 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably learning a multi-head attention layer
Feb 06, 2024The multi-head attention layer is one of the key components of the transformer architecture that sets it apart from traditional feed-forward models. Given a sequence length $k$, attention matrices $\mathbf{\Theta}_1,\ldots,\mathbf{\Theta}_m\in\mathbb{R}^{d\times d}$, and projection matrices $\mathbf{W}_1,\ldots,\mathbf{W}_m\in\mathbb{R}^{d\times d}$, the corresponding multi-head attention layer $F: \mathbb{R}^{k\times d}\to \mathbb{R}^{k\times d}$ transforms length-$k$ sequences of $d$-dimensional tokens $\mathbf{X}\in\mathbb{R}^{k\times d}$ via $F(\mathbf{X}) \triangleq \sum^m_{i=1} \mathrm{softmax}(\mathbf{X}\mathbf{\Theta}_i\mathbf{X}^\top)\mathbf{X}\mathbf{W}_i$. In this work, we initiate the study of provably learning a multi-head attention layer from random examples and give the first nontrivial upper and lower bounds for this problem: - Provided $\{\mathbf{W}_i, \mathbf{\Theta}_i\}$ satisfy certain non-degeneracy conditions, we give a $(dk)^{O(m^3)}$-time algorithm that learns $F$ to small error given random labeled examples drawn uniformly from $\{\pm 1\}^{k\times d}$. - We prove computational lower bounds showing that in the worst case, exponential dependence on $m$ is unavoidable. We focus on Boolean $\mathbf{X}$ to mimic the discrete nature of tokens in large language models, though our techniques naturally extend to standard continuous settings, e.g. Gaussian. Our algorithm, which is centered around using examples to sculpt a convex body containing the unknown parameters, is a significant departure from existing provable algorithms for learning feedforward networks, which predominantly exploit algebraic and rotation invariance properties of the Gaussian distribution. In contrast, our analysis is more flexible as it primarily relies on various upper and lower tail bounds for the input distribution and "slices" thereof.
Futility and utility of a few ancillas for Pauli channel learning
Sep 25, 2023In this paper we revisit one of the prototypical tasks for characterizing the structure of noise in quantum devices, estimating the eigenvalues of an $n$-qubit Pauli noise channel. Prior work (Chen et al., 2022) established exponential lower bounds for this task for algorithms with limited quantum memory. We first improve upon their lower bounds and show: (1) Any algorithm without quantum memory must make $\Omega(2^n/\epsilon^2)$ measurements to estimate each eigenvalue within error $\epsilon$. This is tight and implies the randomized benchmarking protocol is optimal, resolving an open question of (Flammia and Wallman, 2020). (2) Any algorithm with $\le k$ ancilla qubits of quantum memory must make $\Omega(2^{(n-k)/3})$ queries to the unknown channel. Crucially, unlike in (Chen et al., 2022), our bound holds even if arbitrary adaptive control and channel concatenation are allowed. In fact these lower bounds, like those of (Chen et al., 2022), hold even for the easier hypothesis testing problem of determining whether the underlying channel is completely depolarizing or has exactly one other nontrivial eigenvalue. Surprisingly, we show that: (3) With only $k=2$ ancilla qubits of quantum memory, there is an algorithm that solves this hypothesis testing task with high probability using a single measurement. Note that (3) does not contradict (2) as the protocol concatenates exponentially many queries to the channel before the measurement. This result suggests a novel mechanism by which channel concatenation and $O(1)$ qubits of quantum memory could work in tandem to yield striking speedups for quantum process learning that are not possible for quantum state learning.
A faster and simpler algorithm for learning shallow networks
Jul 24, 2023We revisit the well-studied problem of learning a linear combination of $k$ ReLU activations given labeled examples drawn from the standard $d$-dimensional Gaussian measure. Chen et al. [CDG+23] recently gave the first algorithm for this problem to run in $\text{poly}(d,1/\varepsilon)$ time when $k = O(1)$, where $\varepsilon$ is the target error. More precisely, their algorithm runs in time $(d/\varepsilon)^{\mathrm{quasipoly}(k)}$ and learns over multiple stages. Here we show that a much simpler one-stage version of their algorithm suffices, and moreover its runtime is only $(d/\varepsilon)^{O(k^2)}$.
Learning Mixtures of Gaussians Using the DDPM Objective
Jul 03, 2023Recent works have shown that diffusion models can learn essentially any distribution provided one can perform score estimation. Yet it remains poorly understood under what settings score estimation is possible, let alone when practical gradient-based algorithms for this task can provably succeed. In this work, we give the first provably efficient results along these lines for one of the most fundamental distribution families, Gaussian mixture models. We prove that gradient descent on the denoising diffusion probabilistic model (DDPM) objective can efficiently recover the ground truth parameters of the mixture model in the following two settings: 1) We show gradient descent with random initialization learns mixtures of two spherical Gaussians in $d$ dimensions with $1/\text{poly}(d)$-separated centers. 2) We show gradient descent with a warm start learns mixtures of $K$ spherical Gaussians with $\Omega(\sqrt{\log(\min(K,d))})$-separated centers. A key ingredient in our proofs is a new connection between score-based methods and two other approaches to distribution learning, the EM algorithm and spectral methods.
The probability flow ODE is provably fast
May 19, 2023We provide the first polynomial-time convergence guarantees for the probability flow ODE implementation (together with a corrector step) of score-based generative modeling. Our analysis is carried out in the wake of recent results obtaining such guarantees for the SDE-based implementation (i.e., denoising diffusion probabilistic modeling or DDPM), but requires the development of novel techniques for studying deterministic dynamics without contractivity. Through the use of a specially chosen corrector step based on the underdamped Langevin diffusion, we obtain better dimension dependence than prior works on DDPM ($O(\sqrt{d})$ vs. $O(d)$, assuming smoothness of the data distribution), highlighting potential advantages of the ODE framework.
Learning Narrow One-Hidden-Layer ReLU Networks
Apr 20, 2023

We consider the well-studied problem of learning a linear combination of $k$ ReLU activations with respect to a Gaussian distribution on inputs in $d$ dimensions. We give the first polynomial-time algorithm that succeeds whenever $k$ is a constant. All prior polynomial-time learners require additional assumptions on the network, such as positive combining coefficients or the matrix of hidden weight vectors being well-conditioned. Our approach is based on analyzing random contractions of higher-order moment tensors. We use a multi-scale analysis to argue that sufficiently close neurons can be collapsed together, sidestepping the conditioning issues present in prior work. This allows us to design an iterative procedure to discover individual neurons.
Restoration-Degradation Beyond Linear Diffusions: A Non-Asymptotic Analysis For DDIM-Type Samplers
Mar 06, 2023We develop a framework for non-asymptotic analysis of deterministic samplers used for diffusion generative modeling. Several recent works have analyzed stochastic samplers using tools like Girsanov's theorem and a chain rule variant of the interpolation argument. Unfortunately, these techniques give vacuous bounds when applied to deterministic samplers. We give a new operational interpretation for deterministic sampling by showing that one step along the probability flow ODE can be expressed as two steps: 1) a restoration step that runs gradient ascent on the conditional log-likelihood at some infinitesimally previous time, and 2) a degradation step that runs the forward process using noise pointing back towards the current iterate. This perspective allows us to extend denoising diffusion implicit models to general, non-linear forward processes. We then develop the first polynomial convergence bounds for these samplers under mild conditions on the data distribution.
Learning to predict arbitrary quantum processes
Oct 27, 2022We present an efficient machine learning (ML) algorithm for predicting any unknown quantum process $\mathcal{E}$ over $n$ qubits. For a wide range of distributions $\mathcal{D}$ on arbitrary $n$-qubit states, we show that this ML algorithm can learn to predict any local property of the output from the unknown process $\mathcal{E}$, with a small average error over input states drawn from $\mathcal{D}$. The ML algorithm is computationally efficient even when the unknown process is a quantum circuit with exponentially many gates. Our algorithm combines efficient procedures for learning properties of an unknown state and for learning a low-degree approximation to an unknown observable. The analysis hinges on proving new norm inequalities, including a quantum analogue of the classical Bohnenblust-Hille inequality, which we derive by giving an improved algorithm for optimizing local Hamiltonians. Overall, our results highlight the potential for ML models to predict the output of complex quantum dynamics much faster than the time needed to run the process itself.
The Complexity of NISQ
Oct 13, 2022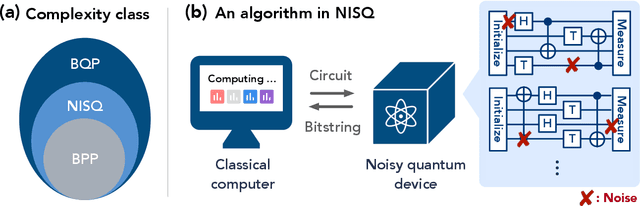
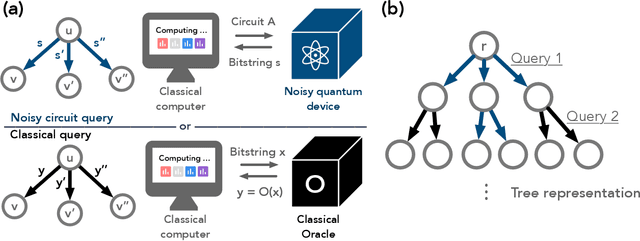
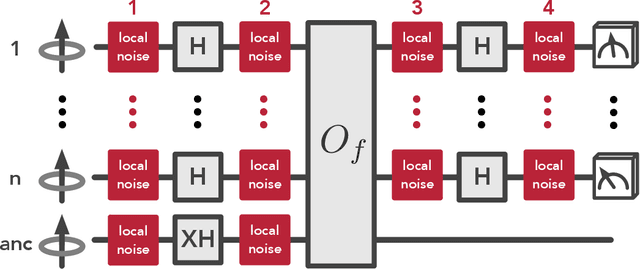
The recent proliferation of NISQ devices has made it imperative to understand their computational power. In this work, we define and study the complexity class $\textsf{NISQ} $, which is intended to encapsulate problems that can be efficiently solved by a classical computer with access to a NISQ device. To model existing devices, we assume the device can (1) noisily initialize all qubits, (2) apply many noisy quantum gates, and (3) perform a noisy measurement on all qubits. We first give evidence that $\textsf{BPP}\subsetneq \textsf{NISQ}\subsetneq \textsf{BQP}$, by demonstrating super-polynomial oracle separations among the three classes, based on modifications of Simon's problem. We then consider the power of $\textsf{NISQ}$ for three well-studied problems. For unstructured search, we prove that $\textsf{NISQ}$ cannot achieve a Grover-like quadratic speedup over $\textsf{BPP}$. For the Bernstein-Vazirani problem, we show that $\textsf{NISQ}$ only needs a number of queries logarithmic in what is required for $\textsf{BPP}$. Finally, for a quantum state learning problem, we prove that $\textsf{NISQ}$ is exponentially weaker than classical computation with access to noiseless constant-depth quantum circuits.
Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions
Oct 04, 2022We provide theoretical convergence guarantees for score-based generative models (SGMs) such as denoising diffusion probabilistic models (DDPMs), which constitute the backbone of large-scale real-world generative models such as DALL$\cdot$E 2. Our main result is that, assuming accurate score estimates, such SGMs can efficiently sample from essentially any realistic data distribution. In contrast to prior works, our results (1) hold for an $L^2$-accurate score estimate (rather than $L^\infty$-accurate); (2) do not require restrictive functional inequality conditions that preclude substantial non-log-concavity; (3) scale polynomially in all relevant problem parameters; and (4) match state-of-the-art complexity guarantees for discretization of the Langevin diffusion, provided that the score error is sufficiently small. We view this as strong theoretical justification for the empirical success of SGMs. We also examine SGMs based on the critically damped Langevin diffusion (CLD). Contrary to conventional wisdom, we provide evidence that the use of the CLD does not reduce the complexity of SGMs.