 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Inlet Rank Collapse in Implicit Neural Representations: Diagnosis and Unified Remedy
Feb 02, 2026Implicit Neural Representations (INRs) have revolutionized continuous signal modeling, yet they struggle to recover fine-grained details within finite training budgets. While empirical techniques, such as positional encoding (PE), sinusoidal activations (SIREN), and batch normalization (BN), effectively mitigate this, their theoretical justifications are predominantly post hoc, focusing on the global NTK spectrum only after modifications are applied. In this work, we reverse this paradigm by introducing a structural diagnostic framework. By performing a layer-wise decomposition of the NTK, we mathematically identify the ``Inlet Rank Collapse'': a phenomenon where the low-dimensional input coordinates fail to span the high-dimensional embedding space, creating a fundamental rank deficiency at the first layer that acts as an expressive bottleneck for the entire network. This framework provides a unified perspective to re-interpret PE, SIREN, and BN as different forms of rank restoration. Guided by this diagnosis, we derive a Rank-Expanding Initialization, a minimalist remedy that ensures the representation rank scales with the layer width without architectural modifications or computational overhead. Our results demonstrate that this principled remedy enables standard MLPs to achieve high-fidelity reconstructions, proving that the key to empowering INRs lies in the structural optimization of the initial rank propagation to effectively populate the latent space.
G3Splat: Geometrically Consistent Generalizable Gaussian Splatting
Dec 19, 20253D Gaussians have recently emerged as an effective scene representation for real-time splatting and accurate novel-view synthesis, motivating several works to adapt multi-view structure prediction networks to regress per-pixel 3D Gaussians from images. However, most prior work extends these networks to predict additional Gaussian parameters -- orientation, scale, opacity, and appearance -- while relying almost exclusively on view-synthesis supervision. We show that a view-synthesis loss alone is insufficient to recover geometrically meaningful splats in this setting. We analyze and address the ambiguities of learning 3D Gaussian splats under self-supervision for pose-free generalizable splatting, and introduce G3Splat, which enforces geometric priors to obtain geometrically consistent 3D scene representations. Trained on RE10K, our approach achieves state-of-the-art performance in (i) geometrically consistent reconstruction, (ii) relative pose estimation, and (iii) novel-view synthesis. We further demonstrate strong zero-shot generalization on ScanNet, substantially outperforming prior work in both geometry recovery and relative pose estimation. Code and pretrained models are released on our project page (https://m80hz.github.io/g3splat/).
3D Gaussian Point Encoders
Nov 06, 2025



In this work, we introduce the 3D Gaussian Point Encoder, an explicit per-point embedding built on mixtures of learned 3D Gaussians. This explicit geometric representation for 3D recognition tasks is a departure from widely used implicit representations such as PointNet. However, it is difficult to learn 3D Gaussian encoders in end-to-end fashion with standard optimizers. We develop optimization techniques based on natural gradients and distillation from PointNets to find a Gaussian Basis that can reconstruct PointNet activations. The resulting 3D Gaussian Point Encoders are faster and more parameter efficient than traditional PointNets. As in the 3D reconstruction literature where there has been considerable interest in the move from implicit (e.g., NeRF) to explicit (e.g., Gaussian Splatting) representations, we can take advantage of computational geometry heuristics to accelerate 3D Gaussian Point Encoders further. We extend filtering techniques from 3D Gaussian Splatting to construct encoders that run 2.7 times faster as a comparable accuracy PointNet while using 46% less memory and 88% fewer FLOPs. Furthermore, we demonstrate the effectiveness of 3D Gaussian Point Encoders as a component in Mamba3D, running 1.27 times faster and achieving a reduction in memory and FLOPs by 42% and 54% respectively. 3D Gaussian Point Encoders are lightweight enough to achieve high framerates on CPU-only devices.
Compressing Sine-Activated Low-Rank Adapters through Post-Training Quantization
May 28, 2025



Low-Rank Adaptation (LoRA) has become a standard approach for parameter-efficient fine-tuning, offering substantial reductions in trainable parameters by modeling updates as the product of two low-rank matrices. While effective, the low-rank constraint inherently limits representational capacity, often resulting in reduced performance compared to full-rank fine-tuning. Recent work by Ji et al. (2025) has addressed this limitation by applying a fixed-frequency sinusoidal transformation to low-rank adapters, increasing their stable rank without introducing additional parameters. This raises a crucial question: can the same sine-activated technique be successfully applied within the context of Post-Training Quantization to retain benefits even after model compression? In this paper, we investigate this question by extending the sinusoidal transformation framework to quantized LoRA adapters. We develop a theoretical analysis showing that the stable rank of a quantized adapter is tightly linked to that of its full-precision counterpart, motivating the use of such rank-enhancing functions even under quantization. Our results demonstrate that the expressivity gains from a sinusoidal non-linearity persist after quantization, yielding highly compressed adapters with negligible loss in performance. We validate our approach across a range of fine-tuning tasks for language, vision and text-to-image generation achieving significant memory savings while maintaining competitive accuracy.
Leaner Transformers: More Heads, Less Depth
May 27, 2025Transformers have reshaped machine learning by utilizing attention mechanisms to capture complex patterns in large datasets, leading to significant improvements in performance. This success has contributed to the belief that "bigger means better", leading to ever-increasing model sizes. This paper challenge this ideology by showing that many existing transformers might be unnecessarily oversized. We discover a theoretical principle that redefines the role of multi-head attention. An important benefit of the multiple heads is in improving the conditioning of the attention block. We exploit this theoretical insight and redesign popular architectures with an increased number of heads. The improvement in the conditioning proves so significant in practice that model depth can be decreased, reducing the parameter count by up to 30-50% while maintaining accuracy. We obtain consistent benefits across a variety of transformer-based architectures of various scales, on tasks in computer vision (ImageNet-1k) as well as language and sequence modeling (GLUE benchmark, TinyStories, and the Long-Range Arena benchmark).
Structured Initialization for Vision Transformers
May 26, 2025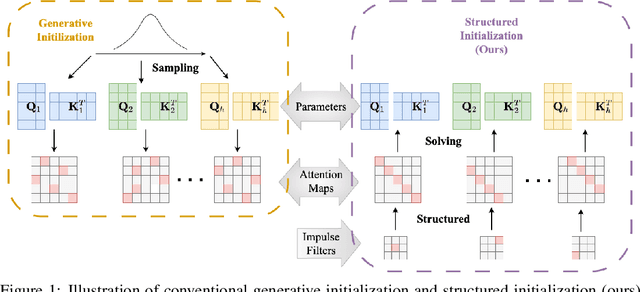

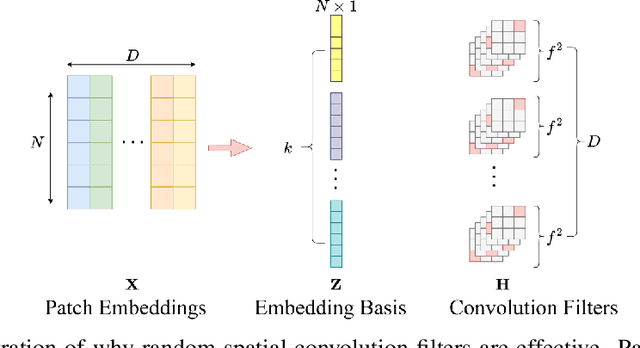

Convolutional Neural Networks (CNNs) inherently encode strong inductive biases, enabling effective generalization on small-scale datasets. In this paper, we propose integrating this inductive bias into ViTs, not through an architectural intervention but solely through initialization. The motivation here is to have a ViT that can enjoy strong CNN-like performance when data assets are small, but can still scale to ViT-like performance as the data expands. Our approach is motivated by our empirical results that random impulse filters can achieve commensurate performance to learned filters within a CNN. We improve upon current ViT initialization strategies, which typically rely on empirical heuristics such as using attention weights from pretrained models or focusing on the distribution of attention weights without enforcing structures. Empirical results demonstrate that our method significantly outperforms standard ViT initialization across numerous small and medium-scale benchmarks, including Food-101, CIFAR-10, CIFAR-100, STL-10, Flowers, and Pets, while maintaining comparative performance on large-scale datasets such as ImageNet-1K. Moreover, our initialization strategy can be easily integrated into various transformer-based architectures such as Swin Transformer and MLP-Mixer with consistent improvements in performance.
Enhancing Transformers Through Conditioned Embedded Tokens
May 19, 2025Transformers have transformed modern machine learning, driving breakthroughs in computer vision, natural language processing, and robotics. At the core of their success lies the attention mechanism, which enables the modeling of global dependencies among input tokens. However, we reveal that the attention block in transformers suffers from inherent ill-conditioning, which hampers gradient-based optimization and leads to inefficient training. To address this, we develop a theoretical framework that establishes a direct relationship between the conditioning of the attention block and that of the embedded tokenized data. Building on this insight, we introduce conditioned embedded tokens, a method that systematically modifies the embedded tokens to improve the conditioning of the attention mechanism. Our analysis demonstrates that this approach significantly mitigates ill-conditioning, leading to more stable and efficient training. We validate our methodology across various transformer architectures, achieving consistent improvements in image classification, object detection, instance segmentation, and natural language processing, highlighting its broad applicability and effectiveness.
Always Skip Attention
May 04, 2025We highlight a curious empirical result within modern Vision Transformers (ViTs). Specifically, self-attention catastrophically fails to train unless it is used in conjunction with a skip connection. This is in contrast to other elements of a ViT that continue to exhibit good performance (albeit suboptimal) when skip connections are removed. Further, we show that this critical dependence on skip connections is a relatively new phenomenon, with previous deep architectures (\eg, CNNs) exhibiting good performance in their absence. In this paper, we theoretically characterize that the self-attention mechanism is fundamentally ill-conditioned and is, therefore, uniquely dependent on skip connections for regularization. Additionally, we propose Token Graying -- a simple yet effective complement (to skip connections) that further improves the condition of input tokens. We validate our approach in both supervised and self-supervised training methods.
Gradient Descent as a Shrinkage Operator for Spectral Bias
Apr 25, 2025We generalize the connection between activation function and spline regression/smoothing and characterize how this choice may influence spectral bias within a 1D shallow network. We then demonstrate how gradient descent (GD) can be reinterpreted as a shrinkage operator that masks the singular values of a neural network's Jacobian. Viewed this way, GD implicitly selects the number of frequency components to retain, thereby controlling the spectral bias. An explicit relationship is proposed between the choice of GD hyperparameters (learning rate & number of iterations) and bandwidth (the number of active components). GD regularization is shown to be effective only with monotonic activation functions. Finally, we highlight the utility of non-monotonic activation functions (sinc, Gaussian) as iteration-efficient surrogates for spectral bias.
Rethinking the Role of Spatial Mixing
Mar 21, 2025Until quite recently, the backbone of nearly every state-of-the-art computer vision model has been the 2D convolution. At its core, a 2D convolution simultaneously mixes information across both the spatial and channel dimensions of a representation. Many recent computer vision architectures consist of sequences of isotropic blocks that disentangle the spatial and channel-mixing components. This separation of the operations allows us to more closely juxtapose the effects of spatial and channel mixing in deep learning. In this paper, we take an initial step towards garnering a deeper understanding of the roles of these mixing operations. Through our experiments and analysis, we discover that on both classical (ResNet) and cutting-edge (ConvMixer) models, we can reach nearly the same level of classification performance by and leaving the spatial mixers at their random initializations. Furthermore, we show that models with random, fixed spatial mixing are naturally more robust to adversarial perturbations. Lastly, we show that this phenomenon extends past the classification regime, as such models can also decode pixel-shuffled images.