 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Data Balancing for Unlabeled Satellite Imagery
Jul 07, 2021



Data imbalance is a ubiquitous problem in machine learning. In large scale collected and annotated datasets, data imbalance is either mitigated manually by undersampling frequent classes and oversampling rare classes, or planned for with imputation and augmentation techniques. In both cases balancing data requires labels. In other words, only annotated data can be balanced. Collecting fully annotated datasets is challenging, especially for large scale satellite systems such as the unlabeled NASA's 35 PB Earth Imagery dataset. Although the NASA Earth Imagery dataset is unlabeled, there are implicit properties of the data source that we can rely on to hypothesize about its imbalance, such as distribution of land and water in the case of the Earth's imagery. We present a new iterative method to balance unlabeled data. Our method utilizes image embeddings as a proxy for image labels that can be used to balance data, and ultimately when trained increases overall accuracy.
Reducing Effects of Swath Gaps on Unsupervised Machine Learning Models for NASA MODIS Instruments
Jun 13, 2021


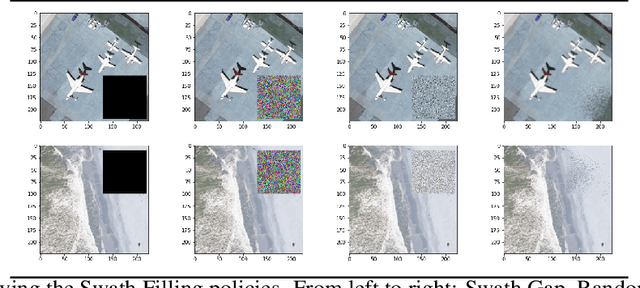
Due to the nature of their pathways, NASA Terra and NASA Aqua satellites capture imagery containing swath gaps, which are areas of no data. Swath gaps can overlap the region of interest (ROI) completely, often rendering the entire imagery unusable by Machine Learning (ML) models. This problem is further exacerbated when the ROI rarely occurs (e.g. a hurricane) and, on occurrence, is partially overlapped with a swath gap. With annotated data as supervision, a model can learn to differentiate between the area of focus and the swath gap. However, annotation is expensive and currently the vast majority of existing data is unannotated. Hence, we propose an augmentation technique that considerably removes the existence of swath gaps in order to allow CNNs to focus on the ROI, and thus successfully use data with swath gaps for training. We experiment on the UC Merced Land Use Dataset, where we add swath gaps through empty polygons (up to 20 percent areas) and then apply augmentation techniques to fill the swath gaps. We compare the model trained with our augmentation techniques on the swath gap-filled data with the model trained on the original swath gap-less data and note highly augmented performance. Additionally, we perform a qualitative analysis using activation maps that visualizes the effectiveness of our trained network in not paying attention to the swath gaps. We also evaluate our results with a human baseline and show that, in certain cases, the filled swath gaps look so realistic that even a human evaluator did not distinguish between original satellite images and swath gap-filled images. Since this method is aimed at unlabeled data, it is widely generalizable and impactful for large scale unannotated datasets from various space data domains.
Next-Gen Machine Learning Supported Diagnostic Systems for Spacecraft
Jun 10, 2021Future short or long-term space missions require a new generation of monitoring and diagnostic systems due to communication impasses as well as limitations in specialized crew and equipment. Machine learning supported diagnostic systems present a viable solution for medical and technical applications. We discuss challenges and applicability of such systems in light of upcoming missions and outline an example use case for a next-generation medical diagnostic system for future space operations. Additionally, we present approach recommendations and constraints for the successful generation and use of machine learning models aboard a spacecraft.
Learn-to-Race: A Multimodal Control Environment for Autonomous Racing
Mar 31, 2021
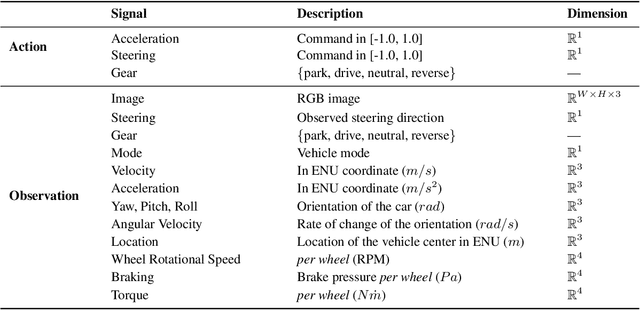
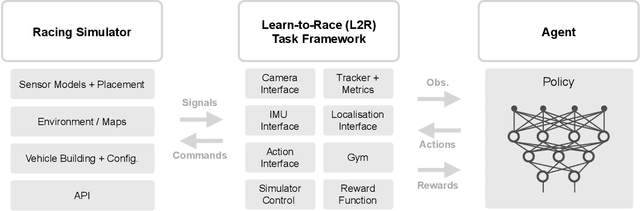

Existing research on autonomous driving primarily focuses on urban driving, which is insufficient for characterising the complex driving behaviour underlying high-speed racing. At the same time, existing racing simulation frameworks struggle in capturing realism, with respect to visual rendering, vehicular dynamics, and task objectives, inhibiting the transfer of learning agents to real-world contexts. We introduce a new environment, where agents Learn-to-Race (L2R) in simulated competition-style racing, using multimodal information--from virtual cameras to a comprehensive array of inertial measurement sensors. Our environment, which includes a simulator and an interfacing training framework, accurately models vehicle dynamics and racing conditions. In this paper, we release the Arrival simulator for autonomous racing. Next, we propose the L2R task with challenging metrics, inspired by learning-to-drive challenges, Formula-style racing, and multimodal trajectory prediction for autonomous driving. Additionally, we provide the L2R framework suite, facilitating simulated racing on high-precision models of real-world tracks, such as the famed Thruxton Circuit and the Las Vegas Motor Speedway. Finally, we provide an official L2R task dataset of expert demonstrations, as well as a series of baseline experiments and reference implementations. We make all code available: https://github.com/hermgerm29/learn-to-race
Global Earth Magnetic Field Modeling and Forecasting with Spherical Harmonics Decomposition
Feb 02, 2021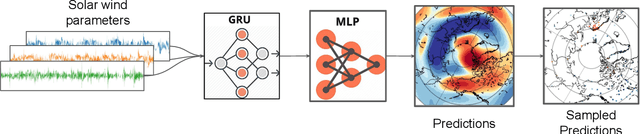


Modeling and forecasting the solar wind-driven global magnetic field perturbations is an open challenge. Current approaches depend on simulations of computationally demanding models like the Magnetohydrodynamics (MHD) model or sampling spatially and temporally through sparse ground-based stations (SuperMAG). In this paper, we develop a Deep Learning model that forecasts in Spherical Harmonics space 2, replacing reliance on MHD models and providing global coverage at one minute cadence, improving over the current state-of-the-art which relies on feature engineering. We evaluate the performance in SuperMAG dataset (improved by 14.53%) and MHD simulations (improved by 24.35%). Additionally, we evaluate the extrapolation performance of the spherical harmonics reconstruction based on sparse ground-based stations (SuperMAG), showing that spherical harmonics can reliably reconstruct the global magnetic field as evaluated on MHD simulation.
Technology Readiness Levels for Machine Learning Systems
Jan 11, 2021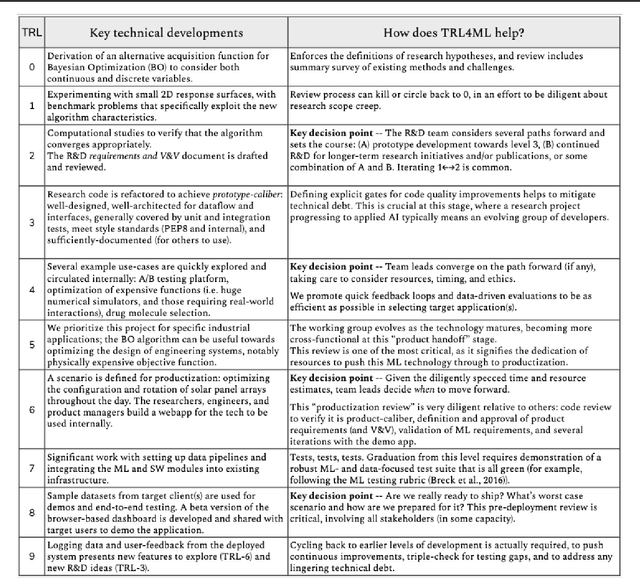

The development and deployment of machine learning (ML) systems can be executed easily with modern tools, but the process is typically rushed and means-to-an-end. The lack of diligence can lead to technical debt, scope creep and misaligned objectives, model misuse and failures, and expensive consequences. Engineering systems, on the other hand, follow well-defined processes and testing standards to streamline development for high-quality, reliable results. The extreme is spacecraft systems, where mission critical measures and robustness are ingrained in the development process. Drawing on experience in both spacecraft engineering and ML (from research through product across domain areas), we have developed a proven systems engineering approach for machine learning development and deployment. Our "Machine Learning Technology Readiness Levels" (MLTRL) framework defines a principled process to ensure robust, reliable, and responsible systems while being streamlined for ML workflows, including key distinctions from traditional software engineering. Even more, MLTRL defines a lingua franca for people across teams and organizations to work collaboratively on artificial intelligence and machine learning technologies. Here we describe the framework and elucidate it with several real world use-cases of developing ML methods from basic research through productization and deployment, in areas such as medical diagnostics, consumer computer vision, satellite imagery, and particle physics.
Space ML: Distributed Open-source Research with Citizen Scientists for the Advancement of Space Technology for NASA
Dec 27, 2020Traditionally, academic labs conduct open-ended research with the primary focus on discoveries with long-term value, rather than direct products that can be deployed in the real world. On the other hand, research in the industry is driven by its expected commercial return on investment, and hence focuses on a real world product with short-term timelines. In both cases, opportunity is selective, often available to researchers with advanced educational backgrounds. Research often happens behind closed doors and may be kept confidential until either its publication or product release, exacerbating the problem of AI reproducibility and slowing down future research by others in the field. As many research organizations tend to exclusively focus on specific areas, opportunities for interdisciplinary research reduce. Undertaking long-term bold research in unexplored fields with non-commercial yet great public value is hard due to factors including the high upfront risk, budgetary constraints, and a lack of availability of data and experts in niche fields. Only a few companies or well-funded research labs can afford to do such long-term research. With research organizations focused on an exploding array of fields and resources spread thin, opportunities for the maturation of interdisciplinary research reduce. Apart from these exigencies, there is also a need to engage citizen scientists through open-source contributors to play an active part in the research dialogue. We present a short case study of Space ML, an extension of the Frontier Development Lab, an AI accelerator for NASA. Space ML distributes open-source research and invites volunteer citizen scientists to partake in development and deployment of high social value products at the intersection of space and AI.
Learnings from Frontier Development Lab and SpaceML -- AI Accelerators for NASA and ESA
Nov 09, 2020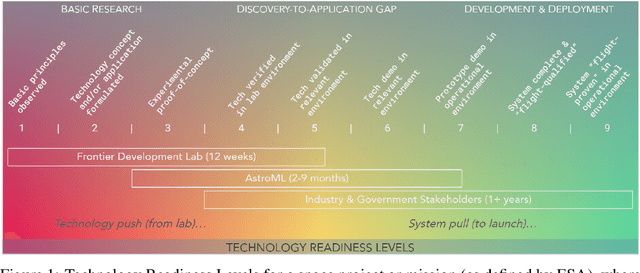
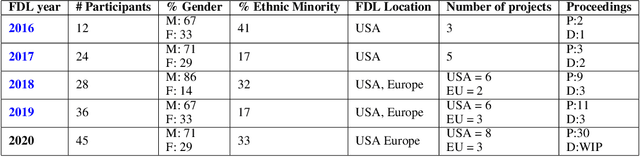
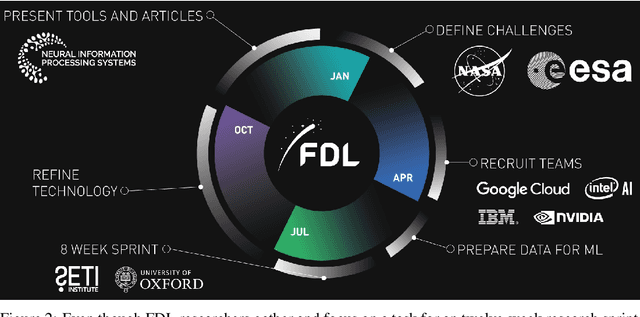
Research with AI and ML technologies lives in a variety of settings with often asynchronous goals and timelines: academic labs and government organizations pursue open-ended research focusing on discoveries with long-term value, while research in industry is driven by commercial pursuits and hence focuses on short-term timelines and return on investment. The journey from research to product is often tacit or ad hoc, resulting in technology transition failures, further exacerbated when research and development is interorganizational and interdisciplinary. Even more, much of the ability to produce results remains locked in the private repositories and know-how of the individual researcher, slowing the impact on future research by others and contributing to the ML community's challenges in reproducibility. With research organizations focused on an exploding array of fields, opportunities for the handover and maturation of interdisciplinary research reduce. With these tensions, we see an emerging need to measure the correctness, impact, and relevance of research during its development to enable better collaboration, improved reproducibility, faster progress, and more trusted outcomes. We perform a case study of the Frontier Development Lab (FDL), an AI accelerator under a public-private partnership from NASA and ESA. FDL research follows principled practices that are grounded in responsible development, conduct, and dissemination of AI research, enabling FDL to churn successful interdisciplinary and interorganizational research projects, measured through NASA's Technology Readiness Levels. We also take a look at the SpaceML Open Source Research Program, which helps accelerate and transition FDL's research to deployable projects with wide spread adoption amongst citizen scientists.
What's in a Question: Using Visual Questions as a Form of Supervision
Apr 12, 2017



Collecting fully annotated image datasets is challenging and expensive. Many types of weak supervision have been explored: weak manual annotations, web search results, temporal continuity, ambient sound and others. We focus on one particular unexplored mode: visual questions that are asked about images. The key observation that inspires our work is that the question itself provides useful information about the image (even without the answer being available). For instance, the question "what is the breed of the dog?" informs the AI that the animal in the scene is a dog and that there is only one dog present. We make three contributions: (1) providing an extensive qualitative and quantitative analysis of the information contained in human visual questions, (2) proposing two simple but surprisingly effective modifications to the standard visual question answering models that allow them to make use of weak supervision in the form of unanswered questions associated with images and (3) demonstrating that a simple data augmentation strategy inspired by our insights results in a 7.1% improvement on the standard VQA benchmark.