 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Edge Deletion: A Comprehensive Approach to Counterfactual Explanation in Graph Neural Networks
Mar 04, 2026Graph Neural Networks (GNNs) are increasingly adopted across domains such as molecular biology and social network analysis, yet their black-box nature hinders interpretability and trust. This is especially problematic in high-stakes applications, such as predicting molecule toxicity, drug discovery, or guiding financial fraud detections, where transparent explanations are essential. Counterfactual explanations - minimal changes that flip a model's prediction - offer a transparent lens into GNNs' behavior. In this work, we introduce XPlore, a novel technique that significantly broadens the counterfactual search space. It consists of gradient-guided perturbations to adjacency and node feature matrices. Unlike most prior methods, which focus solely on edge deletions, our approach belongs to the growing class of techniques that optimize edge insertions and node-feature perturbations, here jointly performed under a unified gradient-based framework, enabling a richer and more nuanced exploration of counterfactuals. To quantify both structural and semantic fidelity, we introduce a cosine similarity metric for learned graph embeddings that addresses a key limitation of traditional distance-based metrics, and demonstrate that XPlore produces more coherent and minimal counterfactuals. Empirical results on 13 real-world and 5 synthetic benchmarks show up to +56.3% improvement in validity and +52.8% in fidelity over state-of-the-art baselines, while retaining competitive runtime.
A Multi-Agent Framework for Interpreting Multivariate Physiological Time Series
Mar 04, 2026Continuous physiological monitoring is central to emergency care, yet deploying trustworthy AI is challenging. While LLMs can translate complex physiological signals into clinical narratives, it is unclear how agentic systems perform relative to zero-shot inference. To address these questions, we present Vivaldi, a role-structured multi-agent system that explains multivariate physiological time series. Due to regulatory constraints that preclude live deployment, we instantiate Vivaldi in a controlled, clinical pilot to a small, highly qualified cohort of emergency medicine experts, whose evaluations reveal a context-dependent picture that contrasts with prevailing assumptions that agentic reasoning uniformly improves performance. Our experiments show that agentic pipelines substantially benefit non-thinking and medically fine-tuned models, improving expert-rated explanation justification and relevance by +6.9 and +9.7 points, respectively. Contrarily, for thinking models, agentic orchestration often degrades explanation quality, including a 14-point drop in relevance, while improving diagnostic precision (ESI F1 +3.6). We also find that explicit tool-based computation is decisive for codifiable clinical metrics, whereas subjective targets, such as pain scores and length of stay, show limited or inconsistent changes. Expert evaluation further indicates that gains in clinical utility depend on visualization conventions, with medically specialized models achieving the most favorable trade-offs between utility and clarity. Together, these findings show that the value of agentic AI lies in the selective externalization of computation and structure rather than in maximal reasoning complexity, and highlight concrete design trade-offs and learned lessons, broadly applicable to explainable AI in safety-critical healthcare settings.
Large-scale Taxonomy Induction Using Entity and Word Embeddings
May 04, 2021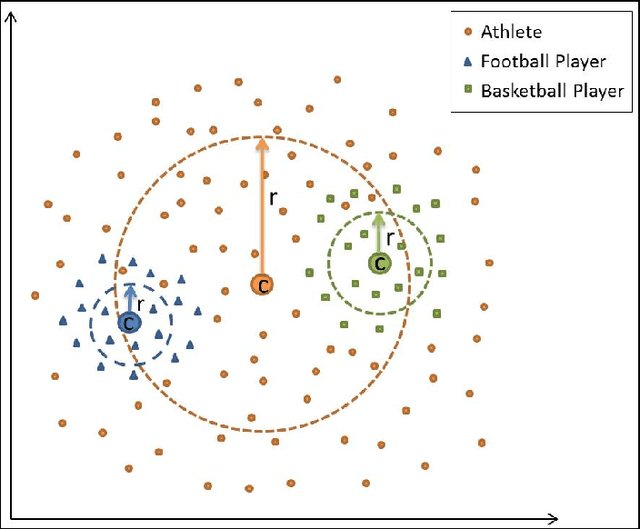
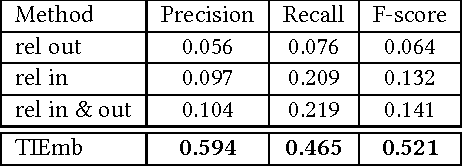

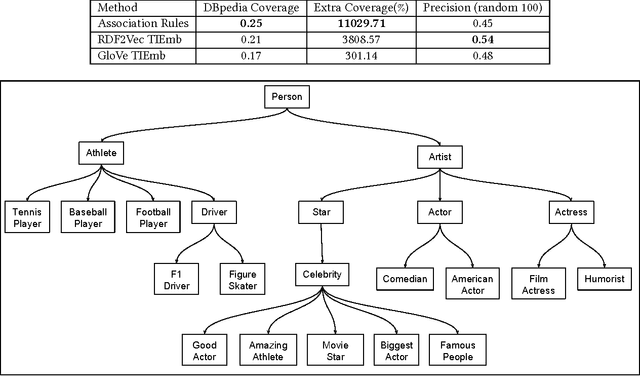
Taxonomies are an important ingredient of knowledge organization, and serve as a backbone for more sophisticated knowledge representations in intelligent systems, such as formal ontologies. However, building taxonomies manually is a costly endeavor, and hence, automatic methods for taxonomy induction are a good alternative to build large-scale taxonomies. In this paper, we propose TIEmb, an approach for automatic unsupervised class subsumption axiom extraction from knowledge bases using entity and text embeddings. We apply the approach on the WebIsA database, a database of subsumption relations extracted from the large portion of the World Wide Web, to extract class hierarchies in the Person and Place domain.
Enriching Frame Representations with Distributionally Induced Senses
Mar 15, 2018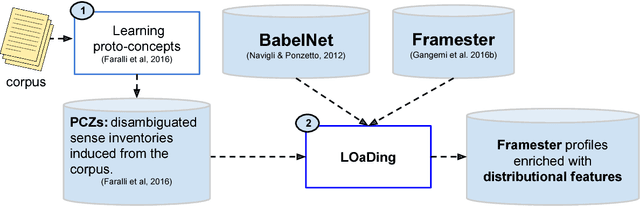

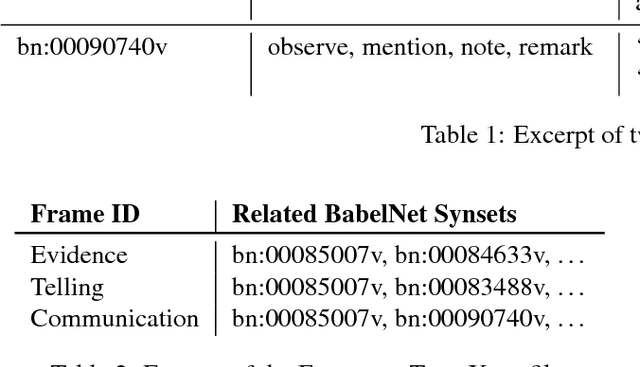
We introduce a new lexical resource that enriches the Framester knowledge graph, which links Framnet, WordNet, VerbNet and other resources, with semantic features from text corpora. These features are extracted from distributionally induced sense inventories and subsequently linked to the manually-constructed frame representations to boost the performance of frame disambiguation in context. Since Framester is a frame-based knowledge graph, which enables full-fledged OWL querying and reasoning, our resource paves the way for the development of novel, deeper semantic-aware applications that could benefit from the combination of knowledge from text and complex symbolic representations of events and participants. Together with the resource we also provide the software we developed for the evaluation in the task of Word Frame Disambiguation (WFD).
Building a Web-Scale Dependency-Parsed Corpus from CommonCrawl
Feb 28, 2018


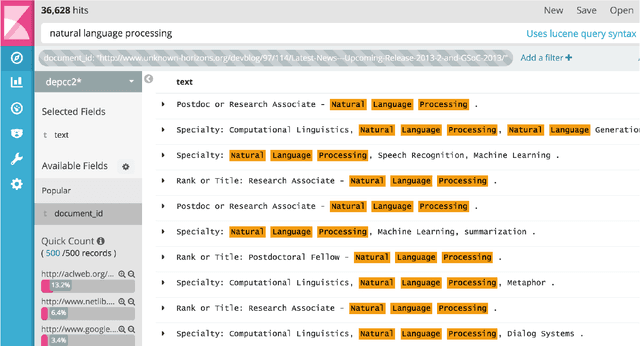
We present DepCC, the largest-to-date linguistically analyzed corpus in English including 365 million documents, composed of 252 billion tokens and 7.5 billion of named entity occurrences in 14.3 billion sentences from a web-scale crawl of the \textsc{Common Crawl} project. The sentences are processed with a dependency parser and with a named entity tagger and contain provenance information, enabling various applications ranging from training syntax-based word embeddings to open information extraction and question answering. We built an index of all sentences and their linguistic meta-data enabling quick search across the corpus. We demonstrate the utility of this corpus on the verb similarity task by showing that a distributional model trained on our corpus yields better results than models trained on smaller corpora, like Wikipedia. This distributional model outperforms the state of art models of verb similarity trained on smaller corpora on the SimVerb3500 dataset.
Improving Hypernymy Extraction with Distributional Semantic Classes
Feb 28, 2018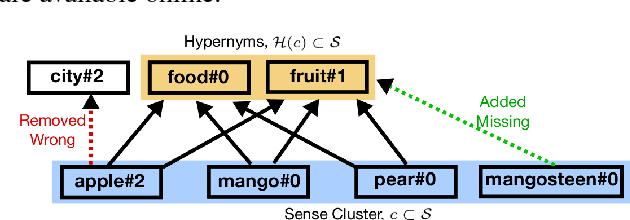

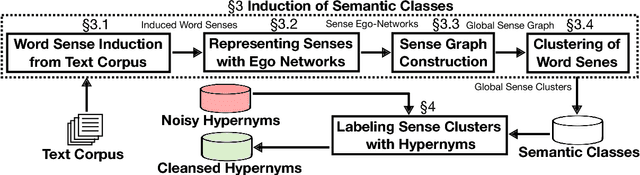

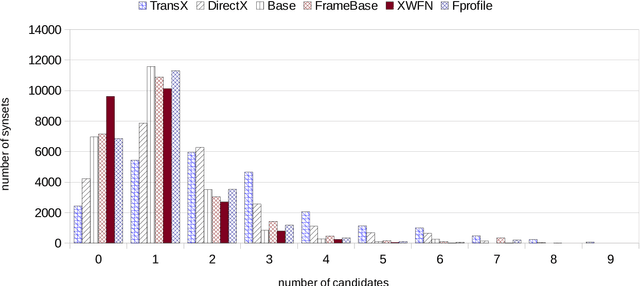
In this paper, we show how distributionally-induced semantic classes can be helpful for extracting hypernyms. We present methods for inducing sense-aware semantic classes using distributional semantics and using these induced semantic classes for filtering noisy hypernymy relations. Denoising of hypernyms is performed by labeling each semantic class with its hypernyms. On the one hand, this allows us to filter out wrong extractions using the global structure of distributionally similar senses. On the other hand, we infer missing hypernyms via label propagation to cluster terms. We conduct a large-scale crowdsourcing study showing that processing of automatically extracted hypernyms using our approach improves the quality of the hypernymy extraction in terms of both precision and recall. Furthermore, we show the utility of our method in the domain taxonomy induction task, achieving the state-of-the-art results on a SemEval'16 task on taxonomy induction.
A Framework for Enriching Lexical Semantic Resources with Distributional Semantics
Dec 23, 2017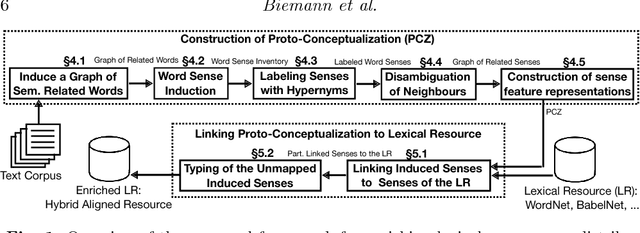
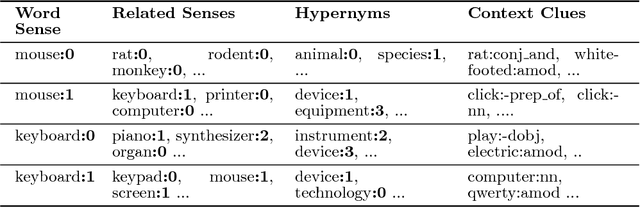


We present an approach to combining distributional semantic representations induced from text corpora with manually constructed lexical-semantic networks. While both kinds of semantic resources are available with high lexical coverage, our aligned resource combines the domain specificity and availability of contextual information from distributional models with the conciseness and high quality of manually crafted lexical networks. We start with a distributional representation of induced senses of vocabulary terms, which are accompanied with rich context information given by related lexical items. We then automatically disambiguate such representations to obtain a full-fledged proto-conceptualization, i.e. a typed graph of induced word senses. In a final step, this proto-conceptualization is aligned to a lexical ontology, resulting in a hybrid aligned resource. Moreover, unmapped induced senses are associated with a semantic type in order to connect them to the core resource. Manual evaluations against ground-truth judgments for different stages of our method as well as an extrinsic evaluation on a knowledge-based Word Sense Disambiguation benchmark all indicate the high quality of the new hybrid resource. Additionally, we show the benefits of enriching top-down lexical knowledge resources with bottom-up distributional information from text for addressing high-end knowledge acquisition tasks such as cleaning hypernym graphs and learning taxonomies from scratch.
Unsupervised, Knowledge-Free, and Interpretable Word Sense Disambiguation
Jul 21, 2017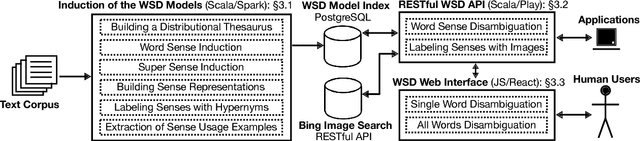
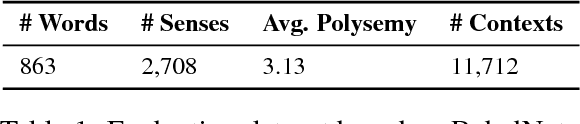
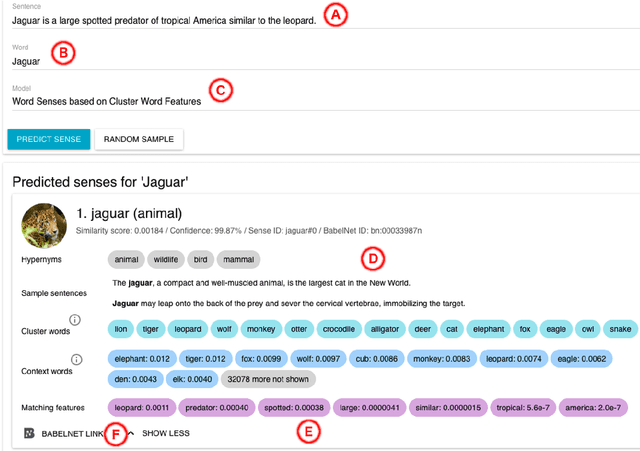

Interpretability of a predictive model is a powerful feature that gains the trust of users in the correctness of the predictions. In word sense disambiguation (WSD), knowledge-based systems tend to be much more interpretable than knowledge-free counterparts as they rely on the wealth of manually-encoded elements representing word senses, such as hypernyms, usage examples, and images. We present a WSD system that bridges the gap between these two so far disconnected groups of methods. Namely, our system, providing access to several state-of-the-art WSD models, aims to be interpretable as a knowledge-based system while it remains completely unsupervised and knowledge-free. The presented tool features a Web interface for all-word disambiguation of texts that makes the sense predictions human readable by providing interpretable word sense inventories, sense representations, and disambiguation results. We provide a public API, enabling seamless integration.