 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSILG: The Multi-environment Symbolic Interactive Language Grounding Benchmark
Oct 20, 2021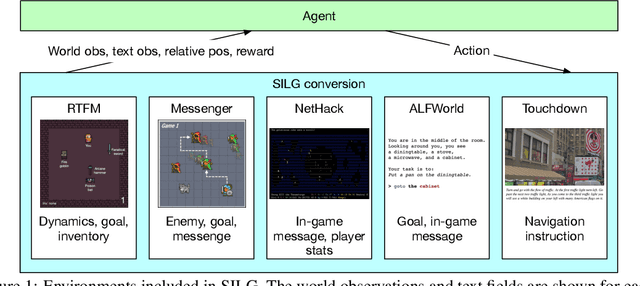
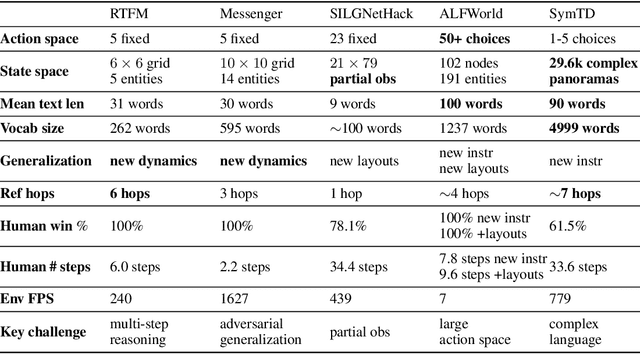
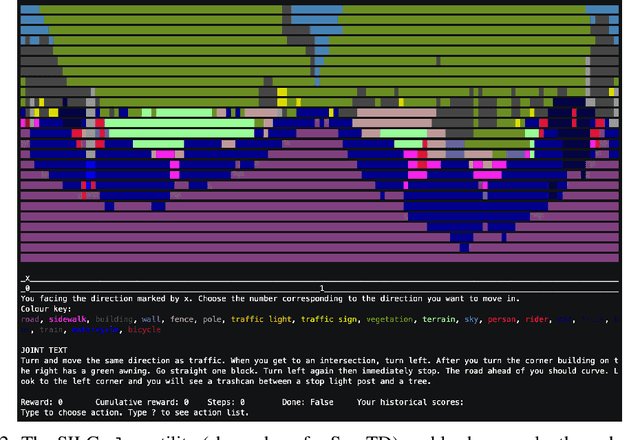
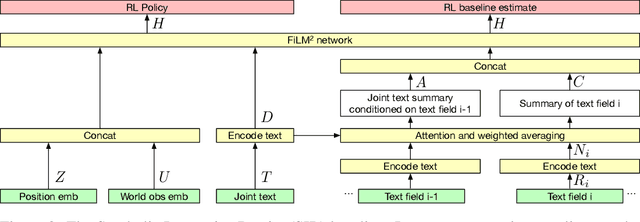
Existing work in language grounding typically study single environments. How do we build unified models that apply across multiple environments? We propose the multi-environment Symbolic Interactive Language Grounding benchmark (SILG), which unifies a collection of diverse grounded language learning environments under a common interface. SILG consists of grid-world environments that require generalization to new dynamics, entities, and partially observed worlds (RTFM, Messenger, NetHack), as well as symbolic counterparts of visual worlds that require interpreting rich natural language with respect to complex scenes (ALFWorld, Touchdown). Together, these environments provide diverse grounding challenges in richness of observation space, action space, language specification, and plan complexity. In addition, we propose the first shared model architecture for RL on these environments, and evaluate recent advances such as egocentric local convolution, recurrent state-tracking, entity-centric attention, and pretrained LM using SILG. Our shared architecture achieves comparable performance to environment-specific architectures. Moreover, we find that many recent modelling advances do not result in significant gains on environments other than the one they were designed for. This highlights the need for a multi-environment benchmark. Finally, the best models significantly underperform humans on SILG, which suggests ample room for future work. We hope SILG enables the community to quickly identify new methodologies for language grounding that generalize to a diverse set of environments and their associated challenges.
Bilingual Lexicon Induction via Unsupervised Bitext Construction and Word Alignment
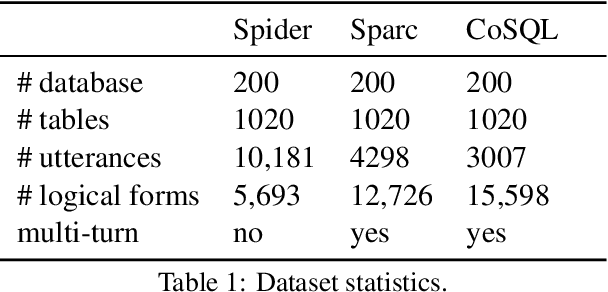
Jan 01, 2021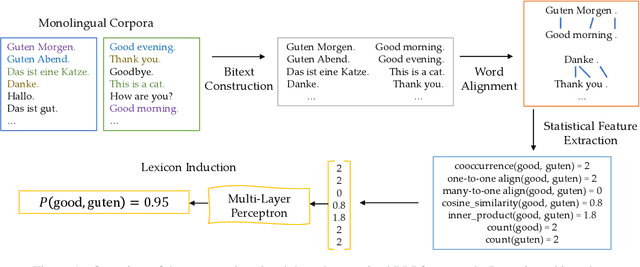
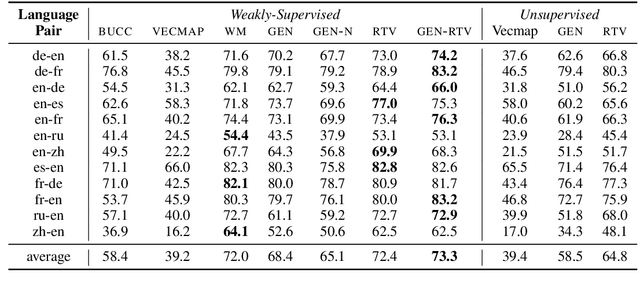
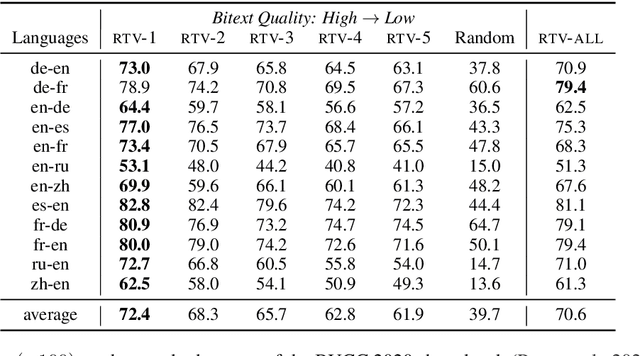
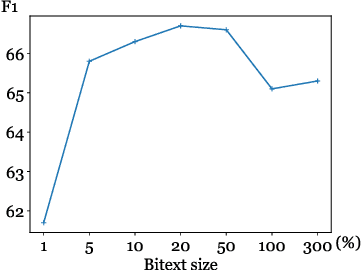
Bilingual lexicons map words in one language to their translations in another, and are typically induced by learning linear projections to align monolingual word embedding spaces. In this paper, we show it is possible to produce much higher quality lexicons with methods that combine (1) unsupervised bitext mining and (2) unsupervised word alignment. Directly applying a pipeline that uses recent algorithms for both subproblems significantly improves induced lexicon quality and further gains are possible by learning to filter the resulting lexical entries, with both unsupervised and semi-supervised schemes. Our final model outperforms the state of the art on the BUCC 2020 shared task by 14 $F_1$ points averaged over 12 language pairs, while also providing a more interpretable approach that allows for rich reasoning of word meaning in context.
Grounded Adaptation for Zero-shot Executable Semantic Parsing
Sep 17, 2020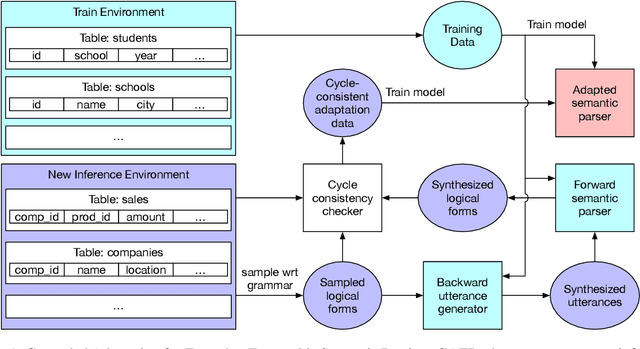

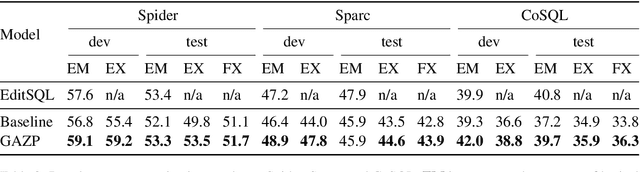
We propose Grounded Adaptation for Zero-shot Executable Semantic Parsing (GAZP) to adapt an existing semantic parser to new environments (e.g. new database schemas). GAZP combines a forward semantic parser with a backward utterance generator to synthesize data (e.g. utterances and SQL queries) in the new environment, then selects cycle-consistent examples to adapt the parser. Unlike data-augmentation, which typically synthesizes unverified examples in the training environment, GAZP synthesizes examples in the new environment whose input-output consistency are verified. On the Spider, Sparc, and CoSQL zero-shot semantic parsing tasks, GAZP improves logical form and execution accuracy of the baseline parser. Our analyses show that GAZP outperforms data-augmentation in the training environment, performance increases with the amount of GAZP-synthesized data, and cycle-consistency is central to successful adaptation.
Simple Recurrent Units for Highly Parallelizable Recurrence
Sep 07, 2018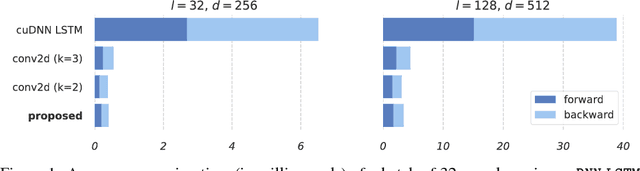

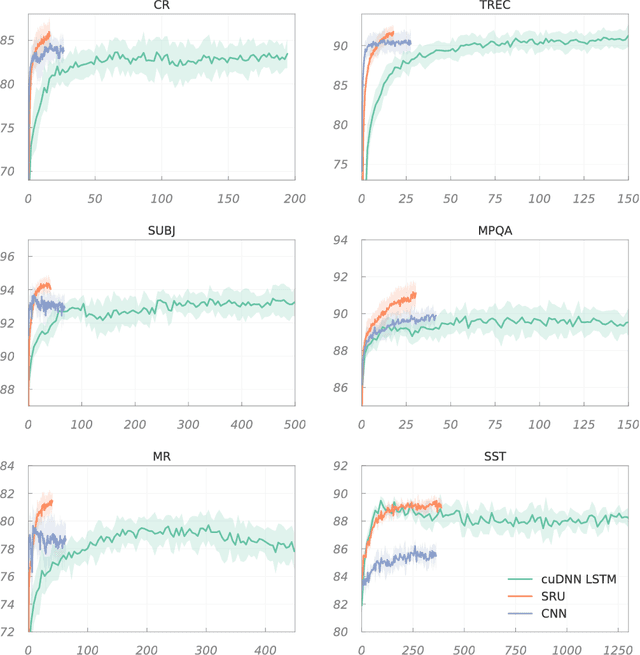
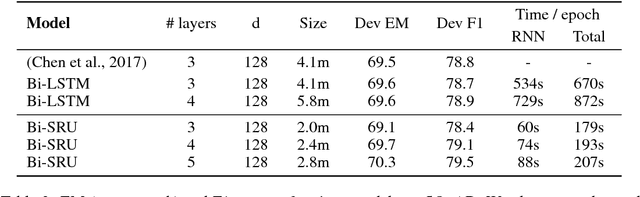
Common recurrent neural architectures scale poorly due to the intrinsic difficulty in parallelizing their state computations. In this work, we propose the Simple Recurrent Unit (SRU), a light recurrent unit that balances model capacity and scalability. SRU is designed to provide expressive recurrence, enable highly parallelized implementation, and comes with careful initialization to facilitate training of deep models. We demonstrate the effectiveness of SRU on multiple NLP tasks. SRU achieves 5--9x speed-up over cuDNN-optimized LSTM on classification and question answering datasets, and delivers stronger results than LSTM and convolutional models. We also obtain an average of 0.7 BLEU improvement over the Transformer model on translation by incorporating SRU into the architecture.
Naturalizing a Programming Language via Interactive Learning
Apr 23, 2017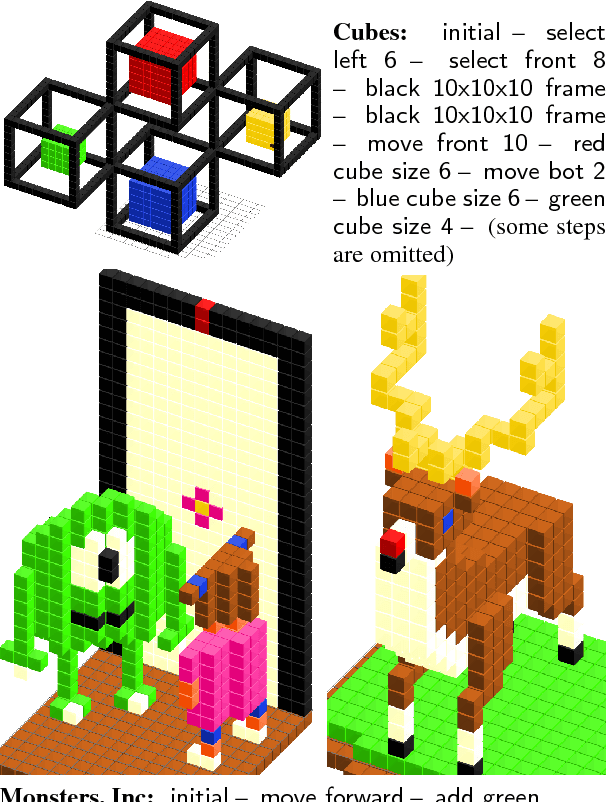
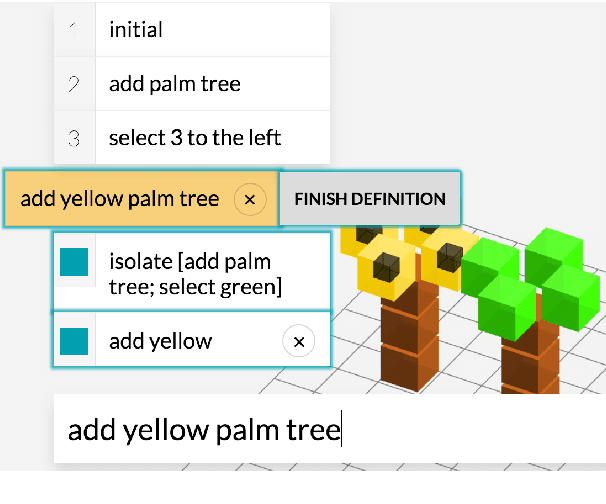
Our goal is to create a convenient natural language interface for performing well-specified but complex actions such as analyzing data, manipulating text, and querying databases. However, existing natural language interfaces for such tasks are quite primitive compared to the power one wields with a programming language. To bridge this gap, we start with a core programming language and allow users to "naturalize" the core language incrementally by defining alternative, more natural syntax and increasingly complex concepts in terms of compositions of simpler ones. In a voxel world, we show that a community of users can simultaneously teach a common system a diverse language and use it to build hundreds of complex voxel structures. Over the course of three days, these users went from using only the core language to using the naturalized language in 85.9\% of the last 10K utterances.
Data Noising as Smoothing in Neural Network Language Models
Mar 07, 2017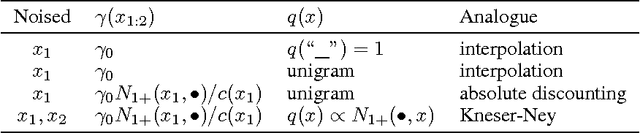
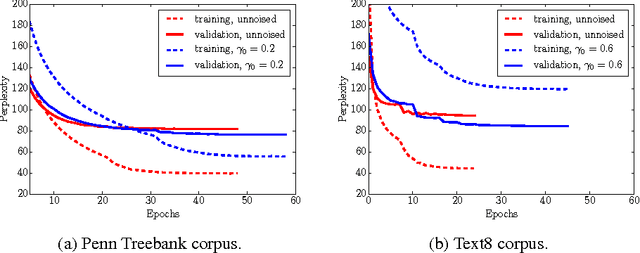
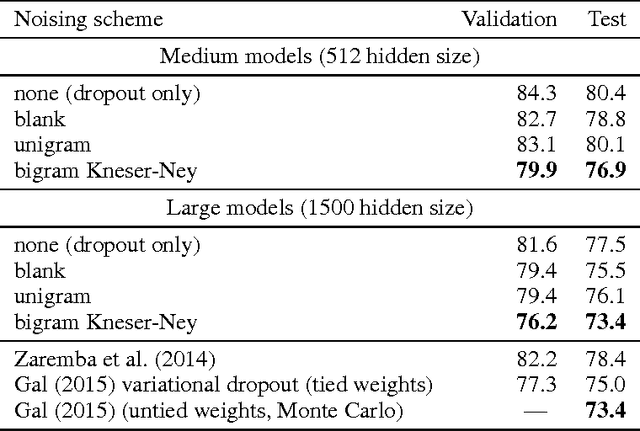
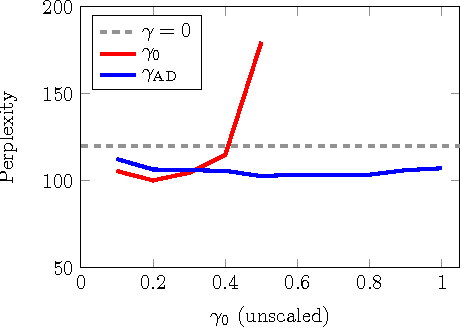
Data noising is an effective technique for regularizing neural network models. While noising is widely adopted in application domains such as vision and speech, commonly used noising primitives have not been developed for discrete sequence-level settings such as language modeling. In this paper, we derive a connection between input noising in neural network language models and smoothing in $n$-gram models. Using this connection, we draw upon ideas from smoothing to develop effective noising schemes. We demonstrate performance gains when applying the proposed schemes to language modeling and machine translation. Finally, we provide empirical analysis validating the relationship between noising and smoothing.
Learning Language Games through Interaction
Jun 08, 2016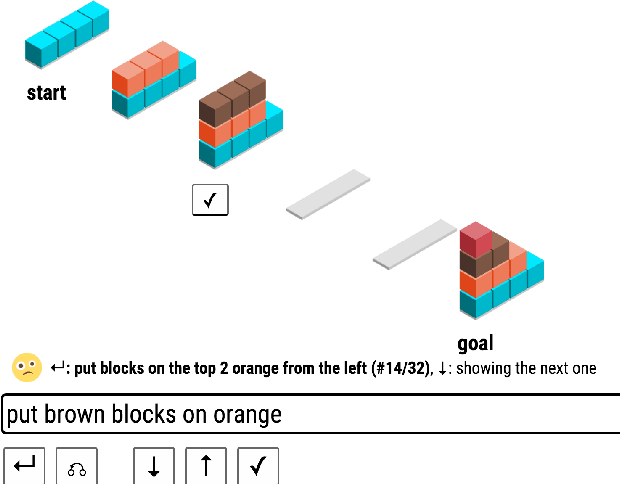

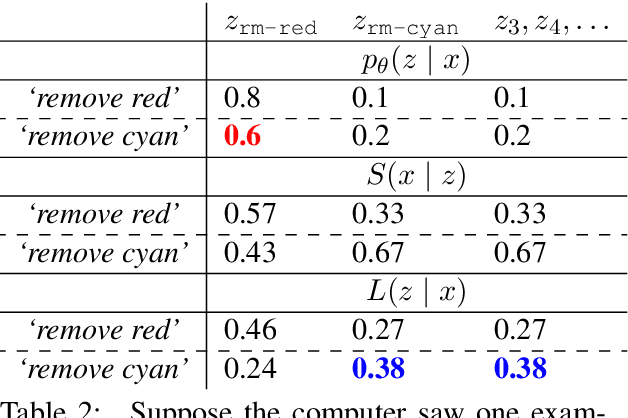
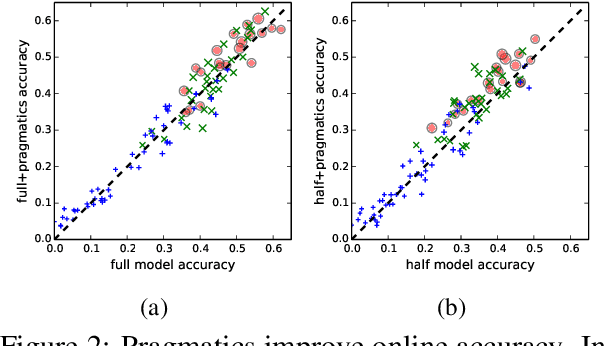
We introduce a new language learning setting relevant to building adaptive natural language interfaces. It is inspired by Wittgenstein's language games: a human wishes to accomplish some task (e.g., achieving a certain configuration of blocks), but can only communicate with a computer, who performs the actual actions (e.g., removing all red blocks). The computer initially knows nothing about language and therefore must learn it from scratch through interaction, while the human adapts to the computer's capabilities. We created a game in a blocks world and collected interactions from 100 people playing it. First, we analyze the humans' strategies, showing that using compositionality and avoiding synonyms correlates positively with task performance. Second, we compare computer strategies, showing how to quickly learn a semantic parsing model from scratch, and that modeling pragmatics further accelerates learning for successful players.
Estimating Mixture Models via Mixtures of Polynomials
Mar 28, 2016

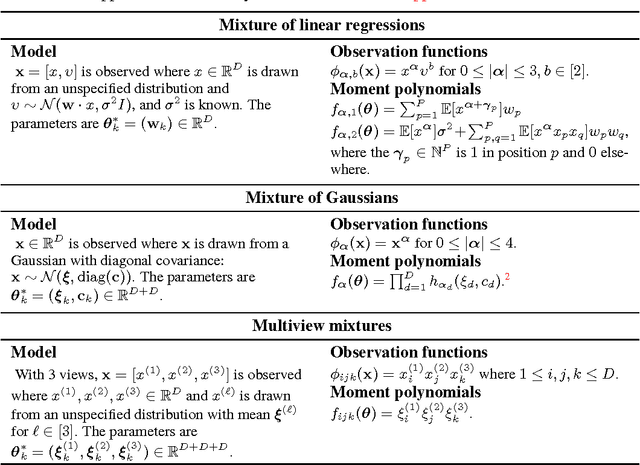
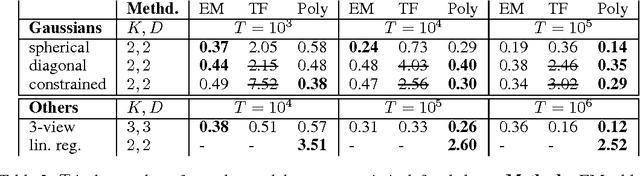
Mixture modeling is a general technique for making any simple model more expressive through weighted combination. This generality and simplicity in part explains the success of the Expectation Maximization (EM) algorithm, in which updates are easy to derive for a wide class of mixture models. However, the likelihood of a mixture model is non-convex, so EM has no known global convergence guarantees. Recently, method of moments approaches offer global guarantees for some mixture models, but they do not extend easily to the range of mixture models that exist. In this work, we present Polymom, an unifying framework based on method of moments in which estimation procedures are easily derivable, just as in EM. Polymom is applicable when the moments of a single mixture component are polynomials of the parameters. Our key observation is that the moments of the mixture model are a mixture of these polynomials, which allows us to cast estimation as a Generalized Moment Problem. We solve its relaxations using semidefinite optimization, and then extract parameters using ideas from computer algebra. This framework allows us to draw insights and apply tools from convex optimization, computer algebra and the theory of moments to study problems in statistical estimation.
Relaxations for inference in restricted Boltzmann machines
Jan 02, 2014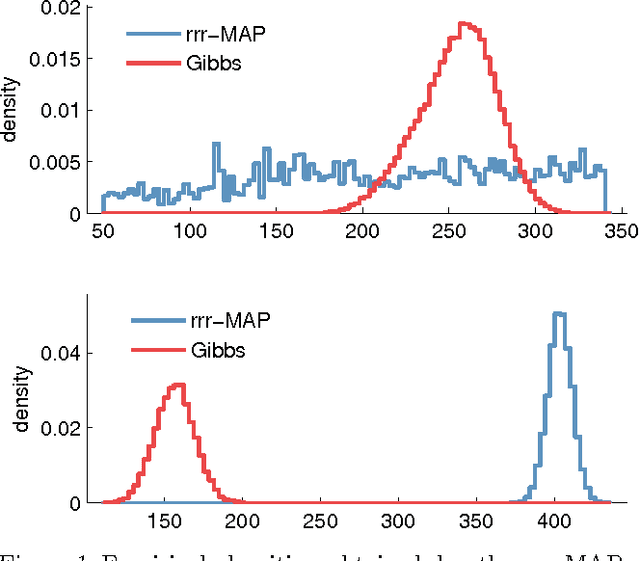
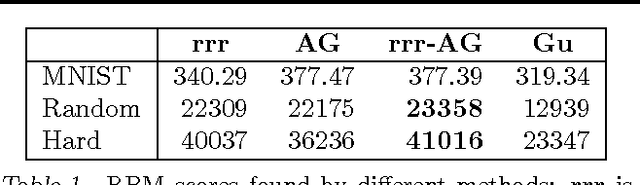
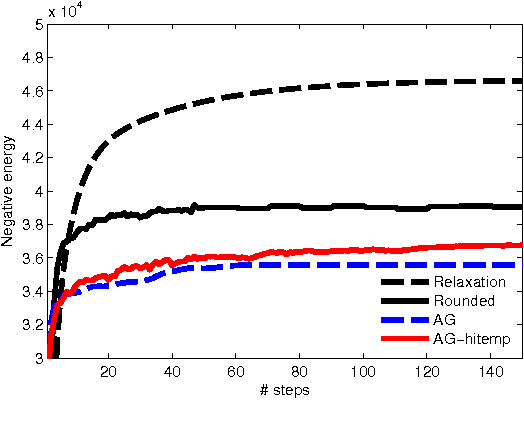

We propose a relaxation-based approximate inference algorithm that samples near-MAP configurations of a binary pairwise Markov random field. We experiment on MAP inference tasks in several restricted Boltzmann machines. We also use our underlying sampler to estimate the log-partition function of restricted Boltzmann machines and compare against other sampling-based methods.