 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Robustness for Streaming Models with a Sliding Window
Mar 28, 2023



The literature on provable robustness in machine learning has primarily focused on static prediction problems, such as image classification, in which input samples are assumed to be independent and model performance is measured as an expectation over the input distribution. Robustness certificates are derived for individual input instances with the assumption that the model is evaluated on each instance separately. However, in many deep learning applications such as online content recommendation and stock market analysis, models use historical data to make predictions. Robustness certificates based on the assumption of independent input samples are not directly applicable in such scenarios. In this work, we focus on the provable robustness of machine learning models in the context of data streams, where inputs are presented as a sequence of potentially correlated items. We derive robustness certificates for models that use a fixed-size sliding window over the input stream. Our guarantees hold for the average model performance across the entire stream and are independent of stream size, making them suitable for large data streams. We perform experiments on speech detection and human activity recognition tasks and show that our certificates can produce meaningful performance guarantees against adversarial perturbations.
Adversarial Robustness of Learning-based Static Malware Classifiers
Mar 20, 2023Malware detection has long been a stage for an ongoing arms race between malware authors and anti-virus systems. Solutions that utilize machine learning (ML) gain traction as the scale of this arms race increases. This trend, however, makes performing attacks directly on ML an attractive prospect for adversaries. We study this arms race from both perspectives in the context of MalConv, a popular convolutional neural network-based malware classifier that operates on raw bytes of files. First, we show that MalConv is vulnerable to adversarial patch attacks: appending a byte-level patch to malware files bypasses detection 94.3% of the time. Moreover, we develop a universal adversarial patch (UAP) attack where a single patch can drop the detection rate in constant time of any malware file that contains it by 80%. These patches are effective even being relatively small with respect to the original file size -- between 2%-8%. As a countermeasure, we then perform window ablation that allows us to apply de-randomized smoothing, a modern certified defense to patch attacks in vision tasks, to raw files. The resulting `smoothed-MalConv' can detect over 80% of malware that contains the universal patch and provides certified robustness up to 66%, outlining a promising step towards robust malware detection. To our knowledge, we are the first to apply universal adversarial patch attack and certified defense using ablations on byte level in the malware field.
Can AI-Generated Text be Reliably Detected?
Mar 17, 2023



The rapid progress of Large Language Models (LLMs) has made them capable of performing astonishingly well on various tasks including document completion and question answering. The unregulated use of these models, however, can potentially lead to malicious consequences such as plagiarism, generating fake news, spamming, etc. Therefore, reliable detection of AI-generated text can be critical to ensure the responsible use of LLMs. Recent works attempt to tackle this problem either using certain model signatures present in the generated text outputs or by applying watermarking techniques that imprint specific patterns onto them. In this paper, both empirically and theoretically, we show that these detectors are not reliable in practical scenarios. Empirically, we show that paraphrasing attacks, where a light paraphraser is applied on top of the generative text model, can break a whole range of detectors, including the ones using the watermarking schemes as well as neural network-based detectors and zero-shot classifiers. We then provide a theoretical impossibility result indicating that for a sufficiently good language model, even the best-possible detector can only perform marginally better than a random classifier. Finally, we show that even LLMs protected by watermarking schemes can be vulnerable against spoofing attacks where adversarial humans can infer hidden watermarking signatures and add them to their generated text to be detected as text generated by the LLMs, potentially causing reputational damages to their developers. We believe these results can open an honest conversation in the community regarding the ethical and reliable use of AI-generated text.
CUDA: Convolution-based Unlearnable Datasets
Mar 07, 2023
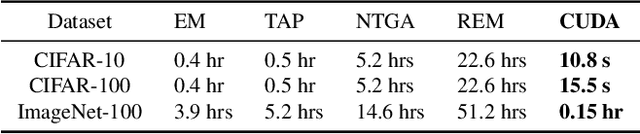
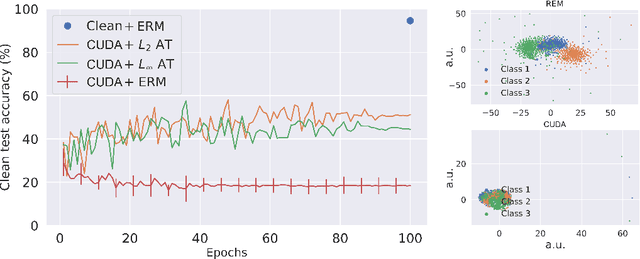
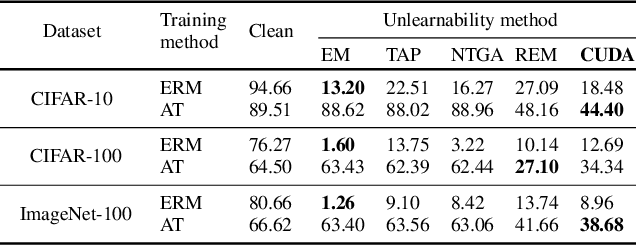
Large-scale training of modern deep learning models heavily relies on publicly available data on the web. This potentially unauthorized usage of online data leads to concerns regarding data privacy. Recent works aim to make unlearnable data for deep learning models by adding small, specially designed noises to tackle this issue. However, these methods are vulnerable to adversarial training (AT) and/or are computationally heavy. In this work, we propose a novel, model-free, Convolution-based Unlearnable DAtaset (CUDA) generation technique. CUDA is generated using controlled class-wise convolutions with filters that are randomly generated via a private key. CUDA encourages the network to learn the relation between filters and labels rather than informative features for classifying the clean data. We develop some theoretical analysis demonstrating that CUDA can successfully poison Gaussian mixture data by reducing the clean data performance of the optimal Bayes classifier. We also empirically demonstrate the effectiveness of CUDA with various datasets (CIFAR-10, CIFAR-100, ImageNet-100, and Tiny-ImageNet), and architectures (ResNet-18, VGG-16, Wide ResNet-34-10, DenseNet-121, DeIT, EfficientNetV2-S, and MobileNetV2). Our experiments show that CUDA is robust to various data augmentations and training approaches such as smoothing, AT with different budgets, transfer learning, and fine-tuning. For instance, training a ResNet-18 on ImageNet-100 CUDA achieves only 8.96$\%$, 40.08$\%$, and 20.58$\%$ clean test accuracies with empirical risk minimization (ERM), $L_{\infty}$ AT, and $L_{2}$ AT, respectively. Here, ERM on the clean training data achieves a clean test accuracy of 80.66$\%$. CUDA exhibits unlearnability effect with ERM even when only a fraction of the training dataset is perturbed. Furthermore, we also show that CUDA is robust to adaptive defenses designed specifically to break it.
Temporal Robustness against Data Poisoning
Feb 07, 2023Data poisoning considers cases when an adversary maliciously inserts and removes training data to manipulate the behavior of machine learning algorithms. Traditional threat models of data poisoning center around a single metric, the number of poisoned samples. In consequence, existing defenses are essentially vulnerable in practice when poisoning more samples remains a feasible option for attackers. To address this issue, we leverage timestamps denoting the birth dates of data, which are often available but neglected in the past. Benefiting from these timestamps, we propose a temporal threat model of data poisoning and derive two novel metrics, earliness and duration, which respectively measure how long an attack started in advance and how long an attack lasted. With these metrics, we define the notions of temporal robustness against data poisoning, providing a meaningful sense of protection even with unbounded amounts of poisoned samples. We present a benchmark with an evaluation protocol simulating continuous data collection and periodic deployments of updated models, thus enabling empirical evaluation of temporal robustness. Lastly, we develop and also empirically verify a baseline defense, namely temporal aggregation, offering provable temporal robustness and highlighting the potential of our temporal modeling of data poisoning.
Run-Off Election: Improved Provable Defense against Data Poisoning Attacks
Feb 05, 2023



In data poisoning attacks, an adversary tries to change a model's prediction by adding, modifying, or removing samples in the training data. Recently, ensemble-based approaches for obtaining provable defenses against data poisoning have been proposed where predictions are done by taking a majority vote across multiple base models. In this work, we show that merely considering the majority vote in ensemble defenses is wasteful as it does not effectively utilize available information in the logits layers of the base models. Instead, we propose Run-Off Election (ROE), a novel aggregation method based on a two-round election across the base models: In the first round, models vote for their preferred class and then a second, Run-Off election is held between the top two classes in the first round. Based on this approach, we propose DPA+ROE and FA+ROE defense methods based on Deep Partition Aggregation (DPA) and Finite Aggregation (FA) approaches from prior work. We show how to obtain robustness for these methods using ideas inspired by dynamic programming and duality. We evaluate our methods on MNIST, CIFAR-10, and GTSRB and obtain improvements in certified accuracy by up to 4.73%, 3.63%, and 3.54%, respectively, establishing a new state-of-the-art in (pointwise) certified robustness against data poisoning. In many cases, our approach outperforms the state-of-the-art, even when using 32 times less computational power.
Spuriosity Rankings: Sorting Data for Spurious Correlation Robustness
Dec 05, 2022



We present a framework for ranking images within their class based on the strength of spurious cues present. By measuring the gap in accuracy on the highest and lowest ranked images (we call this spurious gap), we assess spurious feature reliance for $89$ diverse ImageNet models, finding that even the best models underperform in images with weak spurious presence. However, the effect of spurious cues varies far more dramatically across classes, emphasizing the crucial, often overlooked, class-dependence of the spurious correlation problem. While most spurious features we observe are clarifying (i.e. improving test-time accuracy when present, as is typically expected), we surprisingly find many cases of confusing spurious features, where models perform better when they are absent. We then close the spurious gap by training new classification heads on lowly ranked (i.e. without common spurious cues) images, resulting in improved effective robustness to distribution shifts (ObjectNet, ImageNet-R, ImageNet-Sketch). We also propose a second metric to assess feature reliability, finding that spurious features are generally less reliable than non-spurious (core) ones, though again, spurious features can be more reliable for certain classes. To enable our analysis, we annotated $5,000$ feature-class dependencies over {\it all} of ImageNet as core or spurious using minimal human supervision. Finally, we show the feature discovery and spuriosity ranking framework can be extended to other datasets like CelebA and WaterBirds in a lightweight fashion with only linear layer training, leading to discovering a previously unknown racial bias in the Celeb-A hair classification.
Towards Better Input Masking for Convolutional Neural Networks
Nov 26, 2022The ability to remove features from the input of machine learning models is very important to understand and interpret model predictions. However, this is non-trivial for vision models since masking out parts of the input image and replacing them with a baseline color like black or grey typically causes large distribution shifts. Masking may even make the model focus on the masking patterns for its prediction rather than the unmasked portions of the image. In recent work, it has been shown that vision transformers are less affected by such issues as one can simply drop the tokens corresponding to the masked image portions. They are thus more easily interpretable using techniques like LIME which rely on input perturbation. Using the same intuition, we devise a masking technique for CNNs called layer masking, which simulates running the CNN on only the unmasked input. We find that our method is (i) much less disruptive to the model's output and its intermediate activations, and (ii) much better than commonly used masking techniques for input perturbation based interpretability techniques like LIME. Thus, layer masking is able to close the interpretability gap between CNNs and transformers, and even make CNNs more interpretable in many cases.
Invariant Learning via Diffusion Dreamed Distribution Shifts
Nov 18, 2022Though the background is an important signal for image classification, over reliance on it can lead to incorrect predictions when spurious correlations between foreground and background are broken at test time. Training on a dataset where these correlations are unbiased would lead to more robust models. In this paper, we propose such a dataset called Diffusion Dreamed Distribution Shifts (D3S). D3S consists of synthetic images generated through StableDiffusion using text prompts and image guides obtained by pasting a sample foreground image onto a background template image. Using this scalable approach we generate 120K images of objects from all 1000 ImageNet classes in 10 diverse backgrounds. Due to the incredible photorealism of the diffusion model, our images are much closer to natural images than previous synthetic datasets. D3S contains a validation set of more than 17K images whose labels are human-verified in an MTurk study. Using the validation set, we evaluate several popular DNN image classifiers and find that the classification performance of models generally suffers on our background diverse images. Next, we leverage the foreground & background labels in D3S to learn a foreground (background) representation that is invariant to changes in background (foreground) by penalizing the mutual information between the foreground (background) features and the background (foreground) labels. Linear classifiers trained on these features to predict foreground (background) from foreground (background) have high accuracies at 82.9% (93.8%), while classifiers that predict these labels from background and foreground have a much lower accuracy of 2.4% and 45.6% respectively. This suggests that our foreground and background features are well disentangled. We further test the efficacy of these representations by training classifiers on a task with strong spurious correlations.
Improved techniques for deterministic l2 robustness
Nov 15, 2022



Training convolutional neural networks (CNNs) with a strict 1-Lipschitz constraint under the $l_{2}$ norm is useful for adversarial robustness, interpretable gradients and stable training. 1-Lipschitz CNNs are usually designed by enforcing each layer to have an orthogonal Jacobian matrix (for all inputs) to prevent the gradients from vanishing during backpropagation. However, their performance often significantly lags behind that of heuristic methods to enforce Lipschitz constraints where the resulting CNN is not \textit{provably} 1-Lipschitz. In this work, we reduce this gap by introducing (a) a procedure to certify robustness of 1-Lipschitz CNNs by replacing the last linear layer with a 1-hidden layer MLP that significantly improves their performance for both standard and provably robust accuracy, (b) a method to significantly reduce the training time per epoch for Skew Orthogonal Convolution (SOC) layers (>30\% reduction for deeper networks) and (c) a class of pooling layers using the mathematical property that the $l_{2}$ distance of an input to a manifold is 1-Lipschitz. Using these methods, we significantly advance the state-of-the-art for standard and provable robust accuracies on CIFAR-10 (gains of +1.79\% and +3.82\%) and similarly on CIFAR-100 (+3.78\% and +4.75\%) across all networks. Code is available at \url{https://github.com/singlasahil14/improved_l2_robustness}.