 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIS3R: Very Large Parallax Image Stitching via Deep 3D Reconstruction
Aug 06, 2025Image stitching aim to align two images taken from different viewpoints into one seamless, wider image. However, when the 3D scene contains depth variations and the camera baseline is significant, noticeable parallax occurs-meaning the relative positions of scene elements differ substantially between views. Most existing stitching methods struggle to handle such images with large parallax effectively. To address this challenge, in this paper, we propose an image stitching solution called PIS3R that is robust to very large parallax based on the novel concept of deep 3D reconstruction. First, we apply visual geometry grounded transformer to two input images with very large parallax to obtain both intrinsic and extrinsic parameters, as well as the dense 3D scene reconstruction. Subsequently, we reproject reconstructed dense point cloud onto a designated reference view using the recovered camera parameters, achieving pixel-wise alignment and generating an initial stitched image. Finally, to further address potential artifacts such as holes or noise in the initial stitching, we propose a point-conditioned image diffusion module to obtain the refined result.Compared with existing methods, our solution is very large parallax tolerant and also provides results that fully preserve the geometric integrity of all pixels in the 3D photogrammetric context, enabling direct applicability to downstream 3D vision tasks such as SfM. Experimental results demonstrate that the proposed algorithm provides accurate stitching results for images with very large parallax, and outperforms the existing methods qualitatively and quantitatively.
RSL-BA: Rolling Shutter Line Bundle Adjustment
Aug 10, 2024
The line is a prevalent element in man-made environments, inherently encoding spatial structural information, thus making it a more robust choice for feature representation in practical applications. Despite its apparent advantages, previous rolling shutter bundle adjustment (RSBA) methods have only supported sparse feature points, which lack robustness, particularly in degenerate environments. In this paper, we introduce the first rolling shutter line-based bundle adjustment solution, RSL-BA. Specifically, we initially establish the rolling shutter camera line projection theory utilizing Pl\"ucker line parameterization. Subsequently, we derive a series of reprojection error formulations which are stable and efficient. Finally, we theoretically and experimentally demonstrate that our method can prevent three common degeneracies, one of which is first discovered in this paper. Extensive synthetic and real data experiments demonstrate that our method achieves efficiency and accuracy comparable to existing point-based rolling shutter bundle adjustment solutions.
DFR: Depth from Rotation by Uncalibrated Image Rectification with Latitudinal Motion Assumption
Jul 11, 2023Despite the increasing prevalence of rotating-style capture (e.g., surveillance cameras), conventional stereo rectification techniques frequently fail due to the rotation-dominant motion and small baseline between views. In this paper, we tackle the challenge of performing stereo rectification for uncalibrated rotating cameras. To that end, we propose Depth-from-Rotation (DfR), a novel image rectification solution that analytically rectifies two images with two-point correspondences and serves for further depth estimation. Specifically, we model the motion of a rotating camera as the camera rotates on a sphere with fixed latitude. The camera's optical axis lies perpendicular to the sphere's surface. We call this latitudinal motion assumption. Then we derive a 2-point analytical solver from directly computing the rectified transformations on the two images. We also present a self-adaptive strategy to reduce the geometric distortion after rectification. Extensive synthetic and real data experiments demonstrate that the proposed method outperforms existing works in effectiveness and efficiency by a significant margin.
Learning Local Features with Context Aggregation for Visual Localization
May 30, 2020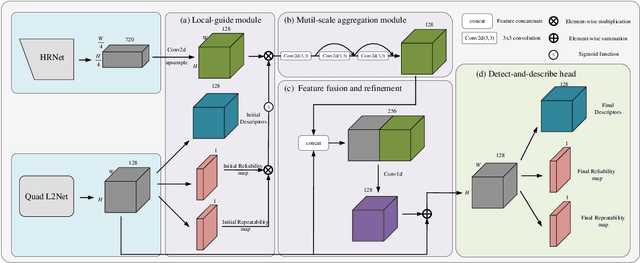
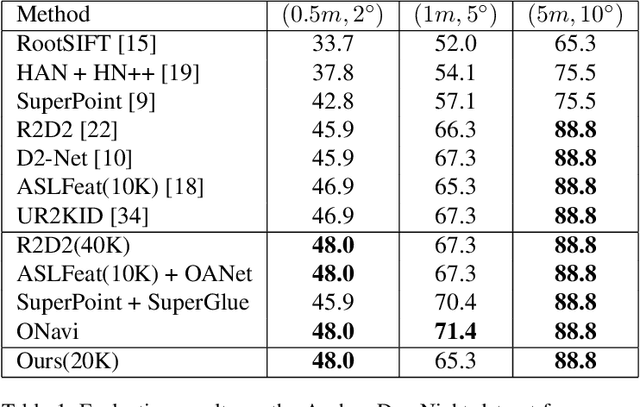
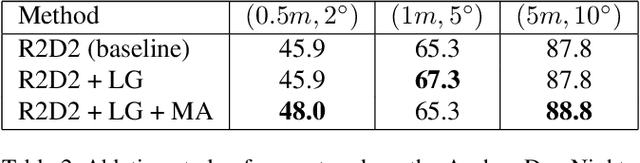

Keypoint detection and description is fundamental yet important in many vision applications. Most existing methods use detect-then-describe or detect-and-describe strategy to learn local features without considering their context information. Consequently, it is challenging for these methods to learn robust local features. In this paper, we focus on the fusion of low-level textual information and high-level semantic context information to improve the discrimitiveness of local features. Specifically, we first estimate a score map to represent the distribution of potential keypoints according to the quality of descriptors of all pixels. Then, we extract and aggregate multi-scale high-level semantic features based by the guidance of the score map. Finally, the low-level local features and high-level semantic features are fused and refined using a residual module. Experiments on the challenging local feature benchmark dataset demonstrate that our method achieves the state-of-the-art performance in the local feature challenge of the visual localization benchmark.