 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Cross-Lingual Retrieval with Multilingual Text Encoders
Dec 21, 2021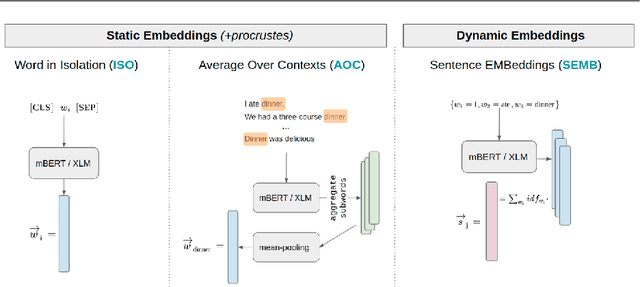
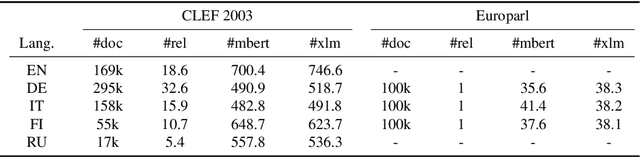
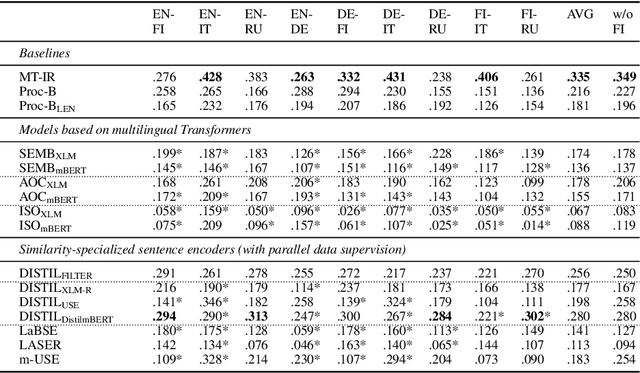
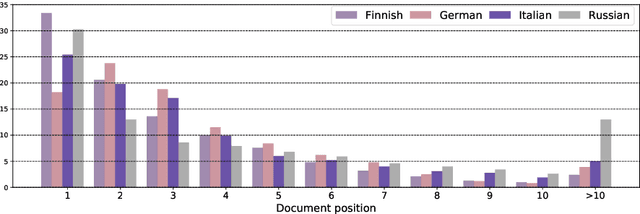
In this work we present a systematic empirical study focused on the suitability of the state-of-the-art multilingual encoders for cross-lingual document and sentence retrieval tasks across a number of diverse language pairs. We first treat these models as multilingual text encoders and benchmark their performance in unsupervised ad-hoc sentence- and document-level CLIR. In contrast to supervised language understanding, our results indicate that for unsupervised document-level CLIR -- a setup with no relevance judgments for IR-specific fine-tuning -- pretrained multilingual encoders on average fail to significantly outperform earlier models based on CLWEs. For sentence-level retrieval, we do obtain state-of-the-art performance: the peak scores, however, are met by multilingual encoders that have been further specialized, in a supervised fashion, for sentence understanding tasks, rather than using their vanilla 'off-the-shelf' variants. Following these results, we introduce localized relevance matching for document-level CLIR, where we independently score a query against document sections. In the second part, we evaluate multilingual encoders fine-tuned in a supervised fashion (i.e., we learn to rank) on English relevance data in a series of zero-shot language and domain transfer CLIR experiments. Our results show that supervised re-ranking rarely improves the performance of multilingual transformers as unsupervised base rankers. Finally, only with in-domain contrastive fine-tuning (i.e., same domain, only language transfer), we manage to improve the ranking quality. We uncover substantial empirical differences between cross-lingual retrieval results and results of (zero-shot) cross-lingual transfer for monolingual retrieval in target languages, which point to "monolingual overfitting" of retrieval models trained on monolingual data.
DS-TOD: Efficient Domain Specialization for Task Oriented Dialog
Oct 15, 2021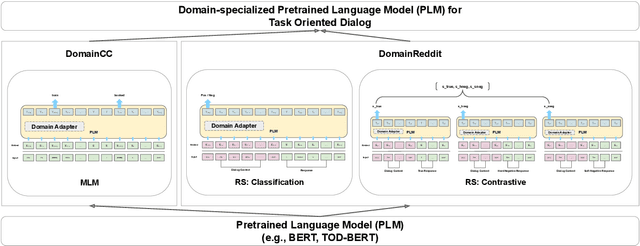
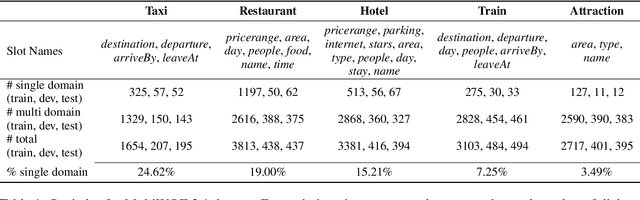
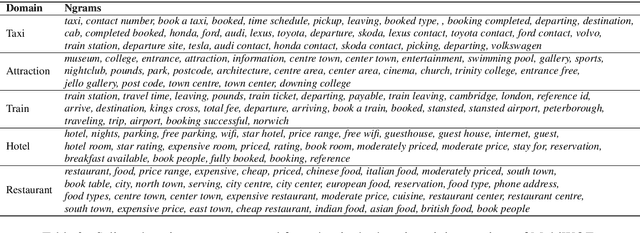
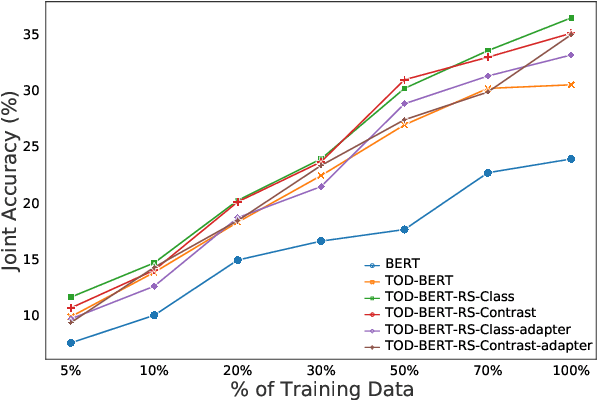
Recent work has shown that self-supervised dialog-specific pretraining on large conversational datasets yields substantial gains over traditional language modeling (LM) pretraining in downstream task-oriented dialog (TOD). These approaches, however, exploit general dialogic corpora (e.g., Reddit) and thus presumably fail to reliably embed domain-specific knowledge useful for concrete downstream TOD domains. In this work, we investigate the effects of domain specialization of pretrained language models (PLMs) for task-oriented dialog. Within our DS-TOD framework, we first automatically extract salient domain-specific terms, and then use them to construct DomainCC and DomainReddit -- resources that we leverage for domain-specific pretraining, based on (i) masked language modeling (MLM) and (ii) response selection (RS) objectives, respectively. We further propose a resource-efficient and modular domain specialization by means of domain adapters -- additional parameter-light layers in which we encode the domain knowledge. Our experiments with two prominent TOD tasks -- dialog state tracking (DST) and response retrieval (RR) -- encompassing five domains from the MultiWOZ TOD benchmark demonstrate the effectiveness of our domain specialization approach. Moreover, we show that the light-weight adapter-based specialization (1) performs comparably to full fine-tuning in single-domain setups and (2) is particularly suitable for multi-domain specialization, in which, besides advantageous computational footprint, it can offer better downstream performance.
Diachronic Analysis of German Parliamentary Proceedings: Ideological Shifts through the Lens of Political Biases
Aug 13, 2021
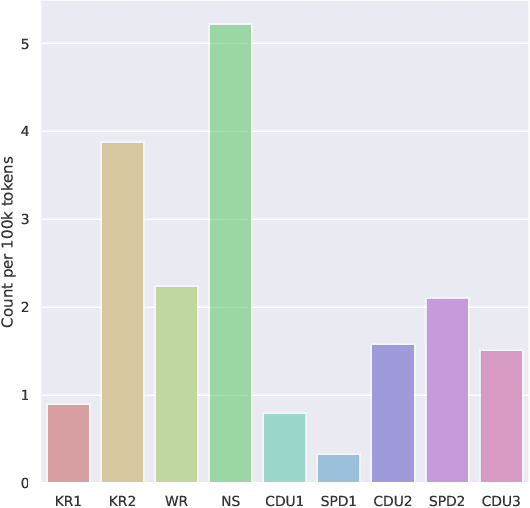

We analyze bias in historical corpora as encoded in diachronic distributional semantic models by focusing on two specific forms of bias, namely a political (i.e., anti-communism) and racist (i.e., antisemitism) one. For this, we use a new corpus of German parliamentary proceedings, DeuPARL, spanning the period 1867--2020. We complement this analysis of historical biases in diachronic word embeddings with a novel measure of bias on the basis of term co-occurrences and graph-based label propagation. The results of our bias measurements align with commonly perceived historical trends of antisemitic and anti-communist biases in German politics in different time periods, thus indicating the viability of analyzing historical bias trends using semantic spaces induced from historical corpora.
Large-scale Taxonomy Induction Using Entity and Word Embeddings
May 04, 2021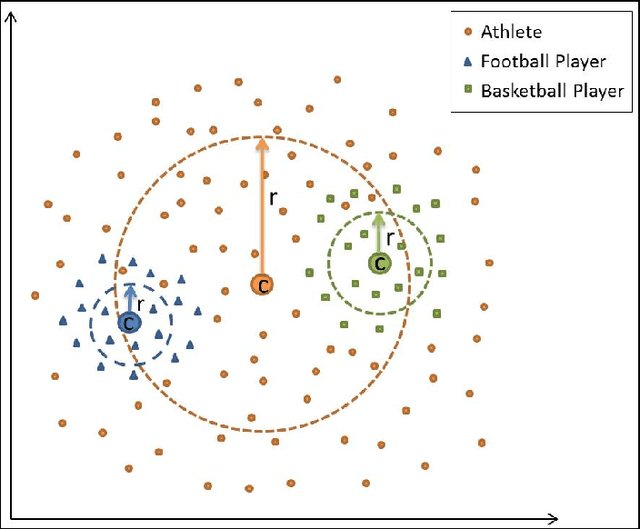
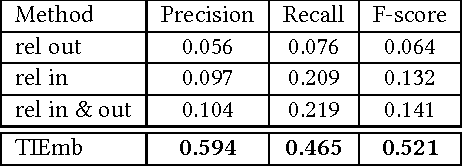

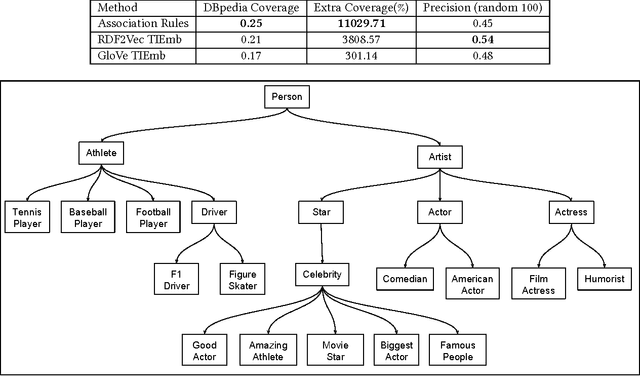
Taxonomies are an important ingredient of knowledge organization, and serve as a backbone for more sophisticated knowledge representations in intelligent systems, such as formal ontologies. However, building taxonomies manually is a costly endeavor, and hence, automatic methods for taxonomy induction are a good alternative to build large-scale taxonomies. In this paper, we propose TIEmb, an approach for automatic unsupervised class subsumption axiom extraction from knowledge bases using entity and text embeddings. We apply the approach on the WebIsA database, a database of subsumption relations extracted from the large portion of the World Wide Web, to extract class hierarchies in the Person and Place domain.
DebIE: A Platform for Implicit and Explicit Debiasing of Word Embedding Spaces
Mar 11, 2021
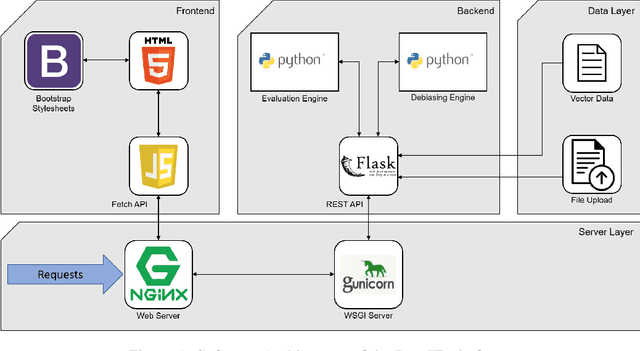
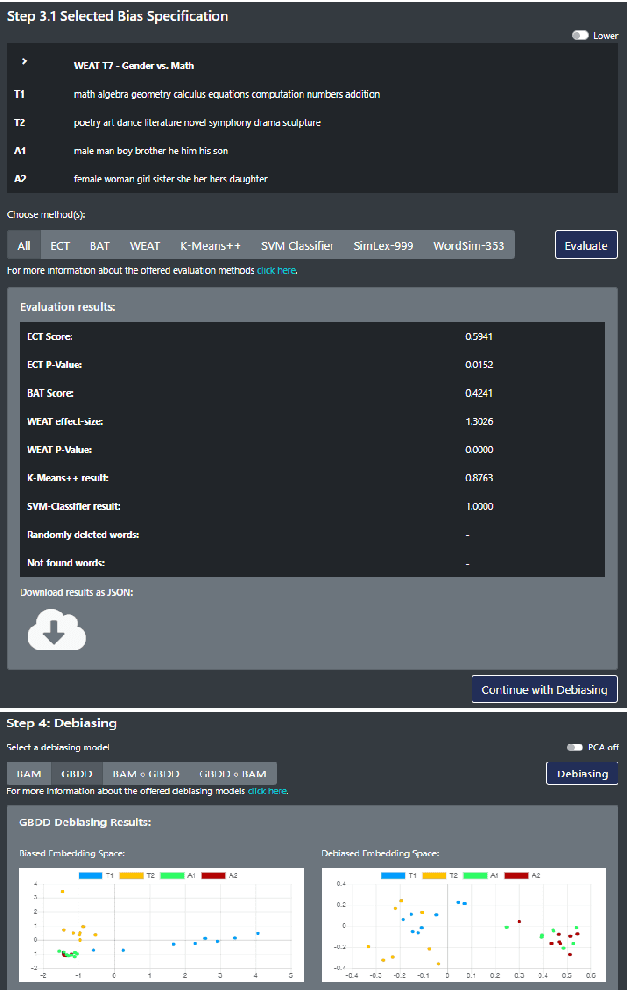
Recent research efforts in NLP have demonstrated that distributional word vector spaces often encode stereotypical human biases, such as racism and sexism. With word representations ubiquitously used in NLP models and pipelines, this raises ethical issues and jeopardizes the fairness of language technologies. While there exists a large body of work on bias measures and debiasing methods, to date, there is no platform that would unify these research efforts and make bias measuring and debiasing of representation spaces widely accessible. In this work, we present DebIE, the first integrated platform for (1) measuring and (2) mitigating bias in word embeddings. Given an (i) embedding space (users can choose between the predefined spaces or upload their own) and (ii) a bias specification (users can choose between existing bias specifications or create their own), DebIE can (1) compute several measures of implicit and explicit bias and modify the embedding space by executing two (mutually composable) debiasing models. DebIE's functionality can be accessed through four different interfaces: (a) a web application, (b) a desktop application, (c) a REST-ful API, and (d) as a command-line application. DebIE is available at: debie.informatik.uni-mannheim.de.
FakeFlow: Fake News Detection by Modeling the Flow of Affective Information
Jan 24, 2021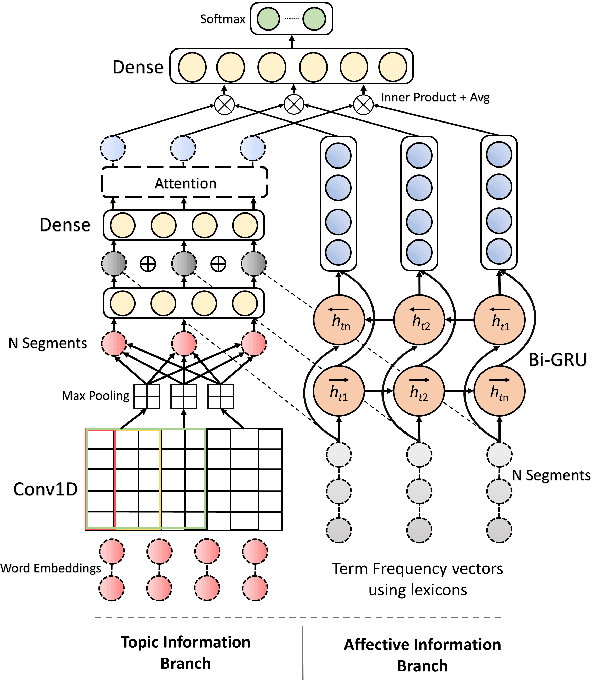

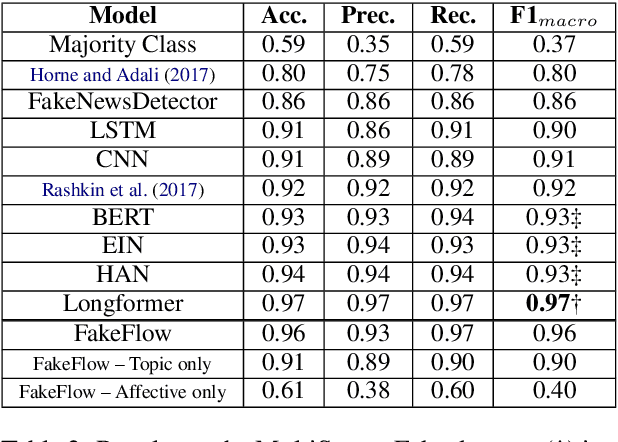
Fake news articles often stir the readers' attention by means of emotional appeals that arouse their feelings. Unlike in short news texts, authors of longer articles can exploit such affective factors to manipulate readers by adding exaggerations or fabricating events, in order to affect the readers' emotions. To capture this, we propose in this paper to model the flow of affective information in fake news articles using a neural architecture. The proposed model, FakeFlow, learns this flow by combining topic and affective information extracted from text. We evaluate the model's performance with several experiments on four real-world datasets. The results show that FakeFlow achieves superior results when compared against state-of-the-art methods, thus confirming the importance of capturing the flow of the affective information in news articles.
Evaluating Multilingual Text Encoders for Unsupervised Cross-Lingual Retrieval
Jan 21, 2021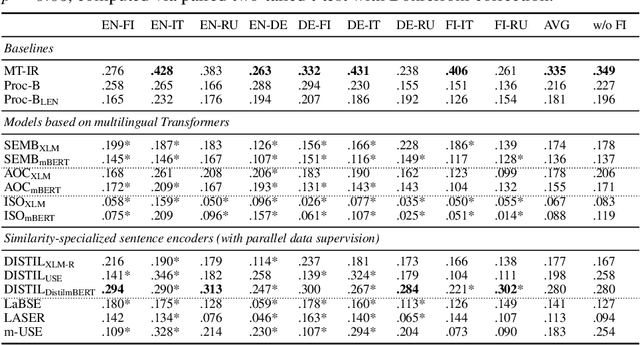
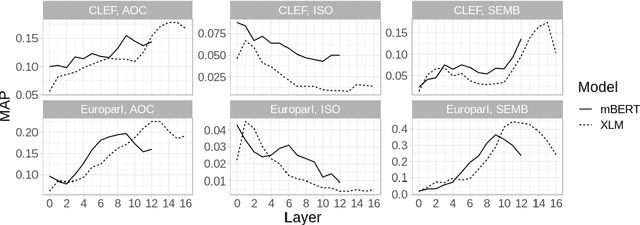
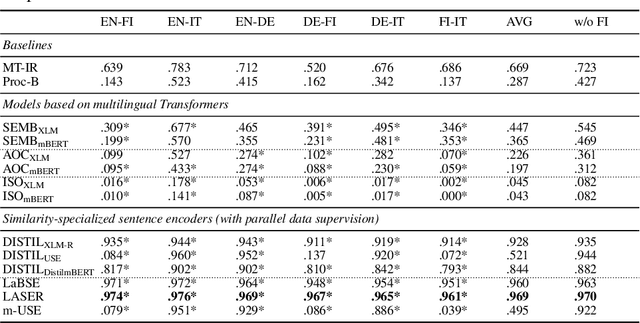
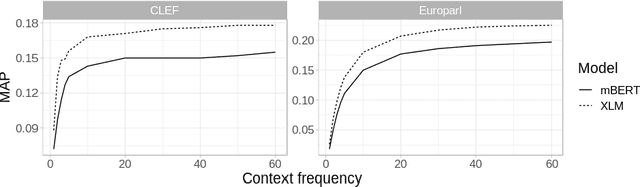
Pretrained multilingual text encoders based on neural Transformer architectures, such as multilingual BERT (mBERT) and XLM, have achieved strong performance on a myriad of language understanding tasks. Consequently, they have been adopted as a go-to paradigm for multilingual and cross-lingual representation learning and transfer, rendering cross-lingual word embeddings (CLWEs) effectively obsolete. However, questions remain to which extent this finding generalizes 1) to unsupervised settings and 2) for ad-hoc cross-lingual IR (CLIR) tasks. Therefore, in this work we present a systematic empirical study focused on the suitability of the state-of-the-art multilingual encoders for cross-lingual document and sentence retrieval tasks across a large number of language pairs. In contrast to supervised language understanding, our results indicate that for unsupervised document-level CLIR -- a setup with no relevance judgments for IR-specific fine-tuning -- pretrained encoders fail to significantly outperform models based on CLWEs. For sentence-level CLIR, we demonstrate that state-of-the-art performance can be achieved. However, the peak performance is not met using the general-purpose multilingual text encoders `off-the-shelf', but rather relying on their variants that have been further specialized for sentence understanding tasks.
Self-Supervised Learning for Visual Summary Identification in Scientific Publications
Jan 14, 2021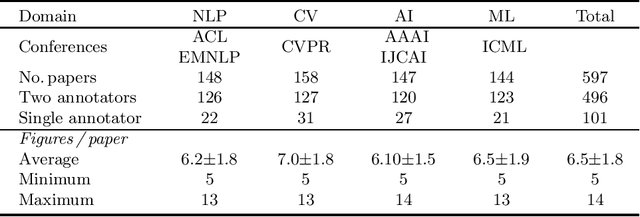
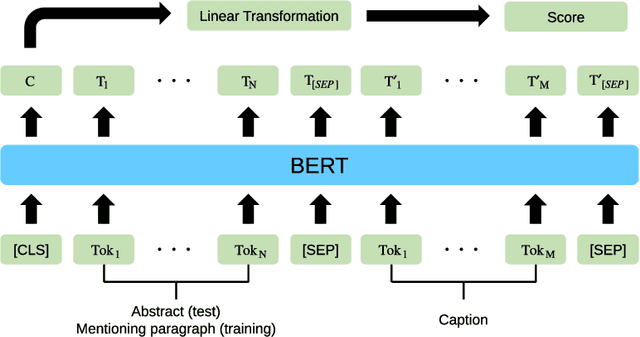
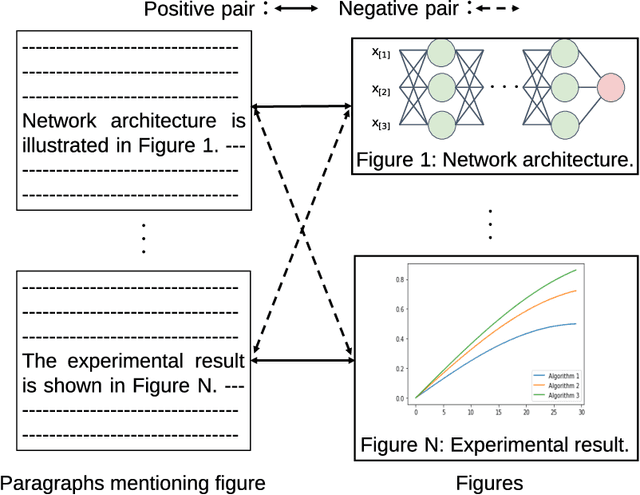

Providing visual summaries of scientific publications can increase information access for readers and thereby help deal with the exponential growth in the number of scientific publications. Nonetheless, efforts in providing visual publication summaries have been few and far apart, primarily focusing on the biomedical domain. This is primarily because of the limited availability of annotated gold standards, which hampers the application of robust and high-performing supervised learning techniques. To address these problems we create a new benchmark dataset for selecting figures to serve as visual summaries of publications based on their abstracts, covering several domains in computer science. Moreover, we develop a self-supervised learning approach, based on heuristic matching of inline references to figures with figure captions. Experiments in both biomedical and computer science domains show that our model is able to outperform the state of the art despite being self-supervised and therefore not relying on any annotated training data.
AraWEAT: Multidimensional Analysis of Biases in Arabic Word Embeddings
Nov 03, 2020

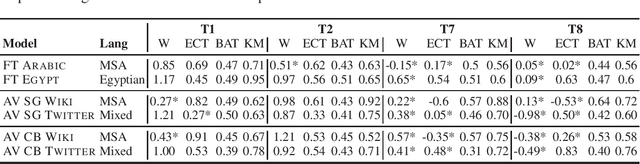

Recent work has shown that distributional word vector spaces often encode human biases like sexism or racism. In this work, we conduct an extensive analysis of biases in Arabic word embeddings by applying a range of recently introduced bias tests on a variety of embedding spaces induced from corpora in Arabic. We measure the presence of biases across several dimensions, namely: embedding models (Skip-Gram, CBOW, and FastText) and vector sizes, types of text (encyclopedic text, and news vs. user-generated content), dialects (Egyptian Arabic vs. Modern Standard Arabic), and time (diachronic analyses over corpora from different time periods). Our analysis yields several interesting findings, e.g., that implicit gender bias in embeddings trained on Arabic news corpora steadily increases over time (between 2007 and 2017). We make the Arabic bias specifications (AraWEAT) publicly available.
Word Sense Disambiguation for 158 Languages using Word Embeddings Only
Mar 14, 2020
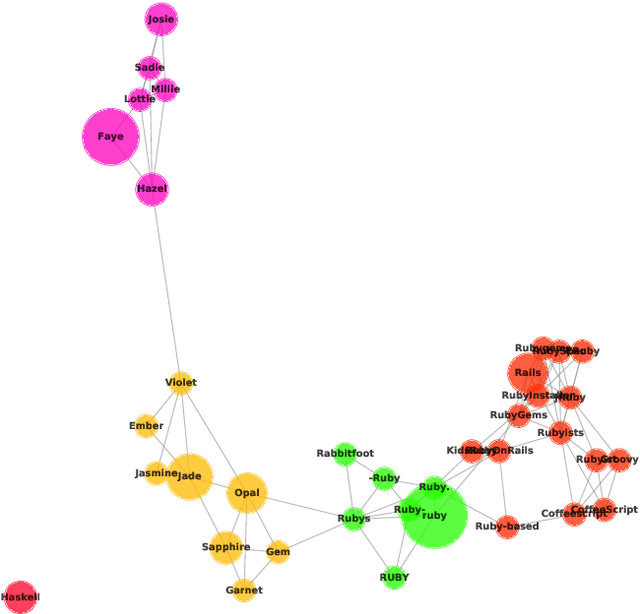

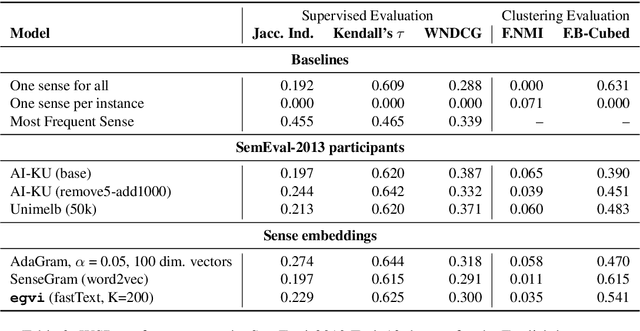
Disambiguation of word senses in context is easy for humans, but is a major challenge for automatic approaches. Sophisticated supervised and knowledge-based models were developed to solve this task. However, (i) the inherent Zipfian distribution of supervised training instances for a given word and/or (ii) the quality of linguistic knowledge representations motivate the development of completely unsupervised and knowledge-free approaches to word sense disambiguation (WSD). They are particularly useful for under-resourced languages which do not have any resources for building either supervised and/or knowledge-based models. In this paper, we present a method that takes as input a standard pre-trained word embedding model and induces a fully-fledged word sense inventory, which can be used for disambiguation in context. We use this method to induce a collection of sense inventories for 158 languages on the basis of the original pre-trained fastText word embeddings by Grave et al. (2018), enabling WSD in these languages. Models and system are available online.