 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closer Look at the Optimization Landscapes of Generative Adversarial Networks
Jun 11, 2019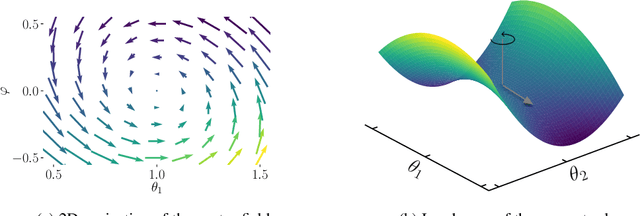
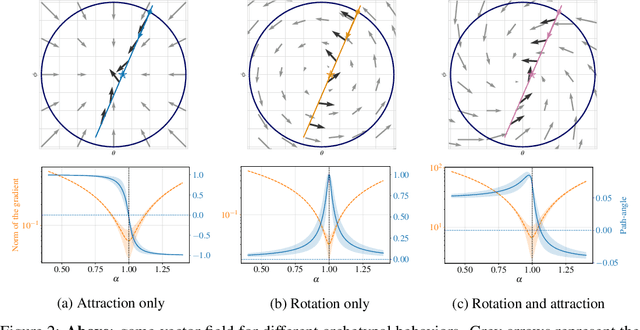
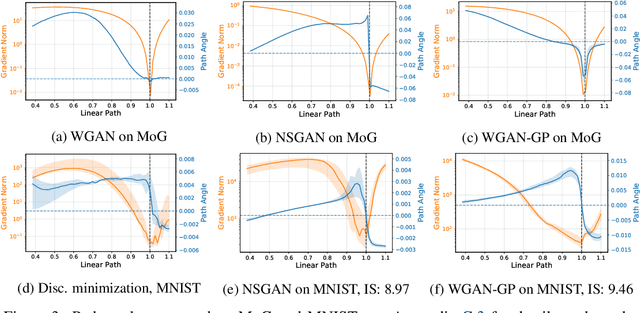
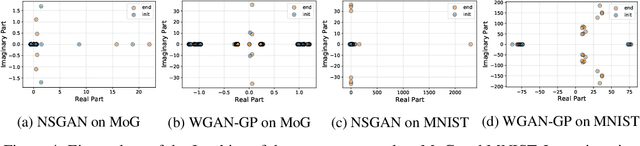
Generative adversarial networks have been very successful in generative modeling, however they remain relatively hard to optimize compared to standard deep neural networks. In this paper, we try to gain insight into the optimization of GANs by looking at the game vector field resulting from the concatenation of the gradient of both players. Based on this point of view, we propose visualization techniques that allow us to make the following empirical observations. First, the training of GANs suffers from rotational behavior around locally stable stationary points, which, as we show, corresponds to the presence of imaginary components in the eigenvalues of the Jacobian of the game. Secondly, GAN training seems to converge to a stable stationary point which is a saddle point for the generator loss, not a minimum, while still achieving excellent performance. This counter-intuitive yet persistent observation questions whether we actually need a Nash equilibrium to get good performance in GANs.
Gradient-Based Neural DAG Learning
Jun 05, 2019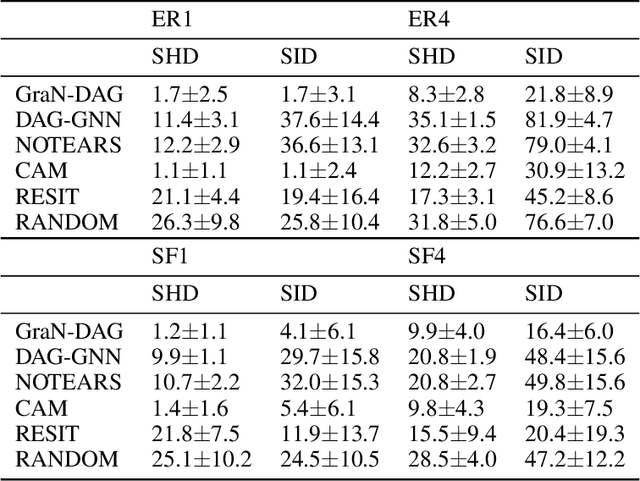
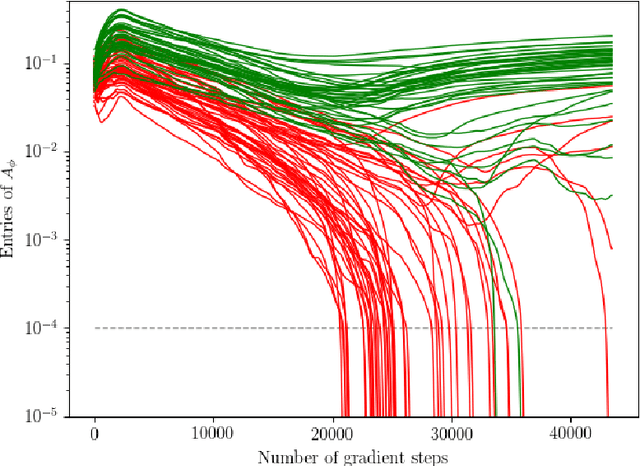
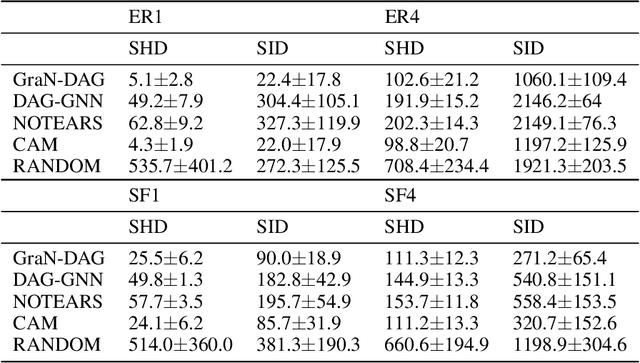
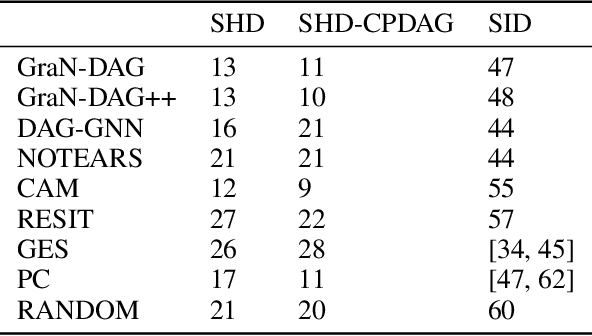
We propose a novel score-based approach to learning a directed acyclic graph (DAG) from observational data. We adapt a recently proposed continuous constrained optimization formulation to allow for nonlinear relationships between variables using neural networks. This extension allows to model complex interactions while being more global in its search compared to other greedy approaches. In addition to comparing our method to existing continuous optimization methods, we provide missing empirical comparisons to nonlinear greedy search methods. On both synthetic and real-world data sets, this new method outperforms current continuous methods on most tasks while being competitive with existing greedy search methods on important metrics for causal inference.
Painless Stochastic Gradient: Interpolation, Line-Search, and Convergence Rates
May 24, 2019

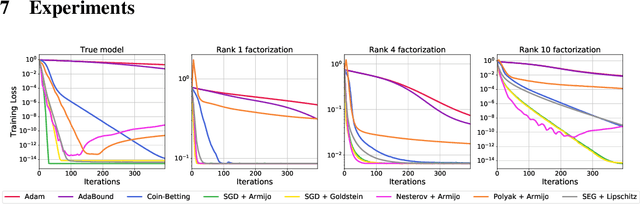
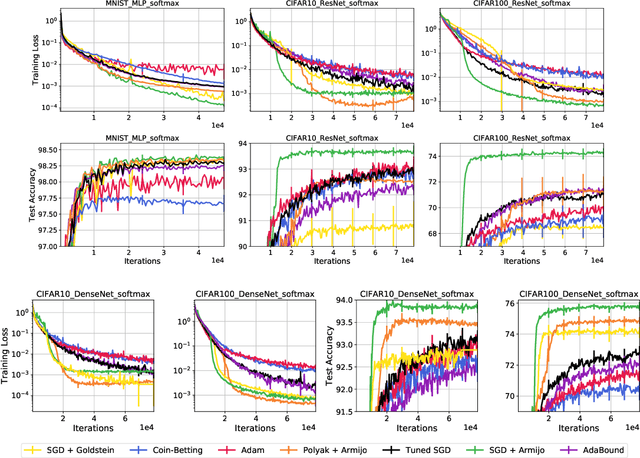
Recent works have shown that stochastic gradient descent (SGD) achieves the fast convergence rates of full-batch gradient descent for over-parameterized models satisfying certain interpolation conditions. However, the step-size used in these works depends on unknown quantities, and SGD's practical performance heavily relies on the choice of the step-size. We propose to use line-search methods to automatically set the step-size when training models that can interpolate the data. We prove that SGD with the classic Armijo line-search attains the fast convergence rates of full-batch gradient descent in convex and strongly-convex settings. We also show that under additional assumptions, SGD with a modified line-search can attain a fast rate of convergence for non-convex functions. Furthermore, we show that a stochastic extra-gradient method with a Lipschitz line-search attains a fast convergence rate for an important class of non-convex functions and saddle-point problems satisfying interpolation. We then give heuristics to use larger step-sizes and acceleration with our line-search techniques. We compare the proposed algorithms against numerous optimization methods for standard classification tasks using both kernel methods and deep networks. The proposed methods are robust and result in competitive performance across all models and datasets. Moreover, for the deep network models, SGD with our line-search results in both faster convergence and better generalization.
Implicit Regularization of Discrete Gradient Dynamics in Deep Linear Neural Networks
Apr 30, 2019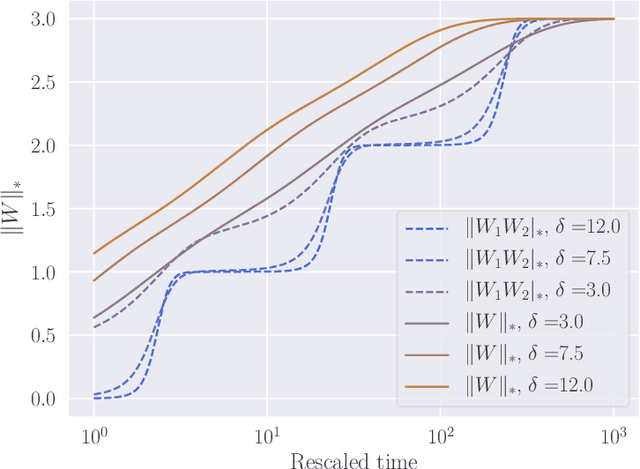

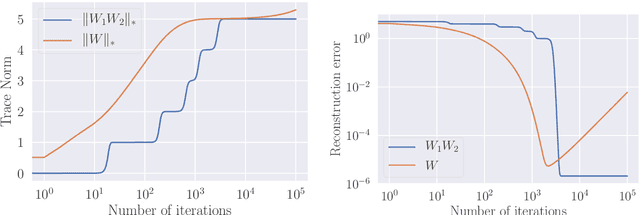
When optimizing over-parameterized models, such as deep neural networks, a large set of parameters can achieve zero training error. In such cases, the choice of the optimization algorithm and its respective hyper-parameters introduces biases that will lead to convergence to specific minimizers of the objective. Consequently, this choice can be considered as an implicit regularization for the training of over-parametrized models. In this work, we push this idea further by studying the discrete gradient dynamics of the training of a two-layer linear network with the least-square loss. Using a time rescaling, we show that, with a vanishing initialization and a small enough step size, this dynamics sequentially learns components that are the solutions of a reduced-rank regression with a gradually increasing rank.
Reducing Noise in GAN Training with Variance Reduced Extragradient
Apr 18, 2019
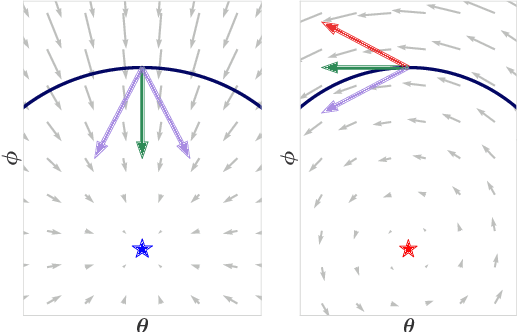
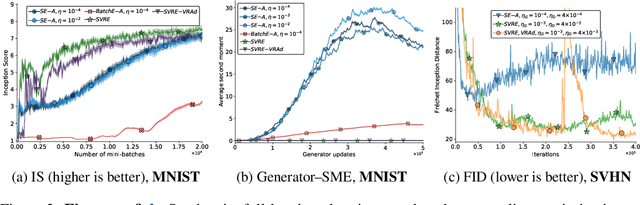

Using large mini-batches when training generative adversarial networks (GANs) has been recently shown to significantly improve the quality of the generated samples. This can be seen as a simple but computationally expensive way of reducing the noise of the gradient estimates. In this paper, we investigate the effect of the noise in this context and show that it can prevent the convergence of standard stochastic game optimization methods, while their respective batch version converges. To address this issue, we propose a variance-reduced version of the stochastic extragradient algorithm (SVRE). We show experimentally that it performs similarly to a batch method, while being computationally cheaper, and show its theoretical convergence, improving upon the best rates proposed in the literature. Experiments on several datasets show that SVRE improves over baselines. Notably, SVRE is the first optimization method for GANs to our knowledge that can produce near state-of-the-art results without using adaptive step-size such as Adam.
Centroid Networks for Few-Shot Clustering and Unsupervised Few-Shot Classification
Feb 22, 2019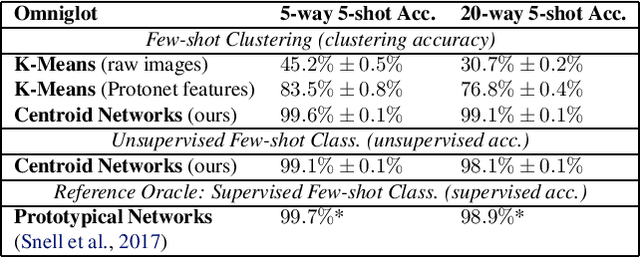
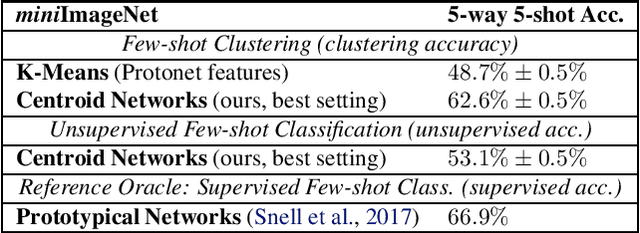
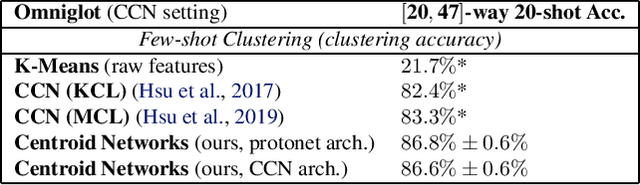
Traditional clustering algorithms such as K-means rely heavily on the nature of the chosen metric or data representation. To get meaningful clusters, these representations need to be tailored to the downstream task (e.g. cluster photos by object category, cluster faces by identity). Therefore, we frame clustering as a meta-learning task, few-shot clustering, which allows us to specify how to cluster the data at the meta-training level, despite the clustering algorithm itself being unsupervised. We propose Centroid Networks, a simple and efficient few-shot clustering method based on learning representations which are tailored both to the task to solve and to its internal clustering module. We also introduce unsupervised few-shot classification, which is conceptually similar to few-shot clustering, but is strictly harder than supervised* few-shot classification and therefore allows direct comparison with existing supervised few-shot classification methods. On Omniglot and miniImageNet, our method achieves accuracy competitive with popular supervised few-shot classification algorithms, despite using *no labels* from the support set. We also show performance competitive with state-of-the-art learning-to-cluster methods.
Predicting Tactical Solutions to Operational Planning Problems under Imperfect Information
Jan 22, 2019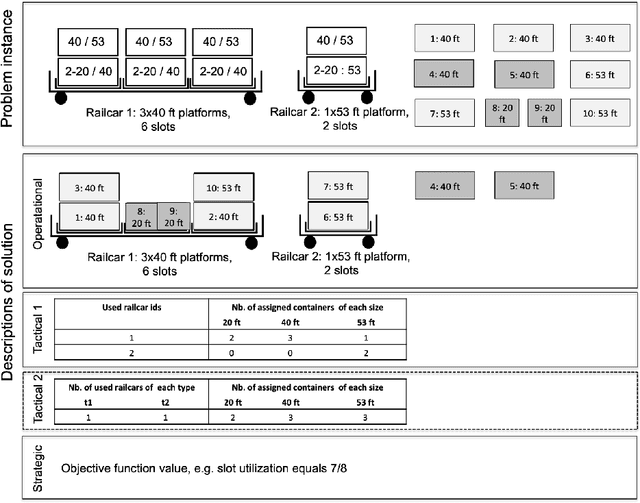

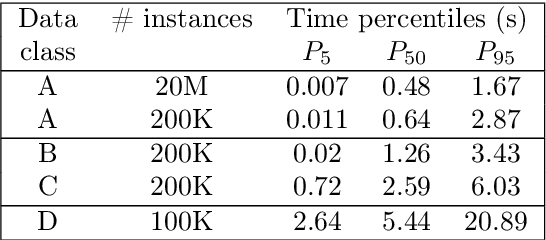

This paper offers a methodological contribution at the intersection of machine learning and operations research. Namely, we propose a methodology to quickly predict tactical solutions to a given operational problem. In this context, the tactical solution is less detailed than the operational one but it has to be computed in very short time and under imperfect information. The problem is of importance in various applications where tactical and operational planning problems are interrelated and information about the operational problem is revealed over time. This is for instance the case in certain capacity planning and demand management systems. We formulate the problem as a two-stage optimal prediction stochastic program whose solution we predict with a supervised machine learning algorithm. The training data set consists of a large number of deterministic (second stage) problems generated by controlled probabilistic sampling. The labels are computed based on solutions to the deterministic problems (solved independently and offline) employing appropriate aggregation and subselection methods to address uncertainty. Results on our motivating application in load planning for rail transportation show that deep learning algorithms produce highly accurate predictions in very short computing time (milliseconds or less). The prediction accuracy is comparable to solutions computed by sample average approximation of the stochastic program.
A Variational Inequality Perspective on Generative Adversarial Networks
Nov 02, 2018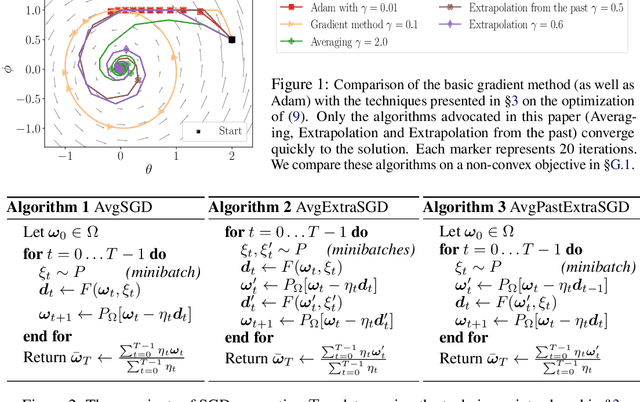
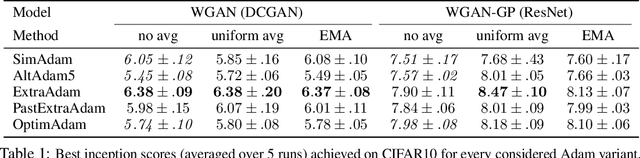
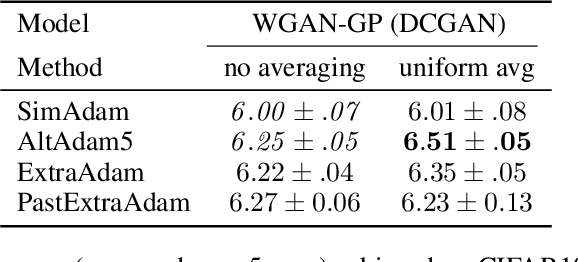
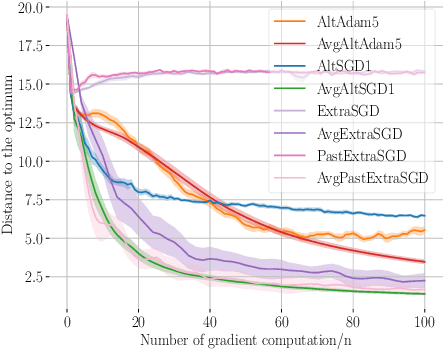
Generative adversarial networks (GANs) form a generative modeling approach known for producing appealing samples, but they are notably difficult to train. One common way to tackle this issue has been to propose new formulations of the GAN objective. Yet, surprisingly few studies have looked at optimization methods designed for this adversarial training. In this work, we cast GAN optimization problems in the general variational inequality framework. Tapping into the mathematical programming literature, we counter some common misconceptions about the difficulties of saddle point optimization and propose to extend techniques designed for variational inequalities to the training of GANs. We apply averaging, extrapolation and a novel computationally cheaper variant that we call extrapolation from the past to the stochastic gradient method (SGD) and Adam.
Quantifying Learning Guarantees for Convex but Inconsistent Surrogates
Oct 26, 2018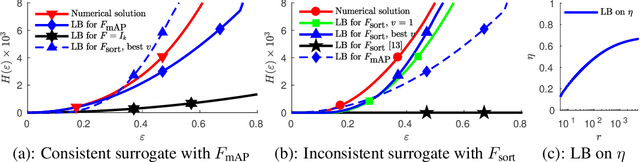
We study consistency properties of machine learning methods based on minimizing convex surrogates. We extend the recent framework of Osokin et al. (2017) for the quantitative analysis of consistency properties to the case of inconsistent surrogates. Our key technical contribution consists in a new lower bound on the calibration function for the quadratic surrogate, which is non-trivial (not always zero) for inconsistent cases. The new bound allows to quantify the level of inconsistency of the setting and shows how learning with inconsistent surrogates can have guarantees on sample complexity and optimization difficulty. We apply our theory to two concrete cases: multi-class classification with the tree-structured loss and ranking with the mean average precision loss. The results show the approximation-computation trade-offs caused by inconsistent surrogates and their potential benefits.
A Modern Take on the Bias-Variance Tradeoff in Neural Networks
Oct 19, 2018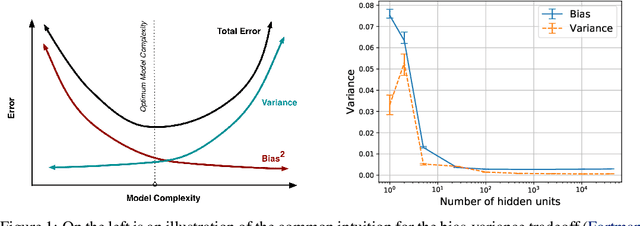
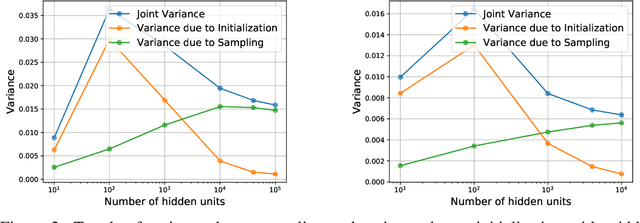
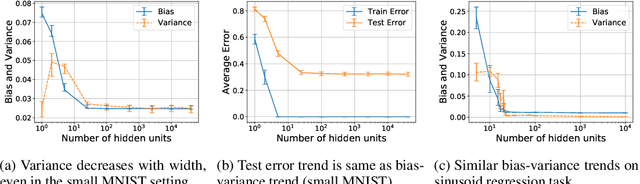
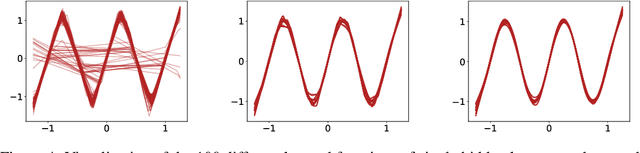
We revisit the bias-variance tradeoff for neural networks in light of modern empirical findings. The traditional bias-variance tradeoff in machine learning suggests that as model complexity grows, variance increases. Classical bounds in statistical learning theory point to the number of parameters in a model as a measure of model complexity, which means the tradeoff would indicate that variance increases with the size of neural networks. However, we empirically find that variance due to training set sampling is roughly \textit{constant} (with both width and depth) in practice. Variance caused by the non-convexity of the loss landscape is different. We find that it decreases with width and increases with depth, in our setting. We provide theoretical analysis, in a simplified setting inspired by linear models, that is consistent with our empirical findings for width. We view bias-variance as a useful lens to study generalization through and encourage further theoretical explanation from this perspective.