in machine learning literature despite its prevalence in many domains such as healthcare. We propose three new DP multi-winner mechanisms: Binary, $\tau$, and Powerset voting. Binary voting operates independently per label through composition. $\tau$ voting bounds votes optimally in their $\ell_2$ norm for tight data-independent guarantees. Powerset voting operates over the entire binary vector by viewing the possible outcomes as a power set. Our theoretical and empirical analysis shows that Binary voting can be a competitive mechanism on many tasks unless there are strong correlations between labels, in which case Powerset voting outperforms it. We use our mechanisms to enable privacy-preserving multi-label learning in the central setting by extending the canonical single-label technique: PATE. We find that our techniques outperform current state-of-the-art approaches on large, real-world healthcare data and standard multi-label benchmarks. We further enable multi-label confidential and private collaborative (CaPC) learning and show that model performance can be significantly improved in the multi-site setting.
Federated Boosted Decision Trees with Differential Privacy
Oct 06, 2022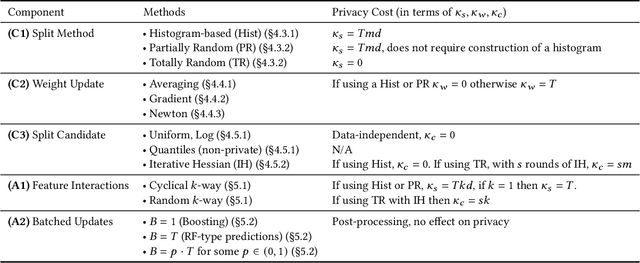
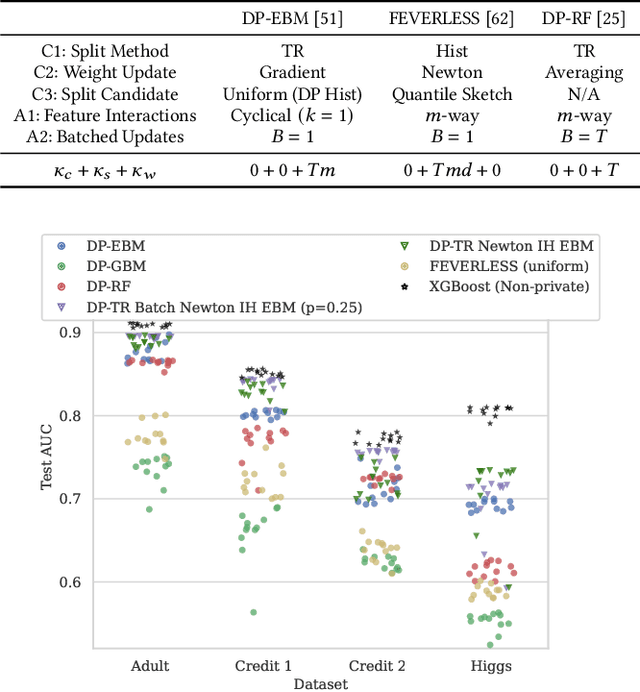
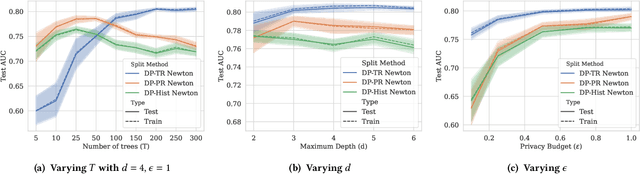
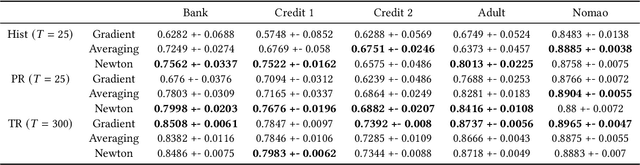
There is great demand for scalable, secure, and efficient privacy-preserving machine learning models that can be trained over distributed data. While deep learning models typically achieve the best results in a centralized non-secure setting, different models can excel when privacy and communication constraints are imposed. Instead, tree-based approaches such as XGBoost have attracted much attention for their high performance and ease of use; in particular, they often achieve state-of-the-art results on tabular data. Consequently, several recent works have focused on translating Gradient Boosted Decision Tree (GBDT) models like XGBoost into federated settings, via cryptographic mechanisms such as Homomorphic Encryption (HE) and Secure Multi-Party Computation (MPC). However, these do not always provide formal privacy guarantees, or consider the full range of hyperparameters and implementation settings. In this work, we implement the GBDT model under Differential Privacy (DP). We propose a general framework that captures and extends existing approaches for differentially private decision trees. Our framework of methods is tailored to the federated setting, and we show that with a careful choice of techniques it is possible to achieve very high utility while maintaining strong levels of privacy.
Overparameterized (robust) models from computational constraints
Aug 27, 2022Overparameterized models with millions of parameters have been hugely successful. In this work, we ask: can the need for large models be, at least in part, due to the \emph{computational} limitations of the learner? Additionally, we ask, is this situation exacerbated for \emph{robust} learning? We show that this indeed could be the case. We show learning tasks for which computationally bounded learners need \emph{significantly more} model parameters than what information-theoretic learners need. Furthermore, we show that even more model parameters could be necessary for robust learning. In particular, for computationally bounded learners, we extend the recent result of Bubeck and Sellke [NeurIPS'2021] which shows that robust models might need more parameters, to the computational regime and show that bounded learners could provably need an even larger number of parameters. Then, we address the following related question: can we hope to remedy the situation for robust computationally bounded learning by restricting \emph{adversaries} to also be computationally bounded for sake of obtaining models with fewer parameters? Here again, we show that this could be possible. Specifically, building on the work of Garg, Jha, Mahloujifar, and Mahmoody [ALT'2020], we demonstrate a learning task that can be learned efficiently and robustly against a computationally bounded attacker, while to be robust against an information-theoretic attacker requires the learner to utilize significantly more parameters.
Constraining the Attack Space of Machine Learning Models with Distribution Clamping Preprocessing
May 18, 2022
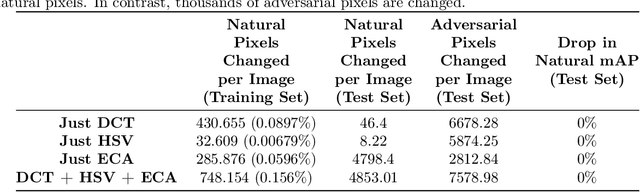
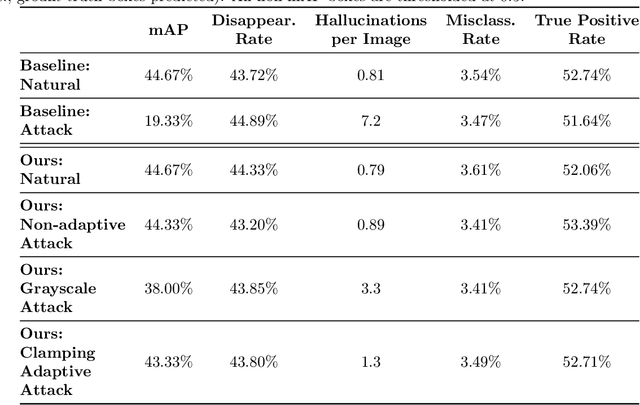
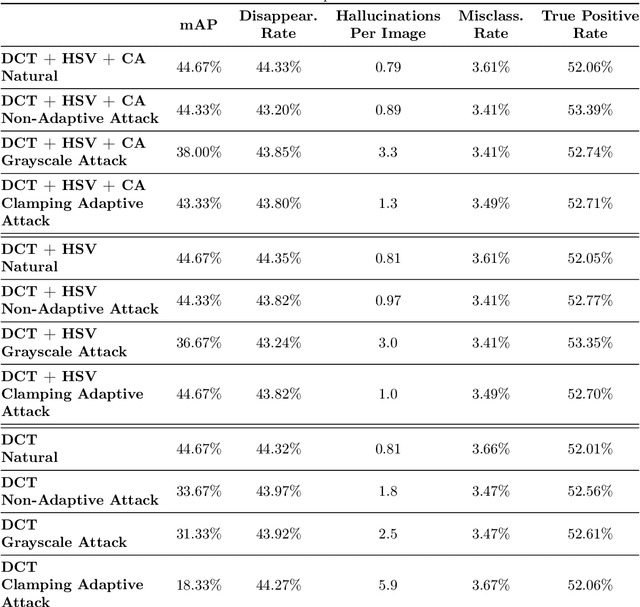
Preprocessing and outlier detection techniques have both been applied to neural networks to increase robustness with varying degrees of success. In this paper, we formalize the ideal preprocessor function as one that would take any input and set it to the nearest in-distribution input. In other words, we detect any anomalous pixels and set them such that the new input is in-distribution. We then illustrate a relaxed solution to this problem in the context of patch attacks. Specifically, we demonstrate that we can model constraints on the patch attack that specify regions as out of distribution. With these constraints, we are able to preprocess inputs successfully, increasing robustness on CARLA object detection.
Optimal Membership Inference Bounds for Adaptive Composition of Sampled Gaussian Mechanisms
Apr 12, 2022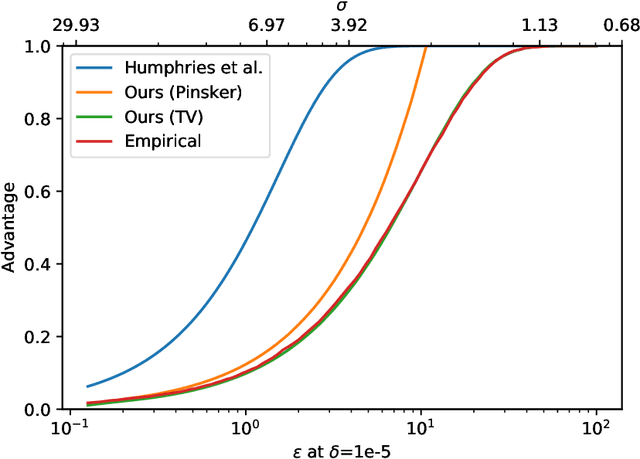
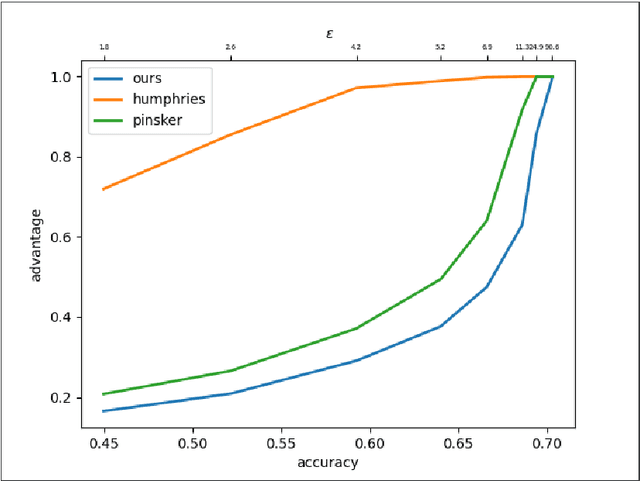
Given a trained model and a data sample, membership-inference (MI) attacks predict whether the sample was in the model's training set. A common countermeasure against MI attacks is to utilize differential privacy (DP) during model training to mask the presence of individual examples. While this use of DP is a principled approach to limit the efficacy of MI attacks, there is a gap between the bounds provided by DP and the empirical performance of MI attacks. In this paper, we derive bounds for the \textit{advantage} of an adversary mounting a MI attack, and demonstrate tightness for the widely-used Gaussian mechanism. We further show bounds on the \textit{confidence} of MI attacks. Our bounds are much stronger than those obtained by DP analysis. For example, analyzing a setting of DP-SGD with $\epsilon=4$ would obtain an upper bound on the advantage of $\approx0.36$ based on our analyses, while getting bound of $\approx 0.97$ using the analysis of previous work that convert $\epsilon$ to membership inference bounds. Finally, using our analysis, we provide MI metrics for models trained on CIFAR10 dataset. To the best of our knowledge, our analysis provides the state-of-the-art membership inference bounds for the privacy.
Concept-based Explanations for Out-Of-Distribution Detectors
Mar 04, 2022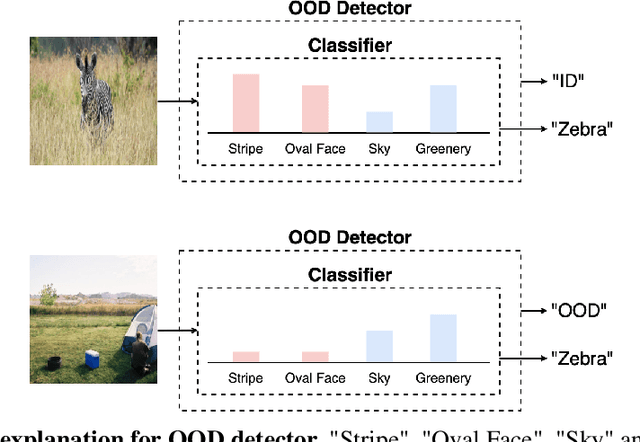
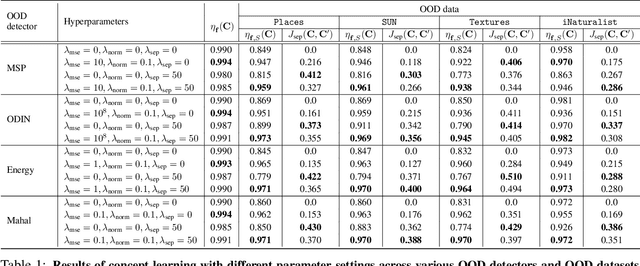
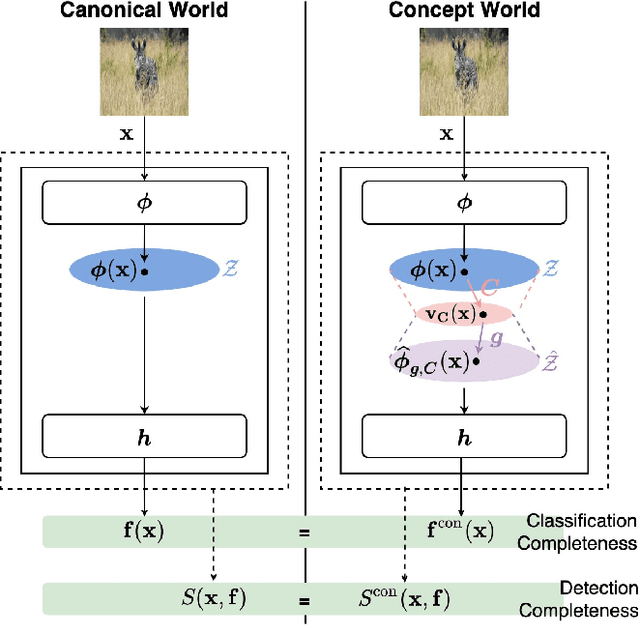
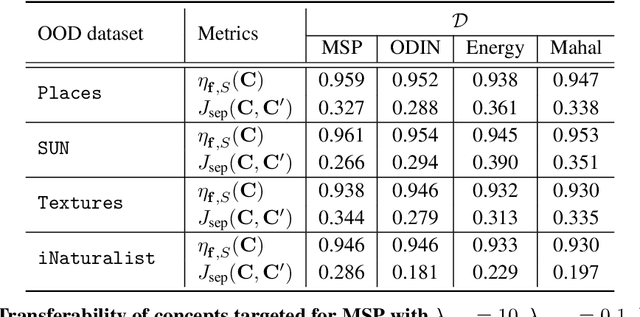
Out-of-distribution (OOD) detection plays a crucial role in ensuring the safe deployment of deep neural network (DNN) classifiers. While a myriad of methods have focused on improving the performance of OOD detectors, a critical gap remains in interpreting their decisions. We help bridge this gap by providing explanations for OOD detectors based on learned high-level concepts. We first propose two new metrics for assessing the effectiveness of a particular set of concepts for explaining OOD detectors: 1) detection completeness, which quantifies the sufficiency of concepts for explaining an OOD-detector's decisions, and 2) concept separability, which captures the distributional separation between in-distribution and OOD data in the concept space. Based on these metrics, we propose a framework for learning a set of concepts that satisfy the desired properties of detection completeness and concept separability and demonstrate the framework's effectiveness in providing concept-based explanations for diverse OOD techniques. We also show how to identify prominent concepts that contribute to the detection results via a modified Shapley value-based importance score.
A Quantitative Geometric Approach to Neural Network Smoothness
Mar 02, 2022
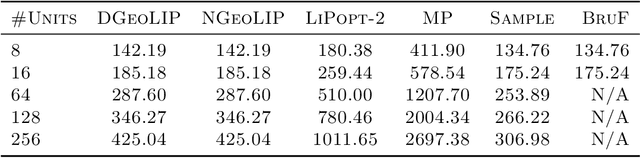
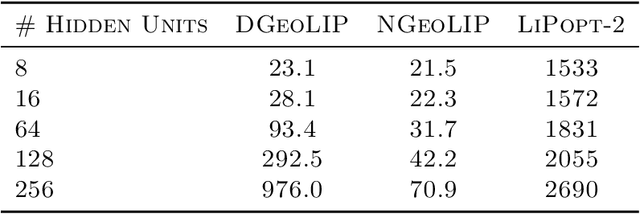

Fast and precise Lipschitz constant estimation of neural networks is an important task for deep learning. Researchers have recently found an intrinsic trade-off between the accuracy and smoothness of neural networks, so training a network with a loose Lipschitz constant estimation imposes a strong regularization and can hurt the model accuracy significantly. In this work, we provide a unified theoretical framework, a quantitative geometric approach, to address the Lipschitz constant estimation. By adopting this framework, we can immediately obtain several theoretical results, including the computational hardness of Lipschitz constant estimation and its approximability. Furthermore, the quantitative geometric perspective can also provide some insights into recent empirical observations that techniques for one norm do not usually transfer to another one. We also implement the algorithms induced from this quantitative geometric approach in a tool GeoLIP. These algorithms are based on semidefinite programming (SDP). Our empirical evaluation demonstrates that GeoLIP is more scalable and precise than existing tools on Lipschitz constant estimation for $\ell_\infty$-perturbations. Furthermore, we also show its intricate relations with other recent SDP-based techniques, both theoretically and empirically. We believe that this unified quantitative geometric perspective can bring new insights and theoretical tools to the investigation of neural-network smoothness and robustness.