 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow many Observations are Enough? Knowledge Distillation for Trajectory Forecasting
Mar 09, 2022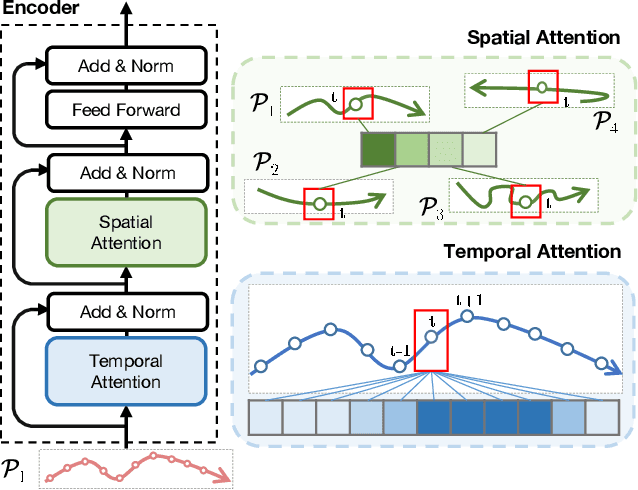
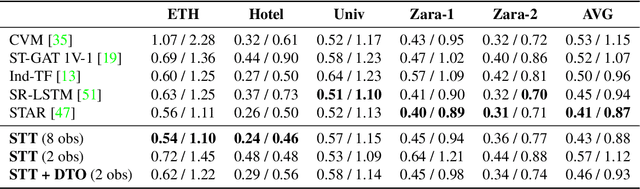
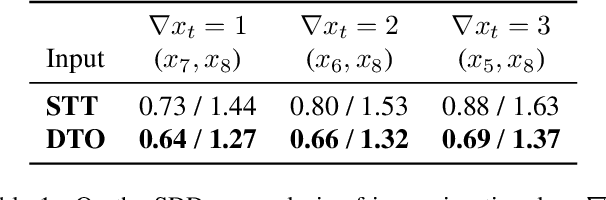
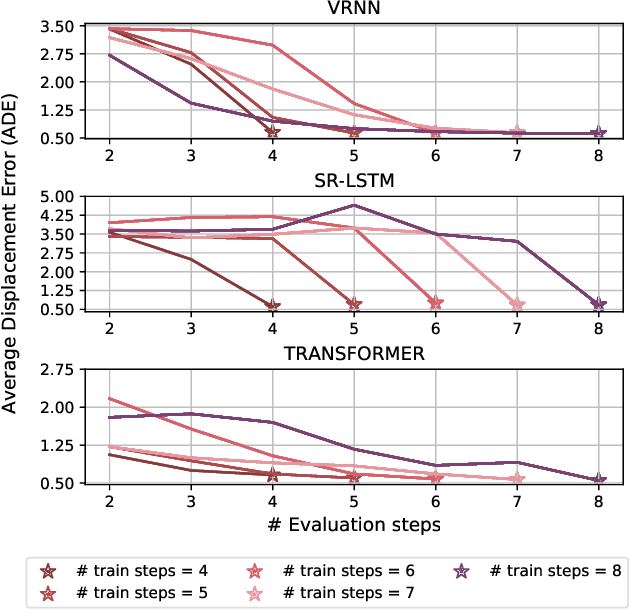
Accurate prediction of future human positions is an essential task for modern video-surveillance systems. Current state-of-the-art models usually rely on a "history" of past tracked locations (e.g., 3 to 5 seconds) to predict a plausible sequence of future locations (e.g., up to the next 5 seconds). We feel that this common schema neglects critical traits of realistic applications: as the collection of input trajectories involves machine perception (i.e., detection and tracking), incorrect detection and fragmentation errors may accumulate in crowded scenes, leading to tracking drifts. On this account, the model would be fed with corrupted and noisy input data, thus fatally affecting its prediction performance. In this regard, we focus on delivering accurate predictions when only few input observations are used, thus potentially lowering the risks associated with automatic perception. To this end, we conceive a novel distillation strategy that allows a knowledge transfer from a teacher network to a student one, the latter fed with fewer observations (just two ones). We show that a properly defined teacher supervision allows a student network to perform comparably to state-of-the-art approaches that demand more observations. Besides, extensive experiments on common trajectory forecasting datasets highlight that our student network better generalizes to unseen scenarios.
Class-Incremental Continual Learning into the eXtended DER-verse
Jan 03, 2022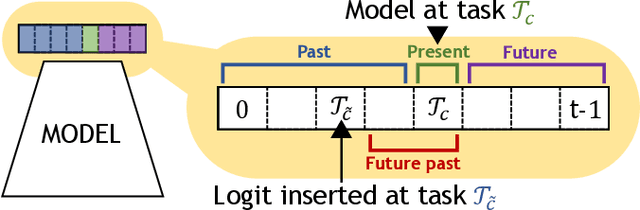
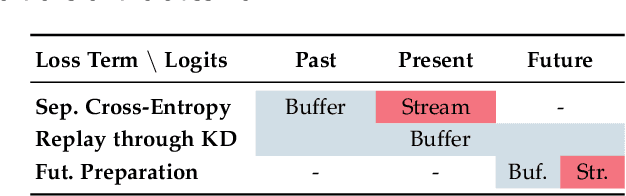

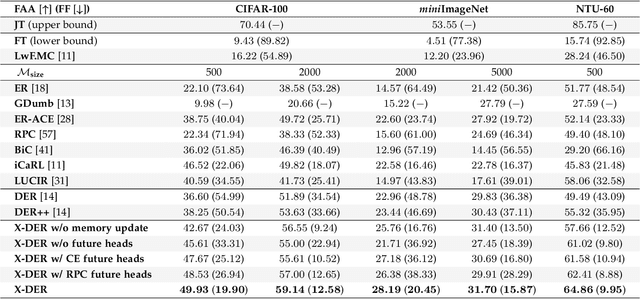
The staple of human intelligence is the capability of acquiring knowledge in a continuous fashion. In stark contrast, Deep Networks forget catastrophically and, for this reason, the sub-field of Class-Incremental Continual Learning fosters methods that learn a sequence of tasks incrementally, blending sequentially-gained knowledge into a comprehensive prediction. This work aims at assessing and overcoming the pitfalls of our previous proposal Dark Experience Replay (DER), a simple and effective approach that combines rehearsal and Knowledge Distillation. Inspired by the way our minds constantly rewrite past recollections and set expectations for the future, we endow our model with the abilities to i) revise its replay memory to welcome novel information regarding past data ii) pave the way for learning yet unseen classes. We show that the application of these strategies leads to remarkable improvements; indeed, the resulting method - termed eXtended-DER (X-DER) - outperforms the state of the art on both standard benchmarks (such as CIFAR-100 and miniImagenet) and a novel one here introduced. To gain a better understanding, we further provide extensive ablation studies that corroborate and extend the findings of our previous research (e.g. the value of Knowledge Distillation and flatter minima in continual learning setups).
MOTSynth: How Can Synthetic Data Help Pedestrian Detection and Tracking?
Aug 21, 2021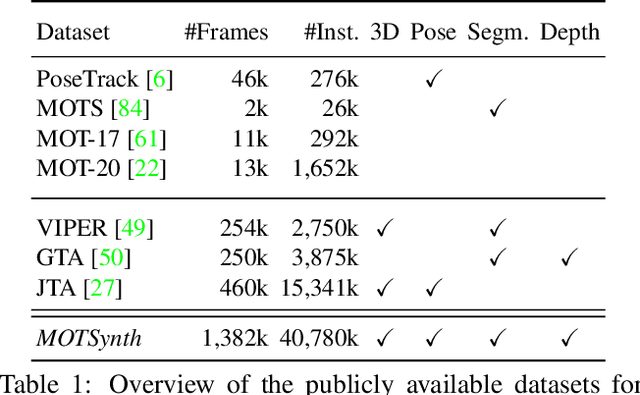

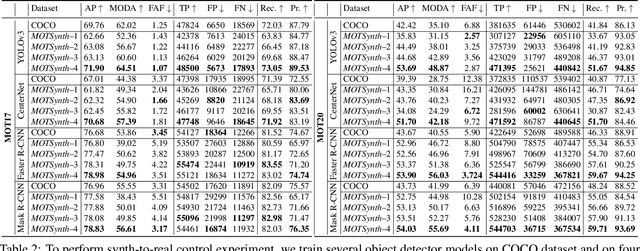
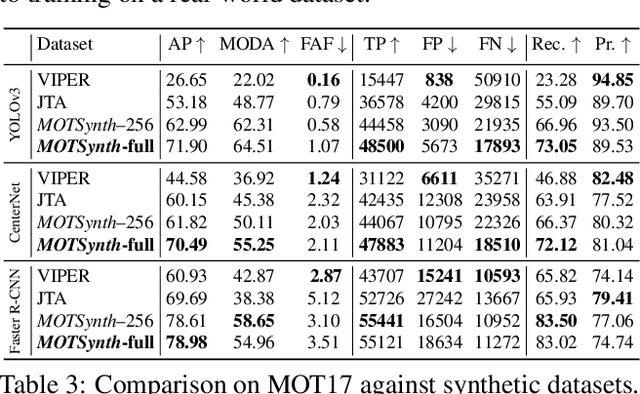
Deep learning-based methods for video pedestrian detection and tracking require large volumes of training data to achieve good performance. However, data acquisition in crowded public environments raises data privacy concerns -- we are not allowed to simply record and store data without the explicit consent of all participants. Furthermore, the annotation of such data for computer vision applications usually requires a substantial amount of manual effort, especially in the video domain. Labeling instances of pedestrians in highly crowded scenarios can be challenging even for human annotators and may introduce errors in the training data. In this paper, we study how we can advance different aspects of multi-person tracking using solely synthetic data. To this end, we generate MOTSynth, a large, highly diverse synthetic dataset for object detection and tracking using a rendering game engine. Our experiments show that MOTSynth can be used as a replacement for real data on tasks such as pedestrian detection, re-identification, segmentation, and tracking.
Weakly Supervised Continual Learning
Aug 14, 2021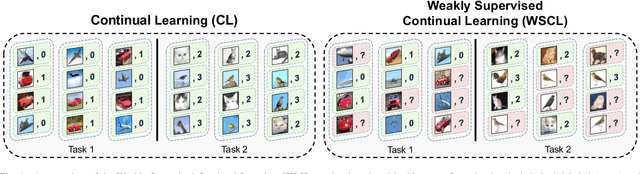
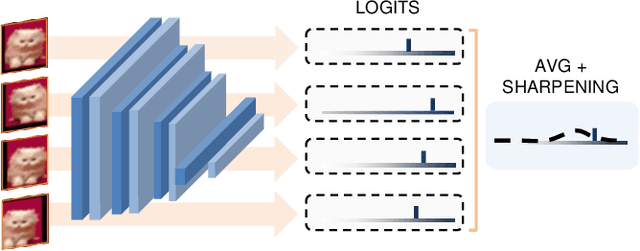
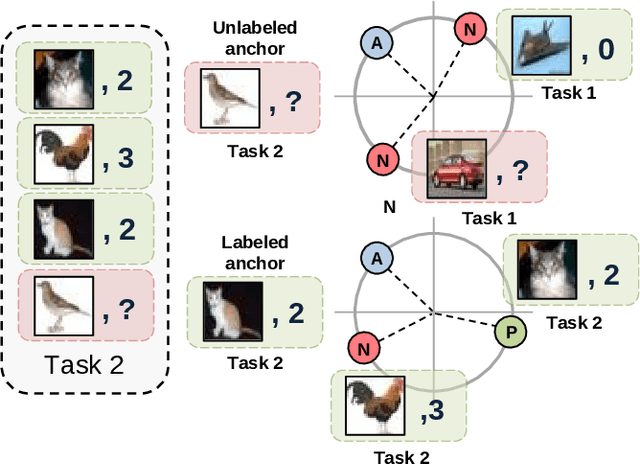
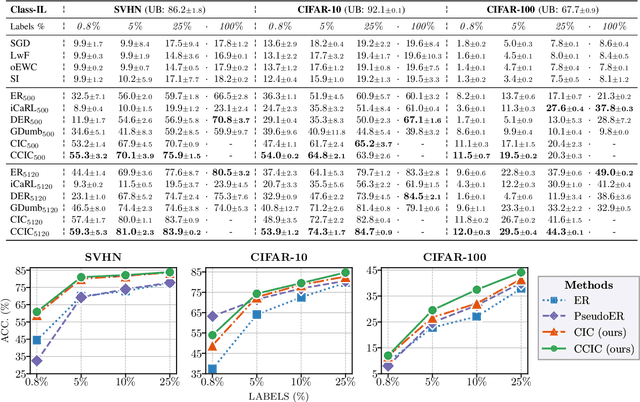
Continual Learning (CL) investigates how to train Deep Networks on a stream of tasks without incurring catastrophic forgetting. CL settings proposed in the literature assume that every incoming example is paired with ground-truth annotations. However, this clashes with many real-world applications: gathering labeled data, which is in itself tedious and expensive, becomes indeed infeasible when data flow as a stream and must be consumed in real-time. This work explores Weakly Supervised Continual Learning (WSCL): here, only a small fraction of labeled input examples are shown to the learner. We assess how current CL methods (e.g.: EWC, LwF, iCaRL, ER, GDumb, DER) perform in this novel and challenging scenario, in which overfitting entangles forgetting. Subsequently, we design two novel WSCL methods which exploit metric learning and consistency regularization to leverage unsupervised data while learning. In doing so, we show that not only our proposals exhibit higher flexibility when supervised information is scarce, but also that less than 25% labels can be enough to reach or even outperform SOTA methods trained under full supervision.
Avalanche: an End-to-End Library for Continual Learning
Apr 01, 2021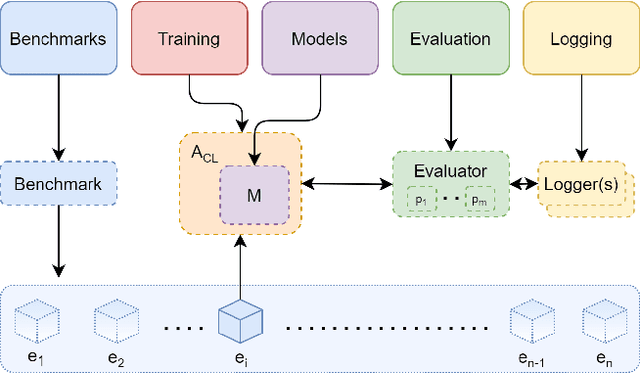

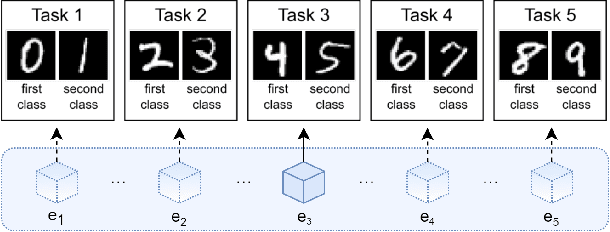

Learning continually from non-stationary data streams is a long-standing goal and a challenging problem in machine learning. Recently, we have witnessed a renewed and fast-growing interest in continual learning, especially within the deep learning community. However, algorithmic solutions are often difficult to re-implement, evaluate and port across different settings, where even results on standard benchmarks are hard to reproduce. In this work, we propose Avalanche, an open-source end-to-end library for continual learning research based on PyTorch. Avalanche is designed to provide a shared and collaborative codebase for fast prototyping, training, and reproducible evaluation of continual learning algorithms.
RMS-Net: Regression and Masking for Soccer Event Spotting
Feb 15, 2021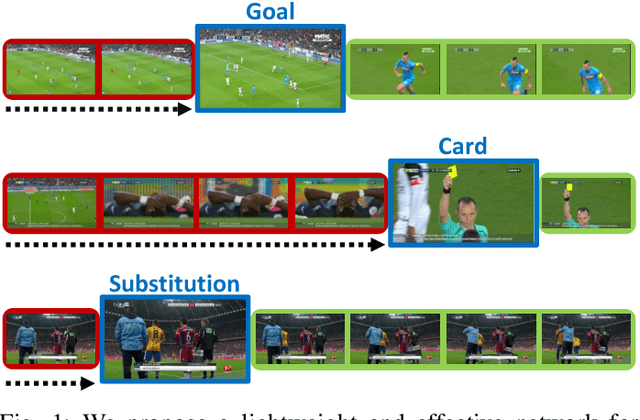
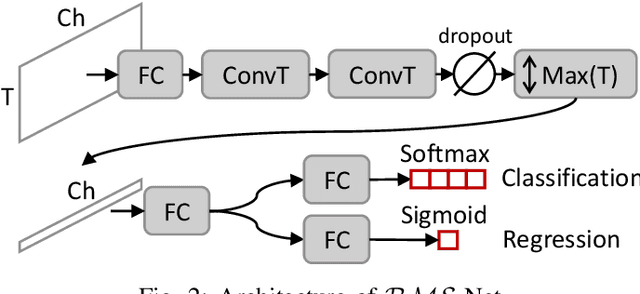
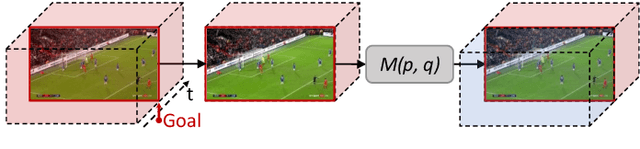
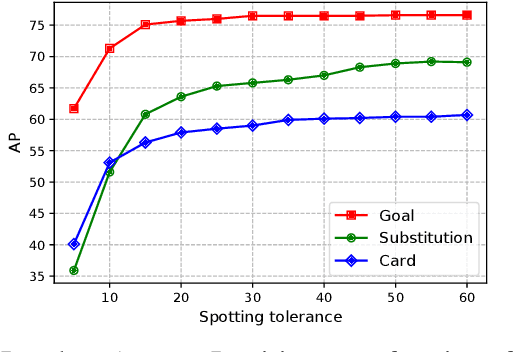
The recently proposed action spotting task consists in finding the exact timestamp in which an event occurs. This task fits particularly well for soccer videos, where events correspond to salient actions strictly defined by soccer rules (a goal occurs when the ball crosses the goal line). In this paper, we devise a lightweight and modular network for action spotting, which can simultaneously predict the event label and its temporal offset using the same underlying features. We enrich our model with two training strategies: the first one for data balancing and uniform sampling, the second for masking ambiguous frames and keeping the most discriminative visual cues. When tested on the SoccerNet dataset and using standard features, our full proposal exceeds the current state of the art by 3 Average-mAP points. Additionally, it reaches a gain of more than 10 Average-mAP points on the test set when fine-tuned in combination with a strong 2D backbone.
Generalising via Meta-Examples for Continual Learning in the Wild
Jan 28, 2021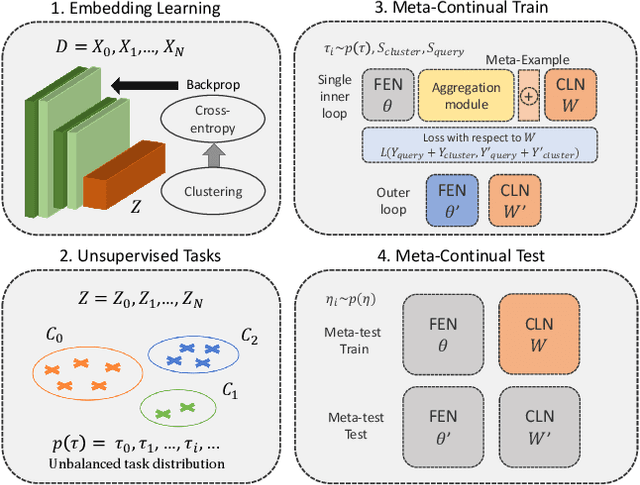
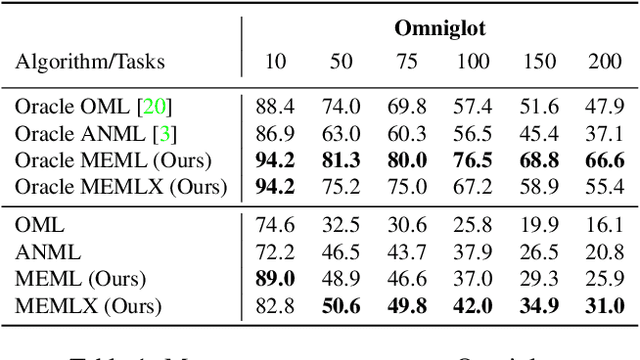
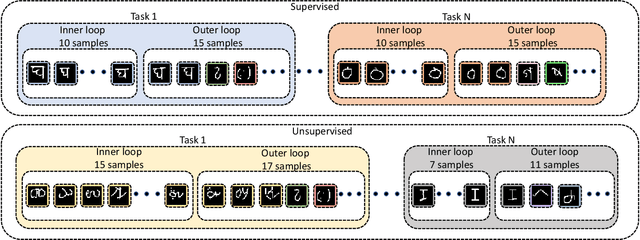
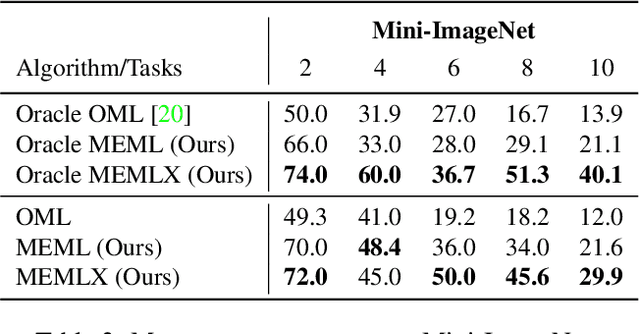
Learning quickly and continually is still an ambitious task for neural networks. Indeed, many real-world applications do not reflect the learning setting where neural networks shine, as data are usually few, mostly unlabelled and come as a stream. To narrow this gap, we introduce FUSION - Few-shot UnSupervIsed cONtinual learning - a novel strategy which aims to deal with neural networks that "learn in the wild", simulating a real distribution and flow of unbalanced tasks. We equip FUSION with MEML - Meta-Example Meta-Learning - a new module that simultaneously alleviates catastrophic forgetting and favours the generalisation and future learning of new tasks. To encourage features reuse during the meta-optimisation, our model exploits a single inner loop per task, taking advantage of an aggregated representation achieved through the use of a self-attention mechanism. To further enhance the generalisation capability of MEML, we extend it by adopting a technique that creates various augmented tasks and optimises over the hardest. Experimental results on few-shot learning benchmarks show that our model exceeds the other baselines in both FUSION and fully supervised case. We also explore how it behaves in standard continual learning consistently outperforming state-of-the-art approaches.
Rethinking Experience Replay: a Bag of Tricks for Continual Learning
Oct 12, 2020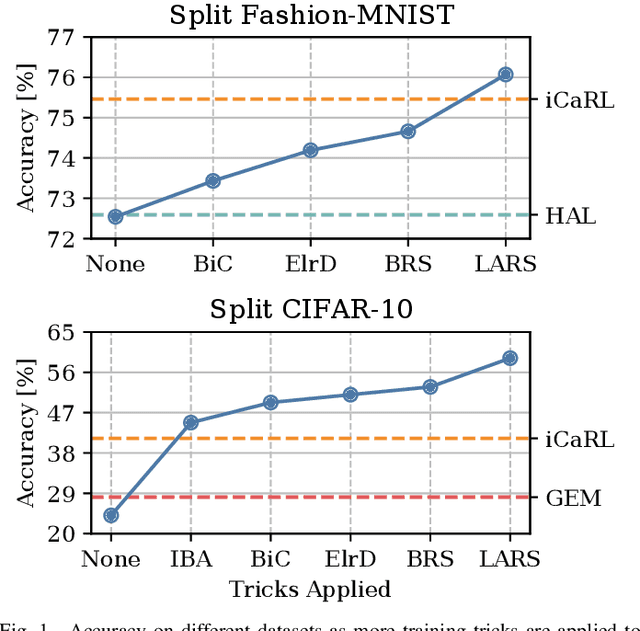
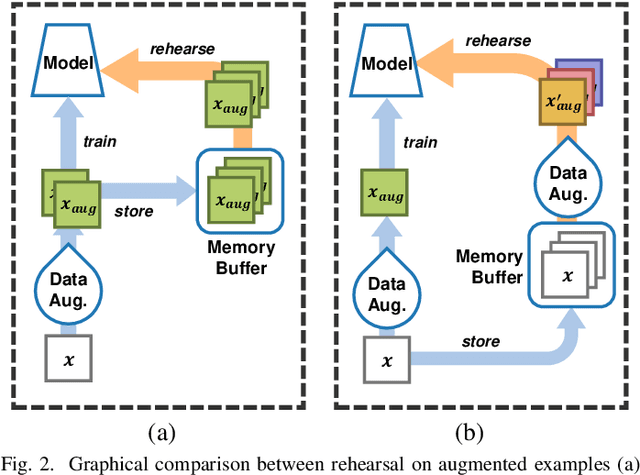

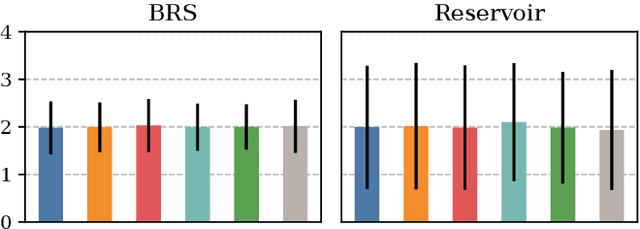
In Continual Learning, a Neural Network is trained on a stream of data whose distribution shifts over time. Under these assumptions, it is especially challenging to improve on classes appearing later in the stream while remaining accurate on previous ones. This is due to the infamous problem of catastrophic forgetting, which causes a quick performance degradation when the classifier focuses on learning new categories. Recent literature proposed various approaches to tackle this issue, often resorting to very sophisticated techniques. In this work, we show that naive rehearsal can be patched to achieve similar performance. We point out some shortcomings that restrain Experience Replay (ER) and propose five tricks to mitigate them. Experiments show that ER, thus enhanced, displays an accuracy gain of 51.2 and 26.9 percentage points on the CIFAR-10 and CIFAR-100 datasets respectively (memory buffer size 1000). As a result, it surpasses current state-of-the-art rehearsal-based methods.
Few-Shot Unsupervised Continual Learning through Meta-Examples
Sep 17, 2020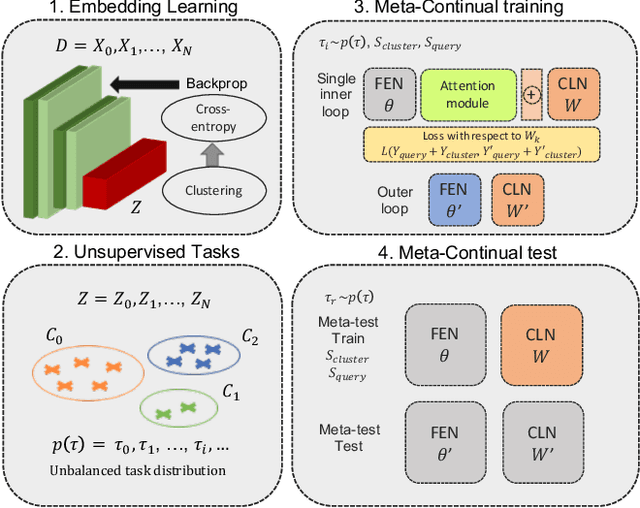
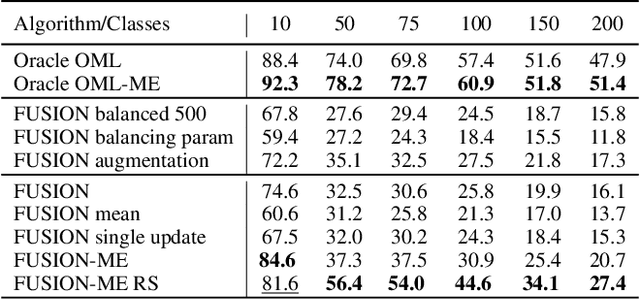
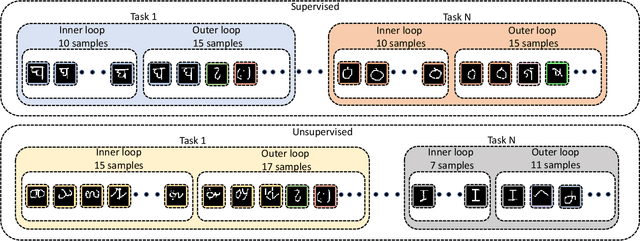
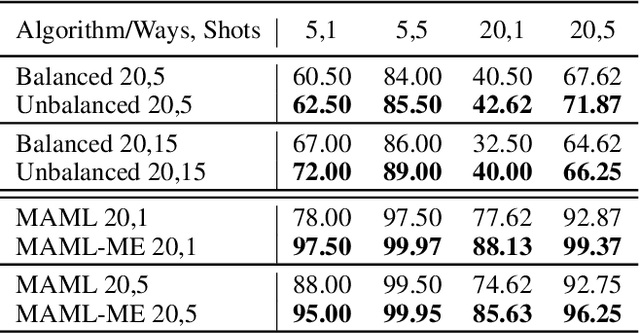
In real-world applications, data do not reflect the ones commonly used for neural networks training, since they are usually few, unbalanced, unlabeled and can be available as a stream. Hence many existing deep learning solutions suffer from a limited range of applications, in particular in the case of online streaming data that evolve over time. To narrow this gap, in this work we introduce a novel and complex setting involving unsupervised meta-continual learning with unbalanced tasks. These tasks are built through a clustering procedure applied to a fitted embedding space. We exploit a meta-learning scheme that simultaneously alleviates catastrophic forgetting and favors the generalization to new tasks, even Out-of-Distribution ones. Moreover, to encourage feature reuse during the meta-optimization, we exploit a single inner loop taking advantage of an aggregated representation achieved through the use of a self-attention mechanism. Experimental results on few-shot learning benchmarks show competitive performance even compared to the supervised case. Additionally, we empirically observe that in an unsupervised scenario, the small tasks and the variability in the clusters pooling play a crucial role in the generalization capability of the network. Further, on complex datasets, the exploitation of more clusters than the true number of classes leads to higher results, even compared to the ones obtained with full supervision, suggesting that a predefined partitioning into classes can miss relevant structural information.
Inter-Homines: Distance-Based Risk Estimation for Human Safety
Jul 20, 2020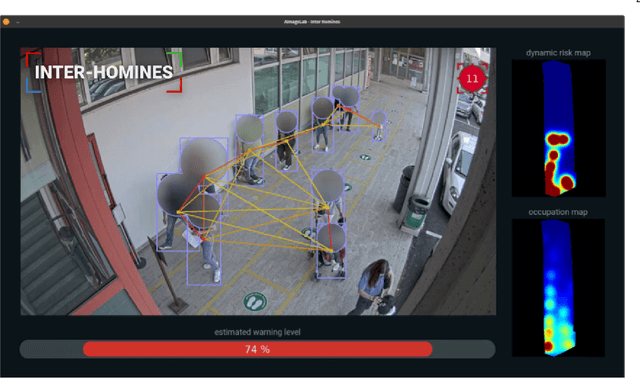
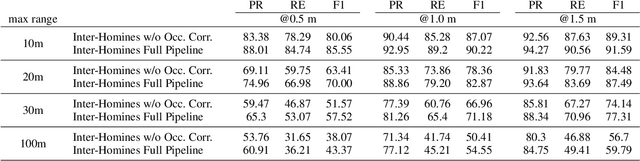
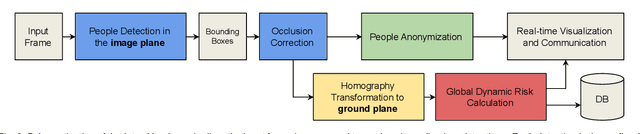

In this document, we report our proposal for modeling the risk of possible contagiousity in a given area monitored by RGB cameras where people freely move and interact. Our system, called Inter-Homines, evaluates in real-time the contagion risk in a monitored area by analyzing video streams: it is able to locate people in 3D space, calculate interpersonal distances and predict risk levels by building dynamic maps of the monitored area. Inter-Homines works both indoor and outdoor, in public and private crowded areas. The software is applicable to already installed cameras or low-cost cameras on industrial PCs, equipped with an additional embedded edge-AI system for temporary measurements. From the AI-side, we exploit a robust pipeline for real-time people detection and localization in the ground plane by homographic transformation based on state-of-the-art computer vision algorithms; it is a combination of a people detector and a pose estimator. From the risk modeling side, we propose a parametric model for a spatio-temporal dynamic risk estimation, that, validated by epidemiologists, could be useful for safety monitoring the acceptance of social distancing prevention measures by predicting the risk level of the scene.