 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Causal Discovery from Interventional Data
Jul 03, 2020

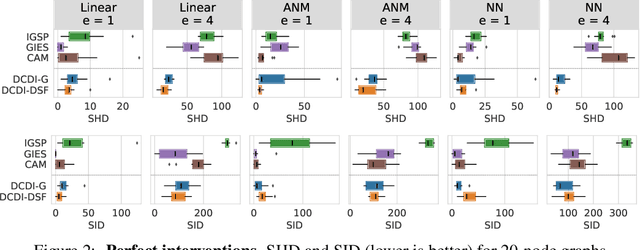

Discovering causal relationships in data is a challenging task that involves solving a combinatorial problem for which the solution is not always identifiable. A new line of work reformulates the combinatorial problem as a continuous constrained optimization one, enabling the use of different powerful optimization techniques. However, methods based on this idea do not yet make use of interventional data, which can significantly alleviate identifiability issues. In this work, we propose a neural network-based method for this task that can leverage interventional data. We illustrate the flexibility of the continuous-constrained framework by taking advantage of expressive neural architectures such as normalizing flows. We show that our approach compares favorably to the state of the art in a variety of settings, including perfect and imperfect interventions for which the targeted nodes may even be unknown.
Adversarial Example Games
Jul 01, 2020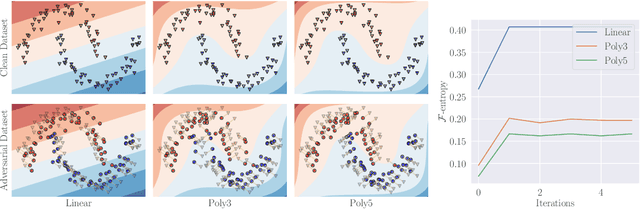

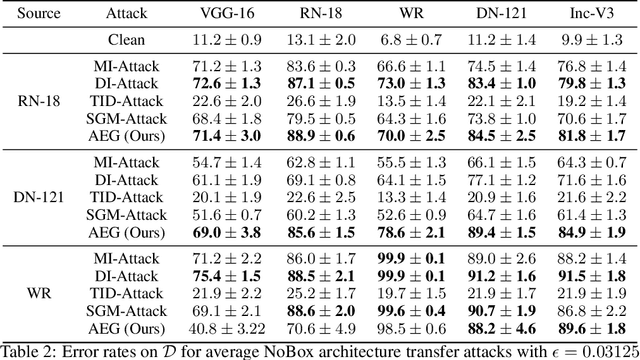

The existence of adversarial examples capable of fooling trained neural network classifiers calls for a much better understanding of possible attacks, in order to guide the development of safeguards against them. It includes attack methods in the highly challenging non-interactive blackbox setting, where adversarial attacks are generated without any access, including queries, to the target model. Prior works in this setting have relied mainly on algorithmic innovations derived from empirical observations (e.g., that momentum helps), and the field currently lacks a firm theoretical basis for understanding transferability in adversarial attacks. In this work, we address this gap and lay the theoretical foundations for crafting transferable adversarial examples to entire function classes. We introduce Adversarial Examples Games (AEG), a novel framework that models adversarial examples as two-player min-max games between an attack generator and a representative classifier. We prove that the saddle point of an AEG game corresponds to a generating distribution of adversarial examples against entire function classes. Training the generator only requires the ability to optimize a representative classifier from a given hypothesis class, enabling BlackBox transfer to unseen classifiers from the same class. We demonstrate the efficacy of our approach on the MNIST and CIFAR-10 datasets against both undefended and robustified models, achieving competitive performance with state-of-the-art BlackBox transfer approaches.
Adaptive Gradient Methods Converge Faster with Over-Parameterization (and you can do a line-search)
Jun 11, 2020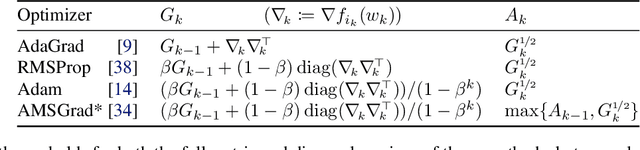
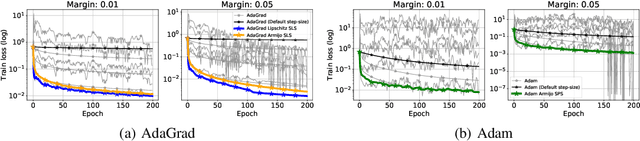

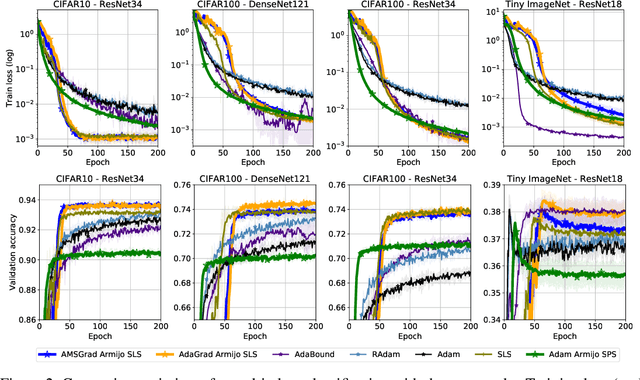
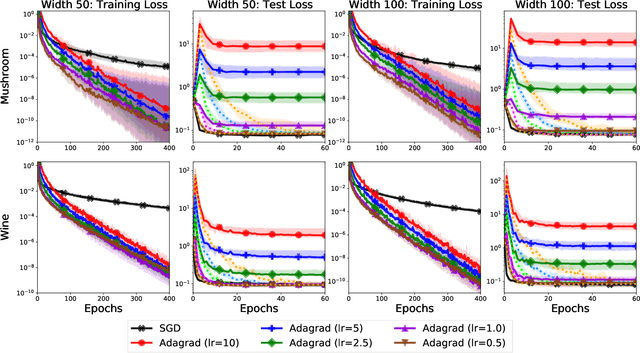
As adaptive gradient methods are typically used for training over-parameterized models capable of exactly fitting the data, we study their convergence in this interpolation setting. Under this assumption, we prove that constant step-size, zero-momentum variants of Adam and AMSGrad can converge to the minimizer at the O(1/T) rate for smooth, convex functions. When this assumption is only approximately satisfied, we show that these methods converge to a neighbourhood of the solution. On the other hand, we show that Adagrad is robust to the violation of interpolation and converges to the minimizer at the optimal rate. However, we demonstrate that even for simple, convex problems satisfying interpolation, the empirical performance of these methods heavily depends on the step-size and requires tuning. We alleviate this problem by making use of stochastic line-search methods (SLS) and Polyak's step-sizes (SPS) to help these methods adapt to the function's local smoothness. We prove that adaptive methods used in conjunction with these techniques do not require knowledge of problem-dependent constants and retain the convergence guarantees of their constant step-size counterparts. Experimentally, we show that using SLS or SPS consistently improves the convergence of adaptive methods across tasks; from binary classification with kernel mappings to classification with deep neural networks. Furthermore, our empirical results show that Adagrad equipped with SLS generalizes better than SGD.
To Each Optimizer a Norm, To Each Norm its Generalization
Jun 11, 2020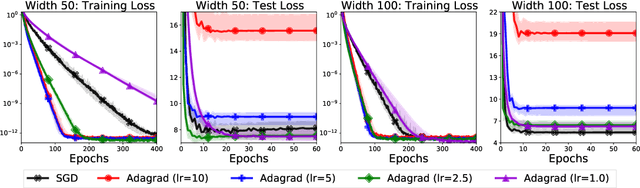
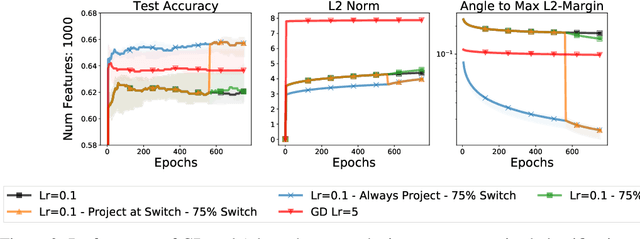
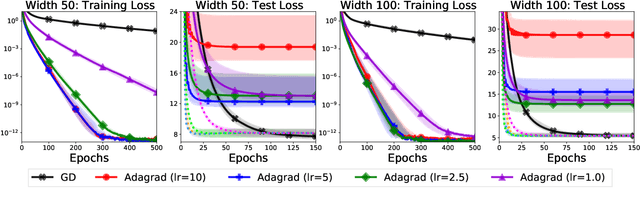
We study the implicit regularization of optimization methods for linear models interpolating the training data in the under-parametrized and over-parametrized regimes. Since it is difficult to determine whether an optimizer converges to solutions that minimize a known norm, we flip the problem and investigate what is the corresponding norm minimized by an interpolating solution. Using this reasoning, we prove that for over-parameterized linear regression, projections onto linear spans can be used to move between different interpolating solutions. For under-parameterized linear classification, we prove that for any linear classifier separating the data, there exists a family of quadratic norms ||.||_P such that the classifier's direction is the same as that of the maximum P-margin solution. For linear classification, we argue that analyzing convergence to the standard maximum l2-margin is arbitrary and show that minimizing the norm induced by the data results in better generalization. Furthermore, for over-parameterized linear classification, projections onto the data-span enable us to use techniques from the under-parameterized setting. On the empirical side, we propose techniques to bias optimizers towards better generalizing solutions, improving their test performance. We validate our theoretical results via synthetic experiments, and use the neural tangent kernel to handle non-linear models.
An Analysis of the Adaptation Speed of Causal Models
May 18, 2020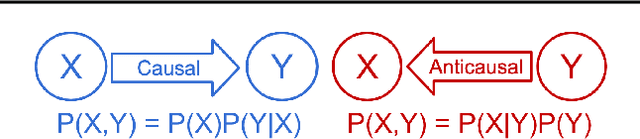

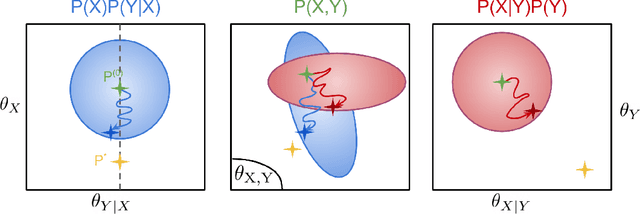
We consider the problem of discovering the causal process that generated a collection of datasets. We assume that all these datasets were generated by unknown sparse interventions on a structural causal model (SCM) $G$, that we want to identify. Recently, Bengio et al. (2020) argued that among all SCMs, $G$ is the fastest to adapt from one dataset to another, and proposed a meta-learning criterion to identify the causal direction in a two-variable SCM. While the experiments were promising, the theoretical justification was incomplete. Our contribution is a theoretical investigation of the adaptation speed of simple two-variable SCMs. We use convergence rates from stochastic optimization to justify that a relevant proxy for adaptation speed is distance in parameter space after intervention. Using this proxy, we show that the SCM with the correct causal direction is advantaged for categorical and normal cause-effect datasets when the intervention is on the cause variable. When the intervention is on the effect variable, we provide a more nuanced picture which highlights that the fastest-to-adapt heuristic is not always valid. Code to reproduce experiments is available at https://github.com/remilepriol/causal-adaptation-speed
Stochastic Polyak Step-size for SGD: An Adaptive Learning Rate for Fast Convergence
Feb 24, 2020
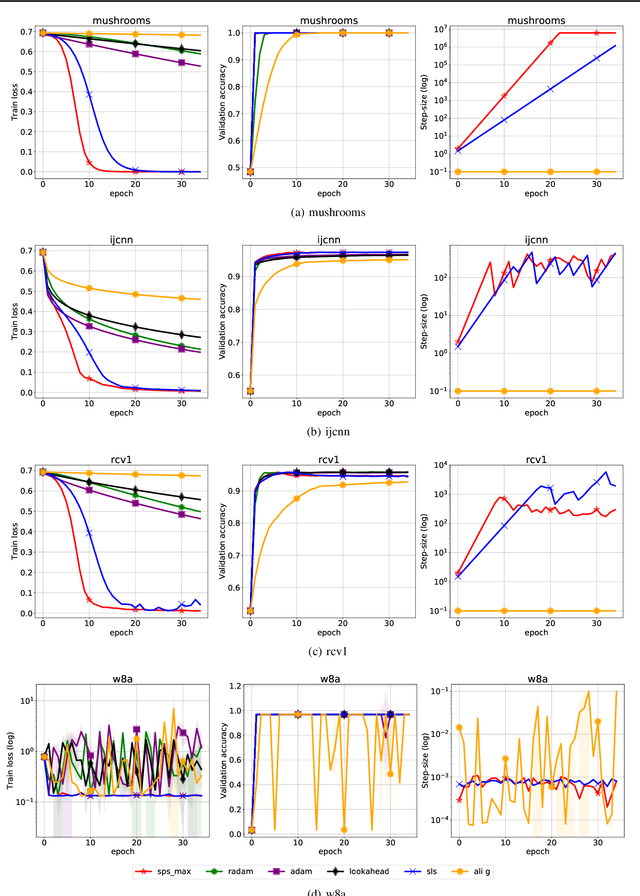
We propose a stochastic variant of the classical Polyak step-size (Polyak, 1987) commonly used in the subgradient method. Although computing the Polyak step-size requires knowledge of the optimal function values, this information is readily available for typical modern machine learning applications. Consequently, the proposed stochastic Polyak step-size (SPS) is an attractive choice for setting the learning rate for stochastic gradient descent (SGD). We provide theoretical convergence guarantees for SGD equipped with SPS in different settings, including strongly convex, convex and non-convex functions. Furthermore, our analysis results in novel convergence guarantees for SGD with a constant step-size. We show that SPS is particularly effective when training over-parameterized models capable of interpolating the training data. In this setting, we prove that SPS enables SGD to converge to the true solution at a fast rate without requiring the knowledge of any problem-dependent constants or additional computational overhead. We experimentally validate our theoretical results via extensive experiments on synthetic and real datasets. We demonstrate the strong performance of SGD with SPS compared to state-of-the-art optimization methods when training over-parameterized models.
Accelerating Smooth Games by Manipulating Spectral Shapes
Jan 02, 2020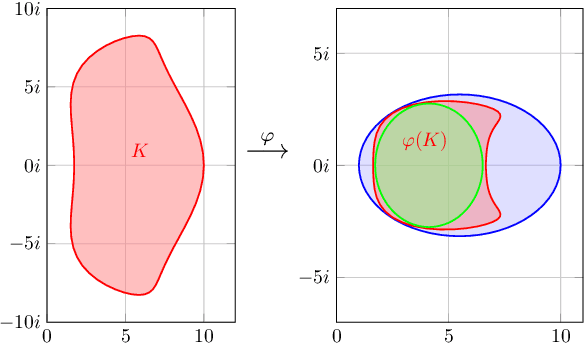
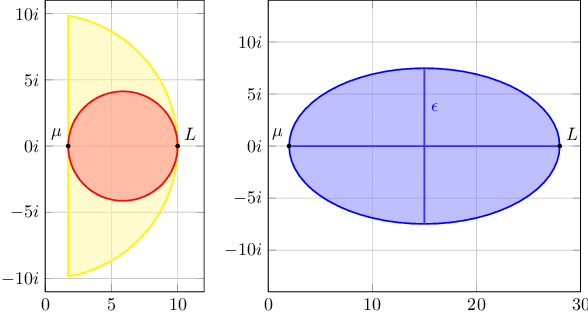
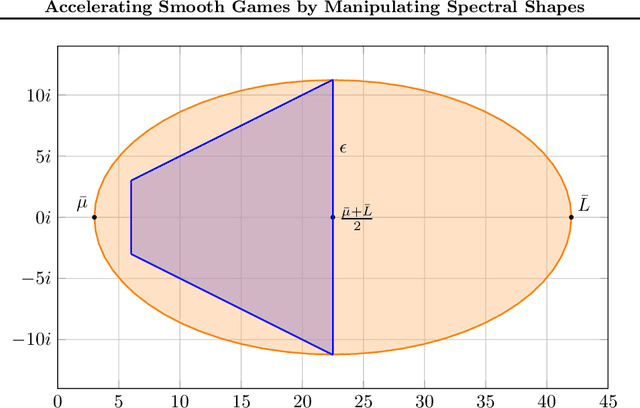
We use matrix iteration theory to characterize acceleration in smooth games. We define the spectral shape of a family of games as the set containing all eigenvalues of the Jacobians of standard gradient dynamics in the family. Shapes restricted to the real line represent well-understood classes of problems, like minimization. Shapes spanning the complex plane capture the added numerical challenges in solving smooth games. In this framework, we describe gradient-based methods, such as extragradient, as transformations on the spectral shape. Using this perspective, we propose an optimal algorithm for bilinear games. For smooth and strongly monotone operators, we identify a continuum between convex minimization, where acceleration is possible using Polyak's momentum, and the worst case where gradient descent is optimal. Finally, going beyond first-order methods, we propose an accelerated version of consensus optimization.
Fast and Furious Convergence: Stochastic Second Order Methods under Interpolation
Oct 11, 2019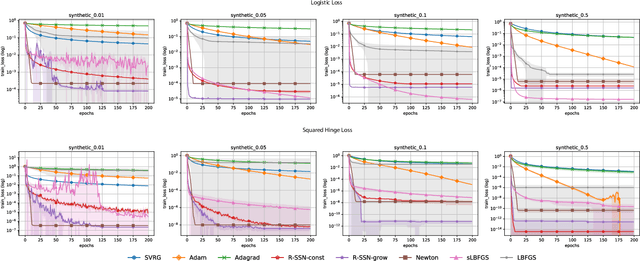
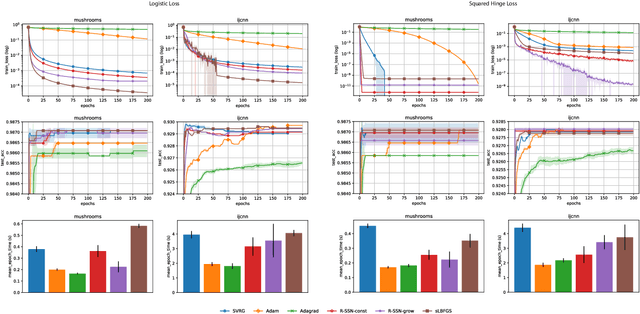
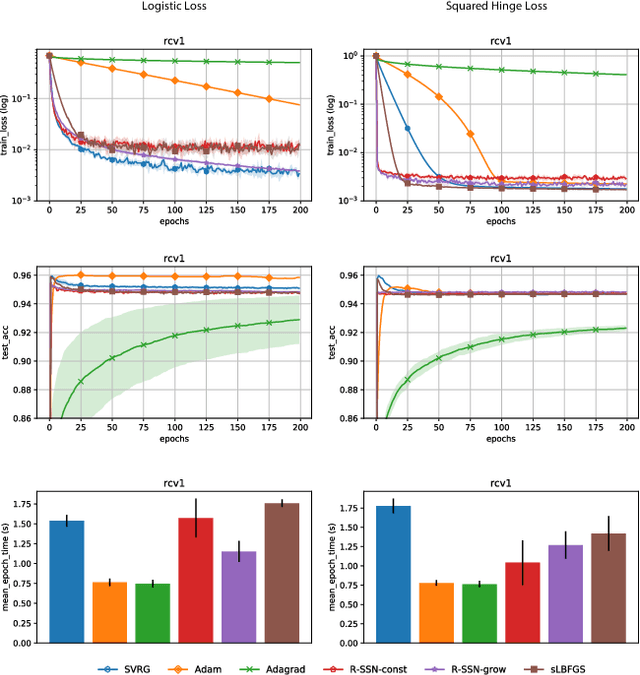
We consider stochastic second order methods for minimizing strongly-convex functions under an interpolation condition satisfied by over-parameterized models. Under this condition, we show that the regularized sub-sampled Newton method (R-SSN) achieves global linear convergence with an adaptive step size and a constant batch size. By growing the batch size for both the sub-sampled gradient and Hessian, we show that R-SSN can converge at a quadratic rate in a local neighbourhood of the solution. We also show that R-SSN attains local linear convergence for the family of self-concordant functions. Furthermore, we analyse stochastic BFGS algorithms in the interpolation setting and prove their global linear convergence. We empirically evaluate stochastic L-BFGS and a "Hessian-free" implementation of R-SSN for binary classification on synthetic, linearly-separable datasets and consider real medium-size datasets under a kernel mapping. Our experimental results show the fast convergence of these methods both in terms of the number of iterations and wall-clock time.
A Tight and Unified Analysis of Extragradient for a Whole Spectrum of Differentiable Games
Jun 24, 2019

We consider differentiable games: multi-objective minimization problems, where the goal is to find a Nash equilibrium. The machine learning community has recently started using extrapolation-based variants of the gradient method. A prime example is the extragradient, which yields linear convergence in cases like bilinear games, where the standard gradient method fails. The full benefits of extrapolation-based methods are not known: i) there is no unified analysis for a large class of games that includes both strongly monotone and bilinear games; ii) it is not known whether the rate achieved by extragradient can be improved, e.g. by considering multiple extrapolation steps. We answer these questions through new analysis of the extragradient's local and global convergence properties. Our analysis covers the whole range of settings between purely bilinear and strongly monotone games. It reveals that extragradient converges via different mechanisms at these extremes; in between, it exploits the most favorable mechanism for the given problem. We then present lower bounds on the rate of convergence for a wide class of algorithms with any number of extrapolations. Our bounds prove that the extragradient achieves the optimal rate in this class, and that our upper bounds are tight. Our precise characterization of the extragradient's convergence behavior in games shows that, unlike in convex optimization, the extragradient method may be much faster than the gradient method.
GEAR: Geometry-Aware Rényi Information
Jun 19, 2019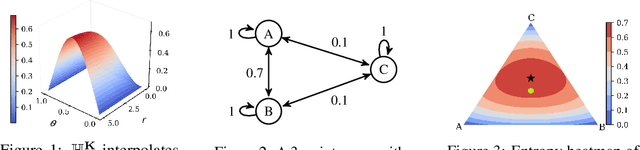


Shannon's seminal theory of information has been of paramount importance in the development of modern machine learning techniques. However, standard information measures deal with probability distributions over an alphabet considered as a mere set of symbols and disregard further geometric structure, which might be available in the form of a metric or similarity function. We advocate the use of a notion of entropy that reflects not only the relative abundances of symbols but also the similarities between them, which was originally introduced in theoretical ecology to study the diversity of biological communities. Echoing this idea, we propose a criterion for comparing two probability distributions (possibly degenerate and with non-overlapping supports) that takes into account the geometry of the space in which the distributions are defined. Our proposal exhibits performance on par with state-of-the-art methods based on entropy-regularized optimal transport, but enjoys a closed-form expression and thus a lower computational cost. We demonstrate the versatility of our proposal via experiments on a broad range of domains: computing image barycenters, approximating densities with a collection of (super-) samples; summarizing texts; assessing mode coverage; as well as training generative models.